 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRSRCC: A Remote Sensing Regional Change Comprehension Benchmark Constructed via Retrieval-Augmented Best-of-N Ranking
Apr 22, 2026Traditional change detection identifies where changes occur, but does not explain what changed in natural language. Existing remote sensing change captioning datasets typically describe overall image-level differences, leaving fine-grained localized semantic reasoning largely unexplored. To close this gap, we present RSRCC, a new benchmark for remote sensing change question-answering containing 126k questions, split into 87k training, 17.1k validation, and 22k test instances. Unlike prior datasets, RSRCC is built around localized, change-specific questions that require reasoning about a particular semantic change. To the best of our knowledge, this is the first remote sensing change question-answering benchmark designed explicitly for such fine-grained reasoning-based supervision. To construct RSRCC, we introduce a hierarchical semi-supervised curation pipeline that uses Best-of-N ranking as a critical final ambiguity-resolution stage. First, candidate change regions are extracted from semantic segmentation masks, then initially screened using an image-text embedding model, and finally validated through retrieval-augmented vision-language curation with Best-of-N ranking. This process enables scalable filtering of noisy and ambiguous candidates while preserving semantically meaningful changes. The dataset is available at https://huggingface.co/datasets/google/RSRCC.
RS-OVC: Open-Vocabulary Counting for Remote-Sensing Data
Apr 09, 2026Object-Counting for remote-sensing (RS) imagery is attracting increasing research interest due to its crucial role in a wide and diverse set of applications. While several promising methods for RS object-counting have been proposed, existing methods focus on a closed, pre-defined set of object classes. This limitation necessitates costly re-annotation and model re-training to adapt current approaches for counting of novel objects that have not been seen during training, and severely inhibits their application in dynamic, real-world monitoring scenarios. To address this gap, in this work we propose RS-OVC - the first Open Vocabulary Counting (OVC) model for Remote-Sensing and aerial imagery. We show that our model is capable of accurate counting of novel object classes, that were unseen during training, based solely on textual and/or visual conditioning.
GroundSet: A Cadastral-Grounded Dataset for Spatial Understanding with Vector Data
Mar 15, 2026Precise spatial understanding in Earth Observation is essential for translating raw aerial imagery into actionable insights for critical applications like urban planning, environmental monitoring and disaster management. However, Multimodal Large Language Models exhibit critical deficiencies in fine-grained spatial understanding within Remote Sensing, primarily due to a reliance on limited or repurposed legacy datasets. To bridge this gap, we introduce a large-scale dataset grounded in verifiable cadastral vector data, comprising 3.8 million annotated objects across 510k high-resolution images with 135 granular semantic categories. We validate this resource through a comprehensive instruction-tuning benchmark spanning seven spatial reasoning tasks. Our evaluation establishes a robust baseline using a standard LLaVA architecture. We show that while current RS-specialized and commercial models (e.g., Gemini) struggle in zero-shot settings, high-fidelity supervision effectively bridges this gap, enabling standard architectures to master fine-grained spatial grounding without complex architectural modifications.
Using Text Injection to Improve Recognition of Personal Identifiers in Speech
Aug 14, 2023



Accurate recognition of specific categories, such as persons' names, dates or other identifiers is critical in many Automatic Speech Recognition (ASR) applications. As these categories represent personal information, ethical use of this data including collection, transcription, training and evaluation demands special care. One way of ensuring the security and privacy of individuals is to redact or eliminate Personally Identifiable Information (PII) from collection altogether. However, this results in ASR models that tend to have lower recognition accuracy of these categories. We use text-injection to improve the recognition of PII categories by including fake textual substitutes of PII categories in the training data using a text injection method. We demonstrate substantial improvement to Recall of Names and Dates in medical notes while improving overall WER. For alphanumeric digit sequences we show improvements to Character Error Rate and Sentence Accuracy.
RED-ACE: Robust Error Detection for ASR using Confidence Embeddings
Mar 14, 2022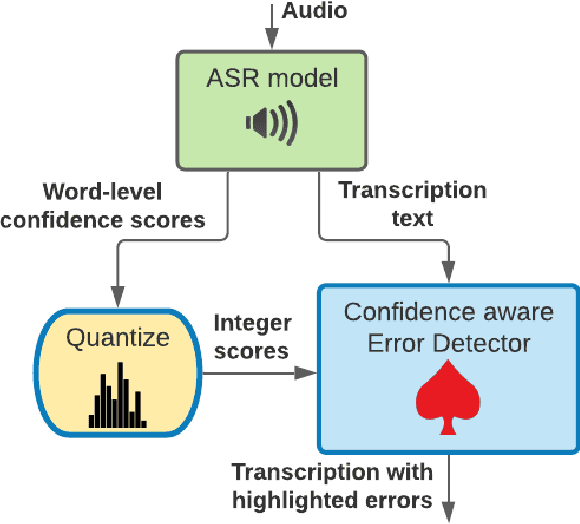
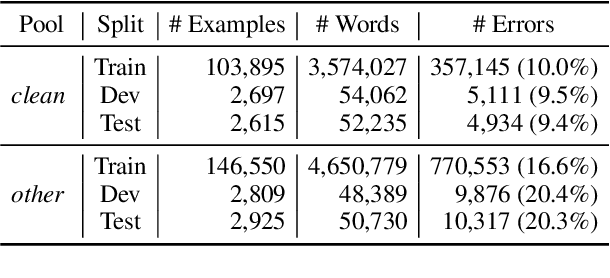
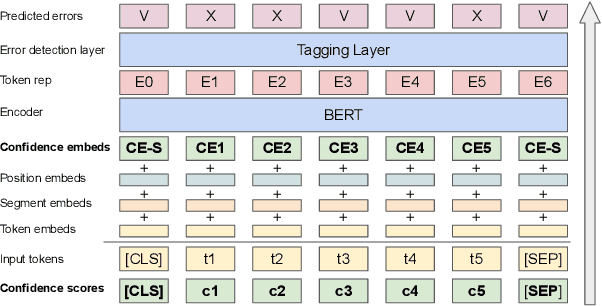
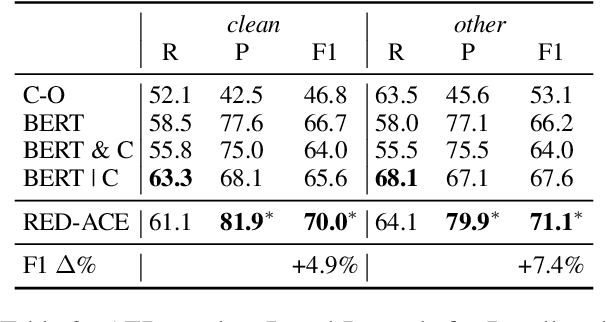
ASR Error Detection (AED) models aim to post-process the output of Automatic Speech Recognition (ASR) systems, in order to detect transcription errors. Modern approaches usually use text-based input, comprised solely of the ASR transcription hypothesis, disregarding additional signals from the ASR model. Instead, we propose to utilize the ASR system's word-level confidence scores for improving AED performance. Specifically, we add an ASR Confidence Embedding (ACE) layer to the AED model's encoder, allowing us to jointly encode the confidence scores and the transcribed text into a contextualized representation. Our experiments show the benefits of ASR confidence scores for AED, their complementary effect over the textual signal, as well as the effectiveness and robustness of ACE for combining these signals. To foster further research, we publish a novel AED dataset consisting of ASR outputs on the LibriSpeech corpus with annotated transcription errors.
KoBE: Knowledge-Based Machine Translation Evaluation
Sep 23, 2020
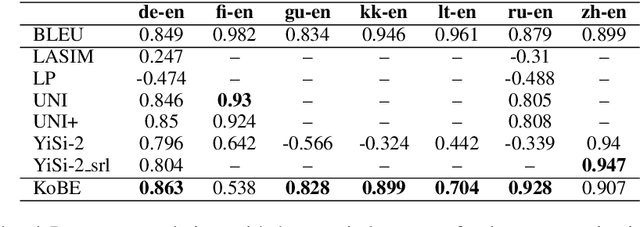
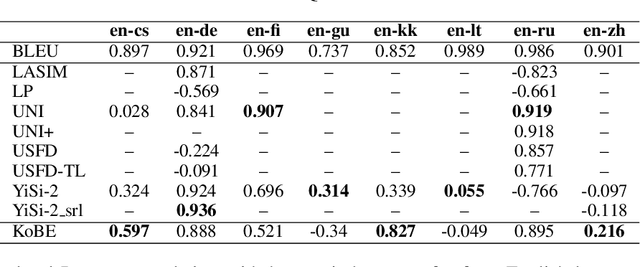
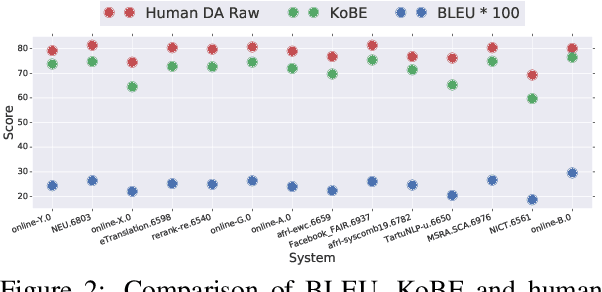
We propose a simple and effective method for machine translation evaluation which does not require reference translations. Our approach is based on (1) grounding the entity mentions found in each source sentence and candidate translation against a large-scale multilingual knowledge base, and (2) measuring the recall of the grounded entities found in the candidate vs. those found in the source. Our approach achieves the highest correlation with human judgements on 9 out of the 18 language pairs from the WMT19 benchmark for evaluation without references, which is the largest number of wins for a single evaluation method on this task. On 4 language pairs, we also achieve higher correlation with human judgements than BLEU. To foster further research, we release a dataset containing 1.8 million grounded entity mentions across 18 language pairs from the WMT19 metrics track data.
A Joint Named-Entity Recognizer for Heterogeneous Tag-setsUsing a Tag Hierarchy
May 22, 2019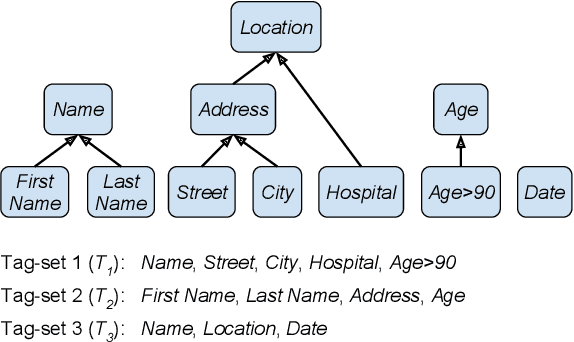
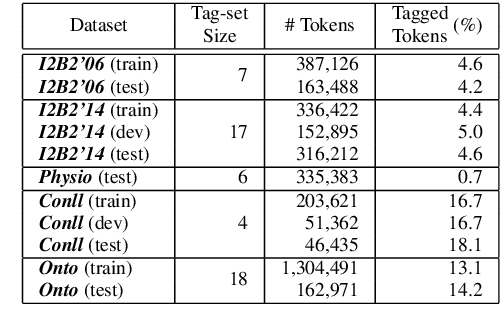
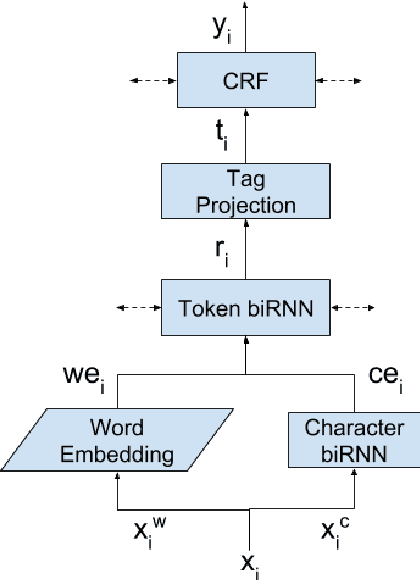

We study a variant of domain adaptation for named-entity recognition where multiple, heterogeneously tagged training sets are available. Furthermore, the test tag-set is not identical to any individual training tag-set. Yet, the relations between all tags are provided in a tag hierarchy, covering the test tags as a combination of training tags. This setting occurs when various datasets are created using different annotation schemes. This is also the case of extending a tag-set with a new tag by annotating only the new tag in a new dataset. We propose to use the given tag hierarchy to jointly learn a neural network that shares its tagging layer among all tag-sets. We compare this model to combining independent models and to a model based on the multitasking approach. Our experiments show the benefit of the tag-hierarchy model, especially when facing non-trivial consolidation of tag-sets.
Audio De-identification: A New Entity Recognition Task
Mar 17, 2019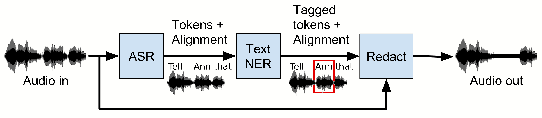
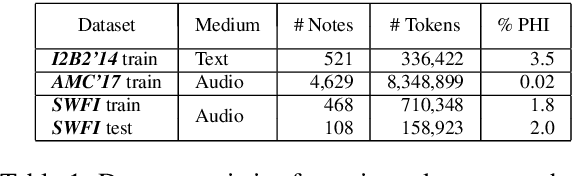
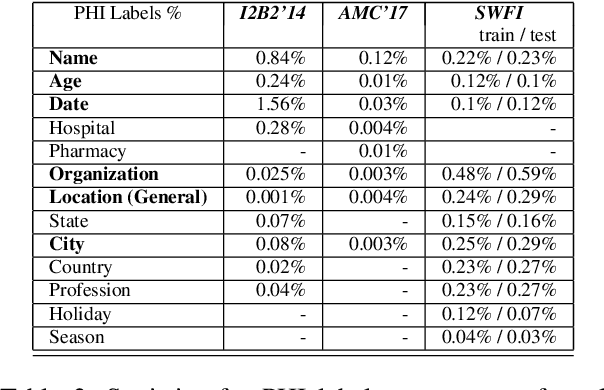
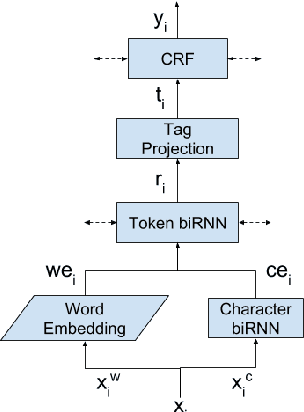
Named Entity Recognition (NER) has been mostly studied in the context of written text. Specifically, NER is an important step in de-identification (de-ID) of medical records, many of which are recorded conversations between a patient and a doctor. In such recordings, audio spans with personal information should be redacted, similar to the redaction of sensitive character spans in de-ID for written text. The application of NER in the context of audio de-identification has yet to be fully investigated. To this end, we define the task of audio de-ID, in which audio spans with entity mentions should be detected. We then present our pipeline for this task, which involves Automatic Speech Recognition (ASR), NER on the transcript text, and text-to-audio alignment. Finally, we introduce a novel metric for audio de-ID and a new evaluation benchmark consisting of a large labeled segment of the Switchboard and Fisher audio datasets and detail our pipeline's results on it.