 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangling Speaker Traits for Deepfake Source Verification via Chebyshev Polynomial and Riemannian Metric Learning
Mar 23, 2026Speech deepfake source verification systems aims to determine whether two synthetic speech utterances originate from the same source generator, often assuming that the resulting source embeddings are independent of speaker traits. However, this assumption remains unverified. In this paper, we first investigate the impact of speaker factors on source verification. We propose a speaker-disentangled metric learning (SDML) framework incorporating two novel loss functions. The first leverages Chebyshev polynomial to mitigate gradient instability during disentanglement optimization. The second projects source and speaker embeddings into hyperbolic space, leveraging Riemannian metric distances to reduce speaker information and learn more discriminative source features. Experimental results on MLAAD benchmark, evaluated under four newly proposed protocols designed for source-speaker disentanglement scenarios, demonstrate the effectiveness of SDML framework. The code, evaluation protocols and demo website are available at https://github.com/xxuan-acoustics/RiemannSD-Net.
Targeted Fine-Tuning of DNN-Based Receivers via Influence Functions
Sep 19, 2025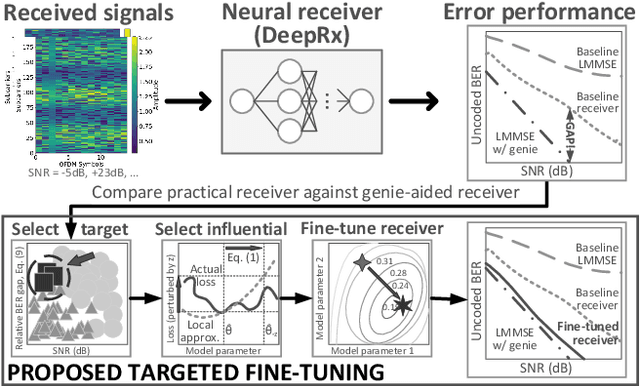
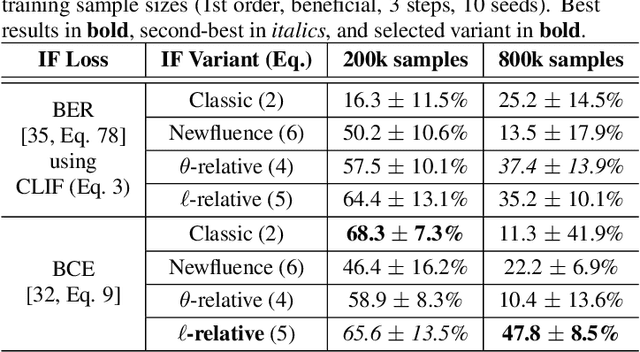
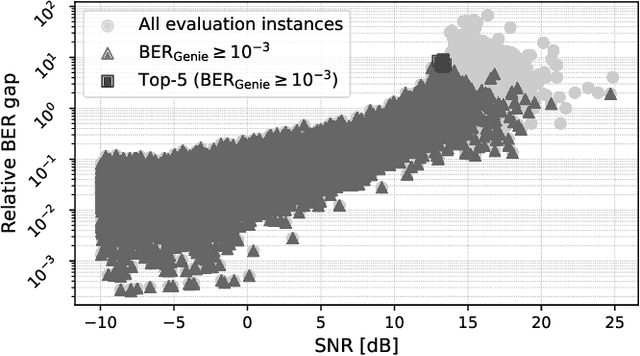
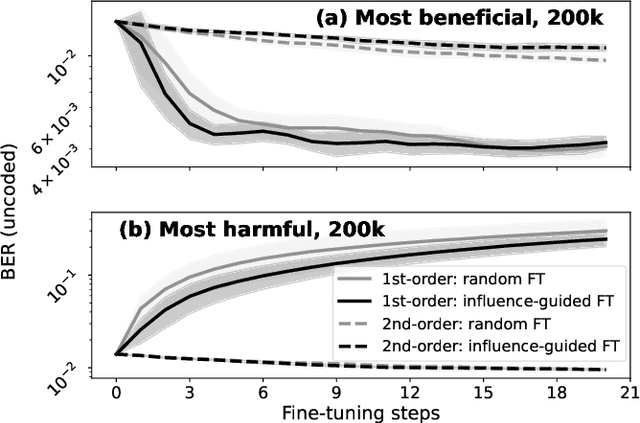
We present the first use of influence functions for deep learning-based wireless receivers. Applied to DeepRx, a fully convolutional receiver, influence analysis reveals which training samples drive bit predictions, enabling targeted fine-tuning of poorly performing cases. We show that loss-relative influence with capacity-like binary cross-entropy loss and first-order updates on beneficial samples most consistently improves bit error rate toward genie-aided performance, outperforming random fine-tuning in single-target scenarios. Multi-target adaptation proved less effective, underscoring open challenges. Beyond experiments, we connect influence to self-influence corrections and propose a second-order, influence-aligned update strategy. Our results establish influence functions as both an interpretability tool and a basis for efficient receiver adaptation.
Mixture of Low-Rank Adapter Experts in Generalizable Audio Deepfake Detection
Sep 17, 2025



Foundation models such as Wav2Vec2 excel at representation learning in speech tasks, including audio deepfake detection. However, after being fine-tuned on a fixed set of bonafide and spoofed audio clips, they often fail to generalize to novel deepfake methods not represented in training. To address this, we propose a mixture-of-LoRA-experts approach that integrates multiple low-rank adapters (LoRA) into the model's attention layers. A routing mechanism selectively activates specialized experts, enhancing adaptability to evolving deepfake attacks. Experimental results show that our method outperforms standard fine-tuning in both in-domain and out-of-domain scenarios, reducing equal error rates relative to baseline models. Notably, our best MoE-LoRA model lowers the average out-of-domain EER from 8.55\% to 6.08\%, demonstrating its effectiveness in achieving generalizable audio deepfake detection.
Refining Neural Activation Patterns for Layer-Level Concept Discovery in Neural Network-Based Receivers
May 21, 2025



Concept discovery in neural networks often targets individual neurons or human-interpretable features, overlooking distributed layer-wide patterns. We study the Neural Activation Pattern (NAP) methodology, which clusters full-layer activation distributions to identify such layer-level concepts. Applied to visual object recognition and radio receiver models, we propose improved normalization, distribution estimation, distance metrics, and varied cluster selection. In the radio receiver model, distinct concepts did not emerge; instead, a continuous activation manifold shaped by Signal-to-Noise Ratio (SNR) was observed -- highlighting SNR as a key learned factor, consistent with classical receiver behavior and supporting physical plausibility. Our enhancements to NAP improved in-distribution vs. out-of-distribution separation, suggesting better generalization and indirectly validating clustering quality. These results underscore the importance of clustering design and activation manifolds in interpreting and troubleshooting neural network behavior.
Meta-Learning Approaches for Improving Detection of Unseen Speech Deepfakes
Oct 27, 2024



Current speech deepfake detection approaches perform satisfactorily against known adversaries; however, generalization to unseen attacks remains an open challenge. The proliferation of speech deepfakes on social media underscores the need for systems that can generalize to unseen attacks not observed during training. We address this problem from the perspective of meta-learning, aiming to learn attack-invariant features to adapt to unseen attacks with very few samples available. This approach is promising since generating of a high-scale training dataset is often expensive or infeasible. Our experiments demonstrated an improvement in the Equal Error Rate (EER) from 21.67% to 10.42% on the InTheWild dataset, using just 96 samples from the unseen dataset. Continuous few-shot adaptation ensures that the system remains up-to-date.
Improving Numerical Stability of Normalized Mutual Information Estimator on High Dimensions
Oct 10, 2024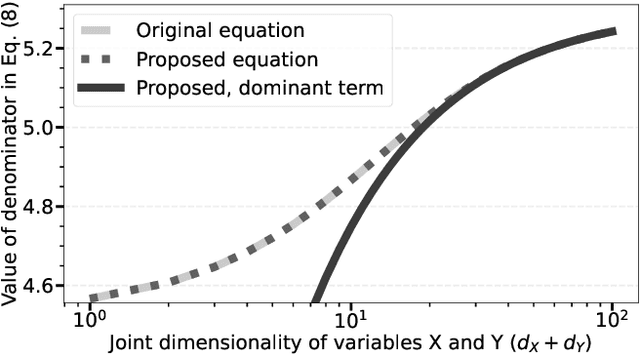

Mutual information provides a powerful, general-purpose metric for quantifying the amount of shared information between variables. Estimating normalized mutual information using a k-Nearest Neighbor (k-NN) based approach involves the calculation of the scaling-invariant k-NN radius. Calculation of the radius suffers from numerical overflow when the joint dimensionality of the data becomes high, typically in the range of several hundred dimensions. To address this issue, we propose a logarithmic transformation technique that improves the numerical stability of the radius calculation in high-dimensional spaces. By applying the proposed transformation during the calculation of the radius, numerical overflow is avoided, and precision is maintained. Proposed transformation is validated through both theoretical analysis and empirical evaluation, demonstrating its ability to stabilize the calculation without compromizing the precision of the results.
Interpreting Deep Neural Network-Based Receiver Under Varying Signal-To-Noise Ratios
Sep 25, 2024



We propose a novel method for interpreting neural networks, focusing on convolutional neural network-based receiver model. The method identifies which unit or units of the model contain most (or least) information about the channel parameter(s) of the interest, providing insights at both global and local levels -- with global explanations aggregating local ones. Experiments on link-level simulations demonstrate the method's effectiveness in identifying units that contribute most (and least) to signal-to-noise ratio processing. Although we focus on a radio receiver model, the method generalizes to other neural network architectures and applications, offering robust estimation even in high-dimensional settings.
Natural Language as Polices: Reasoning for Coordinate-Level Embodied Control with LLMs
Mar 20, 2024



We demonstrate experimental results with LLMs that address robotics action planning problems. Recently, LLMs have been applied in robotics action planning, particularly using a code generation approach that converts complex high-level instructions into mid-level policy codes. In contrast, our approach acquires text descriptions of the task and scene objects, then formulates action planning through natural language reasoning, and outputs coordinate level control commands, thus reducing the necessity for intermediate representation code as policies. Our approach is evaluated on a multi-modal prompt simulation benchmark, demonstrating that our prompt engineering experiments with natural language reasoning significantly enhance success rates compared to its absence. Furthermore, our approach illustrates the potential for natural language descriptions to transfer robotics skills from known tasks to previously unseen tasks.
Gradient weighting for speaker verification in extremely low Signal-to-Noise Ratio
Jan 05, 2024Speaker verification is hampered by background noise, particularly at extremely low Signal-to-Noise Ratio (SNR) under 0 dB. It is difficult to suppress noise without introducing unwanted artifacts, which adversely affects speaker verification. We proposed the mechanism called Gradient Weighting (Grad-W), which dynamically identifies and reduces artifact noise during prediction. The mechanism is based on the property that the gradient indicates which parts of the input the model is paying attention to. Specifically, when the speaker network focuses on a region in the denoised utterance but not on the clean counterpart, we consider it artifact noise and assign higher weights for this region during optimization of enhancement. We validate it by training an enhancement model and testing the enhanced utterance on speaker verification. The experimental results show that our approach effectively reduces artifact noise, improving speaker verification across various SNR levels.
Towards Solving Fuzzy Tasks with Human Feedback: A Retrospective of the MineRL BASALT 2022 Competition
Mar 23, 2023



To facilitate research in the direction of fine-tuning foundation models from human feedback, we held the MineRL BASALT Competition on Fine-Tuning from Human Feedback at NeurIPS 2022. The BASALT challenge asks teams to compete to develop algorithms to solve tasks with hard-to-specify reward functions in Minecraft. Through this competition, we aimed to promote the development of algorithms that use human feedback as channels to learn the desired behavior. We describe the competition and provide an overview of the top solutions. We conclude by discussing the impact of the competition and future directions for improvement.