 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrion: A Unified Visual Agent for Multimodal Perception, Advanced Visual Reasoning and Execution
Nov 18, 2025We introduce Orion, a visual agent framework that can take in any modality and generate any modality. Using an agentic framework with multiple tool-calling capabilities, Orion is designed for visual AI tasks and achieves state-of-the-art results. Unlike traditional vision-language models that produce descriptive outputs, Orion orchestrates a suite of specialized computer vision tools, including object detection, keypoint localization, panoptic segmentation, Optical Character Recognition, and geometric analysis, to execute complex multi-step visual workflows. The system achieves competitive performance on MMMU, MMBench, DocVQA, and MMLongBench while extending monolithic vision-language models to production-grade visual intelligence. By combining neural perception with symbolic execution, Orion enables autonomous visual reasoning, marking a transition from passive visual understanding to active, tool-driven visual intelligence.
PillarFlow: End-to-end Birds-eye-view Flow Estimation for Autonomous Driving
Aug 29, 2020
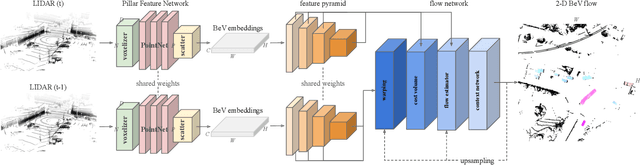

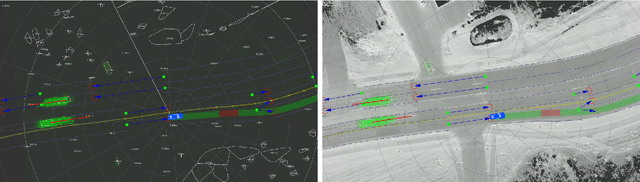
In autonomous driving, accurately estimating the state of surrounding obstacles is critical for safe and robust path planning. However, this perception task is difficult, particularly for generic obstacles/objects, due to appearance and occlusion changes. To tackle this problem, we propose an end-to-end deep learning framework for LIDAR-based flow estimation in bird's eye view (BeV). Our method takes consecutive point cloud pairs as input and produces a 2-D BeV flow grid describing the dynamic state of each cell. The experimental results show that the proposed method not only estimates 2-D BeV flow accurately but also improves tracking performance of both dynamic and static objects.
Neural Ray Surfaces for Self-Supervised Learning of Depth and Ego-motion
Aug 15, 2020
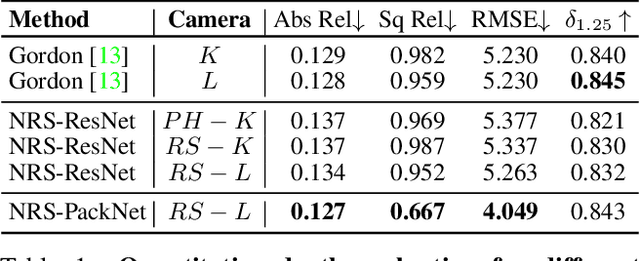
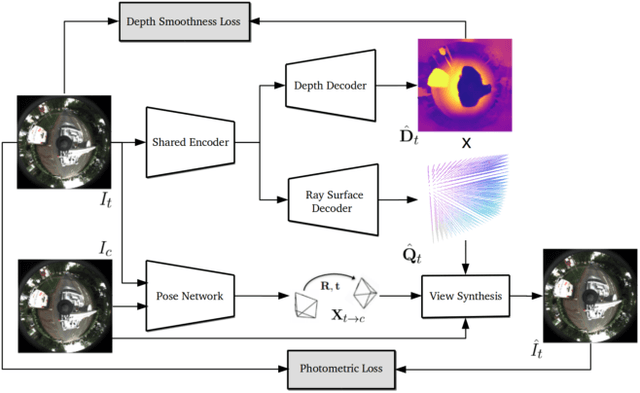

Self-supervised learning has emerged as a powerful tool for depth and ego-motion estimation, leading to state-of-the-art results on benchmark datasets. However, one significant limitation shared by current methods is the assumption of a known parametric camera model -- usually the standard pinhole geometry -- leading to failure when applied to imaging systems that deviate significantly from this assumption (e.g., catadioptric cameras or underwater imaging). In this work, we show that self-supervision can be used to learn accurate depth and ego-motion estimation without prior knowledge of the camera model. Inspired by the geometric model of Grossberg and Nayar, we introduce Neural Ray Surfaces (NRS), convolutional networks that represent pixel-wise projection rays, approximating a wide range of cameras. NRS are fully differentiable and can be learned end-to-end from unlabeled raw videos. We demonstrate the use of NRS for self-supervised learning of visual odometry and depth estimation from raw videos obtained using a wide variety of camera systems, including pinhole, fisheye, and catadioptric.
Neural Outlier Rejection for Self-Supervised Keypoint Learning
Dec 23, 2019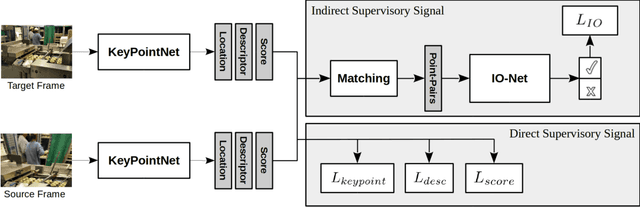
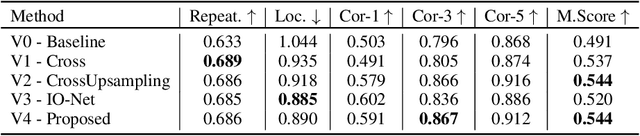
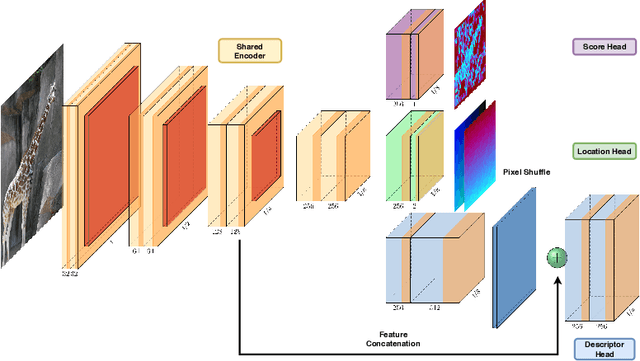
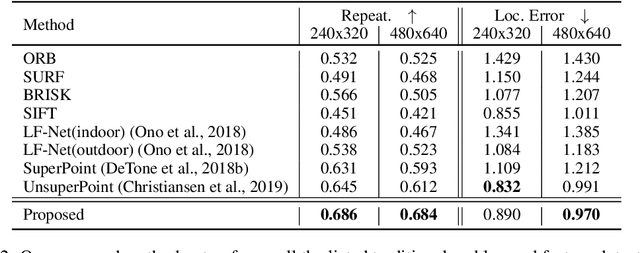
Identifying salient points in images is a crucial component for visual odometry, Structure-from-Motion or SLAM algorithms. Recently, several learned keypoint methods have demonstrated compelling performance on challenging benchmarks. However, generating consistent and accurate training data for interest-point detection in natural images still remains challenging, especially for human annotators. We introduce IO-Net (i.e. InlierOutlierNet), a novel proxy task for the self-supervision of keypoint detection, description and matching. By making the sampling of inlier-outlier sets from point-pair correspondences fully differentiable within the keypoint learning framework, we show that are able to simultaneously self-supervise keypoint description and improve keypoint matching. Second, we introduce KeyPointNet, a keypoint-network architecture that is especially amenable to robust keypoint detection and description. We design the network to allow local keypoint aggregation to avoid artifacts due to spatial discretizations commonly used for this task, and we improve fine-grained keypoint descriptor performance by taking advantage of efficient sub-pixel convolutions to upsample the descriptor feature-maps to a higher operating resolution. Through extensive experiments and ablative analysis, we show that the proposed self-supervised keypoint learning method greatly improves the quality of feature matching and homography estimation on challenging benchmarks over the state-of-the-art.
Self-Supervised 3D Keypoint Learning for Ego-motion Estimation
Dec 07, 2019
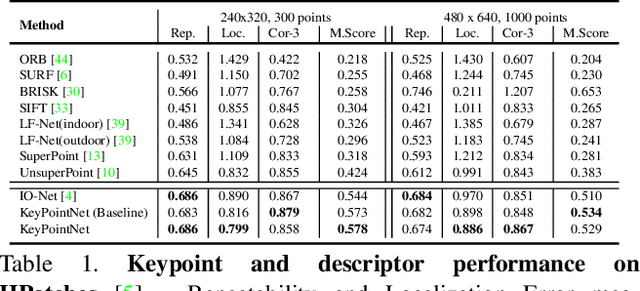
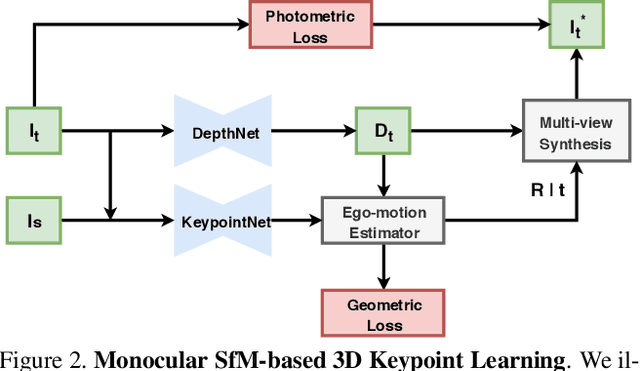

Generating reliable illumination and viewpoint invariant keypoints is critical for feature-based SLAM and SfM. State-of-the-art learning-based methods often rely on generating training samples by employing homography adaptation to create 2D synthetic views. While such approaches trivially solve data association between views, they cannot effectively learn from real illumination and non-planar 3D scenes. In this work, we propose a fully self-supervised approach towards learning depth-aware keypoints \textit{purely} from unlabeled videos by incorporating a differentiable pose estimation module that jointly optimizes the keypoints and their depths in a Structure-from-Motion setting. We introduce 3D Multi-View Adaptation, a technique that exploits the temporal context in videos to self-supervise keypoint detection and matching in an end-to-end differentiable manner. Finally, we show how a fully self-supervised keypoint detection and description network can be trivially incorporated as a front-end into a state-of-the-art visual odometry framework that is robust and accurate.
Robust Semi-Supervised Monocular Depth Estimation with Reprojected Distances
Oct 23, 2019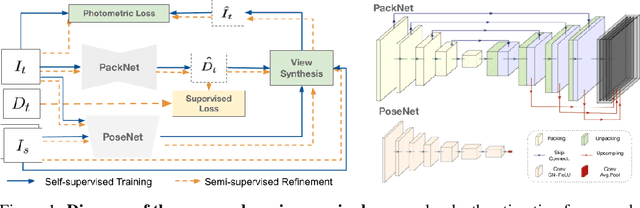
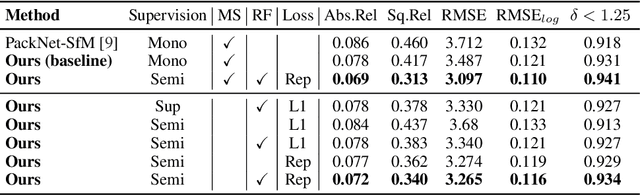
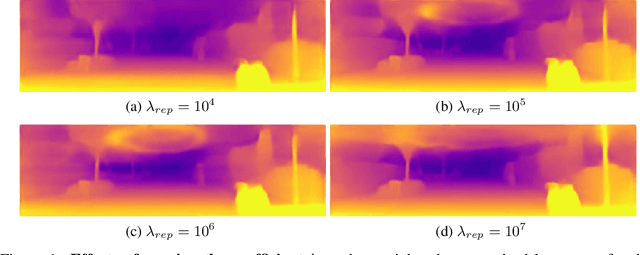
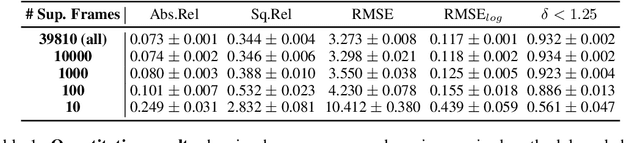
Dense depth estimation from a single image is a key problem in computer vision, with exciting applications in a multitude of robotic tasks. Initially viewed as a direct regression problem, requiring annotated labels as supervision at training time, in the past few years a substantial amount of work has been done in self-supervised depth training based on strong geometric cues, both from stereo cameras and more recently from monocular video sequences. In this paper we investigate how these two approaches (supervised & self-supervised) can be effectively combined, so that a depth model can learn to encode true scale from sparse supervision while achieving high fidelity local accuracy by leveraging geometric cues. To this end, we propose a novel supervised loss term that complements the widely used photometric loss, and show how it can be used to train robust semi-supervised monocular depth estimation models. Furthermore, we evaluate how much supervision is actually necessary to train accurate scale-aware monocular depth models, showing that with our proposed framework, very sparse LiDAR information, with as few as 4 beams (less than 100 valid depth values per image), is enough to achieve results competitive with the current state-of-the-art.
Two Stream Networks for Self-Supervised Ego-Motion Estimation
Oct 23, 2019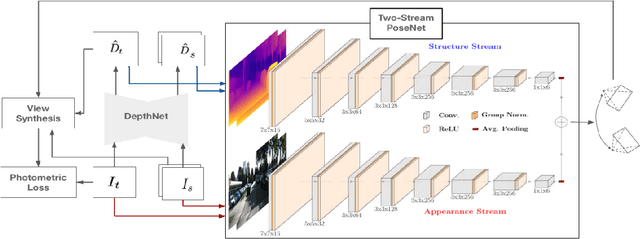
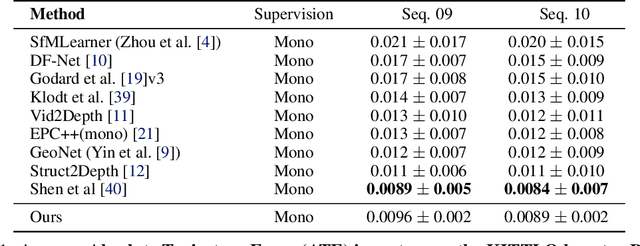

Learning depth and camera ego-motion from raw unlabeled RGB video streams is seeing exciting progress through self-supervision from strong geometric cues. To leverage not only appearance but also scene geometry, we propose a novel self-supervised two-stream network using RGB and inferred depth information for accurate visual odometry. In addition, we introduce a sparsity-inducing data augmentation policy for ego-motion learning that effectively regularizes the pose network to enable stronger generalization performance. As a result, we show that our proposed two-stream pose network achieves state-of-the-art results among learning-based methods on the KITTI odometry benchmark, and is especially suited for self-supervision at scale. Our experiments on a large-scale urban driving dataset of 1 million frames indicate that the performance of our proposed architecture does indeed scale progressively with more data.
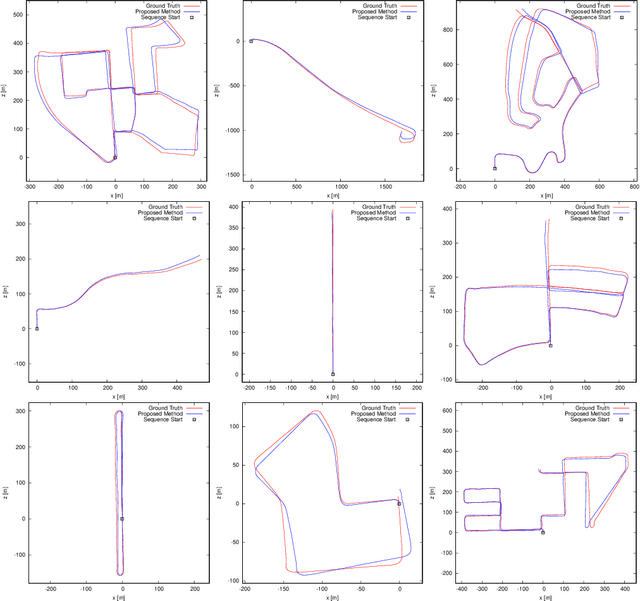
Self-Supervised Visual Place Recognition Learning in Mobile Robots
May 11, 2019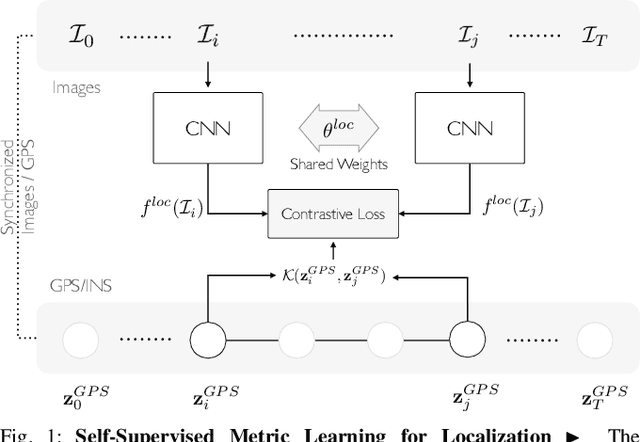

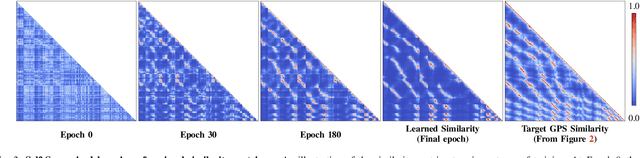
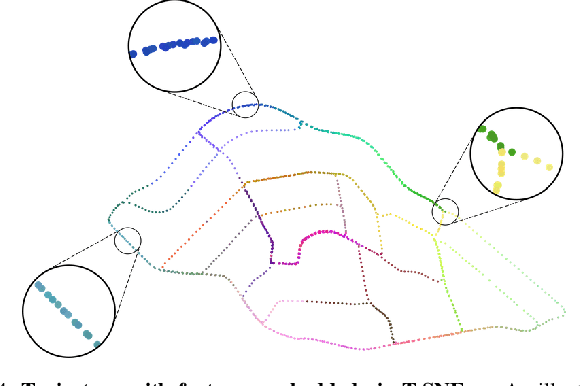
Place recognition is a critical component in robot navigation that enables it to re-establish previously visited locations, and simultaneously use this information to correct the drift incurred in its dead-reckoned estimate. In this work, we develop a self-supervised approach to place recognition in robots. The task of visual loop-closure identification is cast as a metric learning problem, where the labels for positive and negative examples of loop-closures can be bootstrapped using a GPS-aided navigation solution that the robot already uses. By leveraging the synchronization between sensors, we show that we are able to learn an appropriate distance metric for arbitrary real-valued image descriptors (including state-of-the-art CNN models), that is specifically geared for visual place recognition in mobile robots. Furthermore, we show that the newly learned embedding can be particularly powerful in disambiguating visual scenes for the task of vision-based loop-closure identification in mobile robots.
PackNet-SfM: 3D Packing for Self-Supervised Monocular Depth Estimation
May 06, 2019
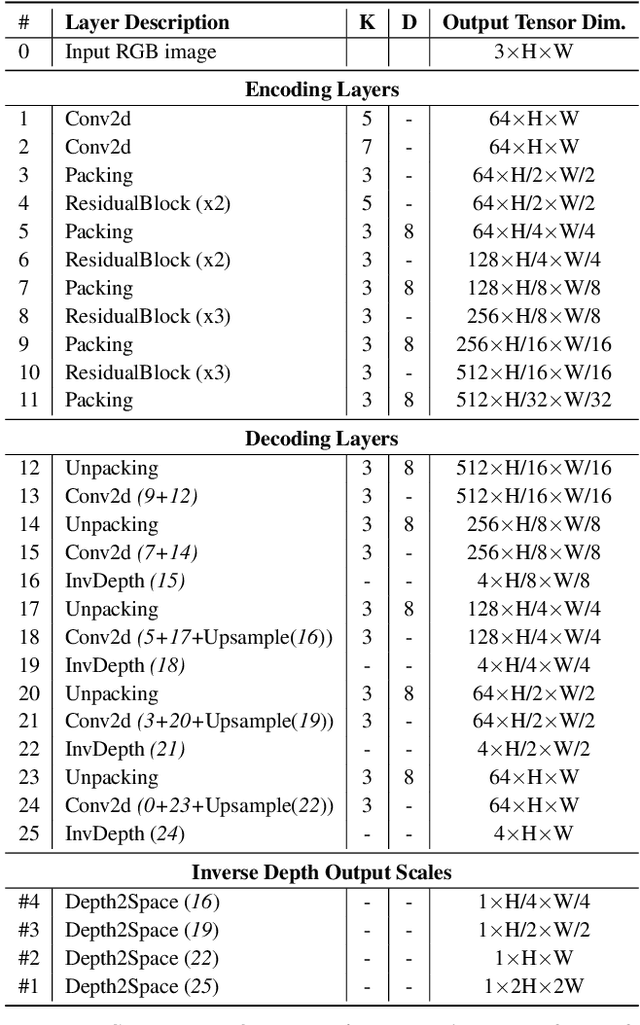
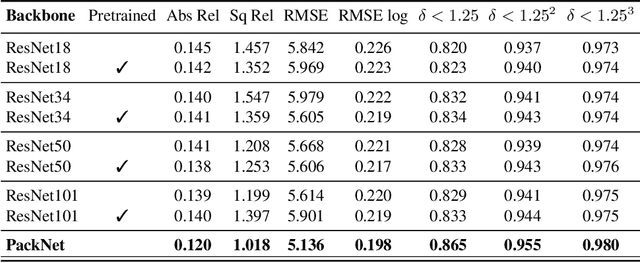
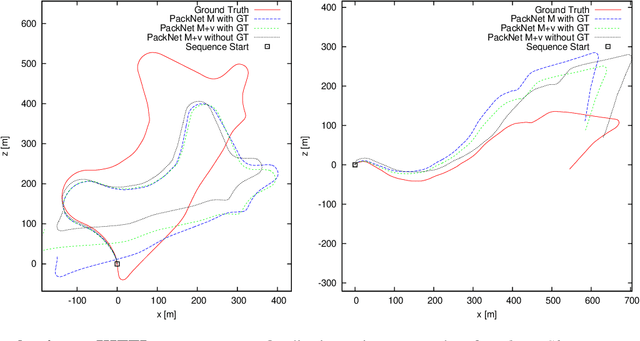
Densely estimating the depth of a scene from a single image is an ill-posed inverse problem that is seeing exciting progress with self-supervision from strong geometric cues, in particular from training using stereo imagery. In this work, we investigate the more challenging structure-from-motion (SfM) setting, learning purely from monocular videos. We propose PackNet - a novel deep architecture that leverages new 3D packing and unpacking blocks to effectively capture fine details in monocular depth map predictions. Additionally, we propose a novel velocity supervision loss that allows our model to predict metrically accurate depths, thus alleviating the need for test-time ground-truth scaling. We show that our proposed scale-aware architecture achieves state-of-the-art results on the KITTI benchmark, significantly improving upon any approach trained on monocular video, and even achieves competitive performance to stereo-trained methods.
SuperDepth: Self-Supervised, Super-Resolved Monocular Depth Estimation
Oct 03, 2018
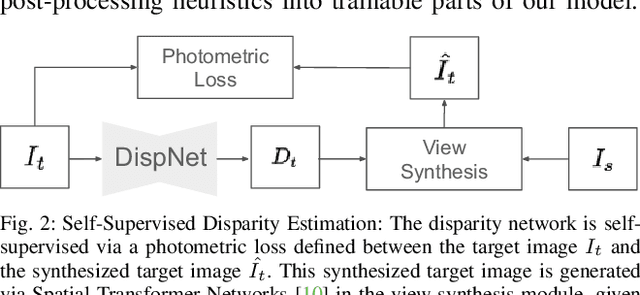
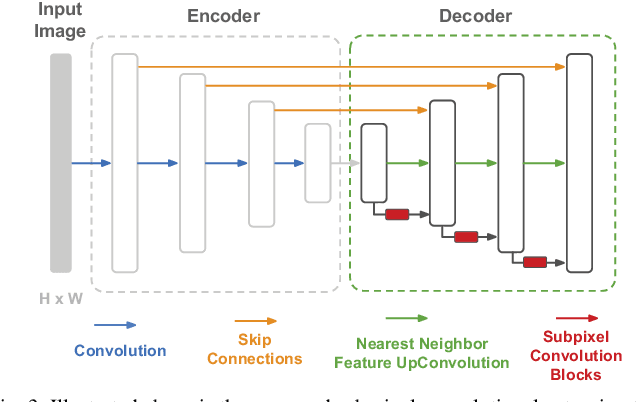
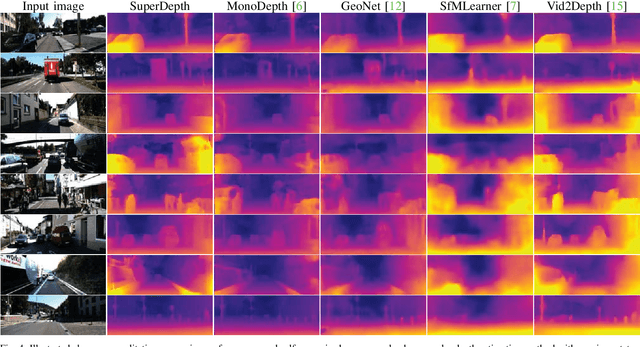
Recent techniques in self-supervised monocular depth estimation are approaching the performance of supervised methods, but operate in low resolution only. We show that high resolution is key towards high-fidelity self-supervised monocular depth prediction. Inspired by recent deep learning methods for Single-Image Super-Resolution, we propose a sub-pixel convolutional layer extension for depth super-resolution that accurately synthesizes high-resolution disparities from their corresponding low-resolution convolutional features. In addition, we introduce a differentiable flip-augmentation layer that accurately fuses predictions from the image and its horizontally flipped version, reducing the effect of left and right shadow regions generated in the disparity map due to occlusions. Both contributions provide significant performance gains over the state-of-the-art in self-supervised depth and pose estimation on the public KITTI benchmark. A video of our approach can be found at https://youtu.be/jKNgBeBMx0I.