 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Single-Image Facial Demorphing using Multimodal Large Language Models
May 25, 2026Face recognition systems are increasingly vulnerable to morphing attacks, where a composite image is crafted to match multiple identities, enabling unauthorized access and identity fraud. Existing detection methods identify morphed images but cannot recover constituent images or identities, limiting their forensic utility. This paper presents a novel reference-free facial demorphing framework that leverages Multimodal Large Language Models (MLLMs) to guide a coupled diffusion-based reconstruction process. Our key innovation lies in extracting semantic embeddings from intermediate MLLM layers to condition the demorphing, providing high-level reasoning about facial attributes and identity cues that complement low-level pixel information. We formulate demorphing as a coupled conditional generation problem, where both constituent faces are synthesized jointly through a denoising diffusion model operating directly in the RGB domain, ensuring inter-identity consistency while preserving fine-grained perceptual details. Unlike prior approaches that rely on compressed latent representations or assume identity overlap between training and testing sets, our method bypasses lossy text generation-reencoding cycles by directly utilizing MLLM hidden states as conditioning signals, enabling the denoising network to attend to subtle visual cues such as hair, background, and facial textures. Ablation studies further reveal that middle MLLM layers encode more identity-discriminative representations, RGB-domain demorphing outperforms latent-space approaches by 30--40\% at strict operating points, and full MLLM embeddings provide substantial advantages over raw ViT features through enhanced semantic structuring from multimodal pretraining.
S2H-DPO: Hardness-Aware Preference Optimization for Vision-Language Models
Apr 20, 2026Vision-Language Models (VLMs) have demonstrated remarkable progress in single-image understanding, yet effective reasoning across multiple images remains challenging. We identify a critical capability gap in existing multi-image alignment approaches: current methods focus primarily on localized reasoning with pre-specified image indices (``Look at Image 3 and...''), bypassing the essential skills of global visual search and autonomous cross-image comparison. To address this limitation, we introduce a Simple-to-Hard (S2H) learning framework that systematically constructs multi-image preference data across three hierarchical reasoning levels requiring an increasing level of capabilities: (1) single-image localized reasoning, (2) multi-image localized comparison, and (3) global visual search. Unlike prior work that relies on model-specific attributes, such as hallucinations or attention heuristics, to generate preference pairs, our approach leverages prompt-driven complexity to create chosen/rejected pairs that are applicable across different models. Through extensive evaluations on LLaVA and Qwen-VL models, we show that our diverse multi-image reasoning data significantly enhances multi-image reasoning performance, yielding significant improvements over baseline methods across benchmarks. Importantly, our approach maintains strong single-image reasoning performance while simultaneously strengthening multi-image understanding capabilities, thus advancing the state of the art for holistic visual preference alignment.
Are Face Embeddings Compatible Across Deep Neural Network Models?
Apr 08, 2026Automated face recognition has made rapid strides over the past decade due to the unprecedented rise of deep neural network (DNN) models that can be trained for domain-specific tasks. At the same time, foundation models that are pretrained on broad vision or vision-language tasks have shown impressive generalization across diverse domains, including biometrics. This raises an important question: Do different DNN models--both domain-specific and foundation models--encode facial identity in similar ways, despite being trained on different datasets, loss functions, and architectures? In this regard, we directly analyze the geometric structure of embedding spaces imputed by different DNN models. Treating embeddings of face images as point clouds, we study whether simple affine transformations can align face representations of one model with another. Our findings reveal surprising cross-model compatibility: low-capacity linear mappings substantially improve cross-model face recognition over unaligned baselines for both face identification and verification tasks. Alignment patterns generalize across datasets and vary systematically across model families, indicating representational convergence in facial identity encoding. These findings have implications for model interoperability, ensemble design, and biometric template security.
Beyond Mortality: Advancements in Post-Mortem Iris Recognition through Data Collection and Computer-Aided Forensic Examination
Mar 27, 2026Post-mortem iris recognition brings both hope to the forensic community (a short-term but accurate and fast means of verifying identity) as well as concerns to society (its potential illicit use in post-mortem impersonation). These hopes and concerns have grown along with the volume of research in post-mortem iris recognition. Barriers to further progress in post-mortem iris recognition include the difficult nature of data collection, and the resulting small number of approaches designed specifically for comparing iris images of deceased subjects. This paper makes several unique contributions to mitigate these barriers. First, we have collected and we offer a new dataset of NIR (compliant with ISO/IEC 19794-6 where possible) and visible-light iris images collected after demise from 259 subjects, with the largest PMI (post-mortem interval) being 1,674 hours. For one subject, the data has been collected before and after death, the first such case ever published. Second, the collected dataset was combined with publicly-available post-mortem samples to assess the current state of the art in automatic forensic iris recognition with five iris recognition methods and data originating from 338 deceased subjects. These experiments include analyses of how selected demographic factors influence recognition performance. Thirdly, this study implements a model for detecting post-mortem iris images, which can be considered as presentation attacks. Finally, we offer an open-source forensic tool integrating three post-mortem iris recognition methods with explainability elements added to make the comparison process more human-interpretable.
A Multi-domain Image Translative Diffusion StyleGAN for Iris Presentation Attack Detection
Oct 16, 2025An iris biometric system can be compromised by presentation attacks (PAs) where artifacts such as artificial eyes, printed eye images, or cosmetic contact lenses are presented to the system. To counteract this, several presentation attack detection (PAD) methods have been developed. However, there is a scarcity of datasets for training and evaluating iris PAD techniques due to the implicit difficulties in constructing and imaging PAs. To address this, we introduce the Multi-domain Image Translative Diffusion StyleGAN (MID-StyleGAN), a new framework for generating synthetic ocular images that captures the PA and bonafide characteristics in multiple domains such as bonafide, printed eyes and cosmetic contact lens. MID-StyleGAN combines the strengths of diffusion models and generative adversarial networks (GANs) to produce realistic and diverse synthetic data. Our approach utilizes a multi-domain architecture that enables the translation between bonafide ocular images and different PA domains. The model employs an adaptive loss function tailored for ocular data to maintain domain consistency. Extensive experiments demonstrate that MID-StyleGAN outperforms existing methods in generating high-quality synthetic ocular images. The generated data was used to significantly enhance the performance of PAD systems, providing a scalable solution to the data scarcity problem in iris and ocular biometrics. For example, on the LivDet2020 dataset, the true detect rate at 1% false detect rate improved from 93.41% to 98.72%, showcasing the impact of the proposed method.
Impact of Phonetics on Speaker Identity in Adversarial Voice Attack
Sep 18, 2025Adversarial perturbations in speech pose a serious threat to automatic speech recognition (ASR) and speaker verification by introducing subtle waveform modifications that remain imperceptible to humans but can significantly alter system outputs. While targeted attacks on end-to-end ASR models have been widely studied, the phonetic basis of these perturbations and their effect on speaker identity remain underexplored. In this work, we analyze adversarial audio at the phonetic level and show that perturbations exploit systematic confusions such as vowel centralization and consonant substitutions. These distortions not only mislead transcription but also degrade phonetic cues critical for speaker verification, leading to identity drift. Using DeepSpeech as our ASR target, we generate targeted adversarial examples and evaluate their impact on speaker embeddings across genuine and impostor samples. Results across 16 phonetically diverse target phrases demonstrate that adversarial audio induces both transcription errors and identity drift, highlighting the need for phonetic-aware defenses to ensure the robustness of ASR and speaker recognition systems.
Benchmarking Foundation Models for Zero-Shot Biometric Tasks
May 30, 2025The advent of foundation models, particularly Vision-Language Models (VLMs) and Multi-modal Large Language Models (MLLMs), has redefined the frontiers of artificial intelligence, enabling remarkable generalization across diverse tasks with minimal or no supervision. Yet, their potential in biometric recognition and analysis remains relatively underexplored. In this work, we introduce a comprehensive benchmark that evaluates the zero-shot and few-shot performance of state-of-the-art publicly available VLMs and MLLMs across six biometric tasks spanning the face and iris modalities: face verification, soft biometric attribute prediction (gender and race), iris recognition, presentation attack detection (PAD), and face manipulation detection (morphs and deepfakes). A total of 41 VLMs were used in this evaluation. Experiments show that embeddings from these foundation models can be used for diverse biometric tasks with varying degrees of success. For example, in the case of face verification, a True Match Rate (TMR) of 96.77 percent was obtained at a False Match Rate (FMR) of 1 percent on the Labeled Face in the Wild (LFW) dataset, without any fine-tuning. In the case of iris recognition, the TMR at 1 percent FMR on the IITD-R-Full dataset was 97.55 percent without any fine-tuning. Further, we show that applying a simple classifier head to these embeddings can help perform DeepFake detection for faces, Presentation Attack Detection (PAD) for irides, and extract soft biometric attributes like gender and ethnicity from faces with reasonably high accuracy. This work reiterates the potential of pretrained models in achieving the long-term vision of Artificial General Intelligence.
diffDemorph: Extending Reference-Free Demorphing to Unseen Faces
May 20, 2025A face morph is created by combining two (or more) face images corresponding to two (or more) identities to produce a composite that successfully matches the constituent identities. Reference-free (RF) demorphing reverses this process using only the morph image, without the need for additional reference images. Previous RF demorphing methods were overly constrained, as they rely on assumptions about the distributions of training and testing morphs such as the morphing technique used, face style, and images used to create the morph. In this paper, we introduce a novel diffusion-based approach that effectively disentangles component images from a composite morph image with high visual fidelity. Our method is the first to generalize across morph techniques and face styles, beating the current state of the art by $\geq 59.46\%$ under a common training protocol across all datasets tested. We train our method on morphs created using synthetically generated face images and test on real morphs, thereby enhancing the practicality of the technique. Experiments on six datasets and two face matchers establish the utility and efficacy of our method.
Person Recognition at Altitude and Range: Fusion of Face, Body Shape and Gait
May 07, 2025
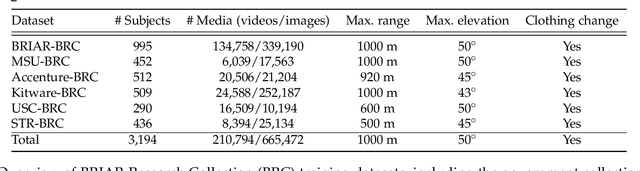

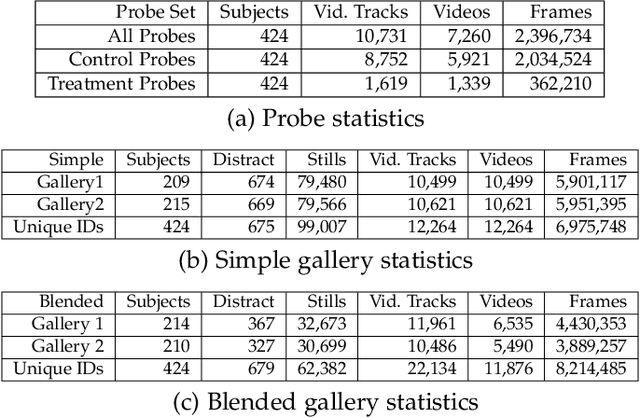
We address the problem of whole-body person recognition in unconstrained environments. This problem arises in surveillance scenarios such as those in the IARPA Biometric Recognition and Identification at Altitude and Range (BRIAR) program, where biometric data is captured at long standoff distances, elevated viewing angles, and under adverse atmospheric conditions (e.g., turbulence and high wind velocity). To this end, we propose FarSight, a unified end-to-end system for person recognition that integrates complementary biometric cues across face, gait, and body shape modalities. FarSight incorporates novel algorithms across four core modules: multi-subject detection and tracking, recognition-aware video restoration, modality-specific biometric feature encoding, and quality-guided multi-modal fusion. These components are designed to work cohesively under degraded image conditions, large pose and scale variations, and cross-domain gaps. Extensive experiments on the BRIAR dataset, one of the most comprehensive benchmarks for long-range, multi-modal biometric recognition, demonstrate the effectiveness of FarSight. Compared to our preliminary system, this system achieves a 34.1% absolute gain in 1:1 verification accuracy (TAR@0.1% FAR), a 17.8% increase in closed-set identification (Rank-20), and a 34.3% reduction in open-set identification errors (FNIR@1% FPIR). Furthermore, FarSight was evaluated in the 2025 NIST RTE Face in Video Evaluation (FIVE), which conducts standardized face recognition testing on the BRIAR dataset. These results establish FarSight as a state-of-the-art solution for operational biometric recognition in challenging real-world conditions.
Task-conditioned Ensemble of Expert Models for Continuous Learning
Apr 14, 2025



One of the major challenges in machine learning is maintaining the accuracy of the deployed model (e.g., a classifier) in a non-stationary environment. The non-stationary environment results in distribution shifts and, consequently, a degradation in accuracy. Continuous learning of the deployed model with new data could be one remedy. However, the question arises as to how we should update the model with new training data so that it retains its accuracy on the old data while adapting to the new data. In this work, we propose a task-conditioned ensemble of models to maintain the performance of the existing model. The method involves an ensemble of expert models based on task membership information. The in-domain models-based on the local outlier concept (different from the expert models) provide task membership information dynamically at run-time to each probe sample. To evaluate the proposed method, we experiment with three setups: the first represents distribution shift between tasks (LivDet-Iris-2017), the second represents distribution shift both between and within tasks (LivDet-Iris-2020), and the third represents disjoint distribution between tasks (Split MNIST). The experiments highlight the benefits of the proposed method. The source code is available at https://github.com/iPRoBe-lab/Continuous_Learning_FE_DM.