 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
ABC-KD: Attention-Based-Compression Knowledge Distillation for Deep Learning-Based Noise Suppression
May 26, 2023
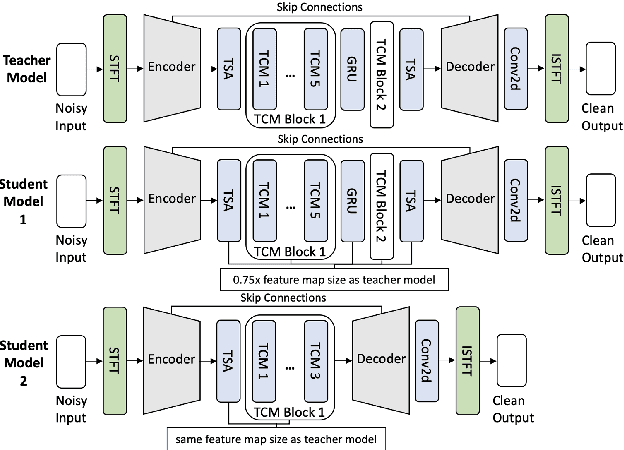
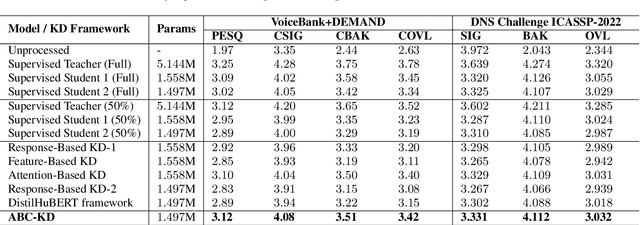
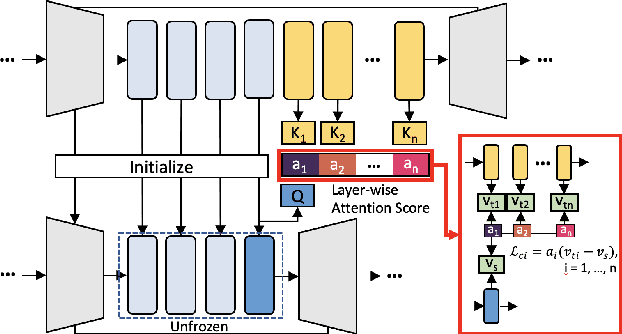
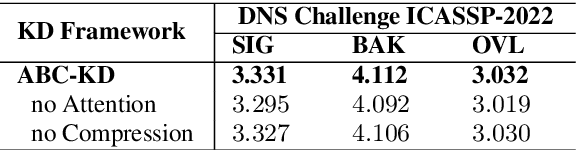
Noise suppression (NS) models have been widely applied to enhance speech quality. Recently, Deep Learning-Based NS, which we denote as Deep Noise Suppression (DNS), became the mainstream NS method due to its excelling performance over traditional ones. However, DNS models face 2 major challenges for supporting the real-world applications. First, high-performing DNS models are usually large in size, causing deployment difficulties. Second, DNS models require extensive training data, including noisy audios as inputs and clean audios as labels. It is often difficult to obtain clean labels for training DNS models. We propose the use of knowledge distillation (KD) to resolve both challenges. Our study serves 2 main purposes. To begin with, we are among the first to comprehensively investigate mainstream KD techniques on DNS models to resolve the two challenges. Furthermore, we propose a novel Attention-Based-Compression KD method that outperforms all investigated mainstream KD frameworks on DNS task.
Seeing What You Said: Talking Face Generation Guided by a Lip Reading Expert
Mar 29, 2023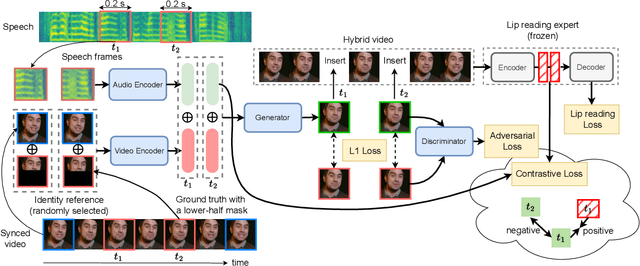
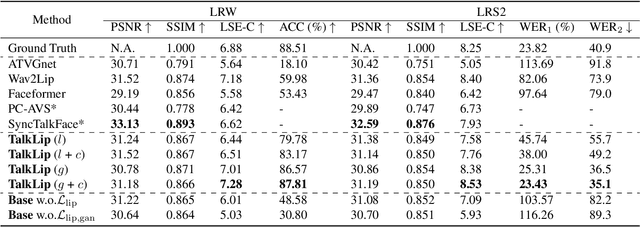
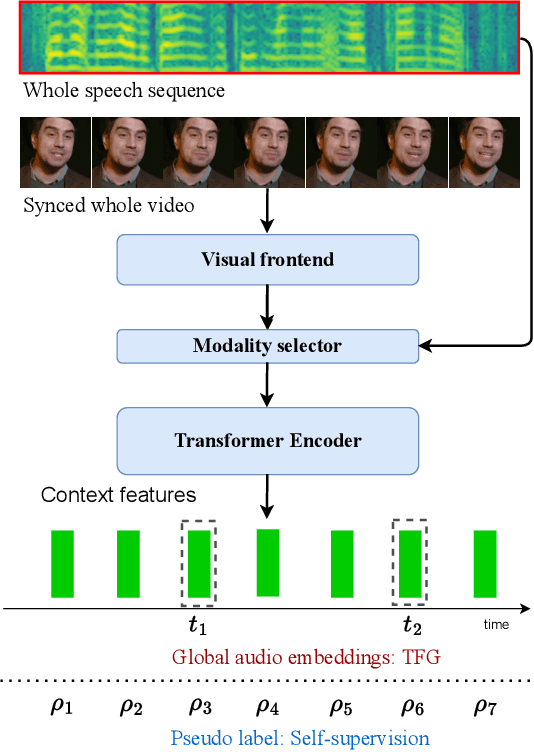
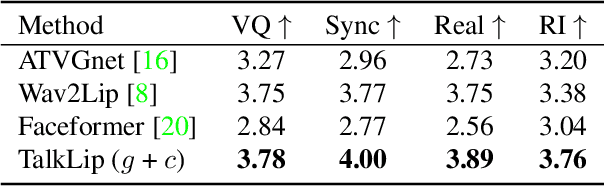
Talking face generation, also known as speech-to-lip generation, reconstructs facial motions concerning lips given coherent speech input. The previous studies revealed the importance of lip-speech synchronization and visual quality. Despite much progress, they hardly focus on the content of lip movements i.e., the visual intelligibility of the spoken words, which is an important aspect of generation quality. To address the problem, we propose using a lip-reading expert to improve the intelligibility of the generated lip regions by penalizing the incorrect generation results. Moreover, to compensate for data scarcity, we train the lip-reading expert in an audio-visual self-supervised manner. With a lip-reading expert, we propose a novel contrastive learning to enhance lip-speech synchronization, and a transformer to encode audio synchronically with video, while considering global temporal dependency of audio. For evaluation, we propose a new strategy with two different lip-reading experts to measure intelligibility of the generated videos. Rigorous experiments show that our proposal is superior to other State-of-the-art (SOTA) methods, such as Wav2Lip, in reading intelligibility i.e., over 38% Word Error Rate (WER) on LRS2 dataset and 27.8% accuracy on LRW dataset. We also achieve the SOTA performance in lip-speech synchronization and comparable performances in visual quality.
Quran Recitation Recognition using End-to-End Deep Learning
May 10, 2023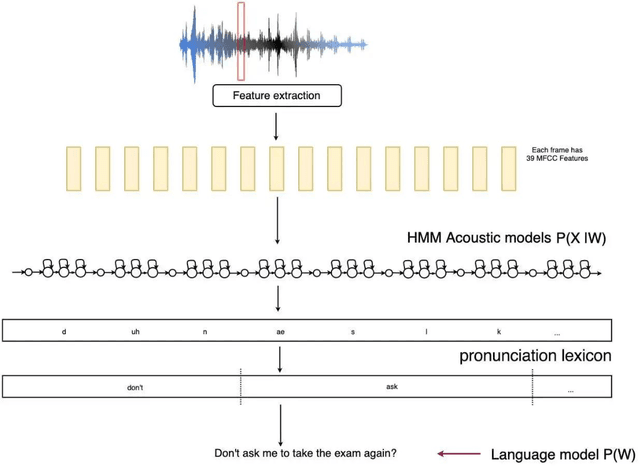
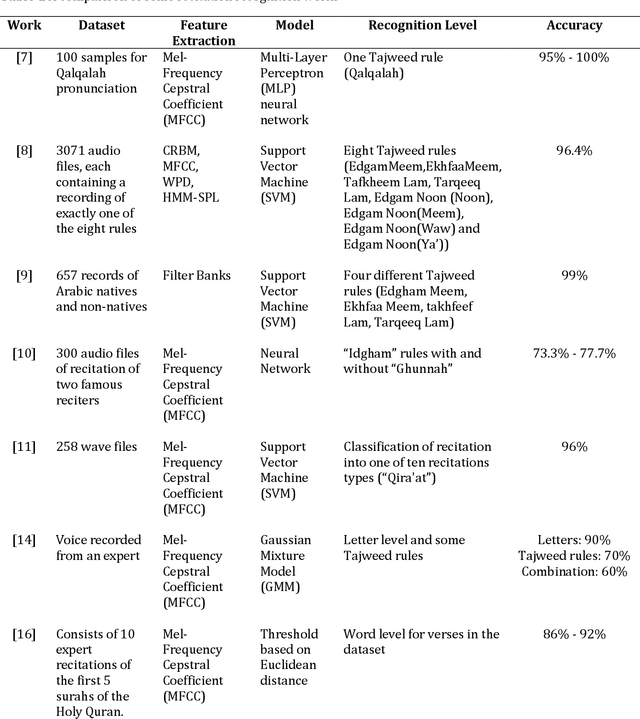
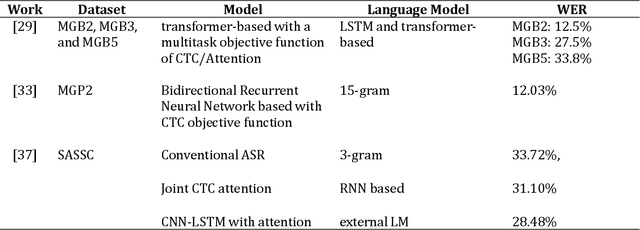
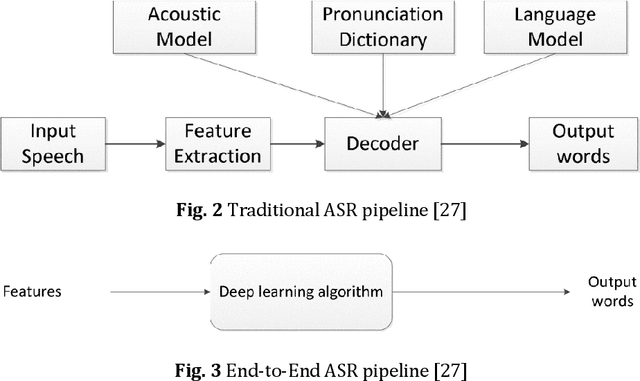
The Quran is the holy scripture of Islam, and its recitation is an important aspect of the religion. Recognizing the recitation of the Holy Quran automatically is a challenging task due to its unique rules that are not applied in normal speaking speeches. A lot of research has been done in this domain, but previous works have detected recitation errors as a classification task or used traditional automatic speech recognition (ASR). In this paper, we proposed a novel end-to-end deep learning model for recognizing the recitation of the Holy Quran. The proposed model is a CNN-Bidirectional GRU encoder that uses CTC as an objective function, and a character-based decoder which is a beam search decoder. Moreover, all previous works were done on small private datasets consisting of short verses and a few chapters of the Holy Quran. As a result of using private datasets, no comparisons were done. To overcome this issue, we used a public dataset that has recently been published (Ar-DAD) and contains about 37 chapters that were recited by 30 reciters, with different recitation speeds and different types of pronunciation rules. The proposed model performance was evaluated using the most common evaluation metrics in speech recognition, word error rate (WER), and character error rate (CER). The results were 8.34% WER and 2.42% CER. We hope this research will be a baseline for comparisons with future research on this public new dataset (Ar-DAD).
The Ability of Self-Supervised Speech Models for Audio Representations
Sep 28, 2022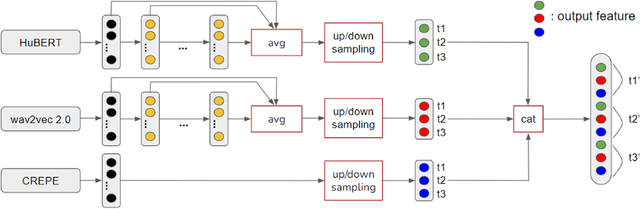
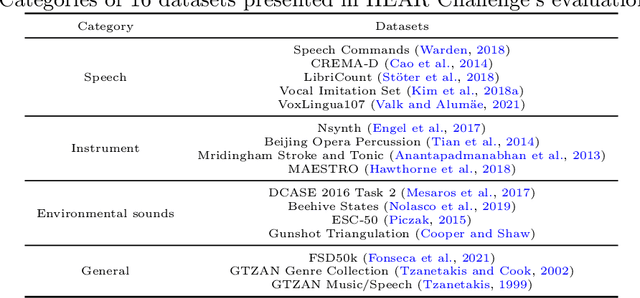
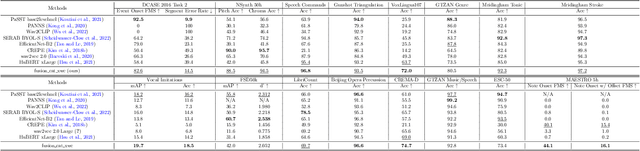

Self-supervised learning (SSL) speech models have achieved unprecedented success in speech representation learning, but some questions regarding their representation ability remain unanswered. This paper addresses two of them: (1) Can SSL speech models deal with non-speech audio?; (2) Would different SSL speech models have insights into diverse aspects of audio features? To answer the two questions, we conduct extensive experiments on abundant speech and non-speech audio datasets to evaluate the representation ability of currently state-of-the-art SSL speech models, which are wav2vec 2.0 and HuBERT in this paper. These experiments are carried out during NeurIPS 2021 HEAR Challenge as a standard evaluation pipeline provided by competition officials. Results show that (1) SSL speech models could extract meaningful features of a wide range of non-speech audio, while they may also fail on certain types of datasets; (2) different SSL speech models have insights into different aspects of audio features. The two conclusions provide a foundation for the ensemble of representation models. We further propose an ensemble framework to fuse speech representation models' embeddings. Our framework outperforms state-of-the-art SSL speech/audio models and has generally superior performance on abundant datasets compared with other teams in HEAR Challenge. Our code is available at https://github.com/tony10101105/HEAR-2021-NeurIPS-Challenge -- NTU-GURA.
Risk of re-identification for shared clinical speech recordings
Oct 18, 2022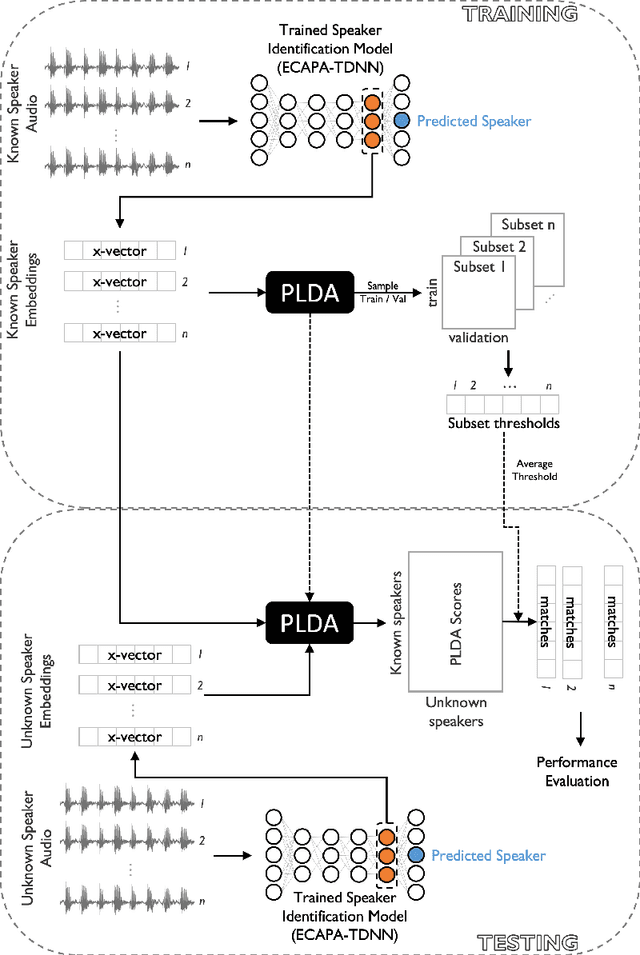
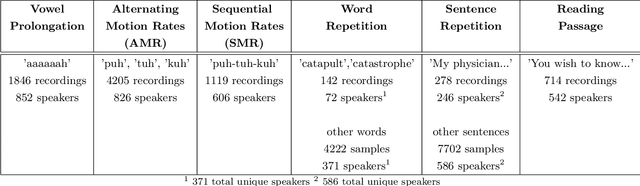
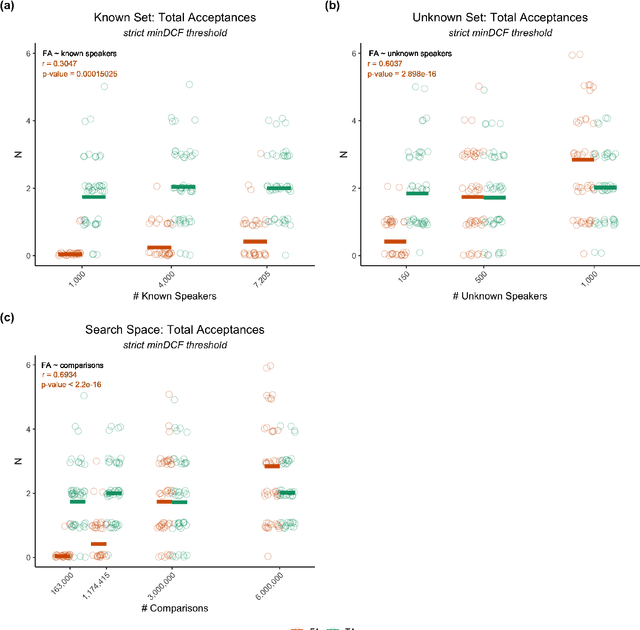
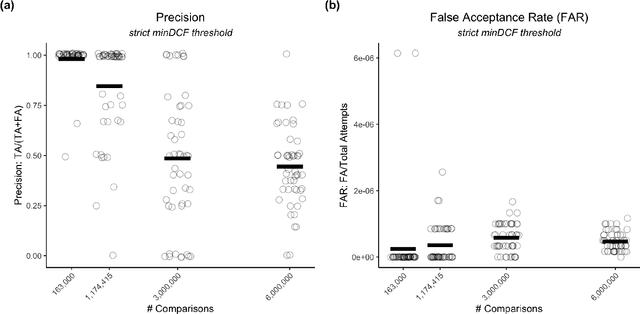
Large, curated datasets are required to leverage speech-based tools in healthcare. These are costly to produce, resulting in increased interest in data sharing. As speech can potentially identify speakers (i.e., voiceprints), sharing recordings raises privacy concerns. We examine the re-identification risk for speech recordings, without reference to demographic or metadata, using a state-of-the-art speaker recognition system. We demonstrate that the risk is inversely related to the number of comparisons an adversary must consider, i.e., the search space. Risk is high for a small search space but drops as the search space grows ($precision >0.85$ for $<1*10^{6}$ comparisons, $precision <0.5$ for $>3*10^{6}$ comparisons). Next, we show that the nature of a speech recording influences re-identification risk, with non-connected speech (e.g., vowel prolongation) being harder to identify. Our findings suggest that speaker recognition systems can be used to re-identify participants in specific circumstances, but in practice, the re-identification risk appears low.
Improving Speech Enhancement through Fine-Grained Speech Characteristics
Jul 01, 2022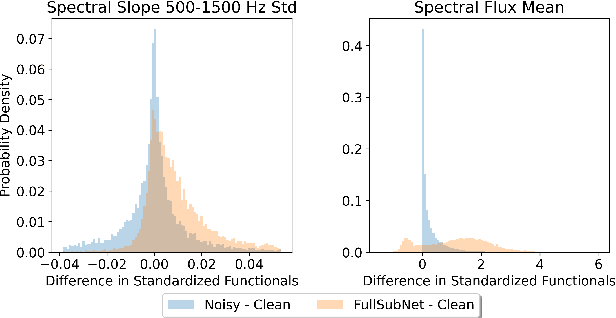
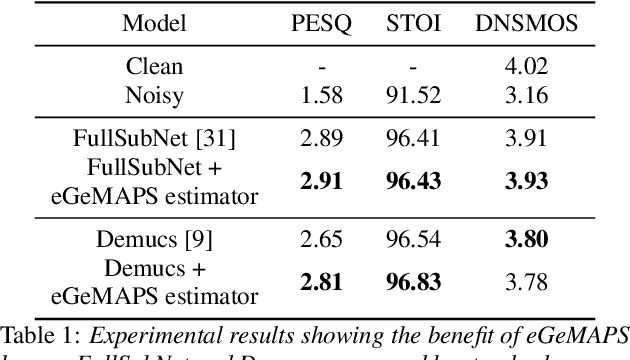
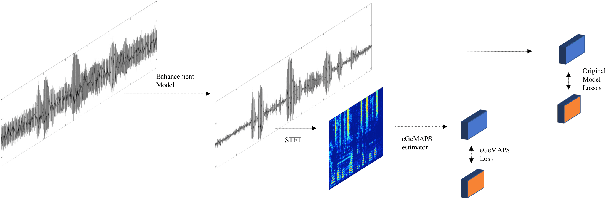
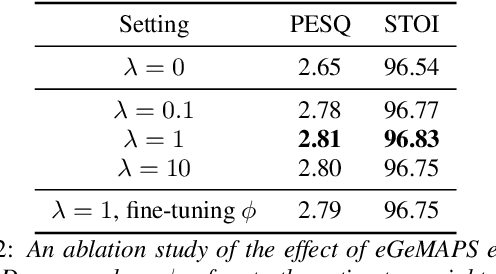
While deep learning based speech enhancement systems have made rapid progress in improving the quality of speech signals, they can still produce outputs that contain artifacts and can sound unnatural. We propose a novel approach to speech enhancement aimed at improving perceptual quality and naturalness of enhanced signals by optimizing for key characteristics of speech. We first identify key acoustic parameters that have been found to correlate well with voice quality (e.g. jitter, shimmer, and spectral flux) and then propose objective functions which are aimed at reducing the difference between clean speech and enhanced speech with respect to these features. The full set of acoustic features is the extended Geneva Acoustic Parameter Set (eGeMAPS), which includes 25 different attributes associated with perception of speech. Given the non-differentiable nature of these feature computation, we first build differentiable estimators of the eGeMAPS and then use them to fine-tune existing speech enhancement systems. Our approach is generic and can be applied to any existing deep learning based enhancement systems to further improve the enhanced speech signals. Experimental results conducted on the Deep Noise Suppression (DNS) Challenge dataset shows that our approach can improve the state-of-the-art deep learning based enhancement systems.
Fast and efficient speech enhancement with variational autoencoders
Nov 02, 2022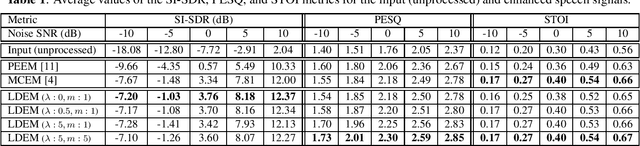
Unsupervised speech enhancement based on variational autoencoders has shown promising performance compared with the commonly used supervised methods. This approach involves the use of a pre-trained deep speech prior along with a parametric noise model, where the noise parameters are learned from the noisy speech signal with an expectationmaximization (EM)-based method. The E-step involves an intractable latent posterior distribution. Existing algorithms to solve this step are either based on computationally heavy Monte Carlo Markov Chain sampling methods and variational inference, or inefficient optimization-based methods. In this paper, we propose a new approach based on Langevin dynamics that generates multiple sequences of samples and comes with a total variation-based regularization to incorporate temporal correlations of latent vectors. Our experiments demonstrate that the developed framework makes an effective compromise between computational efficiency and enhancement quality, and outperforms existing methods.
SpeechLM: Enhanced Speech Pre-Training with Unpaired Textual Data
Sep 30, 2022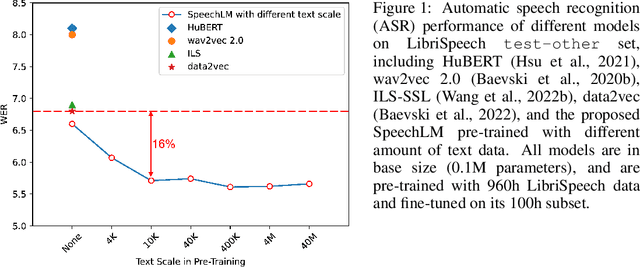
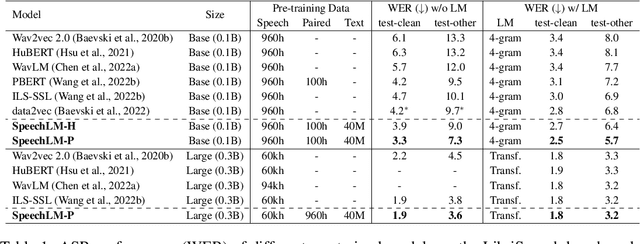
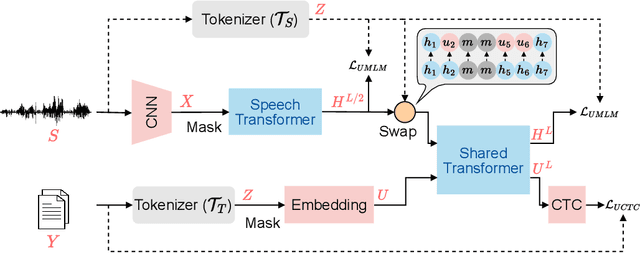
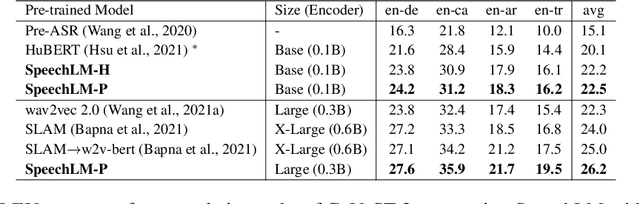
How to boost speech pre-training with textual data is an unsolved problem due to the fact that speech and text are very different modalities with distinct characteristics. In this paper, we propose a cross-modal Speech and Language Model (SpeechLM) to explicitly align speech and text pre-training with a pre-defined unified discrete representation. Specifically, we introduce two alternative discrete tokenizers to bridge the speech and text modalities, including phoneme-unit and hidden-unit tokenizers, which can be trained using a small amount of paired speech-text data. Based on the trained tokenizers, we convert the unlabeled speech and text data into tokens of phoneme units or hidden units. The pre-training objective is designed to unify the speech and the text into the same discrete semantic space with a unified Transformer network. Leveraging only 10K text sentences, our SpeechLM gets a 16\% relative WER reduction over the best base model performance (from 6.8 to 5.7) on the public LibriSpeech ASR benchmark. Moreover, SpeechLM with fewer parameters even outperforms previous SOTA models on CoVoST-2 speech translation tasks. We also evaluate our SpeechLM on various spoken language processing tasks under the universal representation evaluation framework SUPERB, demonstrating significant improvements on content-related tasks. Our code and models are available at https://aka.ms/SpeechLM.
Rethinking Speech Recognition with A Multimodal Perspective via Acoustic and Semantic Cooperative Decoding
May 23, 2023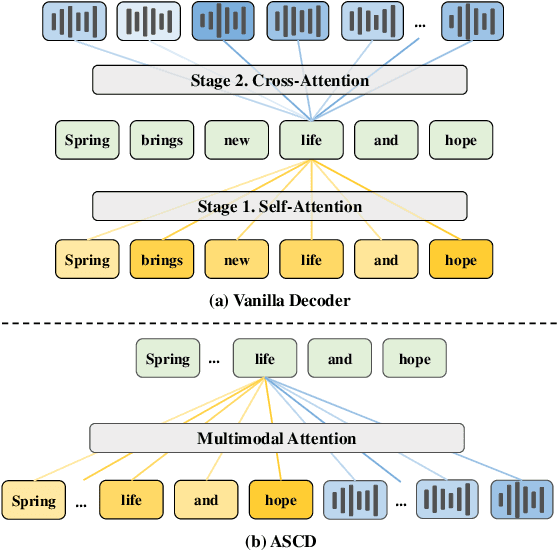
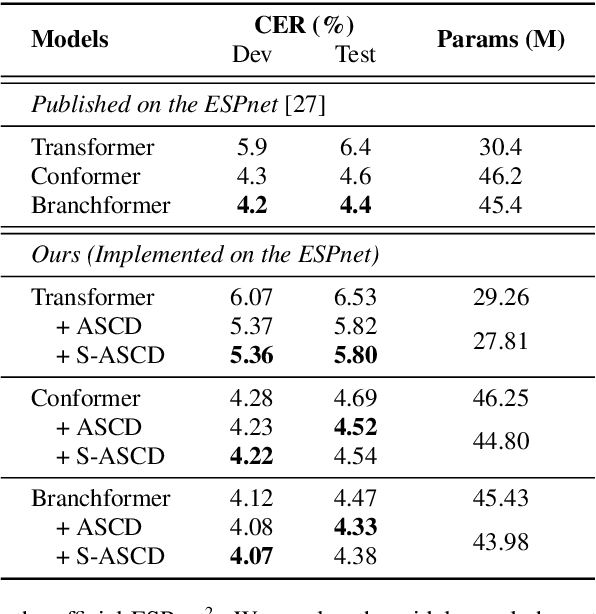
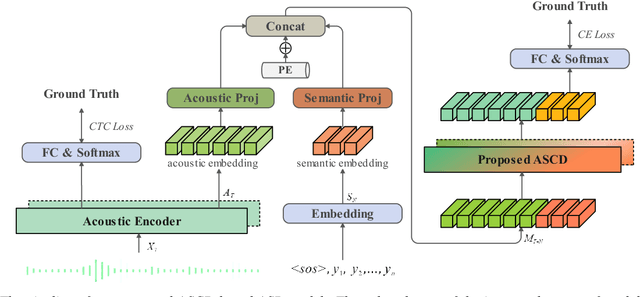
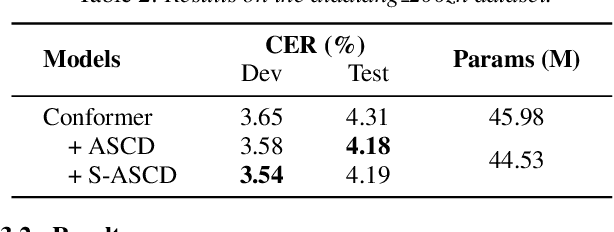
Attention-based encoder-decoder (AED) models have shown impressive performance in ASR. However, most existing AED methods neglect to simultaneously leverage both acoustic and semantic features in decoder, which is crucial for generating more accurate and informative semantic states. In this paper, we propose an Acoustic and Semantic Cooperative Decoder (ASCD) for ASR. In particular, unlike vanilla decoders that process acoustic and semantic features in two separate stages, ASCD integrates them cooperatively. To prevent information leakage during training, we design a Causal Multimodal Mask. Moreover, a variant Semi-ASCD is proposed to balance accuracy and computational cost. Our proposal is evaluated on the publicly available AISHELL-1 and aidatatang_200zh datasets using Transformer, Conformer, and Branchformer as encoders, respectively. The experimental results show that ASCD significantly improves the performance by leveraging both the acoustic and semantic information cooperatively.
Improving Hypernasality Estimation with Automatic Speech Recognition in Cleft Palate Speech
Aug 10, 2022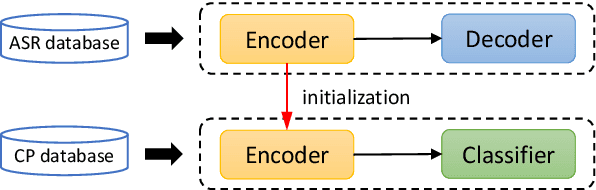
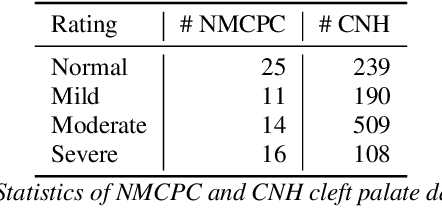
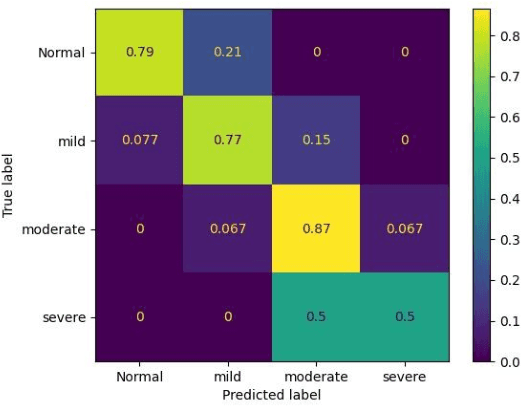
Hypernasality is an abnormal resonance in human speech production, especially in patients with craniofacial anomalies such as cleft palate. In clinical application, hypernasality estimation is crucial in cleft palate diagnosis, as its results determine the subsequent surgery and additional speech therapy. Therefore, designing an automatic hypernasality assessment method will facilitate speech-language pathologists to make precise diagnoses. Existing methods for hypernasality estimation only conduct acoustic analysis based on low-resource cleft palate dataset, by using statistical or neural network-based features. In this paper, we propose a novel approach that uses automatic speech recognition model to improve hypernasality estimation. Specifically, we first pre-train an encoder-decoder framework in an automatic speech recognition (ASR) objective by using speech-to-text dataset, and then fine-tune ASR encoder on the cleft palate dataset for hypernasality estimation. Benefiting from such design, our model for hypernasality estimation can enjoy the advantages of ASR model: 1) compared with low-resource cleft palate dataset, the ASR task usually includes large-scale speech data in the general domain, which enables better model generalization; 2) the text annotations in ASR dataset guide model to extract better acoustic features. Experimental results on two cleft palate datasets demonstrate that our method achieves superior performance compared with previous approaches.