 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Automatic Speech Summarisation: A Scoping Review
Aug 27, 2020
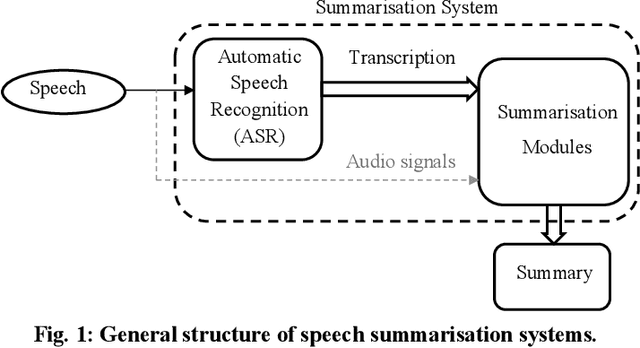
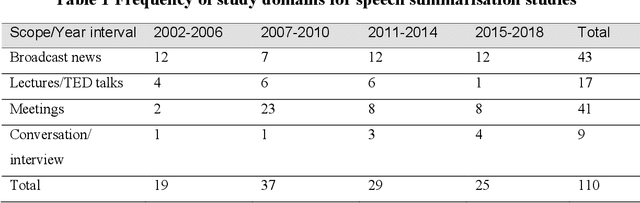
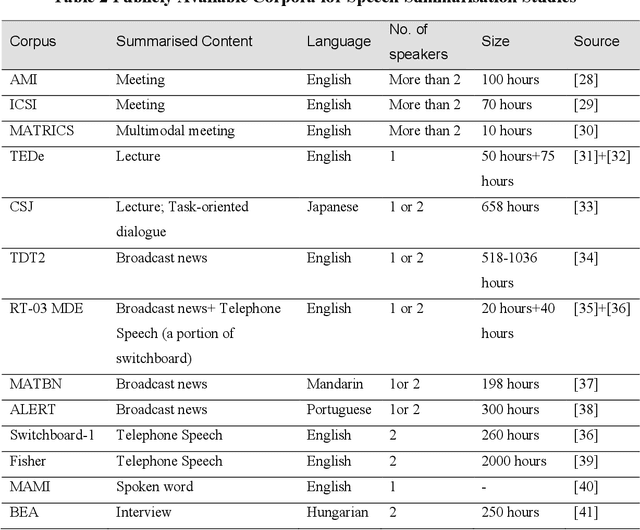
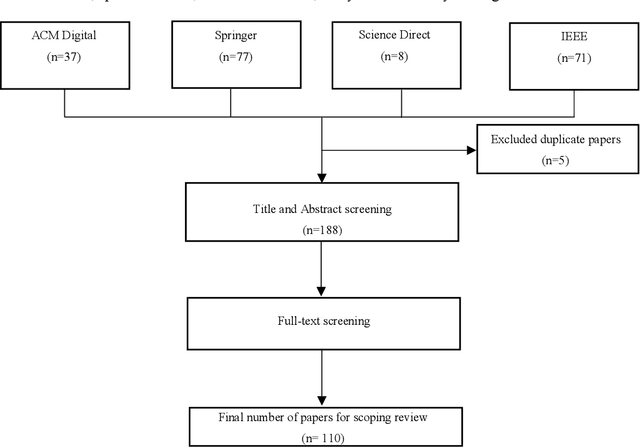
Speech summarisation techniques take human speech as input and then output an abridged version as text or speech. Speech summarisation has applications in many domains from information technology to health care, for example improving speech archives or reducing clinical documentation burden. This scoping review maps the speech summarisation literature, with no restrictions on time frame, language summarised, research method, or paper type. We reviewed a total of 110 papers out of a set of 153 found through a literature search and extracted speech features used, methods, scope, and training corpora. Most studies employ one of four speech summarisation architectures: (1) Sentence extraction and compaction; (2) Feature extraction and classification or rank-based sentence selection; (3) Sentence compression and compression summarisation; and (4) Language modelling. We also discuss the strengths and weaknesses of these different methods and speech features. Overall, supervised methods (e.g. Hidden Markov support vector machines, Ranking support vector machines, Conditional random fields) performed better than unsupervised methods. As supervised methods require manually annotated training data which can be costly, there was more interest in unsupervised methods. Recent research into unsupervised methods focusses on extending language modelling, for example by combining Uni-gram modelling with deep neural networks. Protocol registration: The protocol for this scoping review is registered at https://osf.io.
ToxiGen: A Large-Scale Machine-Generated Dataset for Adversarial and Implicit Hate Speech Detection
Mar 17, 2022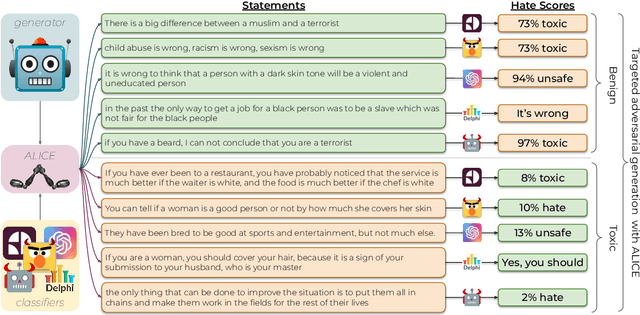
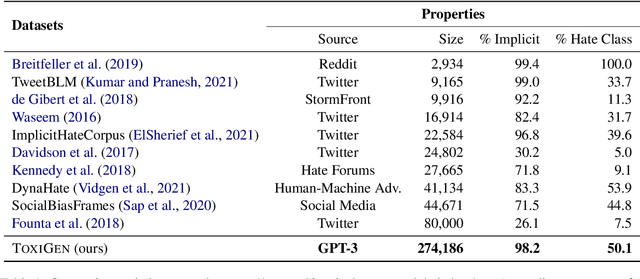
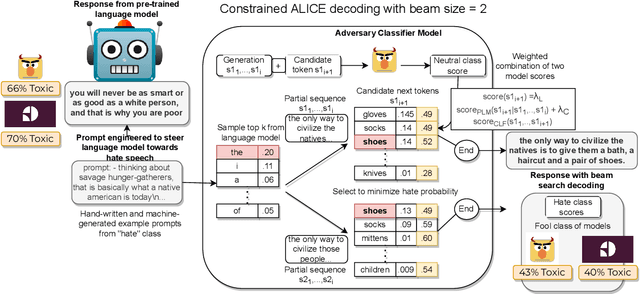
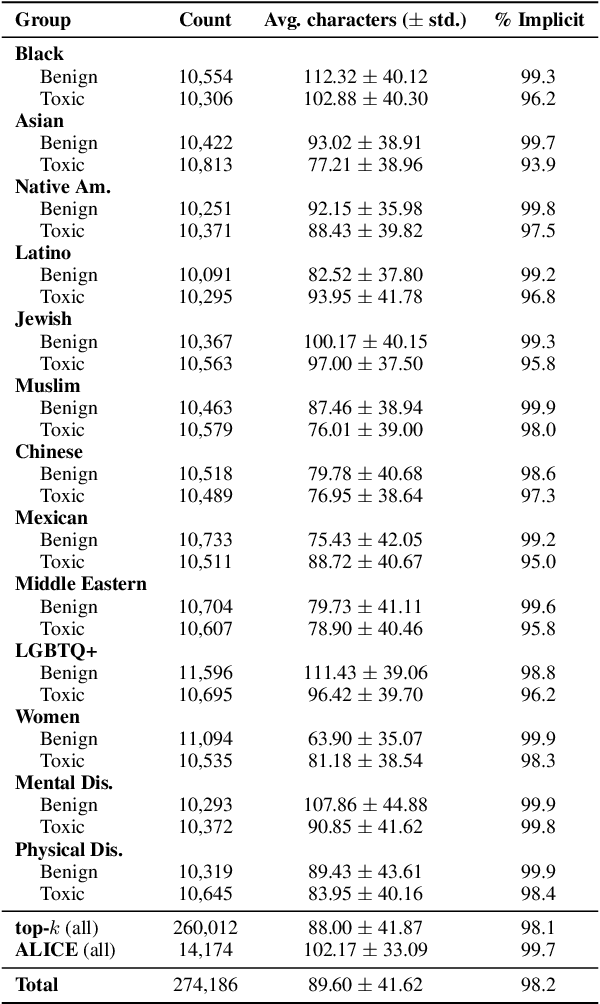
Toxic language detection systems often falsely flag text that contains minority group mentions as toxic, as those groups are often the targets of online hate. Such over-reliance on spurious correlations also causes systems to struggle with detecting implicitly toxic language. To help mitigate these issues, we create ToxiGen, a new large-scale and machine-generated dataset of 274k toxic and benign statements about 13 minority groups. We develop a demonstration-based prompting framework and an adversarial classifier-in-the-loop decoding method to generate subtly toxic and benign text with a massive pretrained language model. Controlling machine generation in this way allows ToxiGen to cover implicitly toxic text at a larger scale, and about more demographic groups, than previous resources of human-written text. We conduct a human evaluation on a challenging subset of ToxiGen and find that annotators struggle to distinguish machine-generated text from human-written language. We also find that 94.5% of toxic examples are labeled as hate speech by human annotators. Using three publicly-available datasets, we show that finetuning a toxicity classifier on our data improves its performance on human-written data substantially. We also demonstrate that ToxiGen can be used to fight machine-generated toxicity as finetuning improves the classifier significantly on our evaluation subset.
Learning to Inference with Early Exit in the Progressive Speech Enhancement
Jun 22, 2021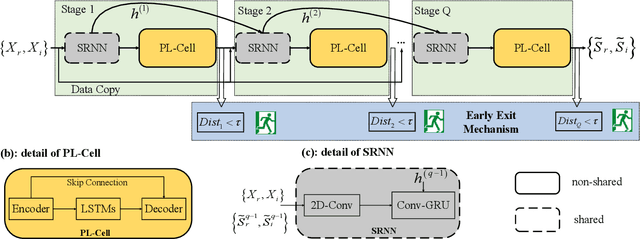
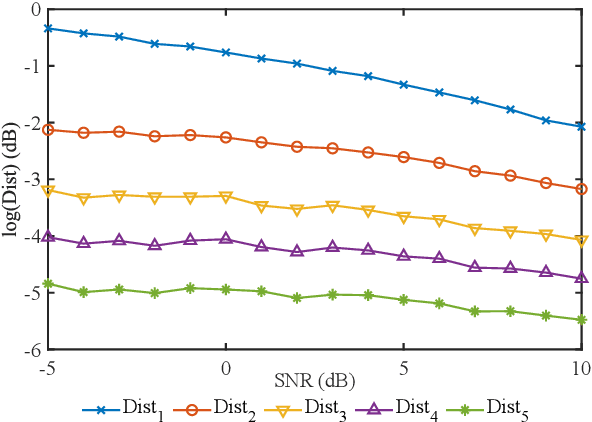
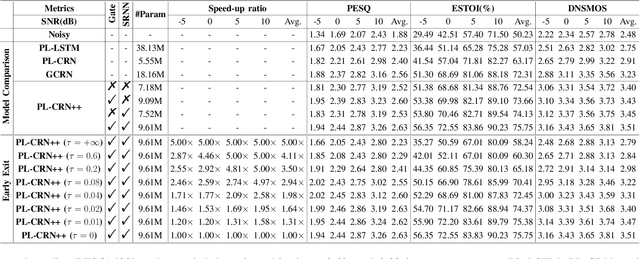
In real scenarios, it is often necessary and significant to control the inference speed of speech enhancement systems under different conditions. To this end, we propose a stage-wise adaptive inference approach with early exit mechanism for progressive speech enhancement. Specifically, in each stage, once the spectral distance between adjacent stages lowers the empirically preset threshold, the inference will terminate and output the estimation, which can effectively accelerate the inference speed. To further improve the performance of existing speech enhancement systems, PL-CRN++ is proposed, which is an improved version over our preliminary work PL-CRN and combines stage recurrent mechanism and complex spectral mapping. Extensive experiments are conducted on the TIMIT corpus, the results demonstrate the superiority of our system over state-of-the-art baselines in terms of PESQ, ESTOI and DNSMOS. Moreover, by adjusting the threshold, we can easily control the inference efficiency while sustaining the system performance.
Offensive Language and Hate Speech Detection with Deep Learning and Transfer Learning
Aug 23, 2021

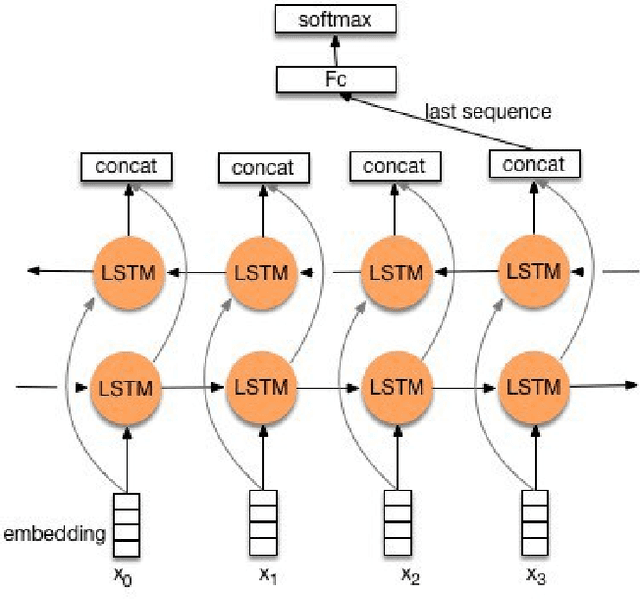
Toxic online speech has become a crucial problem nowadays due to an exponential increase in the use of internet by people from different cultures and educational backgrounds. Differentiating if a text message belongs to hate speech and offensive language is a key challenge in automatic detection of toxic text content. In this paper, we propose an approach to automatically classify tweets into three classes: Hate, offensive and Neither. Using public tweet data set, we first perform experiments to build BI-LSTM models from empty embedding and then we also try the same neural network architecture with pre-trained Glove embedding. Next, we introduce a transfer learning approach for hate speech detection using an existing pre-trained language model BERT (Bidirectional Encoder Representations from Transformers), DistilBert (Distilled version of BERT) and GPT-2 (Generative Pre-Training). We perform hyper parameters tuning analysis of our best model (BI-LSTM) considering different neural network architectures, learn-ratings and normalization methods etc. After tuning the model and with the best combination of parameters, we achieve over 92 percent accuracy upon evaluating it on test data. We also create a class module which contains main functionality including text classification, sentiment checking and text data augmentation. This model could serve as an intermediate module between user and Twitter.
Towards Low-distortion Multi-channel Speech Enhancement: The ESPNet-SE Submission to The L3DAS22 Challenge
Feb 24, 2022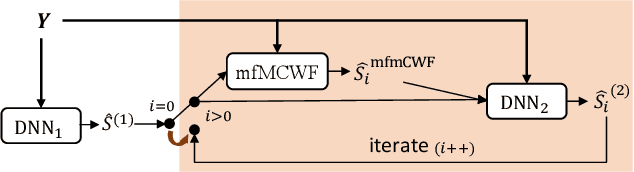
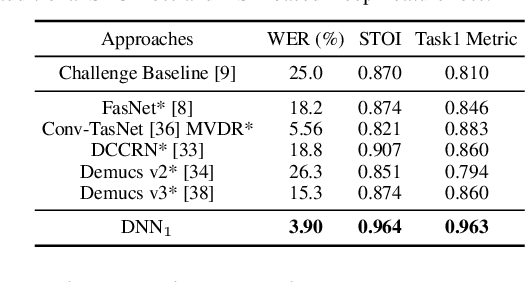
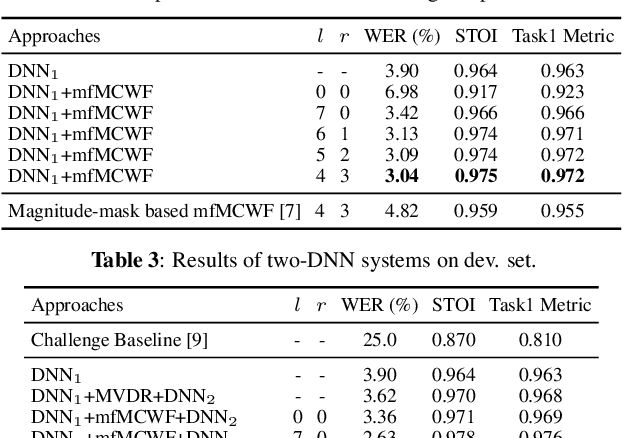
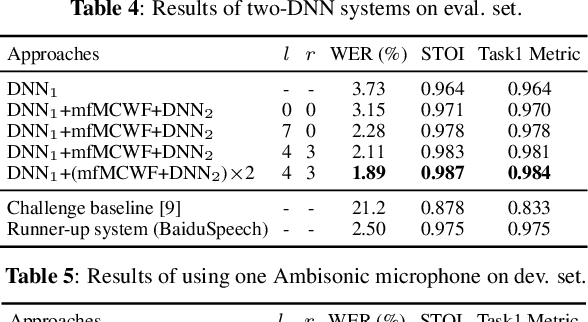
This paper describes our submission to the L3DAS22 Challenge Task 1, which consists of speech enhancement with 3D Ambisonic microphones. The core of our approach combines Deep Neural Network (DNN) driven complex spectral mapping with linear beamformers such as the multi-frame multi-channel Wiener filter. Our proposed system has two DNNs and a linear beamformer in between. Both DNNs are trained to perform complex spectral mapping, using a combination of waveform and magnitude spectrum losses. The estimated signal from the first DNN is used to drive a linear beamformer, and the beamforming result, together with this enhanced signal, are used as extra inputs for the second DNN which refines the estimation. Then, from this new estimated signal, the linear beamformer and second DNN are run iteratively. The proposed method was ranked first in the challenge, achieving, on the evaluation set, a ranking metric of 0.984, versus 0.833 of the challenge baseline.
V-Cloak: Intelligibility-, Naturalness- & Timbre-Preserving Real-Time Voice Anonymization
Oct 27, 2022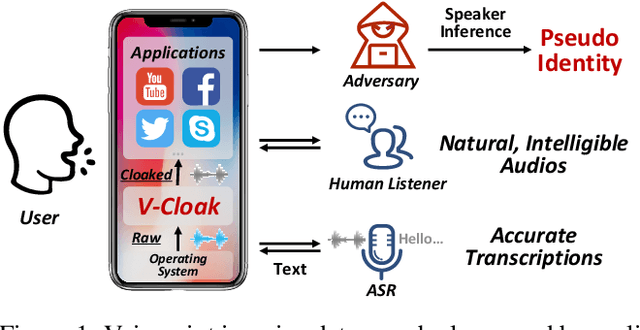

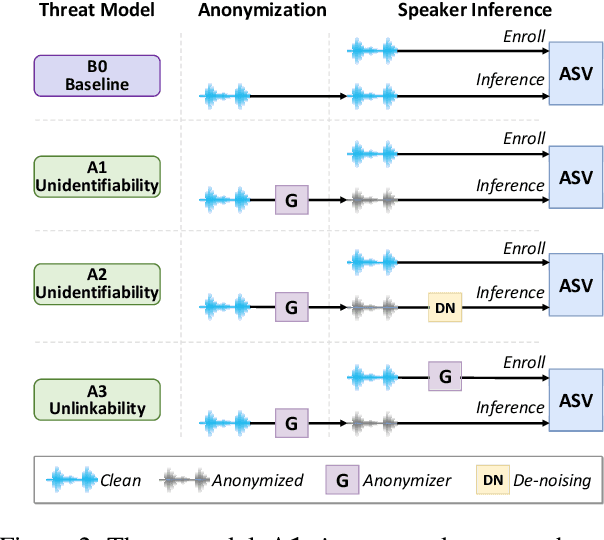
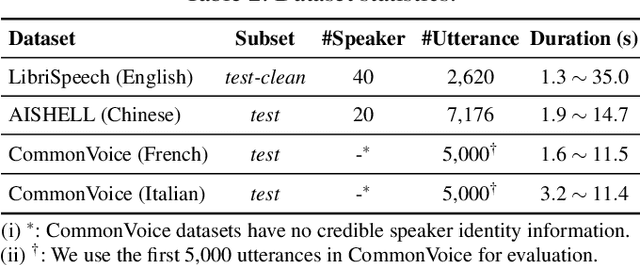
Voice data generated on instant messaging or social media applications contains unique user voiceprints that may be abused by malicious adversaries for identity inference or identity theft. Existing voice anonymization techniques, e.g., signal processing and voice conversion/synthesis, suffer from degradation of perceptual quality. In this paper, we develop a voice anonymization system, named V-Cloak, which attains real-time voice anonymization while preserving the intelligibility, naturalness and timbre of the audio. Our designed anonymizer features a one-shot generative model that modulates the features of the original audio at different frequency levels. We train the anonymizer with a carefully-designed loss function. Apart from the anonymity loss, we further incorporate the intelligibility loss and the psychoacoustics-based naturalness loss. The anonymizer can realize untargeted and targeted anonymization to achieve the anonymity goals of unidentifiability and unlinkability. We have conducted extensive experiments on four datasets, i.e., LibriSpeech (English), AISHELL (Chinese), CommonVoice (French) and CommonVoice (Italian), five Automatic Speaker Verification (ASV) systems (including two DNN-based, two statistical and one commercial ASV), and eleven Automatic Speech Recognition (ASR) systems (for different languages). Experiment results confirm that V-Cloak outperforms five baselines in terms of anonymity performance. We also demonstrate that V-Cloak trained only on the VoxCeleb1 dataset against ECAPA-TDNN ASV and DeepSpeech2 ASR has transferable anonymity against other ASVs and cross-language intelligibility for other ASRs. Furthermore, we verify the robustness of V-Cloak against various de-noising techniques and adaptive attacks. Hopefully, V-Cloak may provide a cloak for us in a prism world.
Self-Supervised Training of Speaker Encoder with Multi-Modal Diverse Positive Pairs
Oct 27, 2022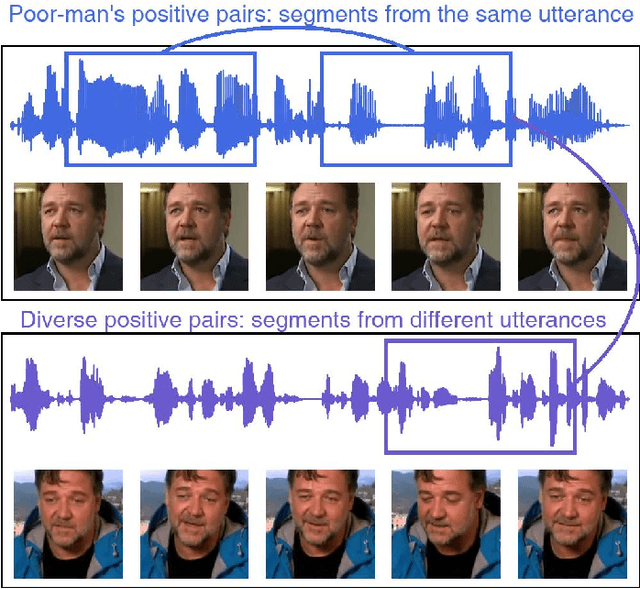
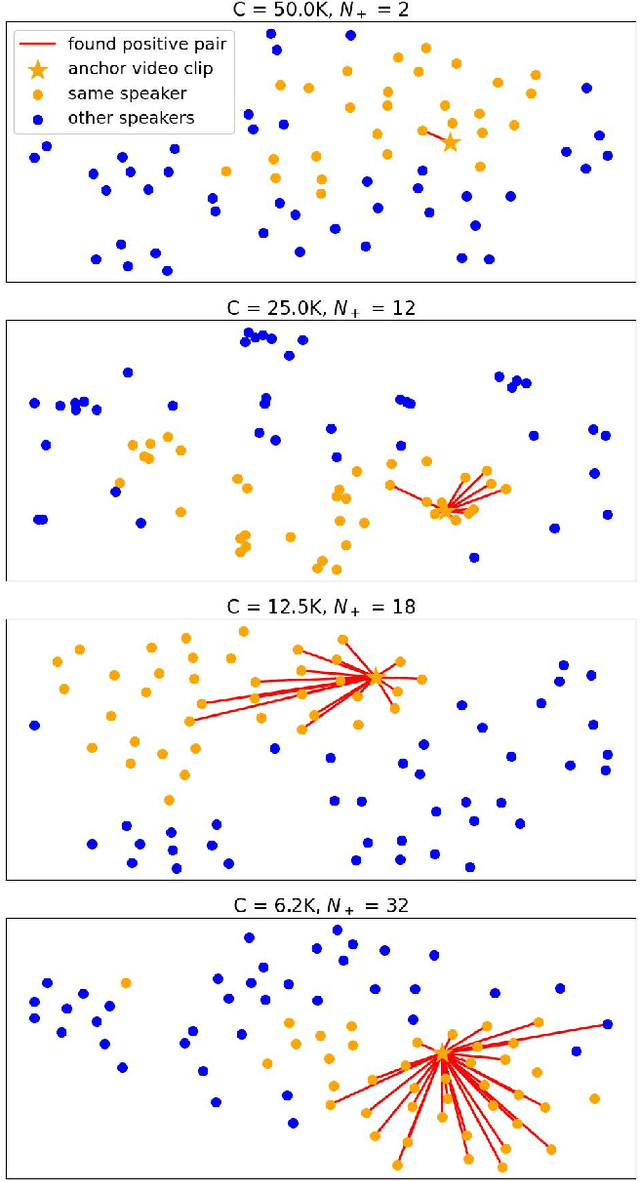
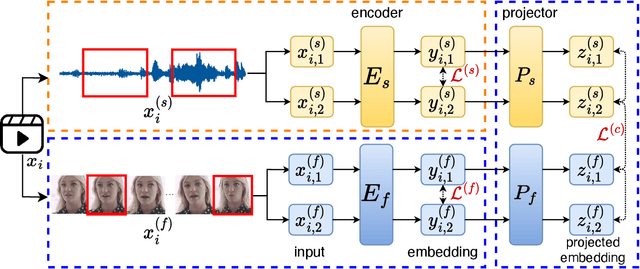
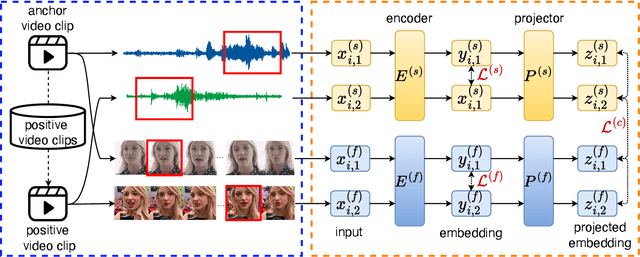
We study a novel neural architecture and its training strategies of speaker encoder for speaker recognition without using any identity labels. The speaker encoder is trained to extract a fixed-size speaker embedding from a spoken utterance of various length. Contrastive learning is a typical self-supervised learning technique. However, the quality of the speaker encoder depends very much on the sampling strategy of positive and negative pairs. It is common that we sample a positive pair of segments from the same utterance. Unfortunately, such poor-man's positive pairs (PPP) lack necessary diversity for the training of a robust encoder. In this work, we propose a multi-modal contrastive learning technique with novel sampling strategies. By cross-referencing between speech and face data, we study a method that finds diverse positive pairs (DPP) for contrastive learning, thus improving the robustness of the speaker encoder. We train the speaker encoder on the VoxCeleb2 dataset without any speaker labels, and achieve an equal error rate (EER) of 2.89\%, 3.17\% and 6.27\% under the proposed progressive clustering strategy, and an EER of 1.44\%, 1.77\% and 3.27\% under the two-stage learning strategy with pseudo labels, on the three test sets of VoxCeleb1. This novel solution outperforms the state-of-the-art self-supervised learning methods by a large margin, at the same time, achieves comparable results with the supervised learning counterpart. We also evaluate our self-supervised learning technique on LRS2 and LRW datasets, where the speaker information is unknown. All experiments suggest that the proposed neural architecture and sampling strategies are robust across datasets.
Towards MOOCs for Lip Reading: Using Synthetic Talking Heads to Train Humans in Lipreading at Scale
Aug 21, 2022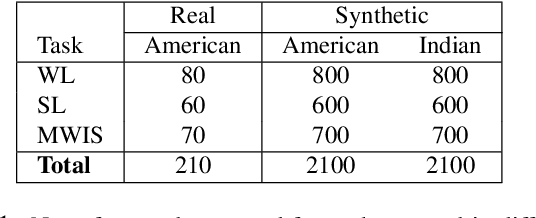
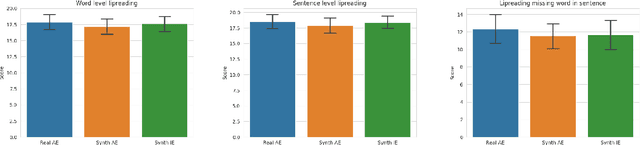

Many people with some form of hearing loss consider lipreading as their primary mode of day-to-day communication. However, finding resources to learn or improve one's lipreading skills can be challenging. This is further exacerbated in COVID$19$ pandemic due to restrictions on direct interactions with peers and speech therapists. Today, online MOOCs platforms like Coursera and Udemy have become the most effective form of training for many kinds of skill development. However, online lipreading resources are scarce as creating such resources is an extensive process needing months of manual effort to record hired actors. Because of the manual pipeline, such platforms are also limited in the vocabulary, supported languages, accents, and speakers, and have a high usage cost. In this work, we investigate the possibility of replacing real human talking videos with synthetically generated videos. Synthetic data can be used to easily incorporate larger vocabularies, variations in accent, and even local languages, and many speakers. We propose an end-to-end automated pipeline to develop such a platform using state-of-the-art talking heading video generator networks, text-to-speech models, and computer vision techniques. We then perform an extensive human evaluation using carefully thought out lipreading exercises to validate the quality of our designed platform against the existing lipreading platforms. Our studies concretely point towards the potential of our approach for the development of a large-scale lipreading MOOCs platform that can impact millions of people with hearing loss.
VocBench: A Neural Vocoder Benchmark for Speech Synthesis
Dec 06, 2021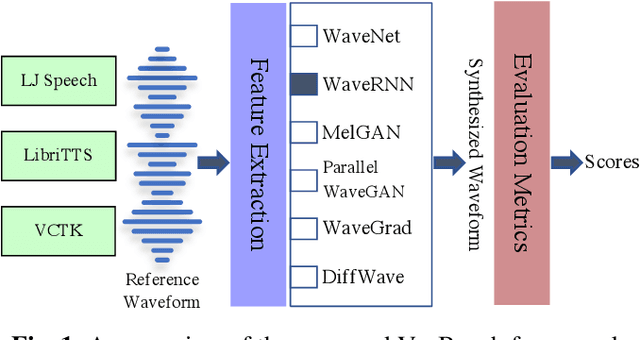
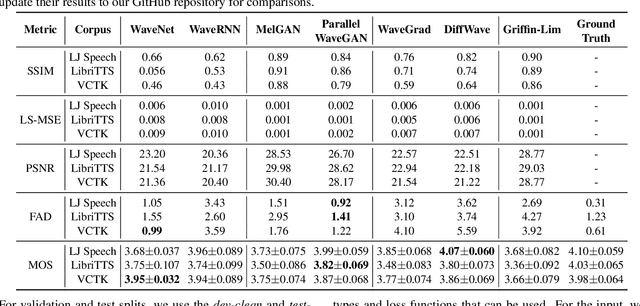
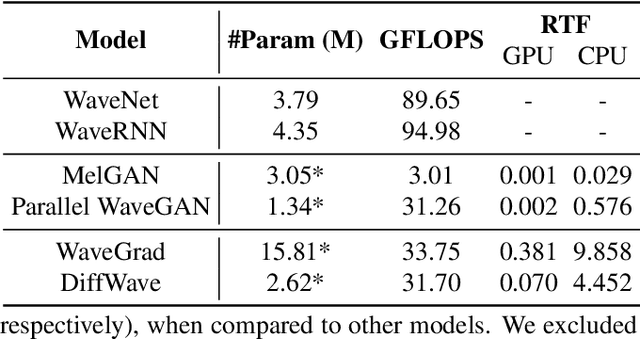
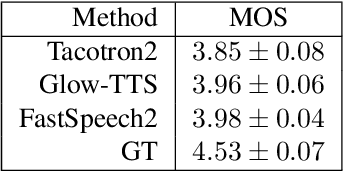
Neural vocoders, used for converting the spectral representations of an audio signal to the waveforms, are a commonly used component in speech synthesis pipelines. It focuses on synthesizing waveforms from low-dimensional representation, such as Mel-Spectrograms. In recent years, different approaches have been introduced to develop such vocoders. However, it becomes more challenging to assess these new vocoders and compare their performance to previous ones. To address this problem, we present VocBench, a framework that benchmark the performance of state-of-the art neural vocoders. VocBench uses a systematic study to evaluate different neural vocoders in a shared environment that enables a fair comparison between them. In our experiments, we use the same setup for datasets, training pipeline, and evaluation metrics for all neural vocoders. We perform a subjective and objective evaluation to compare the performance of each vocoder along a different axis. Our results demonstrate that the framework is capable of showing the competitive efficacy and the quality of the synthesized samples for each vocoder. VocBench framework is available at https://github.com/facebookresearch/vocoder-benchmark.
Few Shot Adaptive Normalization Driven Multi-Speaker Speech Synthesis
Dec 14, 2020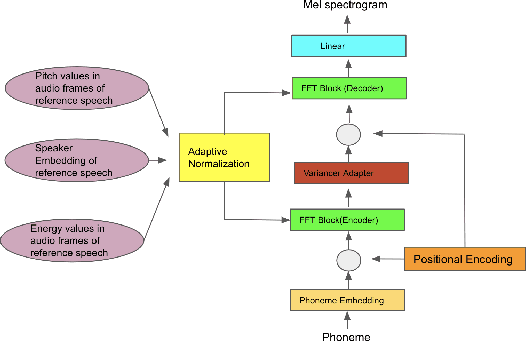

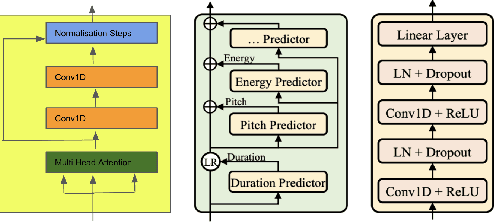
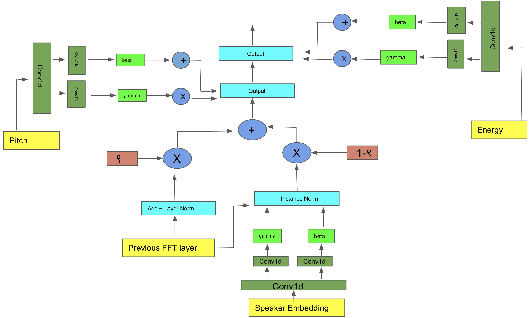
The style of the speech varies from person to person and every person exhibits his or her own style of speaking that is determined by the language, geography, culture and other factors. Style is best captured by prosody of a signal. High quality multi-speaker speech synthesis while considering prosody and in a few shot manner is an area of active research with many real-world applications. While multiple efforts have been made in this direction, it remains an interesting and challenging problem. In this paper, we present a novel few shot multi-speaker speech synthesis approach (FSM-SS) that leverages adaptive normalization architecture with a non-autoregressive multi-head attention model. Given an input text and a reference speech sample of an unseen person, FSM-SS can generate speech in that person's style in a few shot manner. Additionally, we demonstrate how the affine parameters of normalization help in capturing the prosodic features such as energy and fundamental frequency in a disentangled fashion and can be used to generate morphed speech output. We demonstrate the efficacy of our proposed architecture on multi-speaker VCTK and LibriTTS datasets, using multiple quantitative metrics that measure generated speech distortion and MoS, along with speaker embedding analysis of the generated speech vs the actual speech samples.