 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Modelling prospective memory and resilient situated communications via Wizard of Oz
Nov 09, 2023
This abstract presents a scenario for human-robot action in a home setting involving an older adult and a robot. The scenario is designed to explore the envisioned modelling of memory for communication with a socially assistive robots (SAR). The scenario will enable the gathering of data on failures of speech technology and human-robot communication involving shared memory that may occur during daily activities such as a music-listening activity.
Investigating Weight-Perturbed Deep Neural Networks With Application in Iris Presentation Attack Detection
Nov 21, 2023Deep neural networks (DNNs) exhibit superior performance in various machine learning tasks, e.g., image classification, speech recognition, biometric recognition, object detection, etc. However, it is essential to analyze their sensitivity to parameter perturbations before deploying them in real-world applications. In this work, we assess the sensitivity of DNNs against perturbations to their weight and bias parameters. The sensitivity analysis involves three DNN architectures (VGG, ResNet, and DenseNet), three types of parameter perturbations (Gaussian noise, weight zeroing, and weight scaling), and two settings (entire network and layer-wise). We perform experiments in the context of iris presentation attack detection and evaluate on two publicly available datasets: LivDet-Iris-2017 and LivDet-Iris-2020. Based on the sensitivity analysis, we propose improved models simply by perturbing parameters of the network without undergoing training. We further combine these perturbed models at the score-level and at the parameter-level to improve the performance over the original model. The ensemble at the parameter-level shows an average improvement of 43.58% on the LivDet-Iris-2017 dataset and 9.25% on the LivDet-Iris-2020 dataset. The source code is available at \href{https://github.com/redwankarimsony/WeightPerturbation-MSU}{https://github.com/redwankarimsony/WeightPerturbation-MSU}.
Discrete Audio Representation as an Alternative to Mel-Spectrograms for Speaker and Speech Recognition
Sep 19, 2023Discrete audio representation, aka audio tokenization, has seen renewed interest driven by its potential to facilitate the application of text language modeling approaches in audio domain. To this end, various compression and representation-learning based tokenization schemes have been proposed. However, there is limited investigation into the performance of compression-based audio tokens compared to well-established mel-spectrogram features across various speaker and speech related tasks. In this paper, we evaluate compression based audio tokens on three tasks: Speaker Verification, Diarization and (Multi-lingual) Speech Recognition. Our findings indicate that (i) the models trained on audio tokens perform competitively, on average within $1\%$ of mel-spectrogram features for all the tasks considered, and do not surpass them yet. (ii) these models exhibit robustness for out-of-domain narrowband data, particularly in speaker tasks. (iii) audio tokens allow for compression to 20x compared to mel-spectrogram features with minimal loss of performance in speech and speaker related tasks, which is crucial for low bit-rate applications, and (iv) the examined Residual Vector Quantization (RVQ) based audio tokenizer exhibits a low-pass frequency response characteristic, offering a plausible explanation for the observed results, and providing insight for future tokenizer designs.
CleanUNet 2: A Hybrid Speech Denoising Model on Waveform and Spectrogram
Sep 12, 2023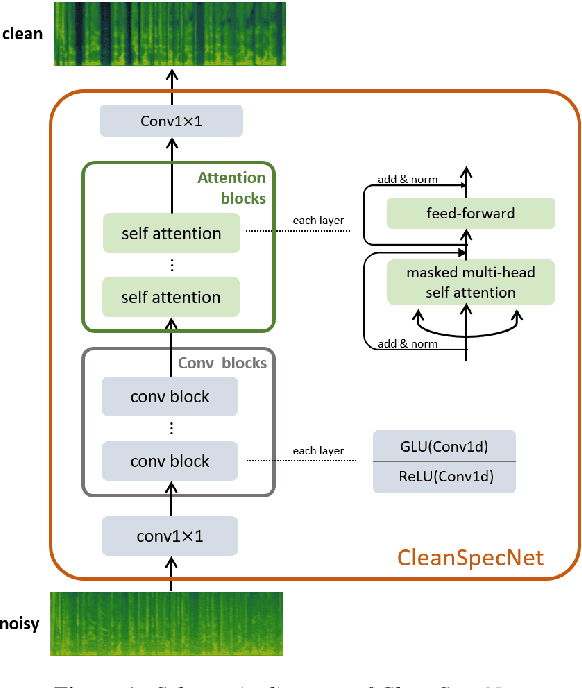
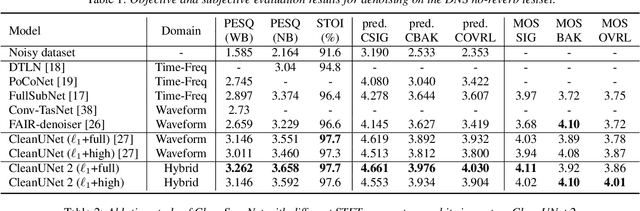
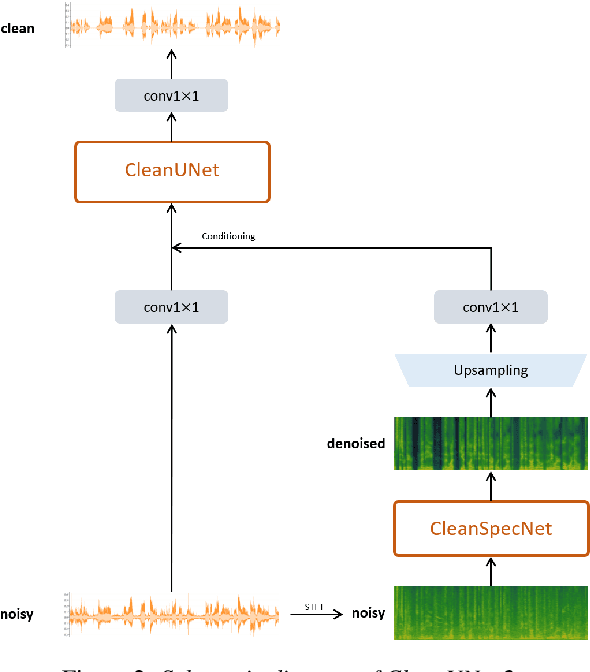
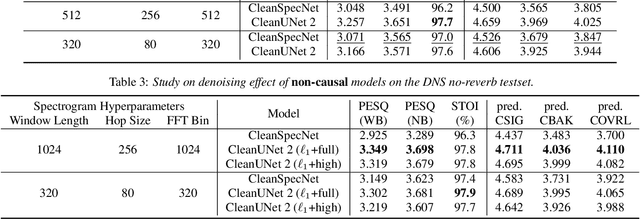
In this work, we present CleanUNet 2, a speech denoising model that combines the advantages of waveform denoiser and spectrogram denoiser and achieves the best of both worlds. CleanUNet 2 uses a two-stage framework inspired by popular speech synthesis methods that consist of a waveform model and a spectrogram model. Specifically, CleanUNet 2 builds upon CleanUNet, the state-of-the-art waveform denoiser, and further boosts its performance by taking predicted spectrograms from a spectrogram denoiser as the input. We demonstrate that CleanUNet 2 outperforms previous methods in terms of various objective and subjective evaluations.
* INTERSPEECH 2023
Folding Attention: Memory and Power Optimization for On-Device Transformer-based Streaming Speech Recognition
Sep 14, 2023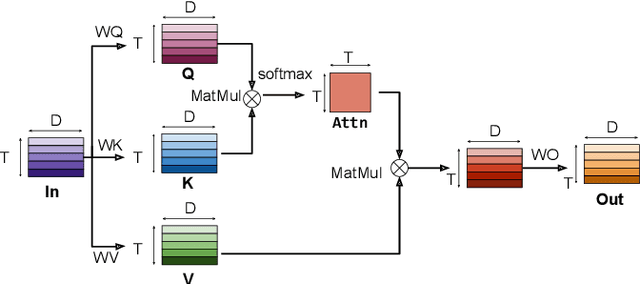
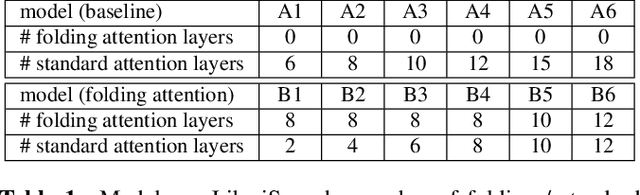
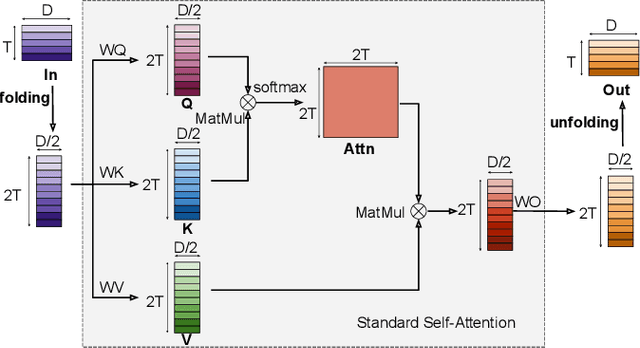
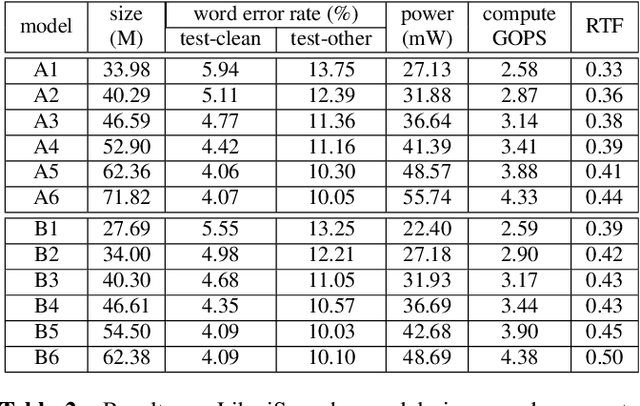
Transformer-based models excel in speech recognition. Existing efforts to optimize Transformer inference, typically for long-context applications, center on simplifying attention score calculations. However, streaming speech recognition models usually process a limited number of tokens each time, making attention score calculation less of a bottleneck. Instead, the bottleneck lies in the linear projection layers of multi-head attention and feedforward networks, constituting a substantial portion of the model size and contributing significantly to computation, memory, and power usage. To address this bottleneck, we propose folding attention, a technique targeting these linear layers, significantly reducing model size and improving memory and power efficiency. Experiments on on-device Transformer-based streaming speech recognition models show that folding attention reduces model size (and corresponding memory consumption) by up to 24% and power consumption by up to 23%, all without compromising model accuracy or computation overhead.
Brain-Driven Representation Learning Based on Diffusion Model
Nov 14, 2023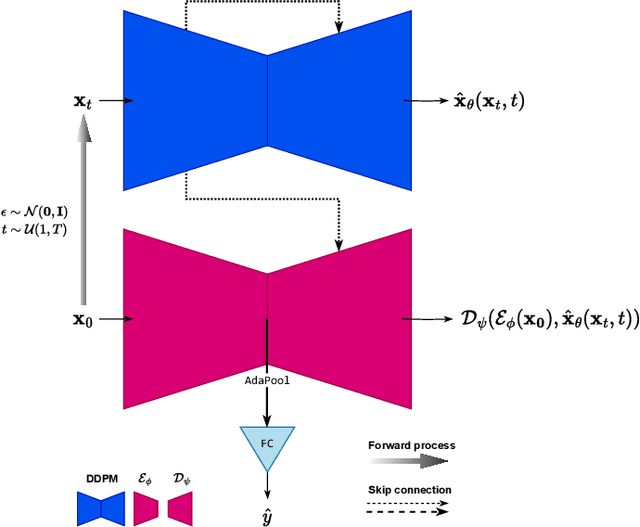


Interpreting EEG signals linked to spoken language presents a complex challenge, given the data's intricate temporal and spatial attributes, as well as the various noise factors. Denoising diffusion probabilistic models (DDPMs), which have recently gained prominence in diverse areas for their capabilities in representation learning, are explored in our research as a means to address this issue. Using DDPMs in conjunction with a conditional autoencoder, our new approach considerably outperforms traditional machine learning algorithms and established baseline models in accuracy. Our results highlight the potential of DDPMs as a sophisticated computational method for the analysis of speech-related EEG signals. This could lead to significant advances in brain-computer interfaces tailored for spoken communication.
SALMONN: Towards Generic Hearing Abilities for Large Language Models
Oct 20, 2023Hearing is arguably an essential ability of artificial intelligence (AI) agents in the physical world, which refers to the perception and understanding of general auditory information consisting of at least three types of sounds: speech, audio events, and music. In this paper, we propose SALMONN, a speech audio language music open neural network, built by integrating a pre-trained text-based large language model (LLM) with speech and audio encoders into a single multimodal model. SALMONN enables the LLM to directly process and understand general audio inputs and achieve competitive performances on a number of speech and audio tasks used in training, such as automatic speech recognition and translation, auditory-information-based question answering, emotion recognition, speaker verification, and music and audio captioning \textit{etc.} SALMONN also has a diverse set of emergent abilities unseen in the training, which includes but is not limited to speech translation to untrained languages, speech-based slot filling, spoken-query-based question answering, audio-based storytelling, and speech audio co-reasoning \textit{etc}. The presence of the cross-modal emergent abilities is studied, and a novel few-shot activation tuning approach is proposed to activate such abilities of SALMONN. To our knowledge, SALMONN is the first model of its type and can be regarded as a step towards AI with generic hearing abilities. An interactive demo of SALMONN is available at \texttt{\url{https://github.com/bytedance/SALMONN}}, and the training code and model checkpoints will be released upon acceptance.
Prompting and Adapter Tuning for Self-supervised Encoder-Decoder Speech Model
Oct 04, 2023Prompting and adapter tuning have emerged as efficient alternatives to fine-tuning (FT) methods. However, existing studies on speech prompting focused on classification tasks and failed on more complex sequence generation tasks. Besides, adapter tuning is primarily applied with a focus on encoder-only self-supervised models. Our experiments show that prompting on Wav2Seq, a self-supervised encoder-decoder model, surpasses previous works in sequence generation tasks. It achieves a remarkable 53% relative improvement in word error rate for ASR and a 27% in F1 score for slot filling. Additionally, prompting competes with the FT method in the low-resource scenario. Moreover, we show the transferability of prompting and adapter tuning on Wav2Seq in cross-lingual ASR. When limited trainable parameters are involved, prompting and adapter tuning consistently outperform conventional FT across 7 languages. Notably, in the low-resource scenario, prompting consistently outperforms adapter tuning.
MSAC: Multiple Speech Attribute Control Method for Speech Emotion Recognition
Aug 08, 2023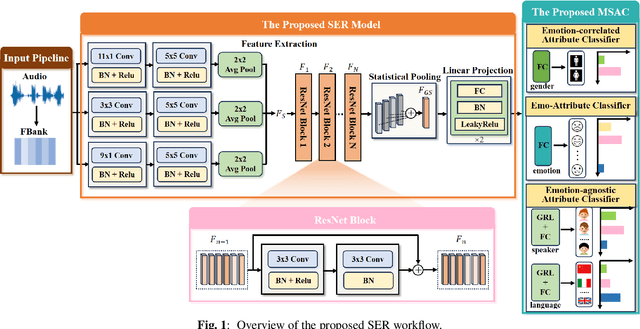


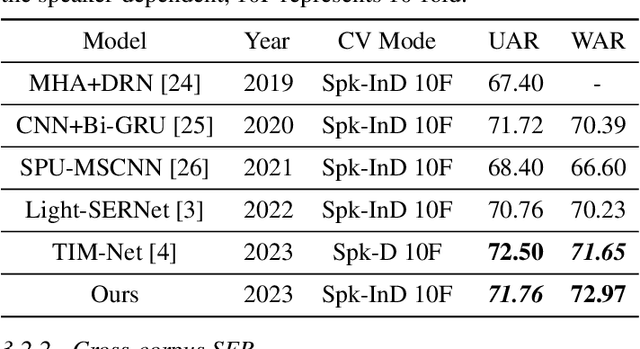
Despite significant progress, speech emotion recognition (SER) remains challenging due to inherent complexity and ambiguity of the emotion attribute, particularly in wild world. Whereas current studies primarily focus on recognition and generalization capabilities, this work pioneers an exploration into the reliability of SER methods and investigates how to model the speech emotion from the aspect of data distribution across various speech attributes. Specifically, we first build a novel CNN-based SER model which adopts additive margin softmax loss to expand the distance between features of different classes, thereby enhancing their discrimination. Second, a novel multiple speech attribute control method MSAC is proposed to explicitly control speech attributes, enabling the model to be less affected by emotion-agnostic attributes and capture more fine-grained emotion-related features. Third, we make a first attempt to test and analyze the reliability of the proposed SER workflow using the out-of-distribution detection method. Extensive experiments on both single and cross-corpus SER scenarios show that our proposed unified SER workflow consistently outperforms the baseline in terms of recognition, generalization, and reliability performance. Besides, in single-corpus SER, the proposed SER workflow achieves superior recognition results with a WAR of 72.97\% and a UAR of 71.76\% on the IEMOCAP corpus.
IruMozhi: Automatically classifying diglossia in Tamil
Nov 13, 2023Tamil, a Dravidian language of South Asia, is a highly diglossic language with two very different registers in everyday use: Literary Tamil (preferred in writing and formal communication) and Spoken Tamil (confined to speech and informal media). Spoken Tamil is under-supported in modern NLP systems. In this paper, we release IruMozhi, a human-annotated dataset of parallel text in Literary and Spoken Tamil. We train classifiers on the task of identifying which variety a text belongs to. We use these models to gauge the availability of pretraining data in Spoken Tamil, to audit the composition of existing labelled datasets for Tamil, and to encourage future work on the variety.