 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
LRSpeech: Extremely Low-Resource Speech Synthesis and Recognition
Aug 09, 2020


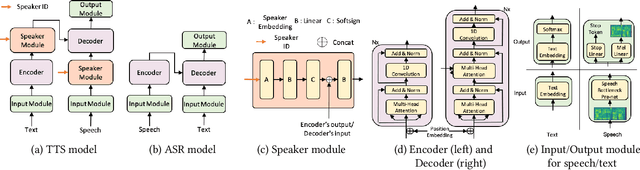
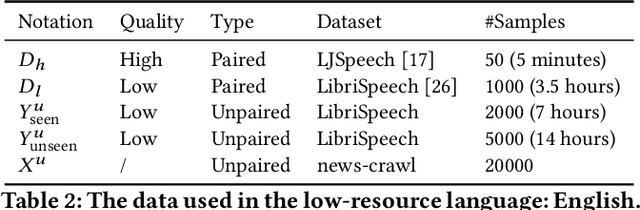
Speech synthesis (text to speech, TTS) and recognition (automatic speech recognition, ASR) are important speech tasks, and require a large amount of text and speech pairs for model training. However, there are more than 6,000 languages in the world and most languages are lack of speech training data, which poses significant challenges when building TTS and ASR systems for extremely low-resource languages. In this paper, we develop LRSpeech, a TTS and ASR system under the extremely low-resource setting, which can support rare languages with low data cost. LRSpeech consists of three key techniques: 1) pre-training on rich-resource languages and fine-tuning on low-resource languages; 2) dual transformation between TTS and ASR to iteratively boost the accuracy of each other; 3) knowledge distillation to customize the TTS model on a high-quality target-speaker voice and improve the ASR model on multiple voices. We conduct experiments on an experimental language (English) and a truly low-resource language (Lithuanian) to verify the effectiveness of LRSpeech. Experimental results show that LRSpeech 1) achieves high quality for TTS in terms of both intelligibility (more than 98% intelligibility rate) and naturalness (above 3.5 mean opinion score (MOS)) of the synthesized speech, which satisfy the requirements for industrial deployment, 2) achieves promising recognition accuracy for ASR, and 3) last but not least, uses extremely low-resource training data. We also conduct comprehensive analyses on LRSpeech with different amounts of data resources, and provide valuable insights and guidances for industrial deployment. We are currently deploying LRSpeech into a commercialized cloud speech service to support TTS on more rare languages.
Deep Multimodal Learning for Audio-Visual Speech Recognition
Jan 22, 2015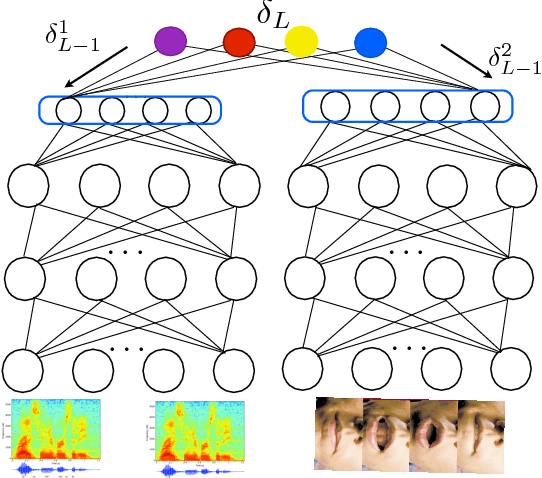
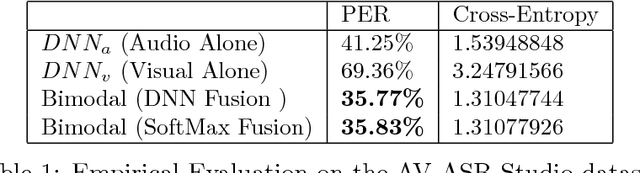
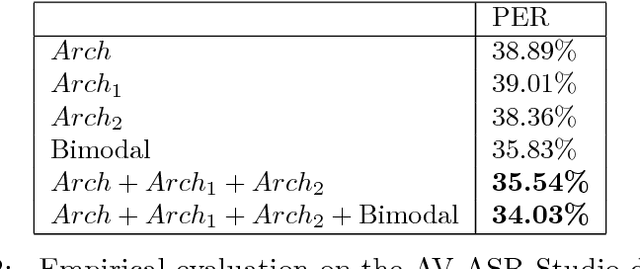
In this paper, we present methods in deep multimodal learning for fusing speech and visual modalities for Audio-Visual Automatic Speech Recognition (AV-ASR). First, we study an approach where uni-modal deep networks are trained separately and their final hidden layers fused to obtain a joint feature space in which another deep network is built. While the audio network alone achieves a phone error rate (PER) of $41\%$ under clean condition on the IBM large vocabulary audio-visual studio dataset, this fusion model achieves a PER of $35.83\%$ demonstrating the tremendous value of the visual channel in phone classification even in audio with high signal to noise ratio. Second, we present a new deep network architecture that uses a bilinear softmax layer to account for class specific correlations between modalities. We show that combining the posteriors from the bilinear networks with those from the fused model mentioned above results in a further significant phone error rate reduction, yielding a final PER of $34.03\%$.
Perception Point: Identifying Critical Learning Periods in Speech for Bilingual Networks
Oct 13, 2021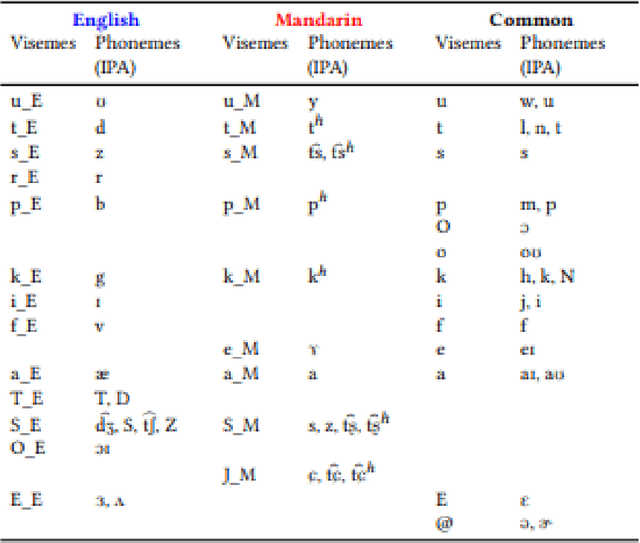



Recent studies in speech perception have been closely linked to fields of cognitive psychology, phonology, and phonetics in linguistics. During perceptual attunement, a critical and sensitive developmental trajectory has been examined in bilingual and monolingual infants where they can best discriminate common phonemes. In this paper, we compare and identify these cognitive aspects on deep neural-based visual lip-reading models. We conduct experiments on the two most extensive public visual speech recognition datasets for English and Mandarin. Through our experimental results, we observe a strong correlation between these theories in cognitive psychology and our unique modeling. We inspect how these computational models develop similar phases in speech perception and acquisitions.
Robust Natural Language Processing: Recent Advances, Challenges, and Future Directions
Jan 03, 2022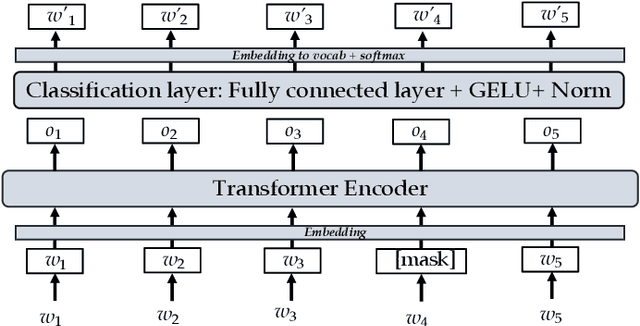
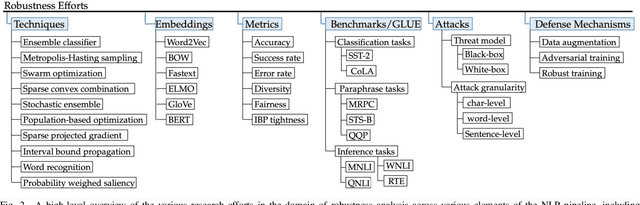
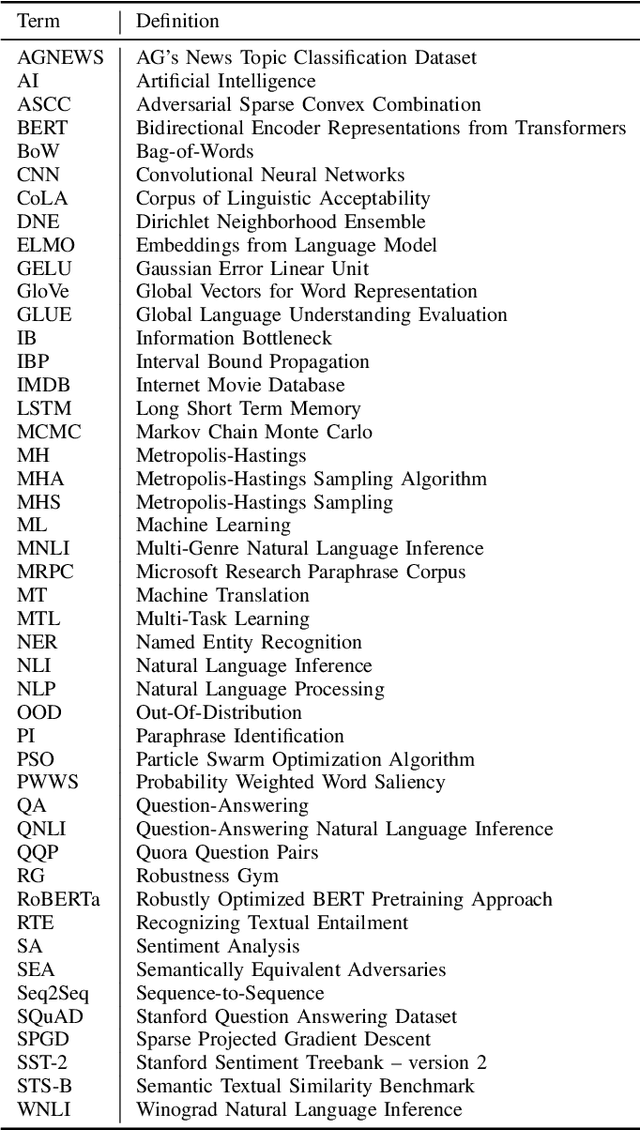
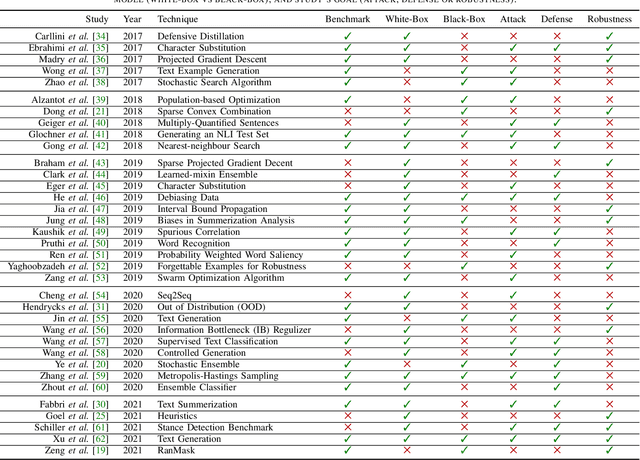
Recent natural language processing (NLP) techniques have accomplished high performance on benchmark datasets, primarily due to the significant improvement in the performance of deep learning. The advances in the research community have led to great enhancements in state-of-the-art production systems for NLP tasks, such as virtual assistants, speech recognition, and sentiment analysis. However, such NLP systems still often fail when tested with adversarial attacks. The initial lack of robustness exposed troubling gaps in current models' language understanding capabilities, creating problems when NLP systems are deployed in real life. In this paper, we present a structured overview of NLP robustness research by summarizing the literature in a systemic way across various dimensions. We then take a deep-dive into the various dimensions of robustness, across techniques, metrics, embeddings, and benchmarks. Finally, we argue that robustness should be multi-dimensional, provide insights into current research, identify gaps in the literature to suggest directions worth pursuing to address these gaps.
Mixed Precision Low-bit Quantization of Neural Network Language Models for Speech Recognition
Nov 29, 2021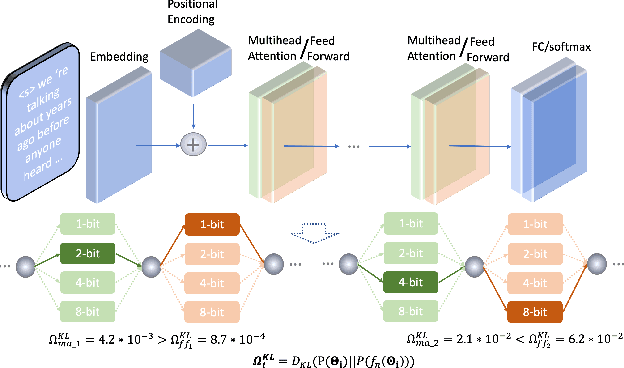
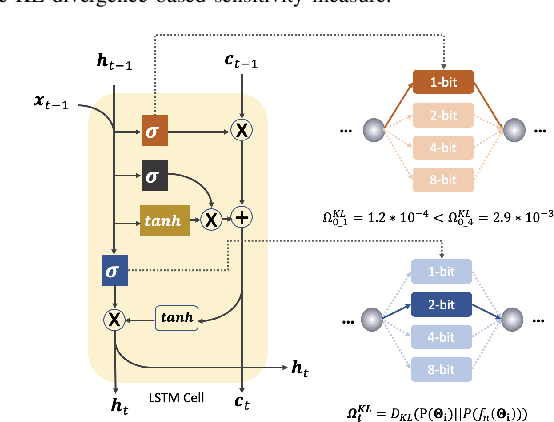
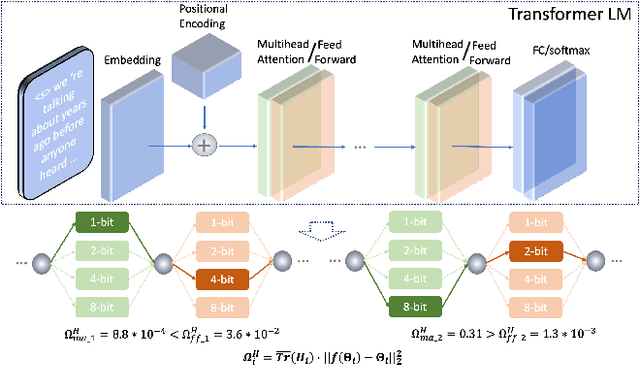
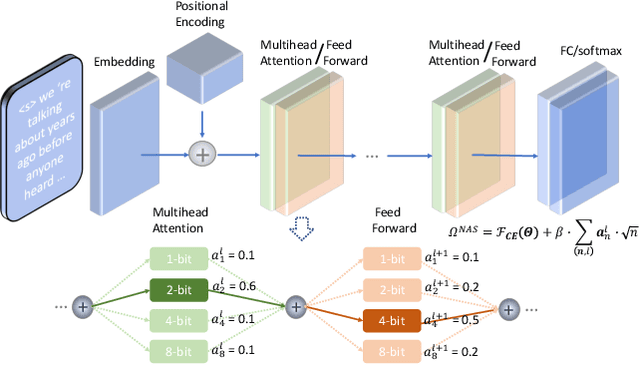
State-of-the-art language models (LMs) represented by long-short term memory recurrent neural networks (LSTM-RNNs) and Transformers are becoming increasingly complex and expensive for practical applications. Low-bit neural network quantization provides a powerful solution to dramatically reduce their model size. Current quantization methods are based on uniform precision and fail to account for the varying performance sensitivity at different parts of LMs to quantization errors. To this end, novel mixed precision neural network LM quantization methods are proposed in this paper. The optimal local precision choices for LSTM-RNN and Transformer based neural LMs are automatically learned using three techniques. The first two approaches are based on quantization sensitivity metrics in the form of either the KL-divergence measured between full precision and quantized LMs, or Hessian trace weighted quantization perturbation that can be approximated efficiently using matrix free techniques. The third approach is based on mixed precision neural architecture search. In order to overcome the difficulty in using gradient descent methods to directly estimate discrete quantized weights, alternating direction methods of multipliers (ADMM) are used to efficiently train quantized LMs. Experiments were conducted on state-of-the-art LF-MMI CNN-TDNN systems featuring speed perturbation, i-Vector and learning hidden unit contribution (LHUC) based speaker adaptation on two tasks: Switchboard telephone speech and AMI meeting transcription. The proposed mixed precision quantization techniques achieved "lossless" quantization on both tasks, by producing model size compression ratios of up to approximately 16 times over the full precision LSTM and Transformer baseline LMs, while incurring no statistically significant word error rate increase.
Prediction of speech intelligibility with DNN-based performance measures
Mar 17, 2022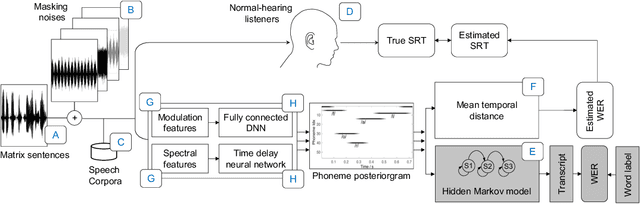


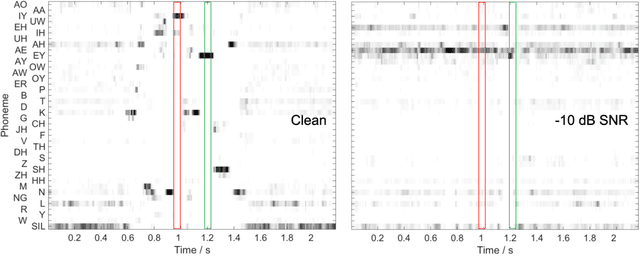
This paper presents a speech intelligibility model based on automatic speech recognition (ASR), combining phoneme probabilities from deep neural networks (DNN) and a performance measure that estimates the word error rate from these probabilities. This model does not require the clean speech reference nor the word labels during testing as the ASR decoding step, which finds the most likely sequence of words given phoneme posterior probabilities, is omitted. The model is evaluated via the root-mean-squared error between the predicted and observed speech reception thresholds from eight normal-hearing listeners. The recognition task consists of identifying noisy words from a German matrix sentence test. The speech material was mixed with eight noise maskers covering different modulation types, from speech-shaped stationary noise to a single-talker masker. The prediction performance is compared to five established models and an ASR-model using word labels. Two combinations of features and networks were tested. Both include temporal information either at the feature level (amplitude modulation filterbanks and a feed-forward network) or captured by the architecture (mel-spectrograms and a time-delay deep neural network, TDNN). The TDNN model is on par with the DNN while reducing the number of parameters by a factor of 37; this optimization allows parallel streams on dedicated hearing aid hardware as a forward-pass can be computed within the 10ms of each frame. The proposed model performs almost as well as the label-based model and produces more accurate predictions than the baseline models.
Feature selection using Fisher's ratio technique for automatic speech recognition
May 13, 2015

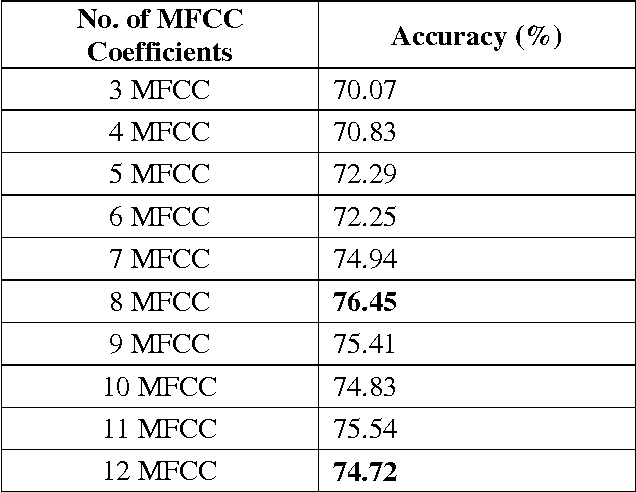
Automatic Speech Recognition involves mainly two steps; feature extraction and classification . Mel Frequency Cepstral Coefficient is used as one of the prominent feature extraction techniques in ASR. Usually, the set of all 12 MFCC coefficients is used as the feature vector in the classification step. But the question is whether the same or improved classification accuracy can be achieved by using a subset of 12 MFCC as feature vector. In this paper, Fisher's ratio technique is used for selecting a subset of 12 MFCC coefficients that contribute more in discriminating a pattern. The selected coefficients are used in classification with Hidden Markov Model algorithm. The classification accuracies that we get by using 12 coefficients and by using the selected coefficients are compared.
NAS-Bench-Suite: NAS Evaluation is (Now) Surprisingly Easy
Feb 11, 2022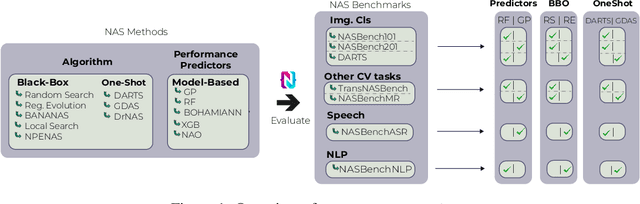
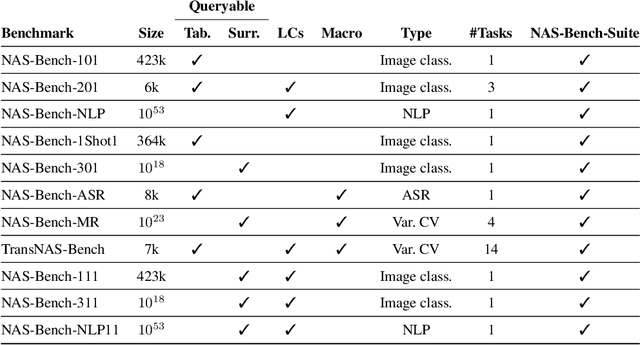
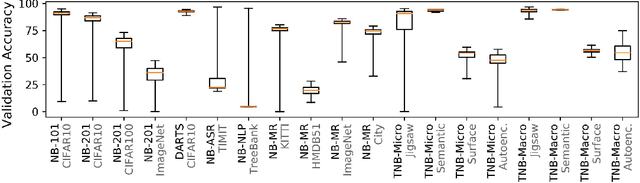
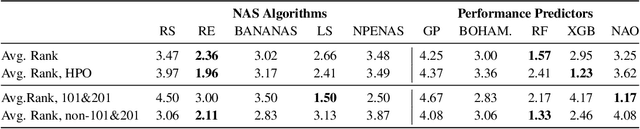
The release of tabular benchmarks, such as NAS-Bench-101 and NAS-Bench-201, has significantly lowered the computational overhead for conducting scientific research in neural architecture search (NAS). Although they have been widely adopted and used to tune real-world NAS algorithms, these benchmarks are limited to small search spaces and focus solely on image classification. Recently, several new NAS benchmarks have been introduced that cover significantly larger search spaces over a wide range of tasks, including object detection, speech recognition, and natural language processing. However, substantial differences among these NAS benchmarks have so far prevented their widespread adoption, limiting researchers to using just a few benchmarks. In this work, we present an in-depth analysis of popular NAS algorithms and performance prediction methods across 25 different combinations of search spaces and datasets, finding that many conclusions drawn from a few NAS benchmarks do not generalize to other benchmarks. To help remedy this problem, we introduce NAS-Bench-Suite, a comprehensive and extensible collection of NAS benchmarks, accessible through a unified interface, created with the aim to facilitate reproducible, generalizable, and rapid NAS research. Our code is available at https://github.com/automl/naslib.
How Bad Are Artifacts?: Analyzing the Impact of Speech Enhancement Errors on ASR
Jan 18, 2022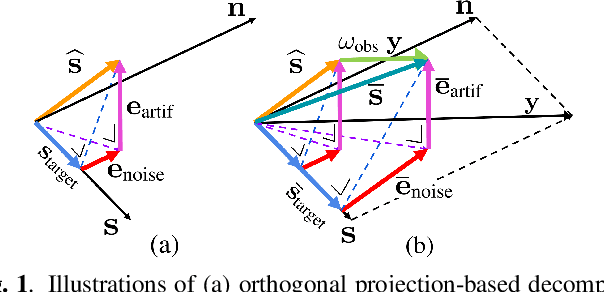
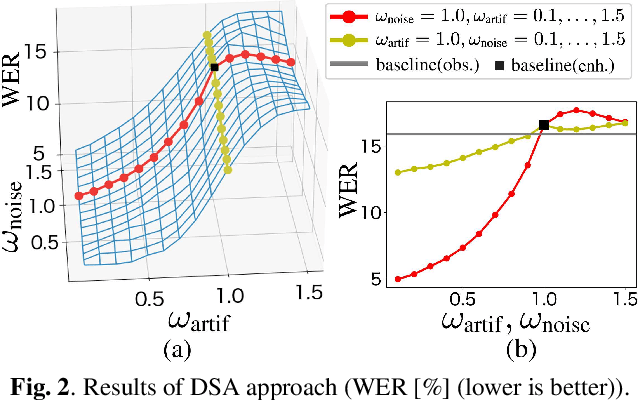
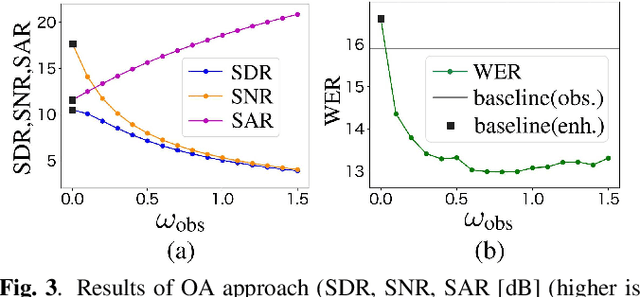
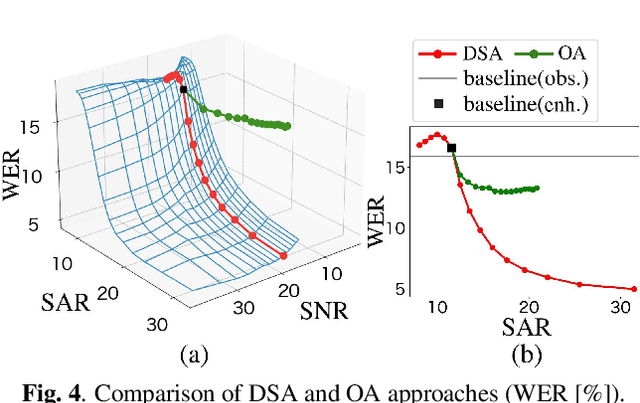
It is challenging to improve automatic speech recognition (ASR) performance in noisy conditions with single-channel speech enhancement (SE). In this paper, we investigate the causes of ASR performance degradation by decomposing the SE errors using orthogonal projection-based decomposition (OPD). OPD decomposes the SE errors into noise and artifact components. The artifact component is defined as the SE error signal that cannot be represented as a linear combination of speech and noise sources. We propose manually scaling the error components to analyze their impact on ASR. We experimentally identify the artifact component as the main cause of performance degradation, and we find that mitigating the artifact can greatly improve ASR performance. Furthermore, we demonstrate that the simple observation adding (OA) technique (i.e., adding a scaled version of the observed signal to the enhanced speech) can monotonically increase the signal-to-artifact ratio under a mild condition. Accordingly, we experimentally confirm that OA improves ASR performance for both simulated and real recordings. The findings of this paper provide a better understanding of the influence of SE errors on ASR and open the door to future research on novel approaches for designing effective single-channel SE front-ends for ASR.
Streaming End-to-End ASR based on Blockwise Non-Autoregressive Models
Jul 20, 2021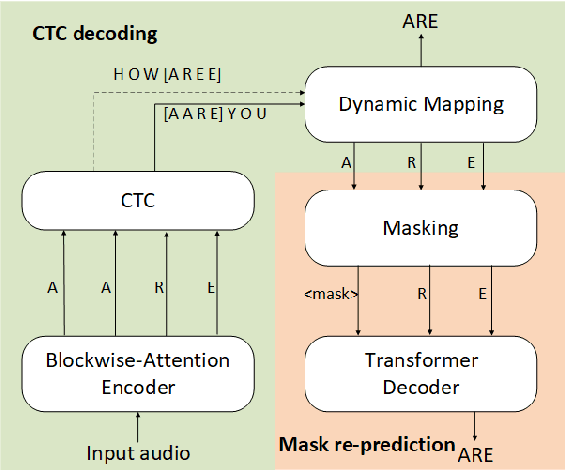
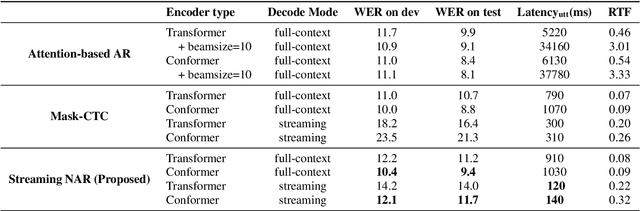
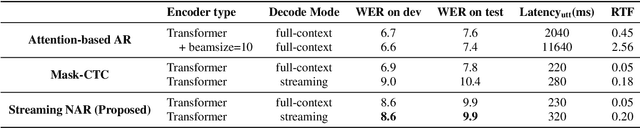
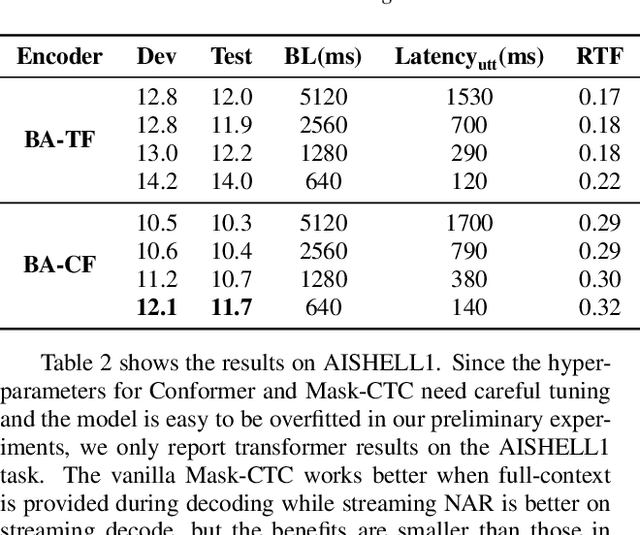
Non-autoregressive (NAR) modeling has gained more and more attention in speech processing. With recent state-of-the-art attention-based automatic speech recognition (ASR) structure, NAR can realize promising real-time factor (RTF) improvement with only small degradation of accuracy compared to the autoregressive (AR) models. However, the recognition inference needs to wait for the completion of a full speech utterance, which limits their applications on low latency scenarios. To address this issue, we propose a novel end-to-end streaming NAR speech recognition system by combining blockwise-attention and connectionist temporal classification with mask-predict (Mask-CTC) NAR. During inference, the input audio is separated into small blocks and then processed in a blockwise streaming way. To address the insertion and deletion error at the edge of the output of each block, we apply an overlapping decoding strategy with a dynamic mapping trick that can produce more coherent sentences. Experimental results show that the proposed method improves online ASR recognition in low latency conditions compared to vanilla Mask-CTC. Moreover, it can achieve a much faster inference speed compared to the AR attention-based models. All of our codes will be publicly available at https://github.com/espnet/espnet.