 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
ed-cec: improving rare word recognition using asr postprocessing based on error detection and context-aware error correction
Oct 08, 2023
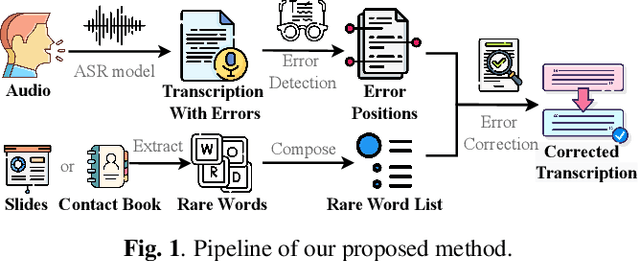
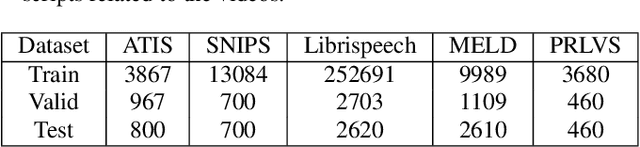
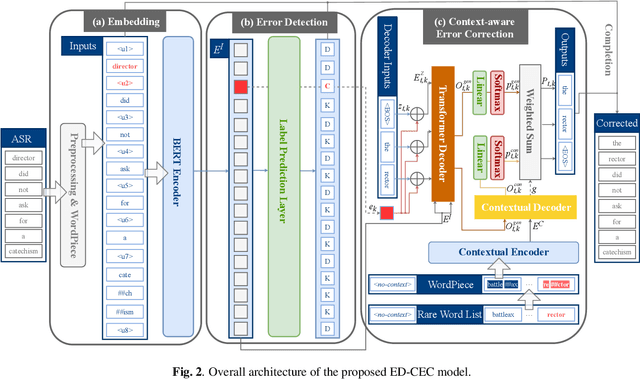
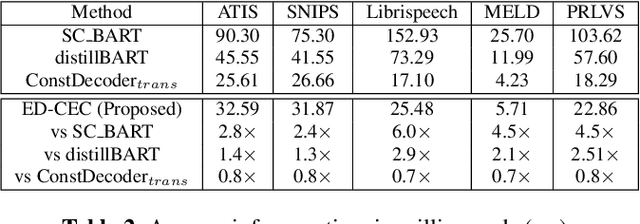
Automatic speech recognition (ASR) systems often encounter difficulties in accurately recognizing rare words, leading to errors that can have a negative impact on downstream tasks such as keyword spotting, intent detection, and text summarization. To address this challenge, we present a novel ASR postprocessing method that focuses on improving the recognition of rare words through error detection and context-aware error correction. Our method optimizes the decoding process by targeting only the predicted error positions, minimizing unnecessary computations. Moreover, we leverage a rare word list to provide additional contextual knowledge, enabling the model to better correct rare words. Experimental results across five datasets demonstrate that our proposed method achieves significantly lower word error rates (WERs) than previous approaches while maintaining a reasonable inference speed. Furthermore, our approach exhibits promising robustness across different ASR systems.
ContextSpeech: Expressive and Efficient Text-to-Speech for Paragraph Reading
Jul 03, 2023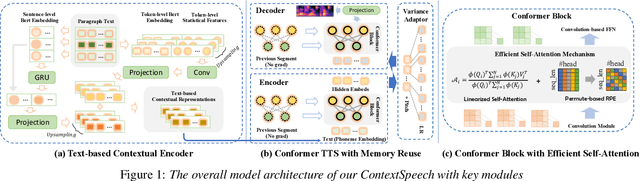

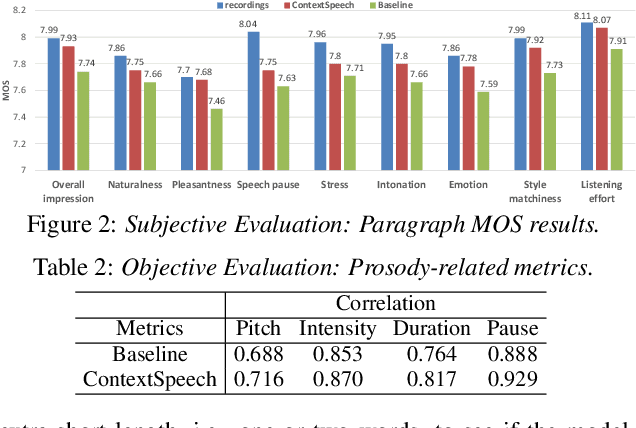
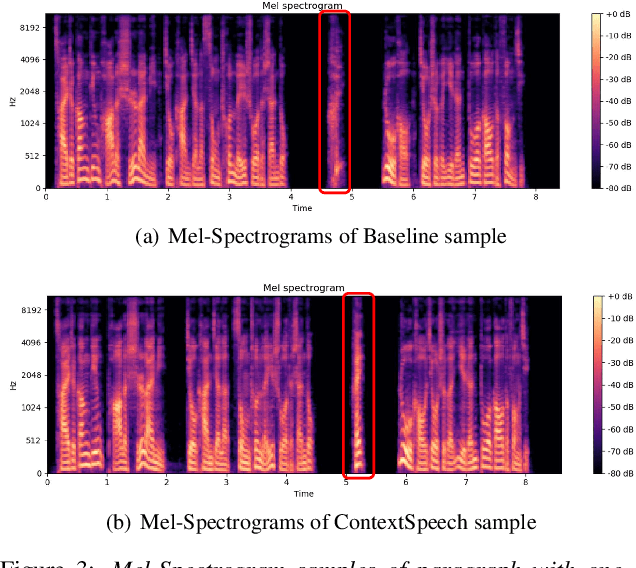
While state-of-the-art Text-to-Speech systems can generate natural speech of very high quality at sentence level, they still meet great challenges in speech generation for paragraph / long-form reading. Such deficiencies are due to i) ignorance of cross-sentence contextual information, and ii) high computation and memory cost for long-form synthesis. To address these issues, this work develops a lightweight yet effective TTS system, ContextSpeech. Specifically, we first design a memory-cached recurrence mechanism to incorporate global text and speech context into sentence encoding. Then we construct hierarchically-structured textual semantics to broaden the scope for global context enhancement. Additionally, we integrate linearized self-attention to improve model efficiency. Experiments show that ContextSpeech significantly improves the voice quality and prosody expressiveness in paragraph reading with competitive model efficiency. Audio samples are available at: https://contextspeech.github.io/demo/
StyleS2ST: Zero-shot Style Transfer for Direct Speech-to-speech Translation
Jun 01, 2023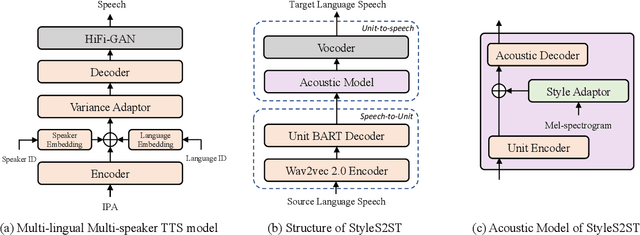
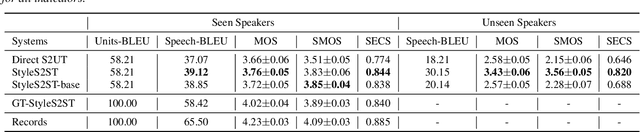
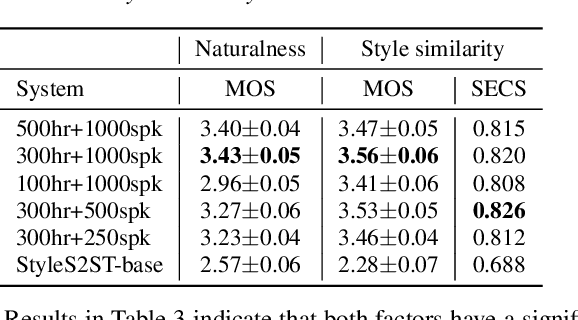
Direct speech-to-speech translation (S2ST) has gradually become popular as it has many advantages compared with cascade S2ST. However, current research mainly focuses on the accuracy of semantic translation and ignores the speech style transfer from a source language to a target language. The lack of high-fidelity expressive parallel data makes such style transfer challenging, especially in more practical zero-shot scenarios. To solve this problem, we first build a parallel corpus using a multi-lingual multi-speaker text-to-speech synthesis (TTS) system and then propose the StyleS2ST model with cross-lingual speech style transfer ability based on a style adaptor on a direct S2ST system framework. Enabling continuous style space modeling of an acoustic model through parallel corpus training and non-parallel TTS data augmentation, StyleS2ST captures cross-lingual acoustic feature mapping from the source to the target language. Experiments show that StyleS2ST achieves good style similarity and naturalness in both in-set and out-of-set zero-shot scenarios.
Contrastive Speaker Embedding With Sequential Disentanglement
Sep 23, 2023Contrastive speaker embedding assumes that the contrast between the positive and negative pairs of speech segments is attributed to speaker identity only. However, this assumption is incorrect because speech signals contain not only speaker identity but also linguistic content. In this paper, we propose a contrastive learning framework with sequential disentanglement to remove linguistic content by incorporating a disentangled sequential variational autoencoder (DSVAE) into the conventional SimCLR framework. The DSVAE aims to disentangle speaker factors from content factors in an embedding space so that only the speaker factors are used for constructing a contrastive loss objective. Because content factors have been removed from the contrastive learning, the resulting speaker embeddings will be content-invariant. Experimental results on VoxCeleb1-test show that the proposed method consistently outperforms SimCLR. This suggests that applying sequential disentanglement is beneficial to learning speaker-discriminative embeddings.
PCNN: A Lightweight Parallel Conformer Neural Network for Efficient Monaural Speech Enhancement
Jul 28, 2023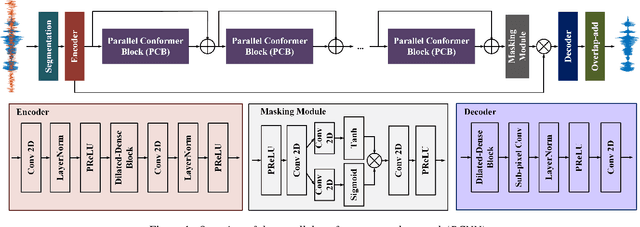
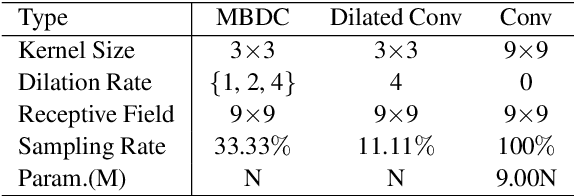
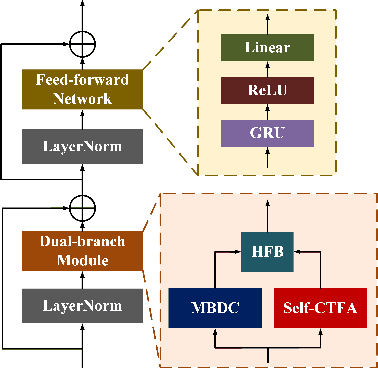
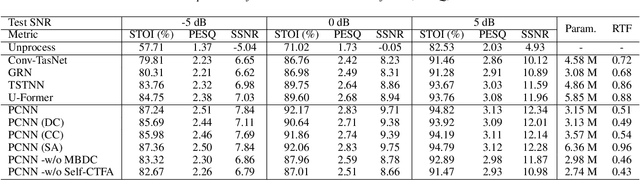
Convolutional neural networks (CNN) and Transformer have wildly succeeded in multimedia applications. However, more effort needs to be made to harmonize these two architectures effectively to satisfy speech enhancement. This paper aims to unify these two architectures and presents a Parallel Conformer for speech enhancement. In particular, the CNN and the self-attention (SA) in the Transformer are fully exploited for local format patterns and global structure representations. Based on the small receptive field size of CNN and the high computational complexity of SA, we specially designed a multi-branch dilated convolution (MBDC) and a self-channel-time-frequency attention (Self-CTFA) module. MBDC contains three convolutional layers with different dilation rates for the feature from local to non-local processing. Experimental results show that our method performs better than state-of-the-art methods in most evaluation criteria while maintaining the lowest model parameters.
Using Text Injection to Improve Recognition of Personal Identifiers in Speech
Aug 14, 2023Accurate recognition of specific categories, such as persons' names, dates or other identifiers is critical in many Automatic Speech Recognition (ASR) applications. As these categories represent personal information, ethical use of this data including collection, transcription, training and evaluation demands special care. One way of ensuring the security and privacy of individuals is to redact or eliminate Personally Identifiable Information (PII) from collection altogether. However, this results in ASR models that tend to have lower recognition accuracy of these categories. We use text-injection to improve the recognition of PII categories by including fake textual substitutes of PII categories in the training data using a text injection method. We demonstrate substantial improvement to Recall of Names and Dates in medical notes while improving overall WER. For alphanumeric digit sequences we show improvements to Character Error Rate and Sentence Accuracy.
Text Injection for Capitalization and Turn-Taking Prediction in Speech Models
Aug 14, 2023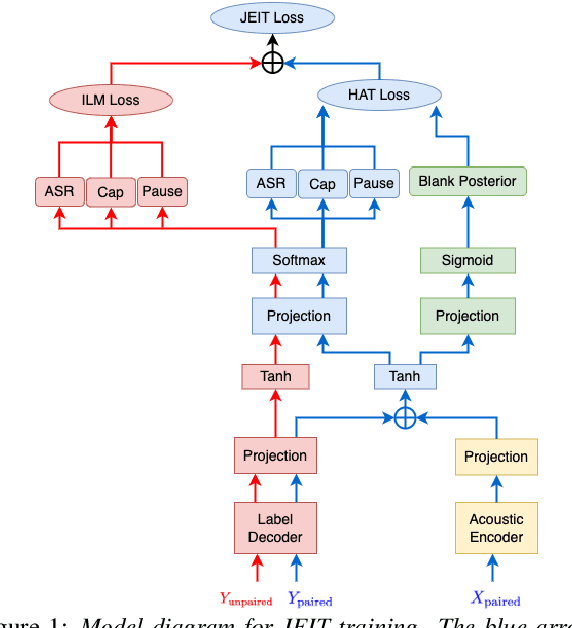
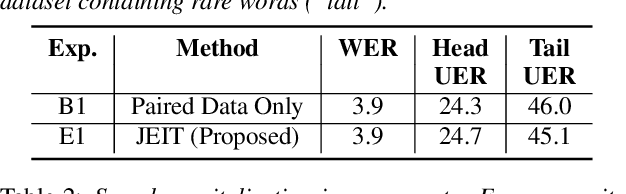

Text injection for automatic speech recognition (ASR), wherein unpaired text-only data is used to supplement paired audio-text data, has shown promising improvements for word error rate. This study examines the use of text injection for auxiliary tasks, which are the non-ASR tasks often performed by an E2E model. In this work, we use joint end-to-end and internal language model training (JEIT) as our text injection algorithm to train an ASR model which performs two auxiliary tasks. The first is capitalization, which is a de-normalization task. The second is turn-taking prediction, which attempts to identify whether a user has completed their conversation turn in a digital assistant interaction. We show results demonstrating that our text injection method boosts capitalization performance for long-tail data, and improves turn-taking detection recall.
Diff-SV: A Unified Hierarchical Framework for Noise-Robust Speaker Verification Using Score-Based Diffusion Probabilistic Models
Sep 14, 2023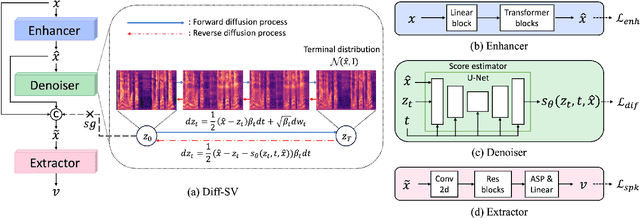
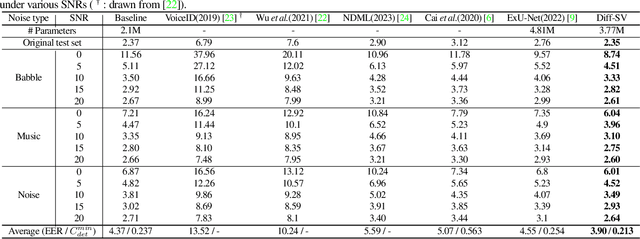
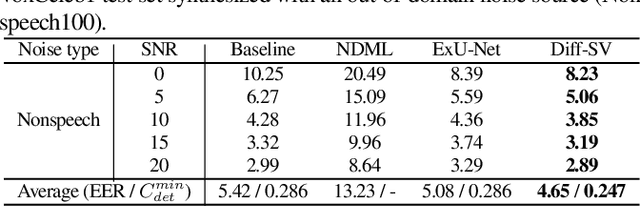
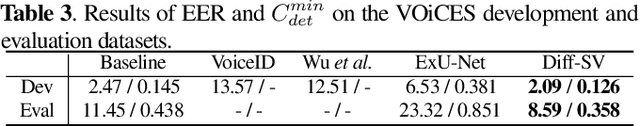
Background noise considerably reduces the accuracy and reliability of speaker verification (SV) systems. These challenges can be addressed using a speech enhancement system as a front-end module. Recently, diffusion probabilistic models (DPMs) have exhibited remarkable noise-compensation capabilities in the speech enhancement domain. Building on this success, we propose Diff-SV, a noise-robust SV framework that leverages DPM. Diff-SV unifies a DPM-based speech enhancement system with a speaker embedding extractor, and yields a discriminative and noise-tolerable speaker representation through a hierarchical structure. The proposed model was evaluated under both in-domain and out-of-domain noisy conditions using the VoxCeleb1 test set, an external noise source, and the VOiCES corpus. The obtained experimental results demonstrate that Diff-SV achieves state-of-the-art performance, outperforming recently proposed noise-robust SV systems.
Knowledge Distilled Ensemble Model for sEMG-based Silent Speech Interface
Aug 07, 2023Voice disorders affect millions of people worldwide. Surface electromyography-based Silent Speech Interfaces (sEMG-based SSIs) have been explored as a potential solution for decades. However, previous works were limited by small vocabularies and manually extracted features from raw data. To address these limitations, we propose a lightweight deep learning knowledge-distilled ensemble model for sEMG-based SSI (KDE-SSI). Our model can classify a 26 NATO phonetic alphabets dataset with 3900 data samples, enabling the unambiguous generation of any English word through spelling. Extensive experiments validate the effectiveness of KDE-SSI, achieving a test accuracy of 85.9\%. Our findings also shed light on an end-to-end system for portable, practical equipment.
Language-Routing Mixture of Experts for Multilingual and Code-Switching Speech Recognition
Jul 14, 2023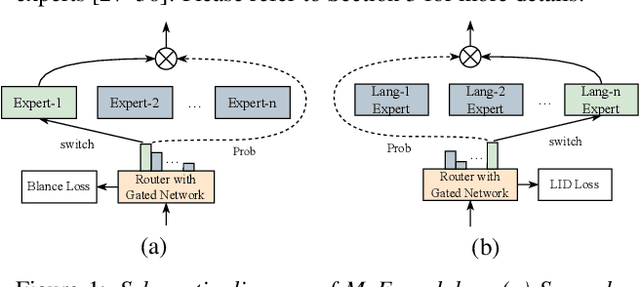
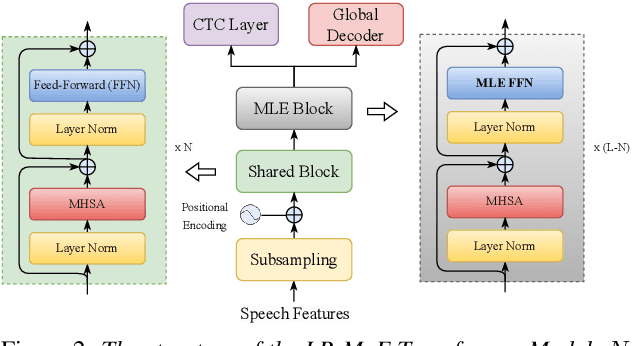
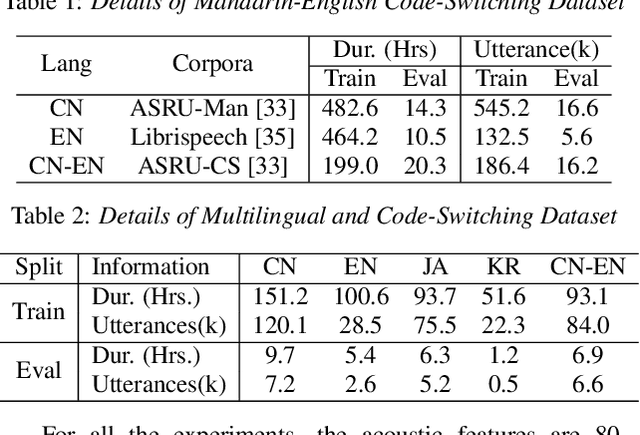
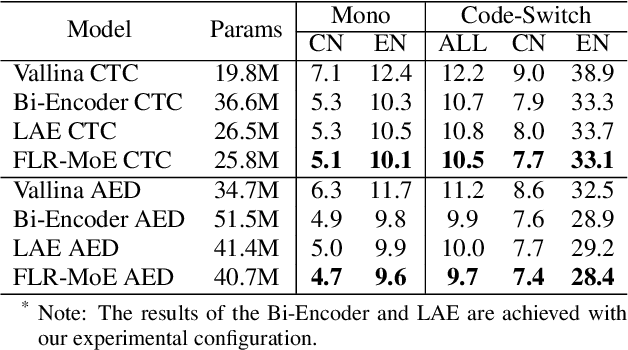
Multilingual speech recognition for both monolingual and code-switching speech is a challenging task. Recently, based on the Mixture of Experts (MoE), many works have made good progress in multilingual and code-switching ASR, but present huge computational complexity with the increase of supported languages. In this work, we propose a computation-efficient network named Language-Routing Mixture of Experts (LR-MoE) for multilingual and code-switching ASR. LR-MoE extracts language-specific representations through the Mixture of Language Experts (MLE), which is guided to learn by a frame-wise language routing mechanism. The weight-shared frame-level language identification (LID) network is jointly trained as the shared pre-router of each MoE layer. Experiments show that the proposed method significantly improves multilingual and code-switching speech recognition performances over baseline with comparable computational efficiency.