 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredictive Response Optimization: Using Reinforcement Learning to Fight Online Social Network Abuse
Feb 24, 2025



Detecting phishing, spam, fake accounts, data scraping, and other malicious activity in online social networks (OSNs) is a problem that has been studied for well over a decade, with a number of important results. Nearly all existing works on abuse detection have as their goal producing the best possible binary classifier; i.e., one that labels unseen examples as "benign" or "malicious" with high precision and recall. However, no prior published work considers what comes next: what does the service actually do after it detects abuse? In this paper, we argue that detection as described in previous work is not the goal of those who are fighting OSN abuse. Rather, we believe the goal to be selecting actions (e.g., ban the user, block the request, show a CAPTCHA, or "collect more evidence") that optimize a tradeoff between harm caused by abuse and impact on benign users. With this framing, we see that enlarging the set of possible actions allows us to move the Pareto frontier in a way that is unattainable by simply tuning the threshold of a binary classifier. To demonstrate the potential of our approach, we present Predictive Response Optimization (PRO), a system based on reinforcement learning that utilizes available contextual information to predict future abuse and user-experience metrics conditioned on each possible action, and select actions that optimize a multi-dimensional tradeoff between abuse/harm and impact on user experience. We deployed versions of PRO targeted at stopping automated activity on Instagram and Facebook. In both cases our experiments showed that PRO outperforms a baseline classification system, reducing abuse volume by 59% and 4.5% (respectively) with no negative impact to users. We also present several case studies that demonstrate how PRO can quickly and automatically adapt to changes in business constraints, system behavior, and/or adversarial tactics.
Leveraging Explainable AI to Analyze Researchers' Aspect-Based Sentiment about ChatGPT
Aug 16, 2023



The groundbreaking invention of ChatGPT has triggered enormous discussion among users across all fields and domains. Among celebration around its various advantages, questions have been raised with regards to its correctness and ethics of its use. Efforts are already underway towards capturing user sentiments around it. But it begs the question as to how the research community is analyzing ChatGPT with regards to various aspects of its usage. It is this sentiment of the researchers that we analyze in our work. Since Aspect-Based Sentiment Analysis has usually only been applied on a few datasets, it gives limited success and that too only on short text data. We propose a methodology that uses Explainable AI to facilitate such analysis on research data. Our technique presents valuable insights into extending the state of the art of Aspect-Based Sentiment Analysis on newer datasets, where such analysis is not hampered by the length of the text data.
CovidMis20: COVID-19 Misinformation Detection System on Twitter Tweets using Deep Learning Models
Sep 13, 2022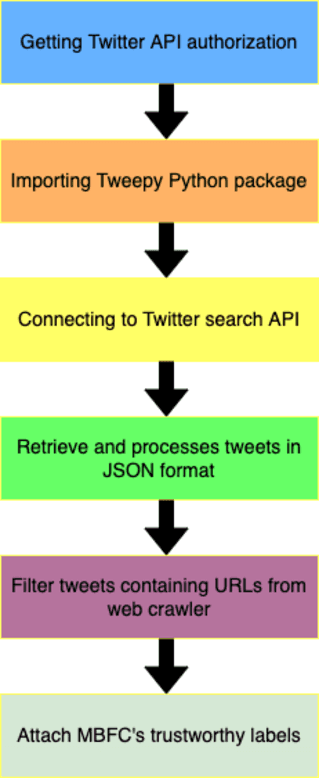
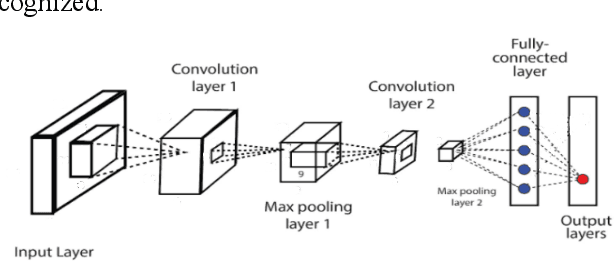
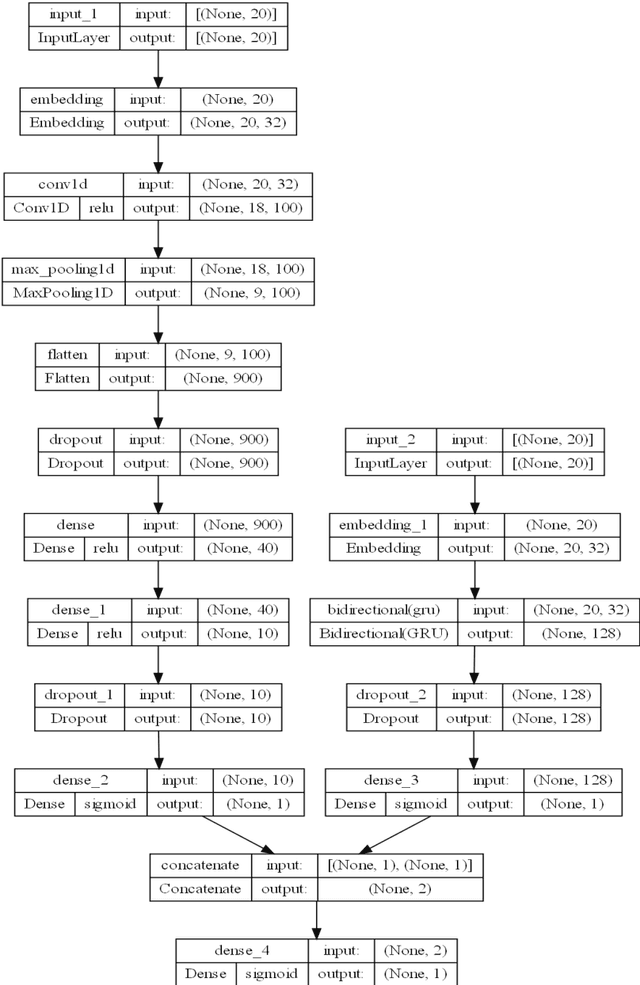
Online news and information sources are convenient and accessible ways to learn about current issues. For instance, more than 300 million people engage with posts on Twitter globally, which provides the possibility to disseminate misleading information. There are numerous cases where violent crimes have been committed due to fake news. This research presents the CovidMis20 dataset (COVID-19 Misinformation 2020 dataset), which consists of 1,375,592 tweets collected from February to July 2020. CovidMis20 can be automatically updated to fetch the latest news and is publicly available at: https://github.com/everythingguy/CovidMis20. This research was conducted using Bi-LSTM deep learning and an ensemble CNN+Bi-GRU for fake news detection. The results showed that, with testing accuracy of 92.23% and 90.56%, respectively, the ensemble CNN+Bi-GRU model consistently provided higher accuracy than the Bi-LSTM model.
Combining Compressions for Multiplicative Size Scaling on Natural Language Tasks
Aug 20, 2022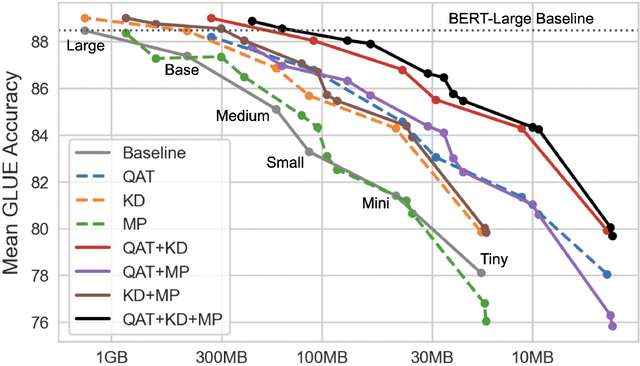
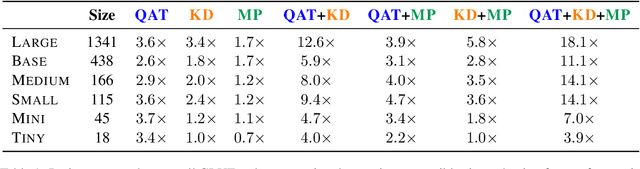
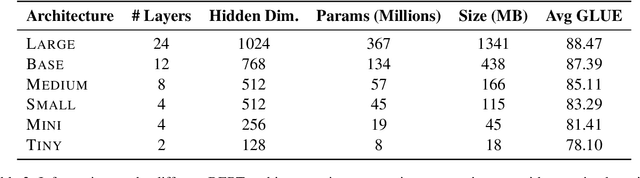
Quantization, knowledge distillation, and magnitude pruning are among the most popular methods for neural network compression in NLP. Independently, these methods reduce model size and can accelerate inference, but their relative benefit and combinatorial interactions have not been rigorously studied. For each of the eight possible subsets of these techniques, we compare accuracy vs. model size tradeoffs across six BERT architecture sizes and eight GLUE tasks. We find that quantization and distillation consistently provide greater benefit than pruning. Surprisingly, except for the pair of pruning and quantization, using multiple methods together rarely yields diminishing returns. Instead, we observe complementary and super-multiplicative reductions to model size. Our work quantitatively demonstrates that combining compression methods can synergistically reduce model size, and that practitioners should prioritize (1) quantization, (2) knowledge distillation, and (3) pruning to maximize accuracy vs. model size tradeoffs.
Offensive Language and Hate Speech Detection with Deep Learning and Transfer Learning
Aug 23, 2021

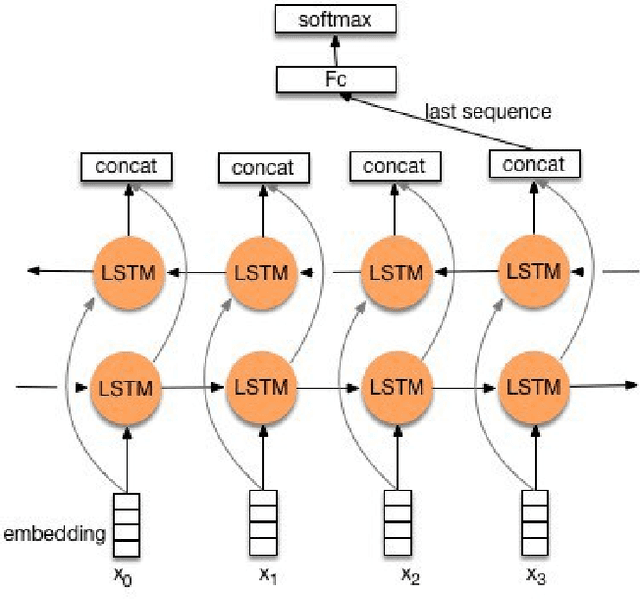
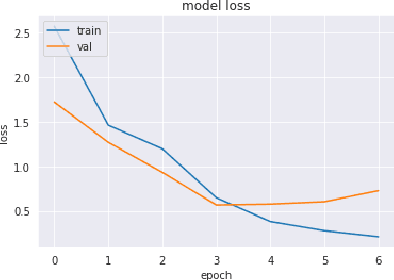
Toxic online speech has become a crucial problem nowadays due to an exponential increase in the use of internet by people from different cultures and educational backgrounds. Differentiating if a text message belongs to hate speech and offensive language is a key challenge in automatic detection of toxic text content. In this paper, we propose an approach to automatically classify tweets into three classes: Hate, offensive and Neither. Using public tweet data set, we first perform experiments to build BI-LSTM models from empty embedding and then we also try the same neural network architecture with pre-trained Glove embedding. Next, we introduce a transfer learning approach for hate speech detection using an existing pre-trained language model BERT (Bidirectional Encoder Representations from Transformers), DistilBert (Distilled version of BERT) and GPT-2 (Generative Pre-Training). We perform hyper parameters tuning analysis of our best model (BI-LSTM) considering different neural network architectures, learn-ratings and normalization methods etc. After tuning the model and with the best combination of parameters, we achieve over 92 percent accuracy upon evaluating it on test data. We also create a class module which contains main functionality including text classification, sentiment checking and text data augmentation. This model could serve as an intermediate module between user and Twitter.
Picking Pearl From Seabed: Extracting Artefacts from Noisy Issue Triaging Collaborative Conversations for Hybrid Cloud Services
May 31, 2021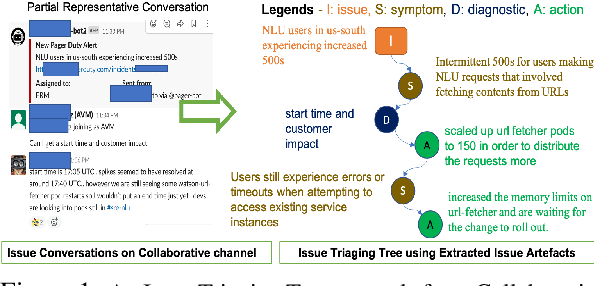
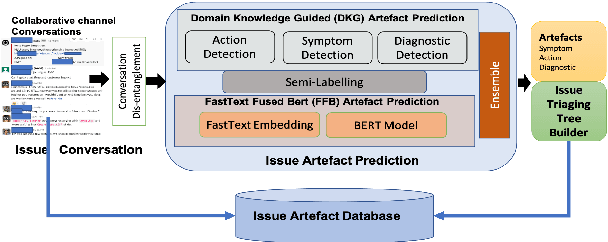
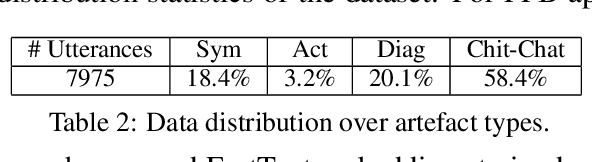
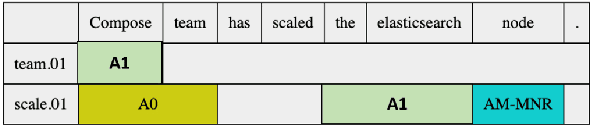
Site Reliability Engineers (SREs) play a key role in issue identification and resolution. After an issue is reported, SREs come together in a virtual room (collaboration platform) to triage the issue. While doing so, they leave behind a wealth of information which can be used later for triaging similar issues. However, usability of the conversations offer challenges due to them being i) noisy and ii) unlabelled. This paper presents a novel approach for issue artefact extraction from the noisy conversations with minimal labelled data. We propose a combination of unsupervised and supervised model with minimum human intervention that leverages domain knowledge to predict artefacts for a small amount of conversation data and use that for fine-tuning an already pretrained language model for artefact prediction on a large amount of conversation data. Experimental results on our dataset show that the proposed ensemble of unsupervised and supervised model is better than using either one of them individually.
Ensembling Low Precision Models for Binary Biomedical Image Segmentation
Oct 16, 2020
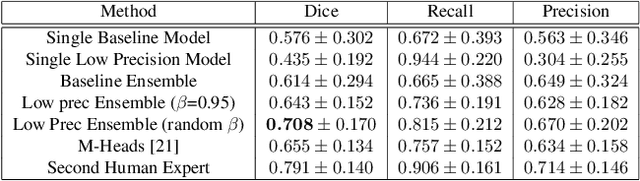
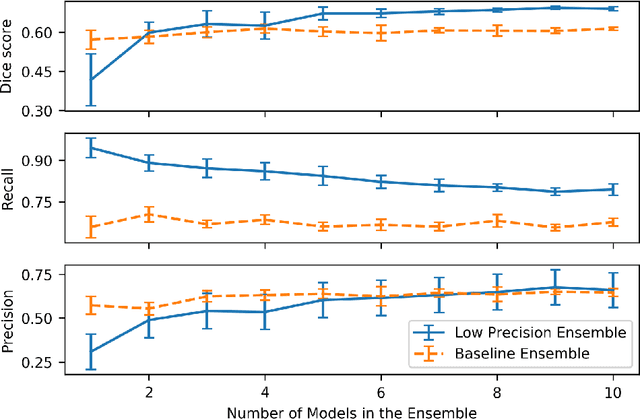

Segmentation of anatomical regions of interest such as vessels or small lesions in medical images is still a difficult problem that is often tackled with manual input by an expert. One of the major challenges for this task is that the appearance of foreground (positive) regions can be similar to background (negative) regions. As a result, many automatic segmentation algorithms tend to exhibit asymmetric errors, typically producing more false positives than false negatives. In this paper, we aim to leverage this asymmetry and train a diverse ensemble of models with very high recall, while sacrificing their precision. Our core idea is straightforward: A diverse ensemble of low precision and high recall models are likely to make different false positive errors (classifying background as foreground in different parts of the image), but the true positives will tend to be consistent. Thus, in aggregate the false positive errors will cancel out, yielding high performance for the ensemble. Our strategy is general and can be applied with any segmentation model. In three different applications (carotid artery segmentation in a neck CT angiography, myocardium segmentation in a cardiovascular MRI and multiple sclerosis lesion segmentation in a brain MRI), we show how the proposed approach can significantly boost the performance of a baseline segmentation method.
Carbon to Diamond: An Incident Remediation Assistant System From Site Reliability Engineers' Conversations in Hybrid Cloud Operations
Oct 12, 2020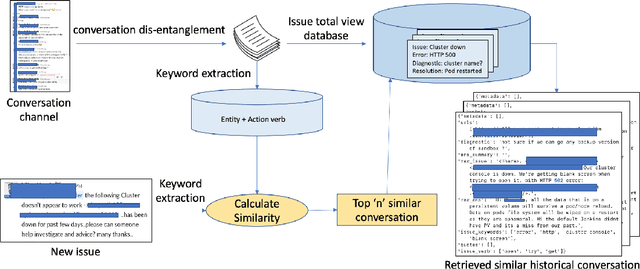
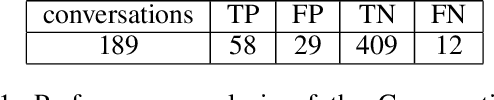

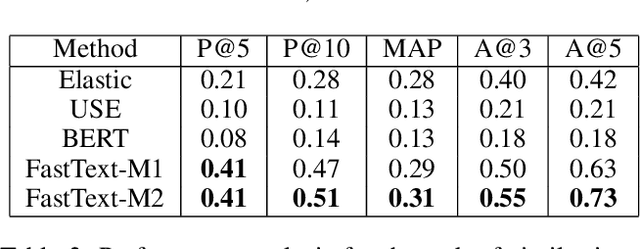
Conversational channels are changing the landscape of hybrid cloud service management. These channels are becoming important avenues for Site Reliability Engineers (SREs) %Subject Matter Experts (SME) to collaboratively work together to resolve an incident or issue. Identifying segmented conversations and extracting key insights or artefacts from them can help engineers to improve the efficiency of the incident remediation process by using information retrieval mechanisms for similar incidents. However, it has been empirically observed that due to the semi-formal behavior of such conversations (human language) they are very unique in nature and also contain lot of domain-specific terms. This makes it difficult to use the standard natural language processing frameworks directly, which are popularly used in standard NLP tasks. %It is important to identify the correct keywords and artefacts like symptoms, issue etc., present in the conversation chats. In this paper, we build a framework that taps into the conversational channels and uses various learning methods to (a) understand and extract key artefacts from conversations like diagnostic steps and resolution actions taken, and (b) present an approach to identify past conversations about similar issues. Experimental results on our dataset show the efficacy of our proposed method.
Volumetric landmark detection with a multi-scale shift equivariant neural network
Mar 03, 2020
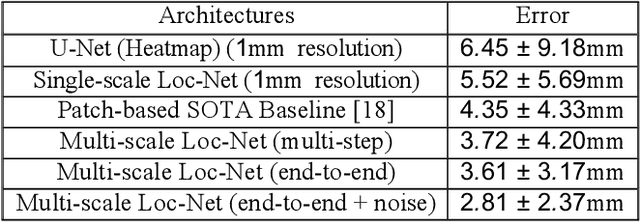

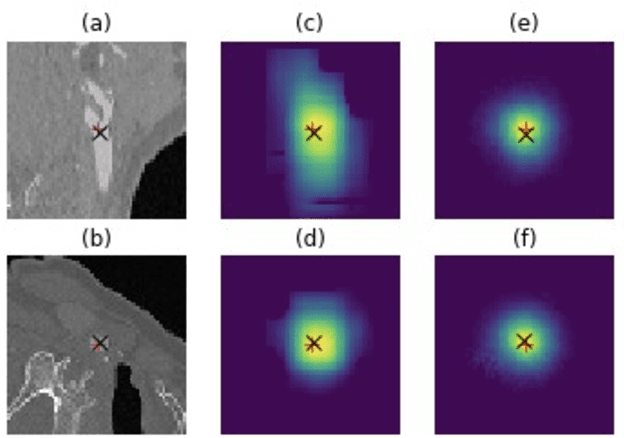
Deep neural networks yield promising results in a wide range of computer vision applications, including landmark detection. A major challenge for accurate anatomical landmark detection in volumetric images such as clinical CT scans is that large-scale data often constrain the capacity of the employed neural network architecture due to GPU memory limitations, which in turn can limit the precision of the output. We propose a multi-scale, end-to-end deep learning method that achieves fast and memory-efficient landmark detection in 3D images. Our architecture consists of blocks of shift-equivariant networks, each of which performs landmark detection at a different spatial scale. These blocks are connected from coarse to fine-scale, with differentiable resampling layers, so that all levels can be trained together. We also present a noise injection strategy that increases the robustness of the model and allows us to quantify uncertainty at test time. We evaluate our method for carotid artery bifurcations detection on 263 CT volumes and achieve a better than state-of-the-art accuracy with mean Euclidean distance error of 2.81mm.
Leveraging Machine Learning and Big Data for Smart Buildings: A Comprehensive Survey
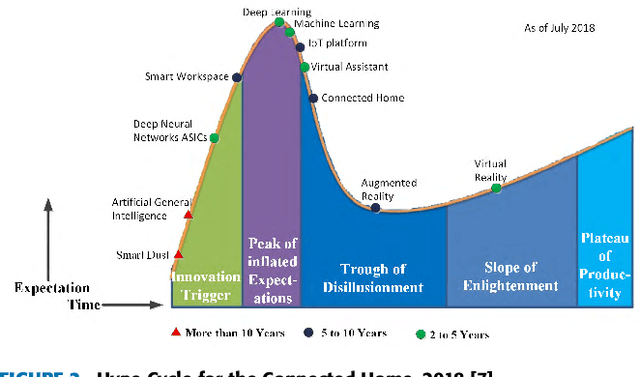
May 19, 2019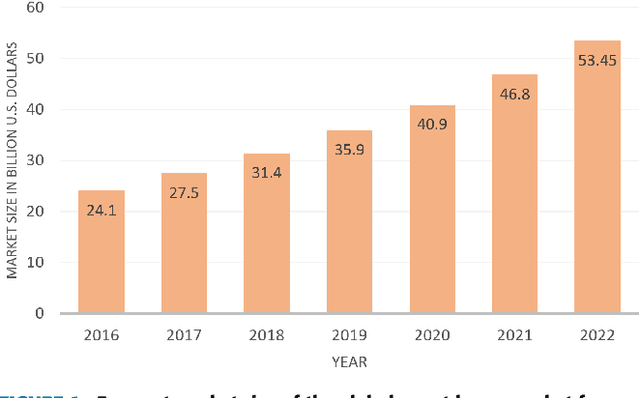

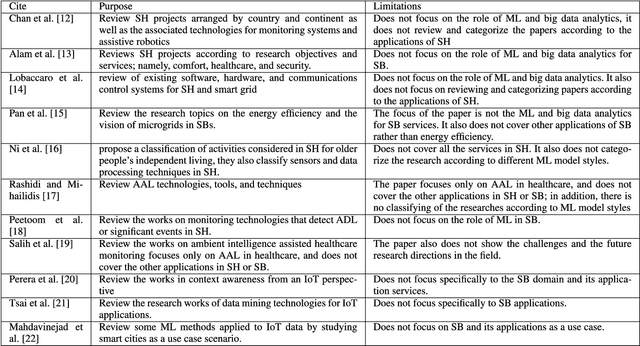
Future buildings will offer new convenience, comfort, and efficiency possibilities to their residents. Changes will occur to the way people live as technology involves into people's lives and information processing is fully integrated into their daily living activities and objects. The future expectation of smart buildings includes making the residents' experience as easy and comfortable as possible. The massive streaming data generated and captured by smart building appliances and devices contains valuable information that needs to be mined to facilitate timely actions and better decision making. Machine learning and big data analytics will undoubtedly play a critical role to enable the delivery of such smart services. In this paper, we survey the area of smart building with a special focus on the role of techniques from machine learning and big data analytics. This survey also reviews the current trends and challenges faced in the development of smart building services.