 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkillBlender: Towards Versatile Humanoid Whole-Body Loco-Manipulation via Skill Blending
Jun 11, 2025Humanoid robots hold significant potential in accomplishing daily tasks across diverse environments thanks to their flexibility and human-like morphology. Recent works have made significant progress in humanoid whole-body control and loco-manipulation leveraging optimal control or reinforcement learning. However, these methods require tedious task-specific tuning for each task to achieve satisfactory behaviors, limiting their versatility and scalability to diverse tasks in daily scenarios. To that end, we introduce SkillBlender, a novel hierarchical reinforcement learning framework for versatile humanoid loco-manipulation. SkillBlender first pretrains goal-conditioned task-agnostic primitive skills, and then dynamically blends these skills to accomplish complex loco-manipulation tasks with minimal task-specific reward engineering. We also introduce SkillBench, a parallel, cross-embodiment, and diverse simulated benchmark containing three embodiments, four primitive skills, and eight challenging loco-manipulation tasks, accompanied by a set of scientific evaluation metrics balancing accuracy and feasibility. Extensive simulated experiments show that our method significantly outperforms all baselines, while naturally regularizing behaviors to avoid reward hacking, resulting in more accurate and feasible movements for diverse loco-manipulation tasks in our daily scenarios. Our code and benchmark will be open-sourced to the community to facilitate future research. Project page: https://usc-gvl.github.io/SkillBlender-web/.
Scan, Materialize, Simulate: A Generalizable Framework for Physically Grounded Robot Planning
May 20, 2025



Autonomous robots must reason about the physical consequences of their actions to operate effectively in unstructured, real-world environments. We present Scan, Materialize, Simulate (SMS), a unified framework that combines 3D Gaussian Splatting for accurate scene reconstruction, visual foundation models for semantic segmentation, vision-language models for material property inference, and physics simulation for reliable prediction of action outcomes. By integrating these components, SMS enables generalizable physical reasoning and object-centric planning without the need to re-learn foundational physical dynamics. We empirically validate SMS in a billiards-inspired manipulation task and a challenging quadrotor landing scenario, demonstrating robust performance on both simulated domain transfer and real-world experiments. Our results highlight the potential of bridging differentiable rendering for scene reconstruction, foundation models for semantic understanding, and physics-based simulation to achieve physically grounded robot planning across diverse settings.
Vision Foundation Model Embedding-Based Semantic Anomaly Detection
May 12, 2025



Semantic anomalies are contextually invalid or unusual combinations of familiar visual elements that can cause undefined behavior and failures in system-level reasoning for autonomous systems. This work explores semantic anomaly detection by leveraging the semantic priors of state-of-the-art vision foundation models, operating directly on the image. We propose a framework that compares local vision embeddings from runtime images to a database of nominal scenarios in which the autonomous system is deemed safe and performant. In this work, we consider two variants of the proposed framework: one using raw grid-based embeddings, and another leveraging instance segmentation for object-centric representations. To further improve robustness, we introduce a simple filtering mechanism to suppress false positives. Our evaluations on CARLA-simulated anomalies show that the instance-based method with filtering achieves performance comparable to GPT-4o, while providing precise anomaly localization. These results highlight the potential utility of vision embeddings from foundation models for real-time anomaly detection in autonomous systems.
Adapting a Foundation Model for Space-based Tasks
Aug 12, 2024



Foundation models, e.g., large language models, possess attributes of intelligence which offer promise to endow a robot with the contextual understanding necessary to navigate complex, unstructured tasks in the wild. In the future of space robotics, we see three core challenges which motivate the use of a foundation model adapted to space-based applications: 1) Scalability of ground-in-the-loop operations; 2) Generalizing prior knowledge to novel environments; and 3) Multi-modality in tasks and sensor data. Therefore, as a first-step towards building a foundation model for space-based applications, we automatically label the AI4Mars dataset to curate a language annotated dataset of visual-question-answer tuples. We fine-tune a pretrained LLaVA checkpoint on this dataset to endow a vision-language model with the ability to perform spatial reasoning and navigation on Mars' surface. In this work, we demonstrate that 1) existing vision-language models are deficient visual reasoners in space-based applications, and 2) fine-tuning a vision-language model on extraterrestrial data significantly improves the quality of responses even with a limited training dataset of only a few thousand samples.
Real-Time Anomaly Detection and Reactive Planning with Large Language Models
Jul 11, 2024



Foundation models, e.g., large language models (LLMs), trained on internet-scale data possess zero-shot generalization capabilities that make them a promising technology towards detecting and mitigating out-of-distribution failure modes of robotic systems. Fully realizing this promise, however, poses two challenges: (i) mitigating the considerable computational expense of these models such that they may be applied online, and (ii) incorporating their judgement regarding potential anomalies into a safe control framework. In this work, we present a two-stage reasoning framework: First is a fast binary anomaly classifier that analyzes observations in an LLM embedding space, which may then trigger a slower fallback selection stage that utilizes the reasoning capabilities of generative LLMs. These stages correspond to branch points in a model predictive control strategy that maintains the joint feasibility of continuing along various fallback plans to account for the slow reasoner's latency as soon as an anomaly is detected, thus ensuring safety. We show that our fast anomaly classifier outperforms autoregressive reasoning with state-of-the-art GPT models, even when instantiated with relatively small language models. This enables our runtime monitor to improve the trustworthiness of dynamic robotic systems, such as quadrotors or autonomous vehicles, under resource and time constraints. Videos illustrating our approach in both simulation and real-world experiments are available on this project page: https://sites.google.com/view/aesop-llm.
Semantic Anomaly Detection with Large Language Models
May 18, 2023As robots acquire increasingly sophisticated skills and see increasingly complex and varied environments, the threat of an edge case or anomalous failure is ever present. For example, Tesla cars have seen interesting failure modes ranging from autopilot disengagements due to inactive traffic lights carried by trucks to phantom braking caused by images of stop signs on roadside billboards. These system-level failures are not due to failures of any individual component of the autonomy stack but rather system-level deficiencies in semantic reasoning. Such edge cases, which we call \textit{semantic anomalies}, are simple for a human to disentangle yet require insightful reasoning. To this end, we study the application of large language models (LLMs), endowed with broad contextual understanding and reasoning capabilities, to recognize these edge semantic cases. We introduce a monitoring framework for semantic anomaly detection in vision-based policies to do so. Our experiments evaluate this framework in monitoring a learned policy for object manipulation and a finite state machine policy for autonomous driving and demonstrate that an LLM-based monitor can serve as a proxy for human reasoning. Finally, we provide an extended discussion on the strengths and weaknesses of this approach and motivate a research outlook on how we can further use foundation models for semantic anomaly detection.
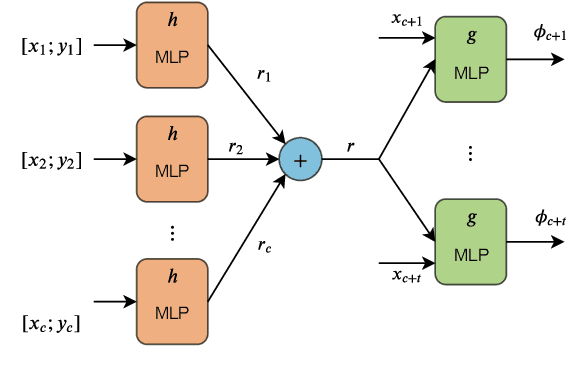
MATS: An Interpretable Trajectory Forecasting Representation for Planning and Control
Sep 16, 2020

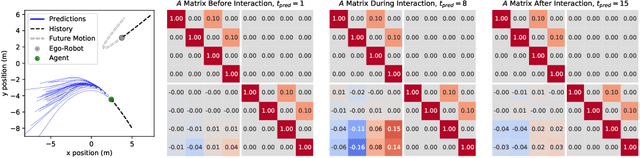
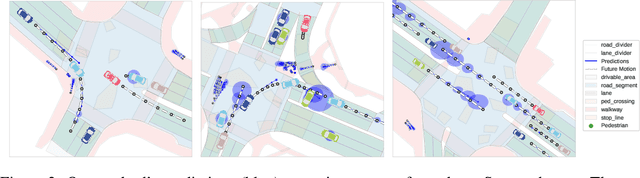
Reasoning about human motion is a core component of modern human-robot interactive systems. In particular, one of the main uses of behavior prediction in autonomous systems is to inform ego-robot motion planning and control. However, a majority of planning and control algorithms reason about system dynamics rather than the predicted agent tracklets that are commonly output by trajectory forecasting methods, which can hinder their integration. Towards this end, we propose Mixtures of Affine Time-varying Systems (MATS) as an output representation for trajectory forecasting that is more amenable to downstream planning and control use. Our approach leverages successful ideas from probabilistic trajectory forecasting works to learn dynamical system representations that are well-studied in the planning and control literature. We integrate our predictions with a proposed multimodal planning methodology and demonstrate significant computational efficiency improvements on a large-scale autonomous driving dataset.
Map-Predictive Motion Planning in Unknown Environments
Oct 17, 2019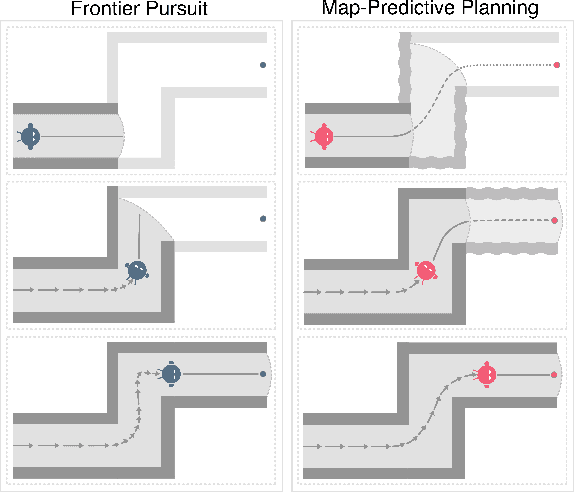
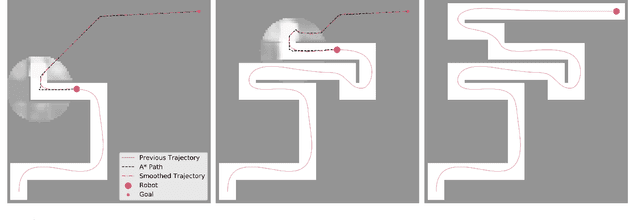
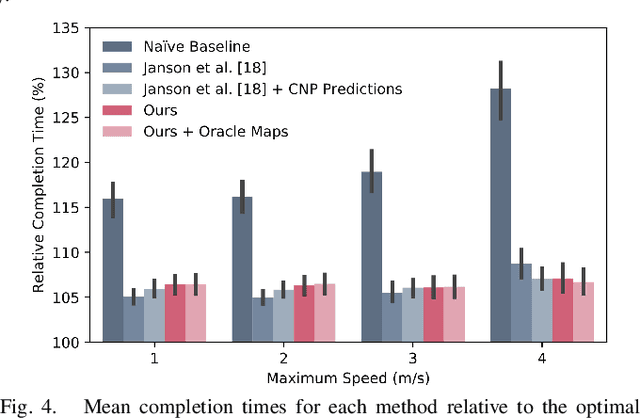
Algorithms for motion planning in unknown environments are generally limited in their ability to reason about the structure of the unobserved environment. As such, current methods generally navigate unknown environments by relying on heuristic methods to choose intermediate objectives along frontiers. We present a unified method that combines map prediction and motion planning for safe, time-efficient autonomous navigation of unknown environments by dynamically-constrained robots. We propose a data-driven method for predicting the map of the unobserved environment, using the robot's observations of its surroundings as context. These map predictions are then used to plan trajectories from the robot's position to the goal without requiring frontier selection. We demonstrate that our map-predictive motion planning strategy yields a substantial improvement in trajectory time over a naive frontier pursuit method and demonstrates similar performance to methods using more sophisticated frontier selection heuristics with significantly shorter computation time.
Network Offloading Policies for Cloud Robotics: a Learning-based Approach
Feb 15, 2019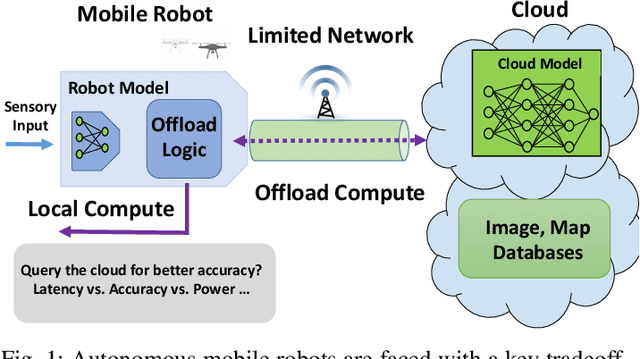
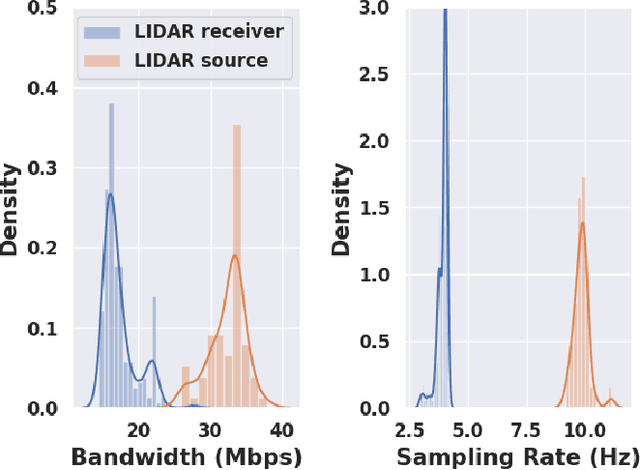
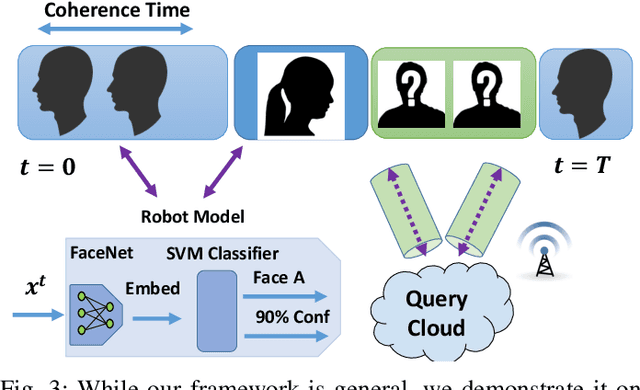
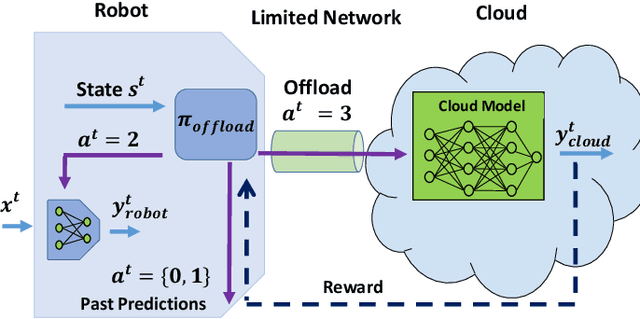
Today's robotic systems are increasingly turning to computationally expensive models such as deep neural networks (DNNs) for tasks like localization, perception, planning, and object detection. However, resource-constrained robots, like low-power drones, often have insufficient on-board compute resources or power reserves to scalably run the most accurate, state-of-the art neural network compute models. Cloud robotics allows mobile robots the benefit of offloading compute to centralized servers if they are uncertain locally or want to run more accurate, compute-intensive models. However, cloud robotics comes with a key, often understated cost: communicating with the cloud over congested wireless networks may result in latency or loss of data. In fact, sending high data-rate video or LIDAR from multiple robots over congested networks can lead to prohibitive delay for real-time applications, which we measure experimentally. In this paper, we formulate a novel Robot Offloading Problem --- how and when should robots offload sensing tasks, especially if they are uncertain, to improve accuracy while minimizing the cost of cloud communication? We formulate offloading as a sequential decision making problem for robots, and propose a solution using deep reinforcement learning. In both simulations and hardware experiments using state-of-the art vision DNNs, our offloading strategy improves vision task performance by between 1.3-2.6x of benchmark offloading strategies, allowing robots the potential to significantly transcend their on-board sensing accuracy but with limited cost of cloud communication.