 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhoto-realistic Neural Domain Randomization
Oct 23, 2022Synthetic data is a scalable alternative to manual supervision, but it requires overcoming the sim-to-real domain gap. This discrepancy between virtual and real worlds is addressed by two seemingly opposed approaches: improving the realism of simulation or foregoing realism entirely via domain randomization. In this paper, we show that the recent progress in neural rendering enables a new unified approach we call Photo-realistic Neural Domain Randomization (PNDR). We propose to learn a composition of neural networks that acts as a physics-based ray tracer generating high-quality renderings from scene geometry alone. Our approach is modular, composed of different neural networks for materials, lighting, and rendering, thus enabling randomization of different key image generation components in a differentiable pipeline. Once trained, our method can be combined with other methods and used to generate photo-realistic image augmentations online and significantly more efficiently than via traditional ray-tracing. We demonstrate the usefulness of PNDR through two downstream tasks: 6D object detection and monocular depth estimation. Our experiments show that training with PNDR enables generalization to novel scenes and significantly outperforms the state of the art in terms of real-world transfer.
Monocular Differentiable Rendering for Self-Supervised 3D Object Detection
Sep 30, 2020

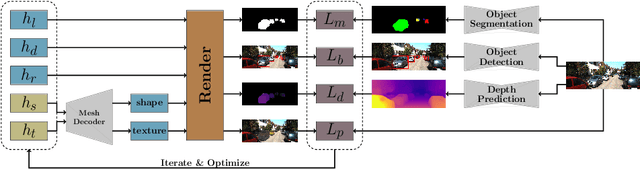
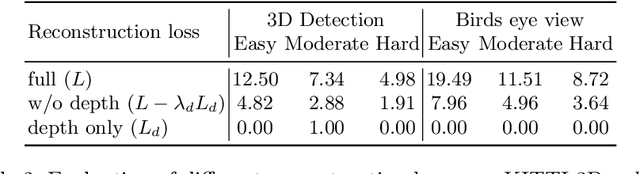
3D object detection from monocular images is an ill-posed problem due to the projective entanglement of depth and scale. To overcome this ambiguity, we present a novel self-supervised method for textured 3D shape reconstruction and pose estimation of rigid objects with the help of strong shape priors and 2D instance masks. Our method predicts the 3D location and meshes of each object in an image using differentiable rendering and a self-supervised objective derived from a pretrained monocular depth estimation network. We use the KITTI 3D object detection dataset to evaluate the accuracy of the method. Experiments demonstrate that we can effectively use noisy monocular depth and differentiable rendering as an alternative to expensive 3D ground-truth labels or LiDAR information.
Differentiable Rendering: A Survey
Jun 22, 2020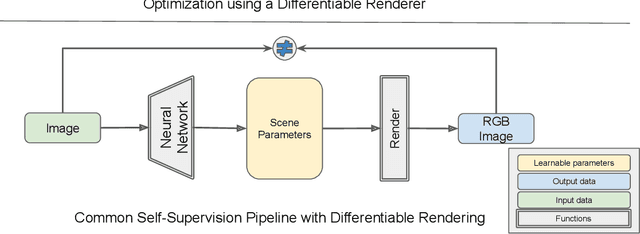
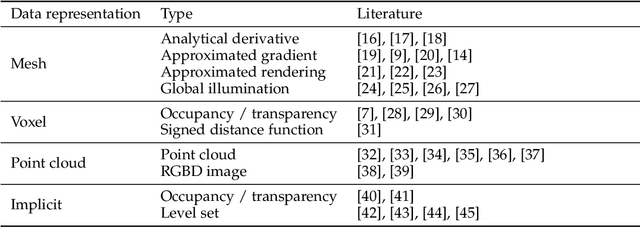
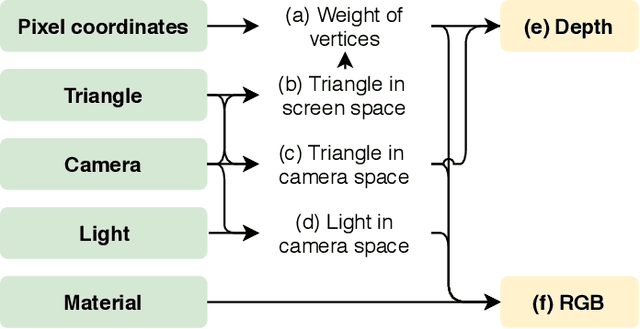

Deep neural networks (DNNs) have shown remarkable performance improvements on vision-related tasks such as object detection or image segmentation. Despite their success, they generally lack the understanding of 3D objects which form the image, as it is not always possible to collect 3D information about the scene or to easily annotate it. Differentiable rendering is a novel field which allows the gradients of 3D objects to be calculated and propagated through images. It also reduces the requirement of 3D data collection and annotation, while enabling higher success rate in various applications. This paper reviews existing literature and discusses the current state of differentiable rendering, its applications and open research problems.
Autolabeling 3D Objects with Differentiable Rendering of SDF Shape Priors
Nov 26, 2019



We present an automatic annotation pipeline to recover 9D cuboids and 3D shape from pre-trained off-the-shelf 2D detectors and sparse LIDAR data. Our autolabeling method solves this challenging ill-posed inverse problem by relying on learned shape priors and optimization of geometric and physical parameters. To that end, we propose a novel differentiable shape renderer over signed distance fields (SDF), which we leverage in combination with normalized object coordinate spaces (NOCS). Initially trained on synthetic data to predict shape and coordinates, our method uses these predictions for projective and geometrical alignment over real samples. We also propose a curriculum learning strategy, iteratively retraining on samples of increasing difficulty for subsequent self-improving annotation rounds. Our experiments on the KITTI3D dataset show that we can recover a substantial amount of accurate cuboids, and that these autolabels can be used to train 3D vehicle detectors with state-of-the-art results. We will make the code publicly available soon.
Real-Time 3D Model Tracking in Color and Depth on a Single CPU Core
Nov 22, 2019

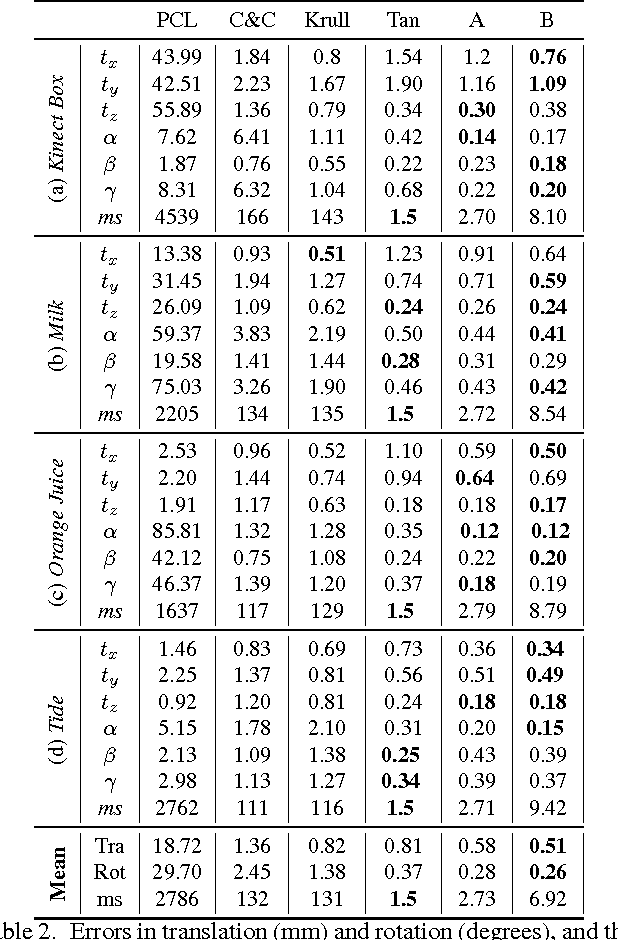
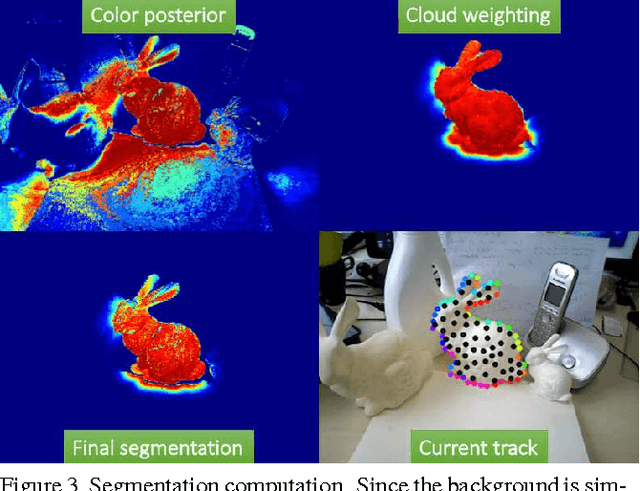
We present a novel method to track 3D models in color and depth data. To this end, we introduce approximations that accelerate the state-of-the-art in region-based tracking by an order of magnitude while retaining similar accuracy. Furthermore, we show how the method can be made more robust in the presence of depth data and consequently formulate a new joint contour and ICP tracking energy. We present better results than the state-of-the-art while being much faster then most other methods and achieving all of the above on a single CPU core.
3D Object Instance Recognition and Pose Estimation Using Triplet Loss with Dynamic Margin
Apr 09, 2019
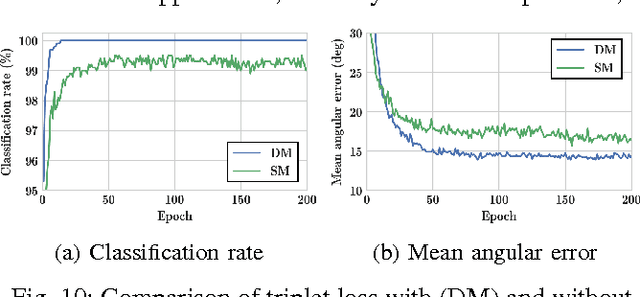

In this paper, we address the problem of 3D object instance recognition and pose estimation of localized objects in cluttered environments using convolutional neural networks. Inspired by the descriptor learning approach of Wohlhart et al., we propose a method that introduces the dynamic margin in the manifold learning triplet loss function. Such a loss function is designed to map images of different objects under different poses to a lower-dimensional, similarity-preserving descriptor space on which efficient nearest neighbor search algorithms can be applied. Introducing the dynamic margin allows for faster training times and better accuracy of the resulting low-dimensional manifolds. Furthermore, we contribute the following: adding in-plane rotations (ignored by the baseline method) to the training, proposing new background noise types that help to better mimic realistic scenarios and improve accuracy with respect to clutter, adding surface normals as another powerful image modality representing an object surface leading to better performance than merely depth, and finally implementing an efficient online batch generation that allows for better variability during the training phase. We perform an exhaustive evaluation to demonstrate the effects of our contributions. Additionally, we assess the performance of the algorithm on the large BigBIRD dataset to demonstrate good scalability properties of the pipeline with respect to the number of models.
DeceptionNet: Network-Driven Domain Randomization
Apr 04, 2019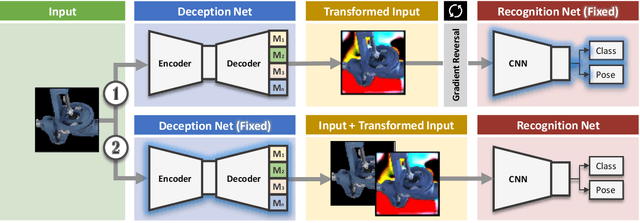
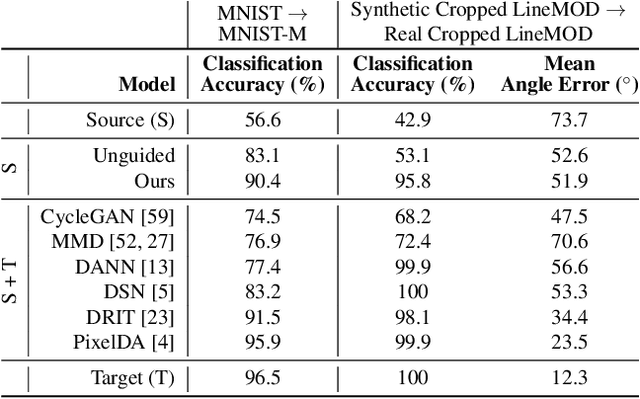
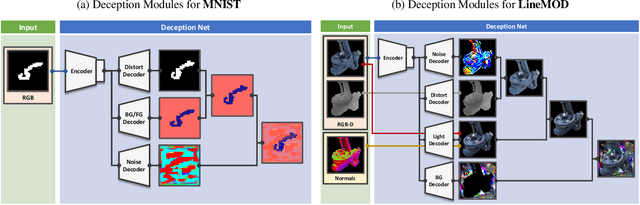
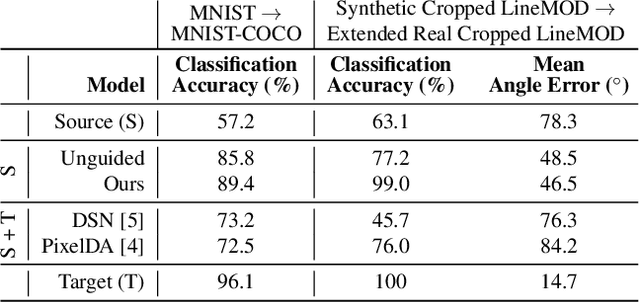
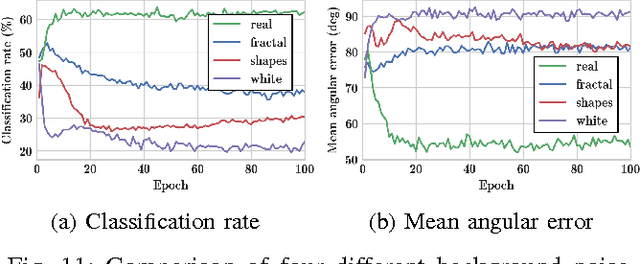
We present a novel approach to tackle domain adaptation between synthetic and real data. Instead of employing 'blind' domain randomization, i.e. augmenting synthetic renderings with random backgrounds or changing illumination and colorization, we leverage the task network as its own adversarial guide towards useful augmentations that maximize the uncertainty of the output. To this end, we design a min-max optimization scheme where a given task competes against a special deception network, with the goal of minimizing the task error subject to specific constraints enforced by the deceiver. The deception network samples from a family of differentiable pixel-level perturbations and exploits the task architecture to find the most destructive augmentations. Unlike GAN-based approaches that require unlabeled data from the target domain, our method achieves robust mappings that scale well to multiple target distributions from source data alone. We apply our framework to the tasks of digit recognition on enhanced MNIST variants as well as classification and object pose estimation on the Cropped LineMOD dataset and compare to a number of domain adaptation approaches, demonstrating similar results with superior generalization capabilities.
ROI-10D: Monocular Lifting of 2D Detection to 6D Pose and Metric Shape
Dec 06, 2018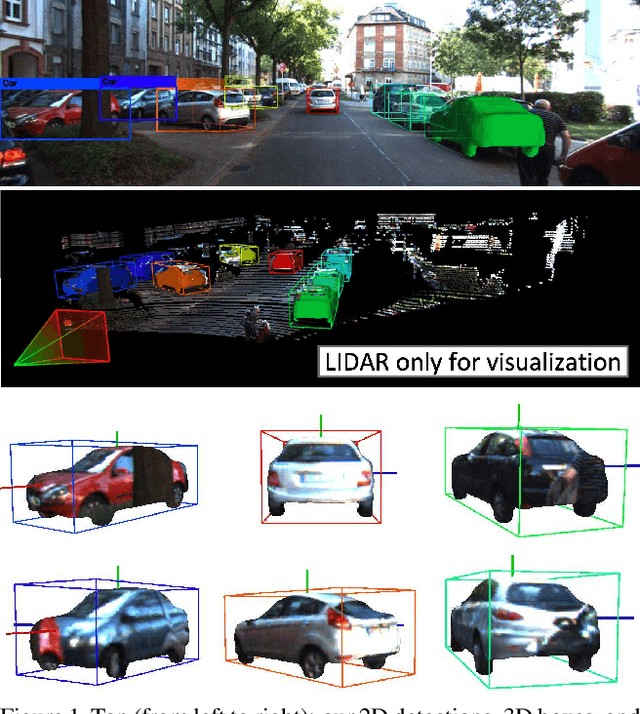

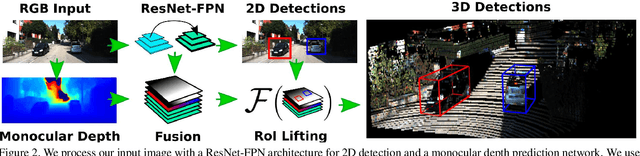
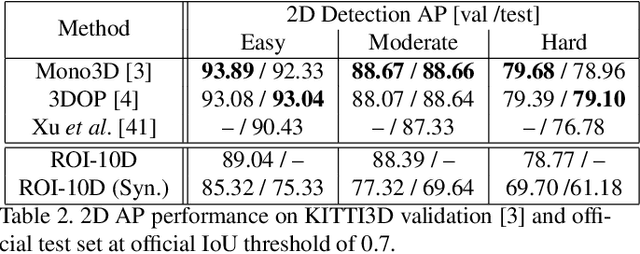
We present a deep learning method for end-to-end monocular 3D object detection and metric shape retrieval. We propose a novel loss formulation by lifting 2D detection, orientation, and scale estimation into 3D space. Instead of optimizing these quantities separately, the 3D instantiation allows to properly measure the metric misalignment of boxes. We experimentally show that our 10D lifting of sparse 2D Regions of Interests (RoIs) achieves great results both for 6D pose and recovery of the textured metric geometry of instances. This further enables 3D synthetic data augmentation via inpainting recovered meshes directly onto the 2D scenes. We evaluate on KITTI3D against other strong monocular methods and demonstrate that our approach doubles the AP on the 3D pose metrics on the official test set, defining the new state of the art.
Deep Model-Based 6D Pose Refinement in RGB
Oct 07, 2018

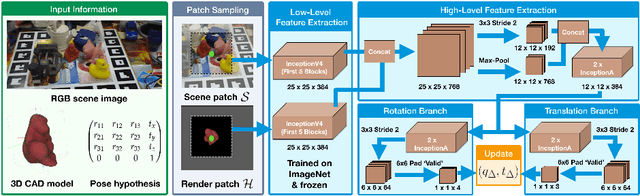
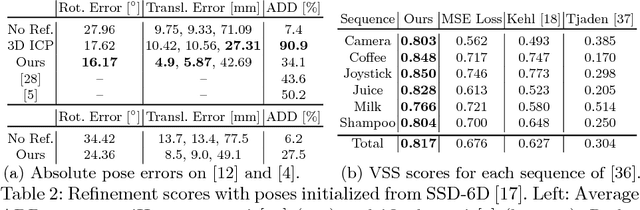
We present a novel approach for model-based 6D pose refinement in color data. Building on the established idea of contour-based pose tracking, we teach a deep neural network to predict a translational and rotational update. At the core, we propose a new visual loss that drives the pose update by aligning object contours, thus avoiding the definition of any explicit appearance model. In contrast to previous work our method is correspondence-free, segmentation-free, can handle occlusion and is agnostic to geometrical symmetry as well as visual ambiguities. Additionally, we observe a strong robustness towards rough initialization. The approach can run in real-time and produces pose accuracies that come close to 3D ICP without the need for depth data. Furthermore, our networks are trained from purely synthetic data and will be published together with the refinement code to ensure reproducibility.
BOP: Benchmark for 6D Object Pose Estimation
Aug 24, 2018
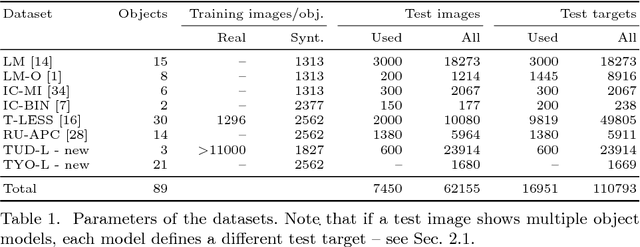

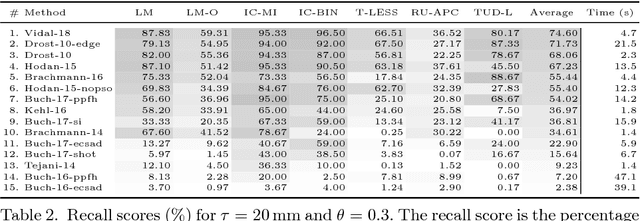
We propose a benchmark for 6D pose estimation of a rigid object from a single RGB-D input image. The training data consists of a texture-mapped 3D object model or images of the object in known 6D poses. The benchmark comprises of: i) eight datasets in a unified format that cover different practical scenarios, including two new datasets focusing on varying lighting conditions, ii) an evaluation methodology with a pose-error function that deals with pose ambiguities, iii) a comprehensive evaluation of 15 diverse recent methods that captures the status quo of the field, and iv) an online evaluation system that is open for continuous submission of new results. The evaluation shows that methods based on point-pair features currently perform best, outperforming template matching methods, learning-based methods and methods based on 3D local features. The project website is available at bop.felk.cvut.cz.