 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGompertz Linear Units: Leveraging Asymmetry for Enhanced Learning Dynamics
Feb 05, 2025



Activation functions are fundamental elements of deep learning architectures as they significantly influence training dynamics. ReLU, while widely used, is prone to the dying neuron problem, which has been mitigated by variants such as LeakyReLU, PReLU, and ELU that better handle negative neuron outputs. Recently, self-gated activations like GELU and Swish have emerged as state-of-the-art alternatives, leveraging their smoothness to ensure stable gradient flow and prevent neuron inactivity. In this work, we introduce the Gompertz Linear Unit (GoLU), a novel self-gated activation function defined as $\mathrm{GoLU}(x) = x \, \mathrm{Gompertz}(x)$, where $\mathrm{Gompertz}(x) = e^{-e^{-x}}$. The GoLU activation leverages the asymmetry in the Gompertz function to reduce variance in the latent space more effectively compared to GELU and Swish, while preserving robust gradient flow. Extensive experiments across diverse tasks, including Image Classification, Language Modeling, Semantic Segmentation, Object Detection, Instance Segmentation, and Diffusion, highlight GoLU's superior performance relative to state-of-the-art activation functions, establishing GoLU as a robust alternative to existing activation functions.
Efficient Search for Customized Activation Functions with Gradient Descent
Aug 13, 2024



Different activation functions work best for different deep learning models. To exploit this, we leverage recent advancements in gradient-based search techniques for neural architectures to efficiently identify high-performing activation functions for a given application. We propose a fine-grained search cell that combines basic mathematical operations to model activation functions, allowing for the exploration of novel activations. Our approach enables the identification of specialized activations, leading to improved performance in every model we tried, from image classification to language models. Moreover, the identified activations exhibit strong transferability to larger models of the same type, as well as new datasets. Importantly, our automated process for creating customized activation functions is orders of magnitude more efficient than previous approaches. It can easily be applied on top of arbitrary deep learning pipelines and thus offers a promising practical avenue for enhancing deep learning architectures.
Surprisingly Strong Performance Prediction with Neural Graph Features
Apr 25, 2024



Performance prediction has been a key part of the neural architecture search (NAS) process, allowing to speed up NAS algorithms by avoiding resource-consuming network training. Although many performance predictors correlate well with ground truth performance, they require training data in the form of trained networks. Recently, zero-cost proxies have been proposed as an efficient method to estimate network performance without any training. However, they are still poorly understood, exhibit biases with network properties, and their performance is limited. Inspired by the drawbacks of zero-cost proxies, we propose neural graph features (GRAF), simple to compute properties of architectural graphs. GRAF offers fast and interpretable performance prediction while outperforming zero-cost proxies and other common encodings. In combination with other zero-cost proxies, GRAF outperforms most existing performance predictors at a fraction of the cost.
Weight-Entanglement Meets Gradient-Based Neural Architecture Search
Dec 16, 2023



Weight sharing is a fundamental concept in neural architecture search (NAS), enabling gradient-based methods to explore cell-based architecture spaces significantly faster than traditional blackbox approaches. In parallel, weight \emph{entanglement} has emerged as a technique for intricate parameter sharing among architectures within macro-level search spaces. %However, the macro structure of such spaces poses compatibility challenges for gradient-based NAS methods. %As a result, blackbox optimization methods have been commonly employed, particularly in conjunction with supernet training, to maintain search efficiency. %Due to the inherent differences in the structure of these search spaces, these Since weight-entanglement poses compatibility challenges for gradient-based NAS methods, these two paradigms have largely developed independently in parallel sub-communities. This paper aims to bridge the gap between these sub-communities by proposing a novel scheme to adapt gradient-based methods for weight-entangled spaces. This enables us to conduct an in-depth comparative assessment and analysis of the performance of gradient-based NAS in weight-entangled search spaces. Our findings reveal that this integration of weight-entanglement and gradient-based NAS brings forth the various benefits of gradient-based methods (enhanced performance, improved supernet training properties and superior any-time performance), while preserving the memory efficiency of weight-entangled spaces. The code for our work is openly accessible \href{https://anonymous.4open.science/r/TangleNAS-527C}{here}
Neural Architecture Search: Insights from 1000 Papers
Jan 25, 2023



In the past decade, advances in deep learning have resulted in breakthroughs in a variety of areas, including computer vision, natural language understanding, speech recognition, and reinforcement learning. Specialized, high-performing neural architectures are crucial to the success of deep learning in these areas. Neural architecture search (NAS), the process of automating the design of neural architectures for a given task, is an inevitable next step in automating machine learning and has already outpaced the best human-designed architectures on many tasks. In the past few years, research in NAS has been progressing rapidly, with over 1000 papers released since 2020 (Deng and Lindauer, 2021). In this survey, we provide an organized and comprehensive guide to neural architecture search. We give a taxonomy of search spaces, algorithms, and speedup techniques, and we discuss resources such as benchmarks, best practices, other surveys, and open-source libraries.
NAS-Bench-Suite-Zero: Accelerating Research on Zero Cost Proxies
Oct 06, 2022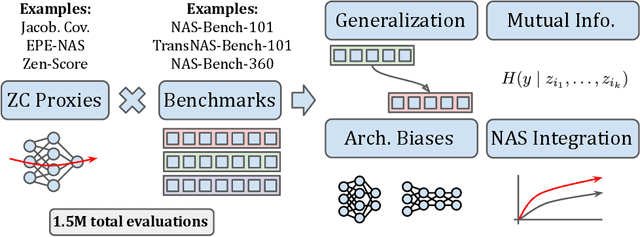
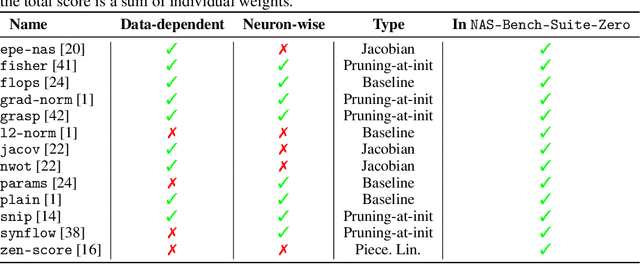
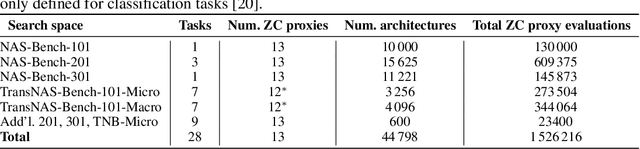
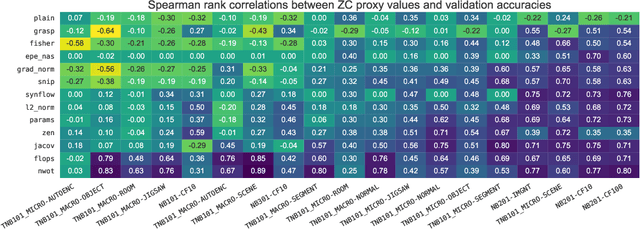
Zero-cost proxies (ZC proxies) are a recent architecture performance prediction technique aiming to significantly speed up algorithms for neural architecture search (NAS). Recent work has shown that these techniques show great promise, but certain aspects, such as evaluating and exploiting their complementary strengths, are under-studied. In this work, we create NAS-Bench-Suite: we evaluate 13 ZC proxies across 28 tasks, creating by far the largest dataset (and unified codebase) for ZC proxies, enabling orders-of-magnitude faster experiments on ZC proxies, while avoiding confounding factors stemming from different implementations. To demonstrate the usefulness of NAS-Bench-Suite, we run a large-scale analysis of ZC proxies, including a bias analysis, and the first information-theoretic analysis which concludes that ZC proxies capture substantial complementary information. Motivated by these findings, we present a procedure to improve the performance of ZC proxies by reducing biases such as cell size, and we also show that incorporating all 13 ZC proxies into the surrogate models used by NAS algorithms can improve their predictive performance by up to 42%. Our code and datasets are available at https://github.com/automl/naslib/tree/zerocost.
NAS-Bench-Suite: NAS Evaluation is (Now) Surprisingly Easy
Feb 11, 2022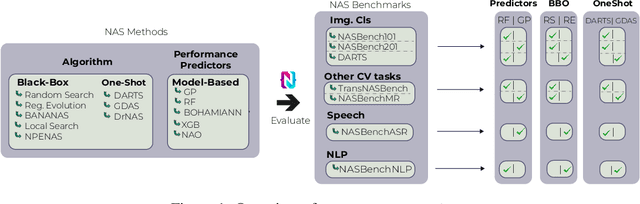
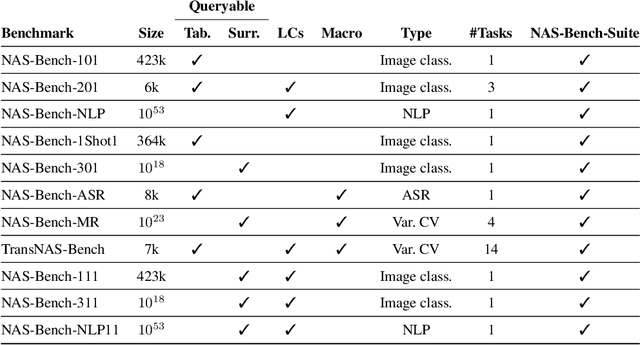
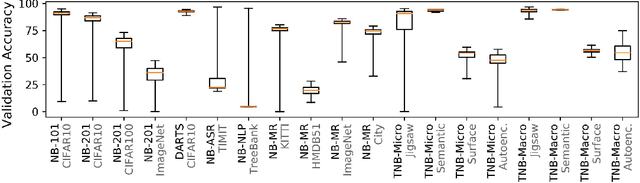
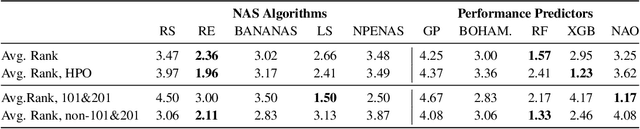
The release of tabular benchmarks, such as NAS-Bench-101 and NAS-Bench-201, has significantly lowered the computational overhead for conducting scientific research in neural architecture search (NAS). Although they have been widely adopted and used to tune real-world NAS algorithms, these benchmarks are limited to small search spaces and focus solely on image classification. Recently, several new NAS benchmarks have been introduced that cover significantly larger search spaces over a wide range of tasks, including object detection, speech recognition, and natural language processing. However, substantial differences among these NAS benchmarks have so far prevented their widespread adoption, limiting researchers to using just a few benchmarks. In this work, we present an in-depth analysis of popular NAS algorithms and performance prediction methods across 25 different combinations of search spaces and datasets, finding that many conclusions drawn from a few NAS benchmarks do not generalize to other benchmarks. To help remedy this problem, we introduce NAS-Bench-Suite, a comprehensive and extensible collection of NAS benchmarks, accessible through a unified interface, created with the aim to facilitate reproducible, generalizable, and rapid NAS research. Our code is available at https://github.com/automl/naslib.
SuperCoder: Program Learning Under Noisy Conditions From Superposition of States
Dec 07, 2020
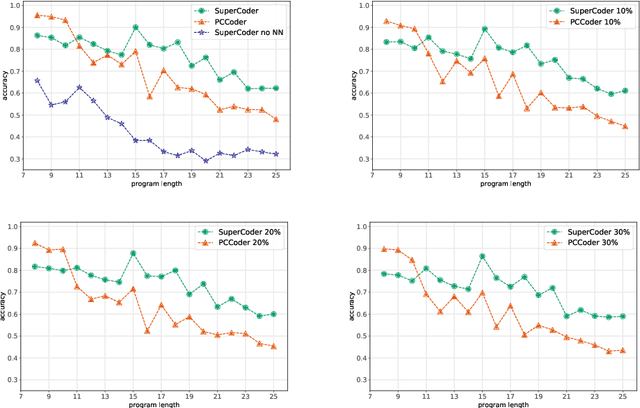
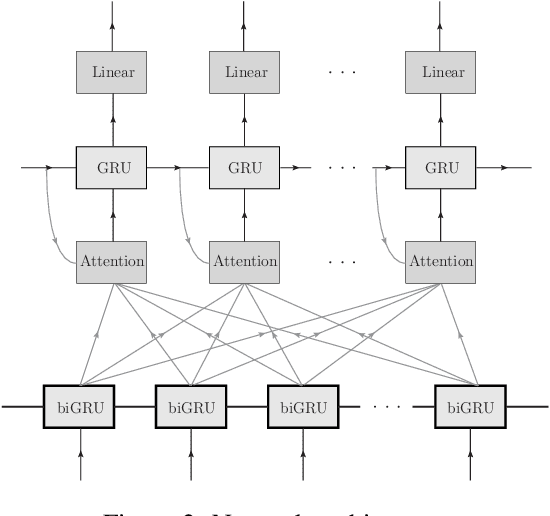
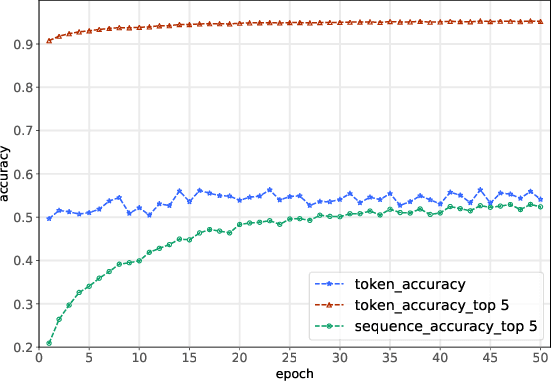
We propose a new method of program learning in a Domain Specific Language (DSL) which is based on gradient descent with no direct search. The first component of our method is a probabilistic representation of the DSL variables. At each timestep in the program sequence, different DSL functions are applied on the DSL variables with a certain probability, leading to different possible outcomes. Rather than handling all these outputs separately, whose number grows exponentially with each timestep, we collect them into a superposition of variables which captures the information in a single, but fuzzy, state. This state is to be contrasted at the final timestep with the ground-truth output, through a loss function. The second component of our method is an attention-based recurrent neural network, which provides an appropriate initialization point for the gradient descent that optimizes the probabilistic representation. The method we have developed surpasses the state-of-the-art for synthesising long programs and is able to learn programs under noise.