 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Multilingual Dense Retrieval via Generative Pseudo Labeling
Mar 06, 2024Dense retrieval methods have demonstrated promising performance in multilingual information retrieval, where queries and documents can be in different languages. However, dense retrievers typically require a substantial amount of paired data, which poses even greater challenges in multilingual scenarios. This paper introduces UMR, an Unsupervised Multilingual dense Retriever trained without any paired data. Our approach leverages the sequence likelihood estimation capabilities of multilingual language models to acquire pseudo labels for training dense retrievers. We propose a two-stage framework which iteratively improves the performance of multilingual dense retrievers. Experimental results on two benchmark datasets show that UMR outperforms supervised baselines, showcasing the potential of training multilingual retrievers without paired data, thereby enhancing their practicality. Our source code, data, and models are publicly available at https://github.com/MiuLab/UMR
Towards General-Purpose Text-Instruction-Guided Voice Conversion
Sep 25, 2023



This paper introduces a novel voice conversion (VC) model, guided by text instructions such as "articulate slowly with a deep tone" or "speak in a cheerful boyish voice". Unlike traditional methods that rely on reference utterances to determine the attributes of the converted speech, our model adds versatility and specificity to voice conversion. The proposed VC model is a neural codec language model which processes a sequence of discrete codes, resulting in the code sequence of converted speech. It utilizes text instructions as style prompts to modify the prosody and emotional information of the given speech. In contrast to previous approaches, which often rely on employing separate encoders like prosody and content encoders to handle different aspects of the source speech, our model handles various information of speech in an end-to-end manner. Experiments have demonstrated the impressive capabilities of our model in comprehending instructions and delivering reasonable results.
CONVERSER: Few-Shot Conversational Dense Retrieval with Synthetic Data Generation
Sep 13, 2023Conversational search provides a natural interface for information retrieval (IR). Recent approaches have demonstrated promising results in applying dense retrieval to conversational IR. However, training dense retrievers requires large amounts of in-domain paired data. This hinders the development of conversational dense retrievers, as abundant in-domain conversations are expensive to collect. In this paper, we propose CONVERSER, a framework for training conversational dense retrievers with at most 6 examples of in-domain dialogues. Specifically, we utilize the in-context learning capability of large language models to generate conversational queries given a passage in the retrieval corpus. Experimental results on conversational retrieval benchmarks OR-QuAC and TREC CAsT 19 show that the proposed CONVERSER achieves comparable performance to fully-supervised models, demonstrating the effectiveness of our proposed framework in few-shot conversational dense retrieval. All source code and generated datasets are available at https://github.com/MiuLab/CONVERSER
Improving Cascaded Unsupervised Speech Translation with Denoising Back-translation
May 12, 2023



Most of the speech translation models heavily rely on parallel data, which is hard to collect especially for low-resource languages. To tackle this issue, we propose to build a cascaded speech translation system without leveraging any kind of paired data. We use fully unpaired data to train our unsupervised systems and evaluate our results on CoVoST 2 and CVSS. The results show that our work is comparable with some other early supervised methods in some language pairs. While cascaded systems always suffer from severe error propagation problems, we proposed denoising back-translation (DBT), a novel approach to building robust unsupervised neural machine translation (UNMT). DBT successfully increases the BLEU score by 0.7--0.9 in all three translation directions. Moreover, we simplified the pipeline of our cascaded system to reduce inference latency and conducted a comprehensive analysis of every part of our work. We also demonstrate our unsupervised speech translation results on the established website.
Ensemble knowledge distillation of self-supervised speech models
Feb 24, 2023

Distilled self-supervised models have shown competitive performance and efficiency in recent years. However, there is a lack of experience in jointly distilling multiple self-supervised speech models. In our work, we performed Ensemble Knowledge Distillation (EKD) on various self-supervised speech models such as HuBERT, RobustHuBERT, and WavLM. We tried two different aggregation techniques, layerwise-average and layerwise-concatenation, to the representations of different teacher models and found that the former was more effective. On top of that, we proposed a multiple prediction head method for student models to predict different layer outputs of multiple teacher models simultaneously. The experimental results show that our method improves the performance of the distilled models on four downstream speech processing tasks, Phoneme Recognition, Speaker Identification, Emotion Recognition, and Automatic Speech Recognition in the hidden-set track of the SUPERB benchmark.
Model Extraction Attack against Self-supervised Speech Models
Nov 29, 2022



Self-supervised learning (SSL) speech models generate meaningful representations of given clips and achieve incredible performance across various downstream tasks. Model extraction attack (MEA) often refers to an adversary stealing the functionality of the victim model with only query access. In this work, we study the MEA problem against SSL speech model with a small number of queries. We propose a two-stage framework to extract the model. In the first stage, SSL is conducted on the large-scale unlabeled corpus to pre-train a small speech model. Secondly, we actively sample a small portion of clips from the unlabeled corpus and query the target model with these clips to acquire their representations as labels for the small model's second-stage training. Experiment results show that our sampling methods can effectively extract the target model without knowing any information about its model architecture.
Improving generalizability of distilled self-supervised speech processing models under distorted settings
Oct 20, 2022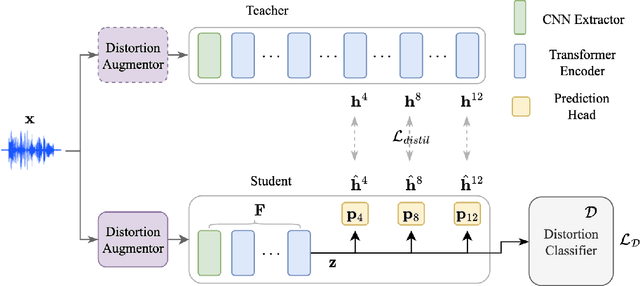
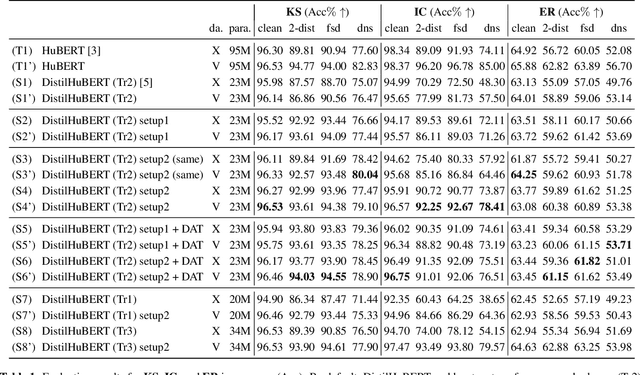
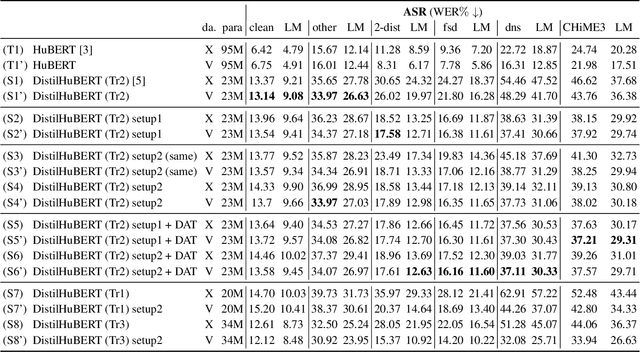
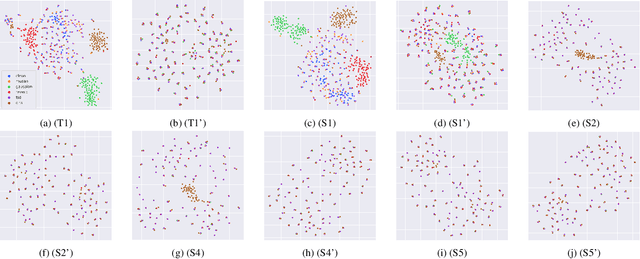
Self-supervised learned (SSL) speech pre-trained models perform well across various speech processing tasks. Distilled versions of SSL models have been developed to match the needs of on-device speech applications. Though having similar performance as original SSL models, distilled counterparts suffer from performance degradation even more than their original versions in distorted environments. This paper proposes to apply Cross-Distortion Mapping and Domain Adversarial Training to SSL models during knowledge distillation to alleviate the performance gap caused by the domain mismatch problem. Results show consistent performance improvements under both in- and out-of-domain distorted setups for different downstream tasks while keeping efficient model size.
The Ability of Self-Supervised Speech Models for Audio Representations
Sep 28, 2022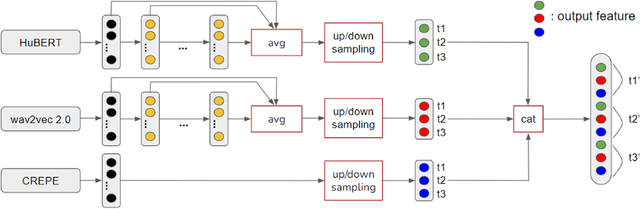
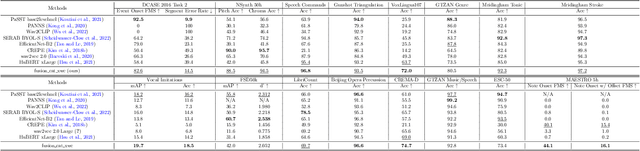

Self-supervised learning (SSL) speech models have achieved unprecedented success in speech representation learning, but some questions regarding their representation ability remain unanswered. This paper addresses two of them: (1) Can SSL speech models deal with non-speech audio?; (2) Would different SSL speech models have insights into diverse aspects of audio features? To answer the two questions, we conduct extensive experiments on abundant speech and non-speech audio datasets to evaluate the representation ability of currently state-of-the-art SSL speech models, which are wav2vec 2.0 and HuBERT in this paper. These experiments are carried out during NeurIPS 2021 HEAR Challenge as a standard evaluation pipeline provided by competition officials. Results show that (1) SSL speech models could extract meaningful features of a wide range of non-speech audio, while they may also fail on certain types of datasets; (2) different SSL speech models have insights into different aspects of audio features. The two conclusions provide a foundation for the ensemble of representation models. We further propose an ensemble framework to fuse speech representation models' embeddings. Our framework outperforms state-of-the-art SSL speech/audio models and has generally superior performance on abundant datasets compared with other teams in HEAR Challenge. Our code is available at https://github.com/tony10101105/HEAR-2021-NeurIPS-Challenge -- NTU-GURA.