 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixed Precision Low-bit Quantization of Neural Network Language Models for Speech Recognition
Paper and Code
Nov 29, 2021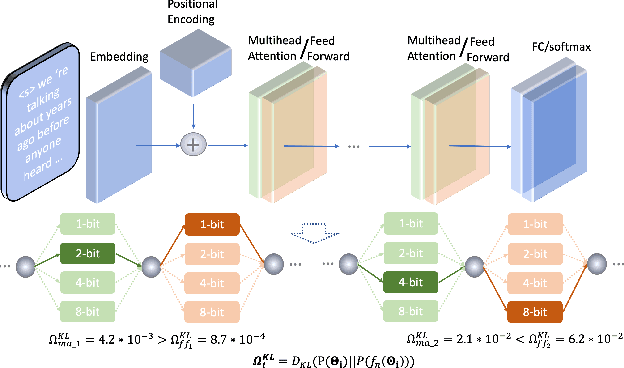
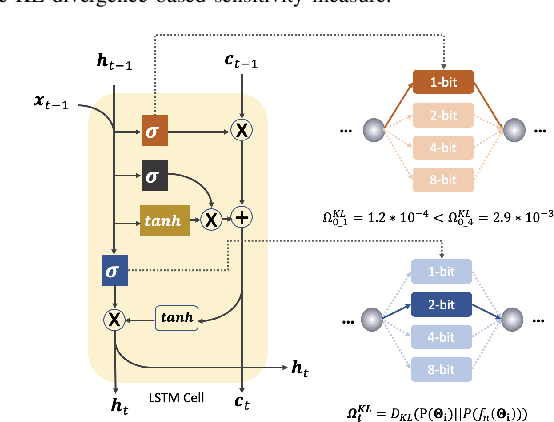
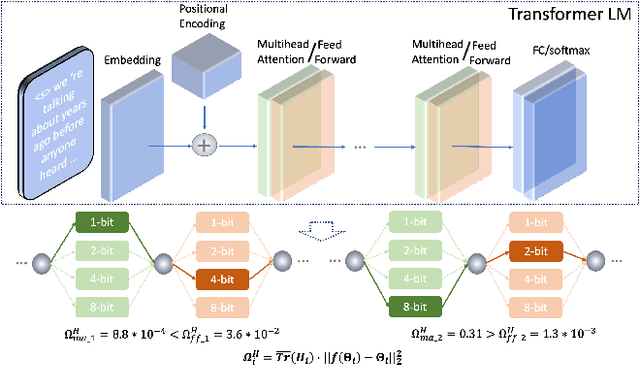
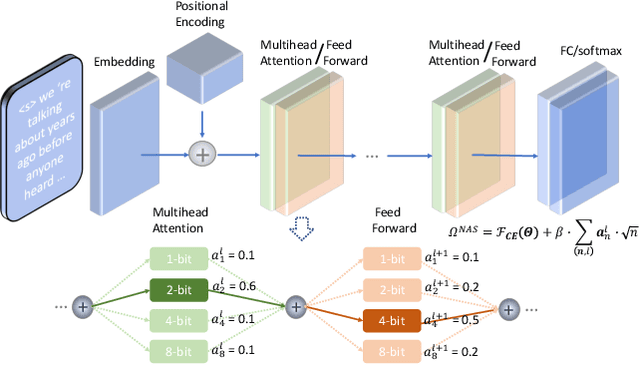
State-of-the-art language models (LMs) represented by long-short term memory recurrent neural networks (LSTM-RNNs) and Transformers are becoming increasingly complex and expensive for practical applications. Low-bit neural network quantization provides a powerful solution to dramatically reduce their model size. Current quantization methods are based on uniform precision and fail to account for the varying performance sensitivity at different parts of LMs to quantization errors. To this end, novel mixed precision neural network LM quantization methods are proposed in this paper. The optimal local precision choices for LSTM-RNN and Transformer based neural LMs are automatically learned using three techniques. The first two approaches are based on quantization sensitivity metrics in the form of either the KL-divergence measured between full precision and quantized LMs, or Hessian trace weighted quantization perturbation that can be approximated efficiently using matrix free techniques. The third approach is based on mixed precision neural architecture search. In order to overcome the difficulty in using gradient descent methods to directly estimate discrete quantized weights, alternating direction methods of multipliers (ADMM) are used to efficiently train quantized LMs. Experiments were conducted on state-of-the-art LF-MMI CNN-TDNN systems featuring speed perturbation, i-Vector and learning hidden unit contribution (LHUC) based speaker adaptation on two tasks: Switchboard telephone speech and AMI meeting transcription. The proposed mixed precision quantization techniques achieved "lossless" quantization on both tasks, by producing model size compression ratios of up to approximately 16 times over the full precision LSTM and Transformer baseline LMs, while incurring no statistically significant word error rate increase.