 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNemotron 3 Nano Omni: Efficient and Open Multimodal Intelligence
Apr 27, 2026We introduce Nemotron 3 Nano Omni, the latest model in the Nemotron multimodal series and the first to natively support audio inputs alongside text, images, and video. Nemotron 3 Nano Omni delivers consistent accuracy improvements over its predecessor, Nemotron Nano V2 VL, across all modalities, enabled by advances in architecture, training data and recipes. In particular, Nemotron 3 delivers leading results in real-world document understanding, long audio-video comprehension, and agentic computer use. Built on the highly efficient Nemotron 3 Nano 30B-A3B backbone, Nemotron 3 Nano Omni further incorporates innovative multimodal token-reduction techniques to deliver substantially lower inference latency and higher throughput than other models of similar size. We are releasing model checkpoints in BF16, FP8, and FP4 formats, along with portions of the training data and codebase to facilitate further research and development.
Speech-Hands: A Self-Reflection Voice Agentic Approach to Speech Recognition and Audio Reasoning with Omni Perception
Jan 14, 2026We introduce a voice-agentic framework that learns one critical omni-understanding skill: knowing when to trust itself versus when to consult external audio perception. Our work is motivated by a crucial yet counterintuitive finding: naively fine-tuning an omni-model on both speech recognition and external sound understanding tasks often degrades performance, as the model can be easily misled by noisy hypotheses. To address this, our framework, Speech-Hands, recasts the problem as an explicit self-reflection decision. This learnable reflection primitive proves effective in preventing the model from being derailed by flawed external candidates. We show that this agentic action mechanism generalizes naturally from speech recognition to complex, multiple-choice audio reasoning. Across the OpenASR leaderboard, Speech-Hands consistently outperforms strong baselines by 12.1% WER on seven benchmarks. The model also achieves 77.37% accuracy and high F1 on audio QA decisions, showing robust generalization and reliability across diverse audio question answering datasets. By unifying perception and decision-making, our work offers a practical path toward more reliable and resilient audio intelligence.
SPGISpeech 2.0: Transcribed multi-speaker financial audio for speaker-tagged transcription
Aug 07, 2025
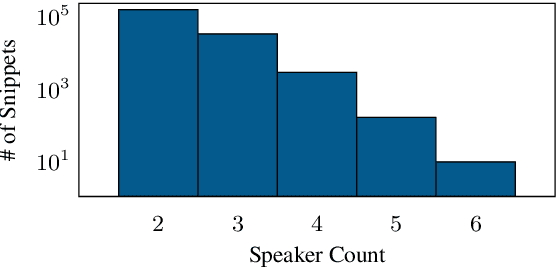
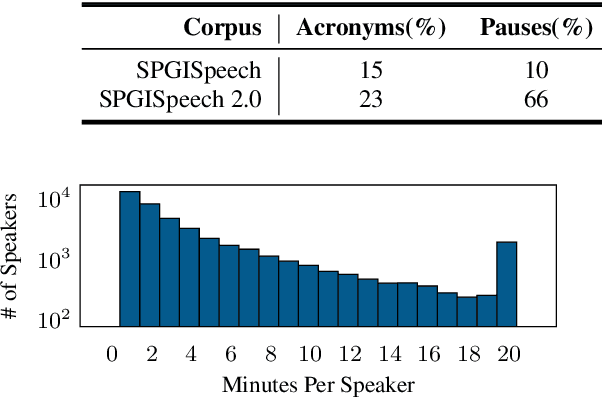
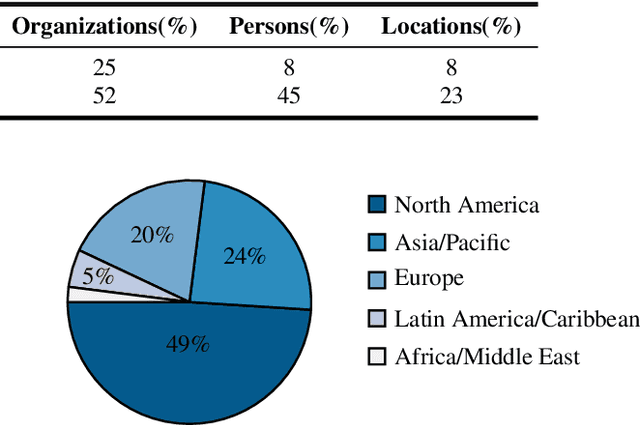
We introduce SPGISpeech 2.0, a dataset suitable for speaker-tagged transcription in the financial domain. SPGISpeech 2.0 improves the diversity of applicable modeling tasks while maintaining the core characteristic of the original SPGISpeech dataset: audio snippets and their corresponding fully formatted text transcriptions, usable for end-to-end automatic speech recognition (ASR). SPGISpeech 2.0 consists of 3,780 additional hours of professionally transcribed earnings calls. Furthermore, the dataset contains call and speaker information for each audio snippet facilitating multi-talker ASR. We validate the utility of SPGISpeech 2.0 through improvements in speaker-tagged ASR performance of popular speech recognition models after fine-tuning on SPGISpeech 2.0. Released free for non-commercial use, we expect SPGISpeech 2.0 to foster advancements in speech recognition technologies and inspire a wide range of research applications.
Word Level Timestamp Generation for Automatic Speech Recognition and Translation
May 21, 2025


We introduce a data-driven approach for enabling word-level timestamp prediction in the Canary model. Accurate timestamp information is crucial for a variety of downstream tasks such as speech content retrieval and timed subtitles. While traditional hybrid systems and end-to-end (E2E) models may employ external modules for timestamp prediction, our approach eliminates the need for separate alignment mechanisms. By leveraging the NeMo Forced Aligner (NFA) as a teacher model, we generate word-level timestamps and train the Canary model to predict timestamps directly. We introduce a new <|timestamp|> token, enabling the Canary model to predict start and end timestamps for each word. Our method demonstrates precision and recall rates between 80% and 90%, with timestamp prediction errors ranging from 20 to 120 ms across four languages, with minimal WER degradation. Additionally, we extend our system to automatic speech translation (AST) tasks, achieving timestamp prediction errors around 200 milliseconds.
Training and Inference Efficiency of Encoder-Decoder Speech Models
Mar 07, 2025



Attention encoder-decoder model architecture is the backbone of several recent top performing foundation speech models: Whisper, Seamless, OWSM, and Canary-1B. However, the reported data and compute requirements for their training are prohibitive for many in the research community. In this work, we focus on the efficiency angle and ask the questions of whether we are training these speech models efficiently, and what can we do to improve? We argue that a major, if not the most severe, detrimental factor for training efficiency is related to the sampling strategy of sequential data. We show that negligence in mini-batch sampling leads to more than 50% computation being spent on padding. To that end, we study, profile, and optimize Canary-1B training to show gradual improvement in GPU utilization leading up to 5x increase in average batch sizes versus its original training settings. This in turn allows us to train an equivalent model using 4x less GPUs in the same wall time, or leverage the original resources and train it in 2x shorter wall time. Finally, we observe that the major inference bottleneck lies in the autoregressive decoder steps. We find that adjusting the model architecture to transfer model parameters from the decoder to the encoder results in a 3x inference speedup as measured by inverse real-time factor (RTFx) while preserving the accuracy and compute requirements for convergence. The training code and models will be available as open-source.
Dynamic-SUPERB Phase-2: A Collaboratively Expanding Benchmark for Measuring the Capabilities of Spoken Language Models with 180 Tasks
Nov 08, 2024



Multimodal foundation models, such as Gemini and ChatGPT, have revolutionized human-machine interactions by seamlessly integrating various forms of data. Developing a universal spoken language model that comprehends a wide range of natural language instructions is critical for bridging communication gaps and facilitating more intuitive interactions. However, the absence of a comprehensive evaluation benchmark poses a significant challenge. We present Dynamic-SUPERB Phase-2, an open and evolving benchmark for the comprehensive evaluation of instruction-based universal speech models. Building upon the first generation, this second version incorporates 125 new tasks contributed collaboratively by the global research community, expanding the benchmark to a total of 180 tasks, making it the largest benchmark for speech and audio evaluation. While the first generation of Dynamic-SUPERB was limited to classification tasks, Dynamic-SUPERB Phase-2 broadens its evaluation capabilities by introducing a wide array of novel and diverse tasks, including regression and sequence generation, across speech, music, and environmental audio. Evaluation results indicate that none of the models performed well universally. SALMONN-13B excelled in English ASR, while WavLLM demonstrated high accuracy in emotion recognition, but current models still require further innovations to handle a broader range of tasks. We will soon open-source all task data and the evaluation pipeline.
VoiceTextBlender: Augmenting Large Language Models with Speech Capabilities via Single-Stage Joint Speech-Text Supervised Fine-Tuning
Oct 23, 2024



Recent studies have augmented large language models (LLMs) with speech capabilities, leading to the development of speech language models (SpeechLMs). Earlier SpeechLMs focused on single-turn speech-based question answering (QA), where user input comprised a speech context and a text question. More recent studies have extended this to multi-turn conversations, though they often require complex, multi-stage supervised fine-tuning (SFT) with diverse data. Another critical challenge with SpeechLMs is catastrophic forgetting-where models optimized for speech tasks suffer significant degradation in text-only performance. To mitigate these issues, we propose a novel single-stage joint speech-text SFT approach on the low-rank adaptation (LoRA) of the LLM backbone. Our joint SFT combines text-only SFT data with three types of speech-related data: speech recognition and translation, speech-based QA, and mixed-modal SFT. Compared to previous SpeechLMs with 7B or 13B parameters, our 3B model demonstrates superior performance across various speech benchmarks while preserving the original capabilities on text-only tasks. Furthermore, our model shows emergent abilities of effectively handling previously unseen prompts and tasks, including multi-turn, mixed-modal inputs.
Large Language Model Based Generative Error Correction: A Challenge and Baselines for Speech Recognition, Speaker Tagging, and Emotion Recognition
Sep 17, 2024



Given recent advances in generative AI technology, a key question is how large language models (LLMs) can enhance acoustic modeling tasks using text decoding results from a frozen, pretrained automatic speech recognition (ASR) model. To explore new capabilities in language modeling for speech processing, we introduce the generative speech transcription error correction (GenSEC) challenge. This challenge comprises three post-ASR language modeling tasks: (i) post-ASR transcription correction, (ii) speaker tagging, and (iii) emotion recognition. These tasks aim to emulate future LLM-based agents handling voice-based interfaces while remaining accessible to a broad audience by utilizing open pretrained language models or agent-based APIs. We also discuss insights from baseline evaluations, as well as lessons learned for designing future evaluations.
Sortformer: Seamless Integration of Speaker Diarization and ASR by Bridging Timestamps and Tokens
Sep 10, 2024



We propose Sortformer, a novel neural model for speaker diarization, trained with unconventional objectives compared to existing end-to-end diarization models. The permutation problem in speaker diarization has long been regarded as a critical challenge. Most prior end-to-end diarization systems employ permutation invariant loss (PIL), which optimizes for the permutation that yields the lowest error. In contrast, we introduce Sort Loss, which enables a diarization model to autonomously resolve permutation, with or without PIL. We demonstrate that combining Sort Loss and PIL achieves performance competitive with state-of-the-art end-to-end diarization models trained exclusively with PIL. Crucially, we present a streamlined multispeaker ASR architecture that leverages Sortformer as a speaker supervision model, embedding speaker label estimation within the ASR encoder state using a sinusoidal kernel function. This approach resolves the speaker permutation problem through sorted objectives, effectively bridging speaker-label timestamps and speaker tokens. In our experiments, we show that the proposed multispeaker ASR architecture, enhanced with speaker supervision, improves performance via adapter techniques. Code and trained models will be made publicly available via the NVIDIA NeMo framework
Resource-Efficient Adaptation of Speech Foundation Models for Multi-Speaker ASR
Sep 02, 2024
Speech foundation models have achieved state-of-the-art (SoTA) performance across various tasks, such as automatic speech recognition (ASR) in hundreds of languages. However, multi-speaker ASR remains a challenging task for these models due to data scarcity and sparsity. In this paper, we present approaches to enable speech foundation models to process and understand multi-speaker speech with limited training data. Specifically, we adapt a speech foundation model for the multi-speaker ASR task using only telephonic data. Remarkably, the adapted model also performs well on meeting data without any fine-tuning, demonstrating the generalization ability of our approach. We conduct several ablation studies to analyze the impact of different parameters and strategies on model performance. Our findings highlight the effectiveness of our methods. Results show that less parameters give better overall cpWER, which, although counter-intuitive, provides insights into adapting speech foundation models for multi-speaker ASR tasks with minimal annotated data.