 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhenLoss: Diagnosing Write and Retrieval Bottlenecks in Long-Context Memory Systems
May 23, 2026Long-context memory systems often fail under fixed budgets, but end-to-end evaluation does not reveal whether evidence was discarded during compression or preserved but never retrieved. We introduce a four-condition diagnostic protocol that evaluates a fixed reader under truncated full context (TFC), oracle evidence (OE), complete stored memory (CSM), and retrieved memory (RM). Under this fixed-budget LongMemEval setup, write-side gaps exceed retrieval-side gaps for most tested baselines, with four of six baselines robustly write-dominant under our default diagnosis margin. Motivated by this diagnosis, we propose Expected Predictive Compression (EPC), which moves the key decision--what information to retain--to write time by using an LLM to anticipate likely future questions and preserve the minimal supporting evidence under the token budget, while leaving retrieval unchanged at question time. Across all 500 LongMemEval questions with three readers (GPT-5.2, Claude Sonnet 4, Gemini 2.5 Pro), EPC achieves the highest CSM scores among all systems (0.49 vs. 0.44 for Summary (LLM), the strongest baseline), reducing Delta_write to 0.04 while leaving Delta_retr comparable to other LLM-based systems. These results suggest that, on this benchmark and evaluation setup, improving what the write stage preserves is a key avenue for performance gains in the tested systems.
GSRM: Generative Speech Reward Model for Speech RLHF
Feb 14, 2026Recent advances in speech language models, such as GPT-4o Voice Mode and Gemini Live, have demonstrated promising speech generation capabilities. Nevertheless, the aesthetic naturalness of the synthesized audio still lags behind that of human speech. Enhancing generation quality requires a reliable evaluator of speech naturalness. However, existing naturalness evaluators typically regress raw audio to scalar scores, offering limited interpretability of the evaluation and moreover fail to generalize to speech across different taxonomies. Inspired by recent advances in generative reward modeling, we propose the Generative Speech Reward Model (GSRM), a reasoning-centric reward model tailored for speech. The GSRM is trained to decompose speech naturalness evaluation into an interpretable acoustic feature extraction stage followed by feature-grounded chain-of-thought reasoning, enabling explainable judgments. To achieve this, we curated a large-scale human feedback dataset comprising 31k expert ratings and an out-of-domain benchmark of real-world user-assistant speech interactions. Experiments show that GSRM substantially outperforms existing speech naturalness predictors, achieving model-human correlation of naturalness score prediction that approaches human inter-rater consistency. We further show how GSRM can improve the naturalness of speech LLM generations by serving as an effective verifier for online RLHF.
VowelPrompt: Hearing Speech Emotions from Text via Vowel-level Prosodic Augmentation
Feb 06, 2026Emotion recognition in speech presents a complex multimodal challenge, requiring comprehension of both linguistic content and vocal expressivity, particularly prosodic features such as fundamental frequency, intensity, and temporal dynamics. Although large language models (LLMs) have shown promise in reasoning over textual transcriptions for emotion recognition, they typically neglect fine-grained prosodic information, limiting their effectiveness and interpretability. In this work, we propose VowelPrompt, a linguistically grounded framework that augments LLM-based emotion recognition with interpretable, fine-grained vowel-level prosodic cues. Drawing on phonetic evidence that vowels serve as primary carriers of affective prosody, VowelPrompt extracts pitch-, energy-, and duration-based descriptors from time-aligned vowel segments, and converts these features into natural language descriptions for better interpretability. Such a design enables LLMs to jointly reason over lexical semantics and fine-grained prosodic variation. Moreover, we adopt a two-stage adaptation procedure comprising supervised fine-tuning (SFT) followed by Reinforcement Learning with Verifiable Reward (RLVR), implemented via Group Relative Policy Optimization (GRPO), to enhance reasoning capability, enforce structured output adherence, and improve generalization across domains and speaker variations. Extensive evaluations across diverse benchmark datasets demonstrate that VowelPrompt consistently outperforms state-of-the-art emotion recognition methods under zero-shot, fine-tuned, cross-domain, and cross-linguistic conditions, while enabling the generation of interpretable explanations that are jointly grounded in contextual semantics and fine-grained prosodic structure.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Get Large Language Models Ready to Speak: A Late-fusion Approach for Speech Generation
Oct 27, 2024



Large language models (LLMs) have revolutionized natural language processing (NLP) with impressive performance across various text-based tasks. However, the extension of text-dominant LLMs to with speech generation tasks remains under-explored. In this work, we introduce a text-to-speech (TTS) system powered by a fine-tuned Llama model, named TTS-Llama, that achieves state-of-the-art speech synthesis performance. Building on TTS-Llama, we further propose MoLE-Llama, a text-and-speech multimodal LLM developed through purely late-fusion parameter-efficient fine-tuning (PEFT) and a mixture-of-expert architecture. Extensive empirical results demonstrate MoLE-Llama's competitive performance on both text-only question-answering (QA) and TTS tasks, mitigating catastrophic forgetting issue in either modality. Finally, we further explore MoLE-Llama in text-in-speech-out QA tasks, demonstrating its great potential as a multimodal dialog system capable of speech generation.
Self-Supervised Representations for Singing Voice Conversion
Mar 21, 2023A singing voice conversion model converts a song in the voice of an arbitrary source singer to the voice of a target singer. Recently, methods that leverage self-supervised audio representations such as HuBERT and Wav2Vec 2.0 have helped further the state-of-the-art. Though these methods produce more natural and melodic singing outputs, they often rely on confusion and disentanglement losses to render the self-supervised representations speaker and pitch-invariant. In this paper, we circumvent disentanglement training and propose a new model that leverages ASR fine-tuned self-supervised representations as inputs to a HiFi-GAN neural vocoder for singing voice conversion. We experiment with different f0 encoding schemes and show that an f0 harmonic generation module that uses a parallel bank of transposed convolutions (PBTC) alongside ASR fine-tuned Wav2Vec 2.0 features results in the best singing voice conversion quality. Additionally, the model is capable of making a spoken voice sing. We also show that a simple f0 shifting scheme during inference helps retain singer identity and bolsters the performance of our singing voice conversion model. Our results are backed up by extensive MOS studies that compare different ablations and baselines.
Synthetic Cross-accent Data Augmentation for Automatic Speech Recognition
Mar 01, 2023


The awareness for biased ASR datasets or models has increased notably in recent years. Even for English, despite a vast amount of available training data, systems perform worse for non-native speakers. In this work, we improve an accent-conversion model (ACM) which transforms native US-English speech into accented pronunciation. We include phonetic knowledge in the ACM training to provide accurate feedback about how well certain pronunciation patterns were recovered in the synthesized waveform. Furthermore, we investigate the feasibility of learned accent representations instead of static embeddings. Generated data was then used to train two state-of-the-art ASR systems. We evaluated our approach on native and non-native English datasets and found that synthetically accented data helped the ASR to better understand speech from seen accents. This observation did not translate to unseen accents, and it was not observed for a model that had been pre-trained exclusively with native speech.
Voice-preserving Zero-shot Multiple Accent Conversion
Nov 23, 2022Most people who have tried to learn a foreign language would have experienced difficulties understanding or speaking with a native speaker's accent. For native speakers, understanding or speaking a new accent is likewise a difficult task. An accent conversion system that changes a speaker's accent but preserves that speaker's voice identity, such as timbre and pitch, has the potential for a range of applications, such as communication, language learning, and entertainment. Existing accent conversion models tend to change the speaker identity and accent at the same time. Here, we use adversarial learning to disentangle accent dependent features while retaining other acoustic characteristics. What sets our work apart from existing accent conversion models is the capability to convert an unseen speaker's utterance to multiple accents while preserving its original voice identity. Subjective evaluations show that our model generates audio that sound closer to the target accent and like the original speaker.
Towards zero-shot Text-based voice editing using acoustic context conditioning, utterance embeddings, and reference encoders
Oct 28, 2022



Text-based voice editing (TBVE) uses synthetic output from text-to-speech (TTS) systems to replace words in an original recording. Recent work has used neural models to produce edited speech that is similar to the original speech in terms of clarity, speaker identity, and prosody. However, one limitation of prior work is the usage of finetuning to optimise performance: this requires further model training on data from the target speaker, which is a costly process that may incorporate potentially sensitive data into server-side models. In contrast, this work focuses on the zero-shot approach which avoids finetuning altogether, and instead uses pretrained speaker verification embeddings together with a jointly trained reference encoder to encode utterance-level information that helps capture aspects such as speaker identity and prosody. Subjective listening tests find that both utterance embeddings and a reference encoder improve the continuity of speaker identity and prosody between the edited synthetic speech and unedited original recording in the zero-shot setting.
VocBench: A Neural Vocoder Benchmark for Speech Synthesis
Dec 06, 2021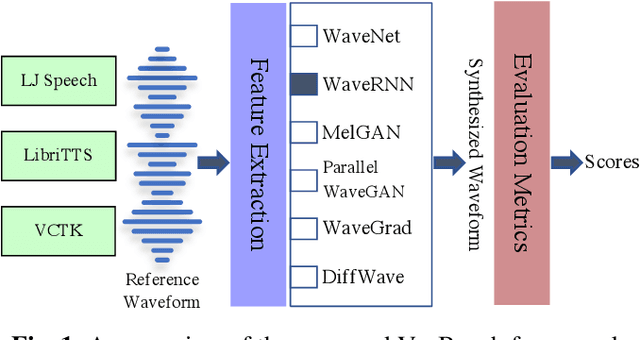
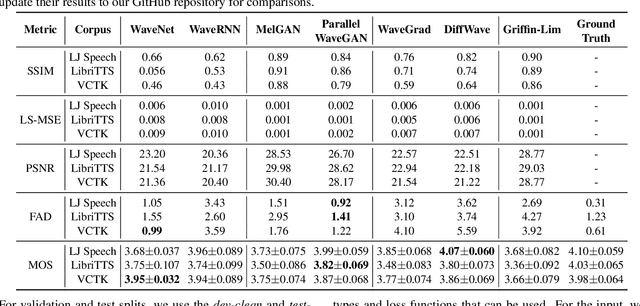
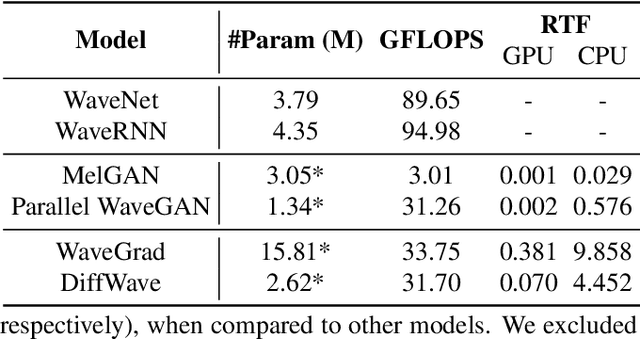
Neural vocoders, used for converting the spectral representations of an audio signal to the waveforms, are a commonly used component in speech synthesis pipelines. It focuses on synthesizing waveforms from low-dimensional representation, such as Mel-Spectrograms. In recent years, different approaches have been introduced to develop such vocoders. However, it becomes more challenging to assess these new vocoders and compare their performance to previous ones. To address this problem, we present VocBench, a framework that benchmark the performance of state-of-the art neural vocoders. VocBench uses a systematic study to evaluate different neural vocoders in a shared environment that enables a fair comparison between them. In our experiments, we use the same setup for datasets, training pipeline, and evaluation metrics for all neural vocoders. We perform a subjective and objective evaluation to compare the performance of each vocoder along a different axis. Our results demonstrate that the framework is capable of showing the competitive efficacy and the quality of the synthesized samples for each vocoder. VocBench framework is available at https://github.com/facebookresearch/vocoder-benchmark.