 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Natural Language Processing: Recent Advances, Challenges, and Future Directions
Paper and Code
Jan 03, 2022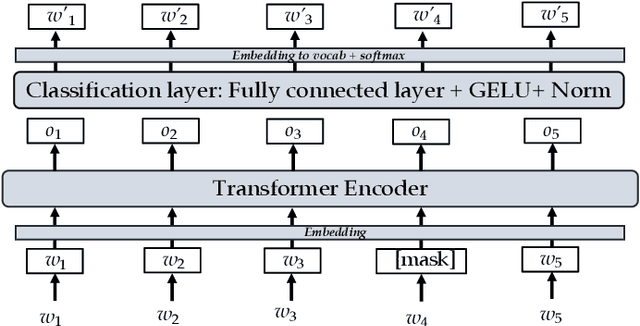
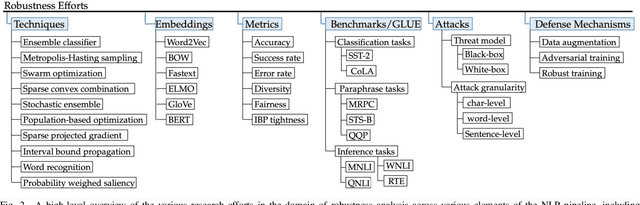
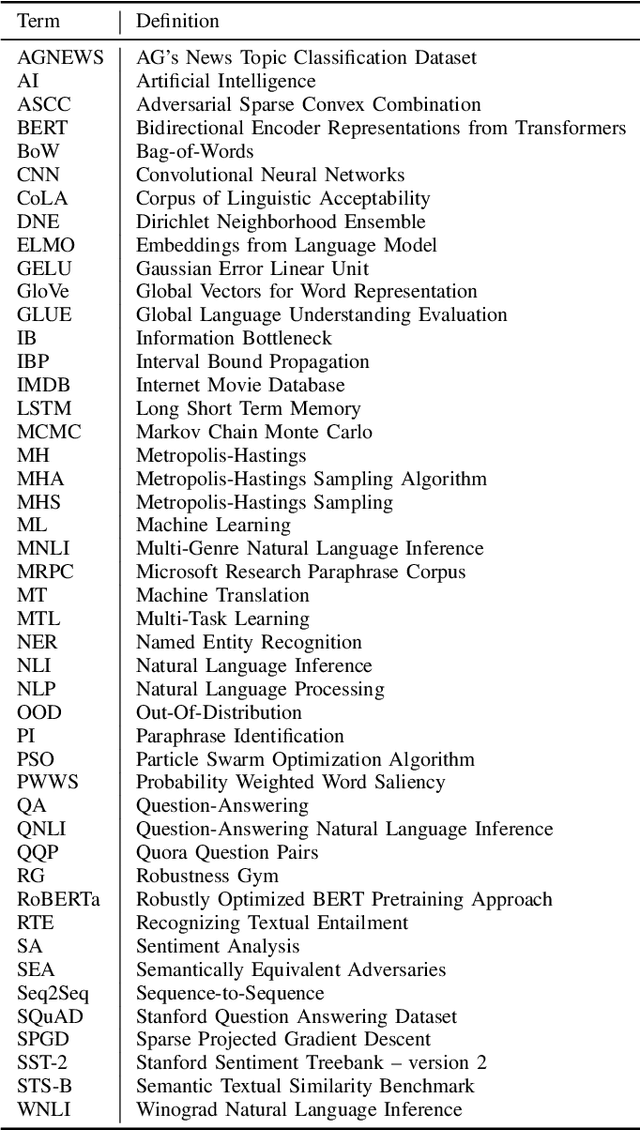
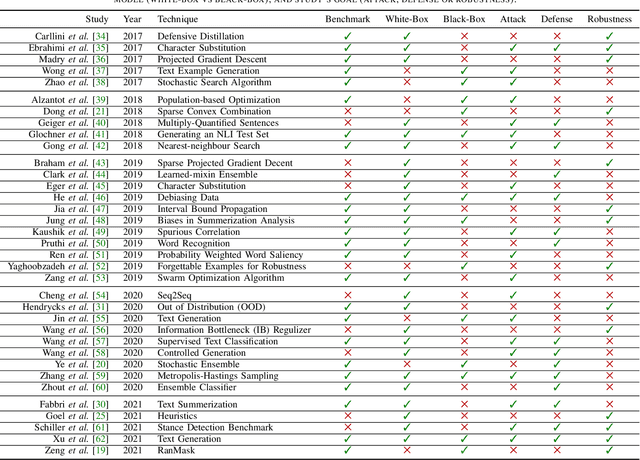
Recent natural language processing (NLP) techniques have accomplished high performance on benchmark datasets, primarily due to the significant improvement in the performance of deep learning. The advances in the research community have led to great enhancements in state-of-the-art production systems for NLP tasks, such as virtual assistants, speech recognition, and sentiment analysis. However, such NLP systems still often fail when tested with adversarial attacks. The initial lack of robustness exposed troubling gaps in current models' language understanding capabilities, creating problems when NLP systems are deployed in real life. In this paper, we present a structured overview of NLP robustness research by summarizing the literature in a systemic way across various dimensions. We then take a deep-dive into the various dimensions of robustness, across techniques, metrics, embeddings, and benchmarks. Finally, we argue that robustness should be multi-dimensional, provide insights into current research, identify gaps in the literature to suggest directions worth pursuing to address these gaps.