 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReference Microphone Selection for Guided Source Separation based on the Normalized L-p Norm
Oct 31, 2025
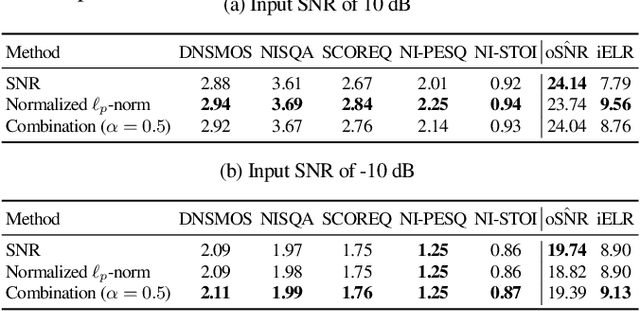

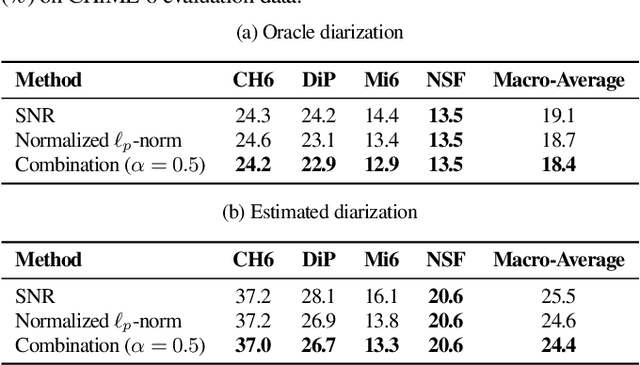
Guided Source Separation (GSS) is a popular front-end for distant automatic speech recognition (ASR) systems using spatially distributed microphones. When considering spatially distributed microphones, the choice of reference microphone may have a large influence on the quality of the output signal and the downstream ASR performance. In GSS-based speech enhancement, reference microphone selection is typically performed using the signal-to-noise ratio (SNR), which is optimal for noise reduction but may neglect differences in early-to-late-reverberant ratio (ELR) across microphones. In this paper, we propose two reference microphone selection methods for GSS-based speech enhancement that are based on the normalized $\ell_p$-norm, either using only the normalized $\ell_p$-norm or combining the normalized $\ell_p$-norm and the SNR to account for both differences in SNR and ELR across microphones. Experimental evaluation using a CHiME-8 distant ASR system shows that the proposed $\ell_p$-norm-based methods outperform the baseline method, reducing the macro-average word error rate.
NTT Multi-Speaker ASR System for the DASR Task of CHiME-8 Challenge
Sep 09, 2024



We present a distant automatic speech recognition (DASR) system developed for the CHiME-8 DASR track. It consists of a diarization first pipeline. For diarization, we use end-to-end diarization with vector clustering (EEND-VC) followed by target speaker voice activity detection (TS-VAD) refinement. To deal with various numbers of speakers, we developed a new multi-channel speaker counting approach. We then apply guided source separation (GSS) with several improvements to the baseline system. Finally, we perform ASR using a combination of systems built from strong pre-trained models. Our proposed system achieves a macro tcpWER of 21.3 % on the dev set, which is a 57 % relative improvement over the baseline.
Rethinking Processing Distortions: Disentangling the Impact of Speech Enhancement Errors on Speech Recognition Performance
Apr 23, 2024



It is challenging to improve automatic speech recognition (ASR) performance in noisy conditions with a single-channel speech enhancement (SE) front-end. This is generally attributed to the processing distortions caused by the nonlinear processing of single-channel SE front-ends. However, the causes of such degraded ASR performance have not been fully investigated. How to design single-channel SE front-ends in a way that significantly improves ASR performance remains an open research question. In this study, we investigate a signal-level numerical metric that can explain the cause of degradation in ASR performance. To this end, we propose a novel analysis scheme based on the orthogonal projection-based decomposition of SE errors. This scheme manually modifies the ratio of the decomposed interference, noise, and artifact errors, and it enables us to directly evaluate the impact of each error type on ASR performance. Our analysis reveals the particularly detrimental effect of artifact errors on ASR performance compared to the other types of errors. This provides us with a more principled definition of processing distortions that cause the ASR performance degradation. Then, we study two practical approaches for reducing the impact of artifact errors. First, we prove that the simple observation adding (OA) post-processing (i.e., interpolating the enhanced and observed signals) can monotonically improve the signal-to-artifact ratio. Second, we propose a novel training objective, called artifact-boosted signal-to-distortion ratio (AB-SDR), which forces the model to estimate the enhanced signals with fewer artifact errors. Through experiments, we confirm that both the OA and AB-SDR approaches are effective in decreasing artifact errors caused by single-channel SE front-ends, allowing them to significantly improve ASR performance.
Neural network-based virtual microphone estimation with virtual microphone and beamformer-level multi-task loss
Nov 20, 2023


Array processing performance depends on the number of microphones available. Virtual microphone estimation (VME) has been proposed to increase the number of microphone signals artificially. Neural network-based VME (NN-VME) trains an NN with a VM-level loss to predict a signal at a microphone location that is available during training but not at inference. However, this training objective may not be optimal for a specific array processing back-end, such as beamforming. An alternative approach is to use a training objective considering the array-processing back-end, such as a loss on the beamformer output. This approach may generate signals optimal for beamforming but not physically grounded. To combine the advantages of both approaches, this paper proposes a multi-task loss for NN-VME that combines both VM-level and beamformer-level losses. We evaluate the proposed multi-task NN-VME on multi-talker underdetermined conditions and show that it achieves a 33.1 % relative WER improvement compared to using only real microphones and 10.8 % compared to using a prior NN-VME approach.
How does end-to-end speech recognition training impact speech enhancement artifacts?
Nov 20, 2023

Jointly training a speech enhancement (SE) front-end and an automatic speech recognition (ASR) back-end has been investigated as a way to mitigate the influence of \emph{processing distortion} generated by single-channel SE on ASR. In this paper, we investigate the effect of such joint training on the signal-level characteristics of the enhanced signals from the viewpoint of the decomposed noise and artifact errors. The experimental analyses provide two novel findings: 1) ASR-level training of the SE front-end reduces the artifact errors while increasing the noise errors, and 2) simply interpolating the enhanced and observed signals, which achieves a similar effect of reducing artifacts and increasing noise, improves ASR performance without jointly modifying the SE and ASR modules, even for a strong ASR back-end using a WavLM feature extractor. Our findings provide a better understanding of the effect of joint training and a novel insight for designing an ASR agnostic SE front-end.
NoisyILRMA: Diffuse-Noise-Aware Independent Low-Rank Matrix Analysis for Fast Blind Source Extraction
Jun 22, 2023


In this paper, we address the multichannel blind source extraction (BSE) of a single source in diffuse noise environments. To solve this problem even faster than by fast multichannel nonnegative matrix factorization (FastMNMF) and its variant, we propose a BSE method called NoisyILRMA, which is a modification of independent low-rank matrix analysis (ILRMA) to account for diffuse noise. NoisyILRMA can achieve considerably fast BSE by incorporating an algorithm developed for independent vector extraction. In addition, to improve the BSE performance of NoisyILRMA, we propose a mechanism to switch the source model with ILRMA-like nonnegative matrix factorization to a more expressive source model during optimization. In the experiment, we show that NoisyILRMA runs faster than a FastMNMF algorithm while maintaining the BSE performance. We also confirm that the switching mechanism improves the BSE performance of NoisyILRMA.
$\text{ISS}_2$: An Extension of Iterative Source Steering Algorithm for Majorization-Minimization-Based Independent Vector Analysis
Feb 02, 2022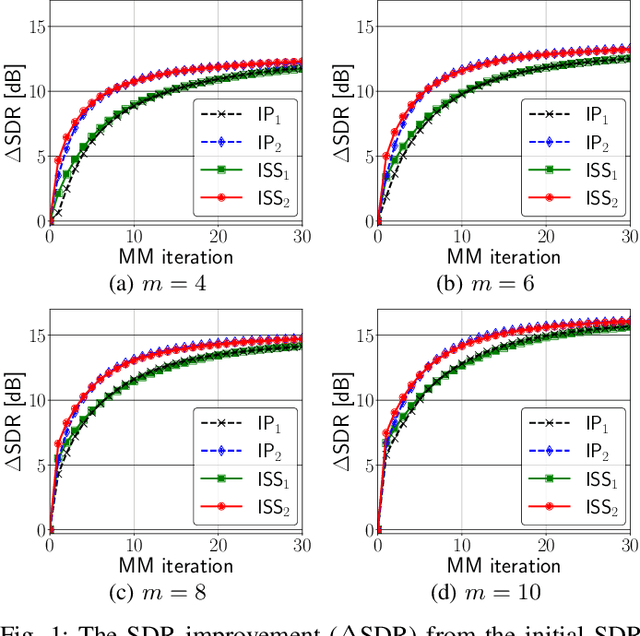
A majorization-minimization (MM) algorithm for independent vector analysis optimizes a separation matrix $W = [w_1, \ldots, w_m]^h \in \mathbb{C}^{m \times m}$ by minimizing a surrogate function of the form $\mathcal{L}(W) = \sum_{i = 1}^m w_i^h V_i w_i - \log | \det W |^2$, where $m \in \mathbb{N}$ is the number of sensors and positive definite matrices $V_1,\ldots,V_m \in \mathbb{C}^{m \times m}$ are constructed in each MM iteration. For $m \geq 3$, no algorithm has been found to obtain a global minimum of $\mathcal{L}(W)$. Instead, block coordinate descent (BCD) methods with closed-form update formulas have been developed for minimizing $\mathcal{L}(W)$ and shown to be effective. One such BCD is called iterative projection (IP) that updates one or two rows of $W$ in each iteration. Another BCD is called iterative source steering (ISS) that updates one column of the mixing matrix $A = W^{-1}$ in each iteration. Although the time complexity per iteration of ISS is $m$ times smaller than that of IP, the conventional ISS converges slower than the current fastest IP (called $\text{IP}_2$) that updates two rows of $W$ in each iteration. We here extend this ISS to $\text{ISS}_2$ that can update two columns of $A$ in each iteration while maintaining its small time complexity. To this end, we provide a unified way for developing new ISS type methods from which $\text{ISS}_2$ as well as the conventional ISS can be immediately obtained in a systematic manner. Numerical experiments to separate reverberant speech mixtures show that our $\text{ISS}_2$ converges in fewer MM iterations than the conventional ISS, and is comparable to $\text{IP}_2$.
How Bad Are Artifacts?: Analyzing the Impact of Speech Enhancement Errors on ASR
Jan 18, 2022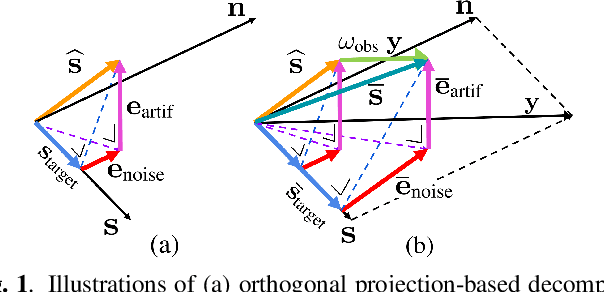
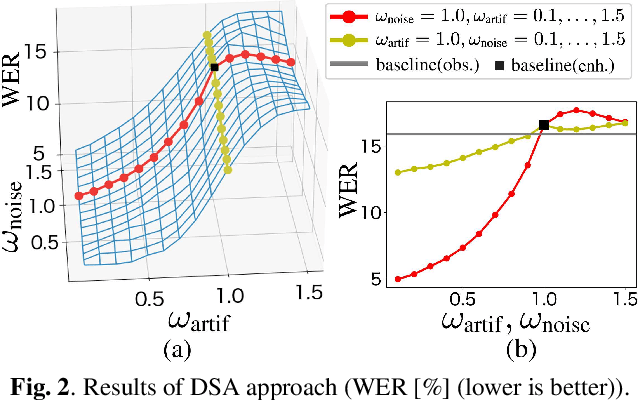
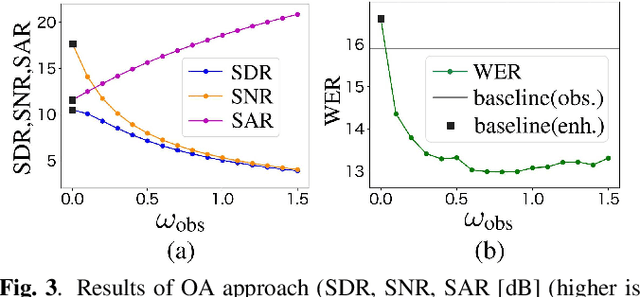
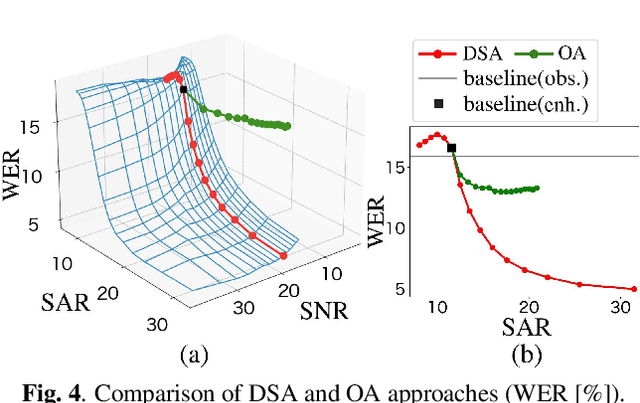
It is challenging to improve automatic speech recognition (ASR) performance in noisy conditions with single-channel speech enhancement (SE). In this paper, we investigate the causes of ASR performance degradation by decomposing the SE errors using orthogonal projection-based decomposition (OPD). OPD decomposes the SE errors into noise and artifact components. The artifact component is defined as the SE error signal that cannot be represented as a linear combination of speech and noise sources. We propose manually scaling the error components to analyze their impact on ASR. We experimentally identify the artifact component as the main cause of performance degradation, and we find that mitigating the artifact can greatly improve ASR performance. Furthermore, we demonstrate that the simple observation adding (OA) technique (i.e., adding a scaled version of the observed signal to the enhanced speech) can monotonically increase the signal-to-artifact ratio under a mild condition. Accordingly, we experimentally confirm that OA improves ASR performance for both simulated and real recordings. The findings of this paper provide a better understanding of the influence of SE errors on ASR and open the door to future research on novel approaches for designing effective single-channel SE front-ends for ASR.
Switching Independent Vector Analysis and Its Extension to Blind and Spatially Guided Convolutional Beamforming Algorithm
Nov 20, 2021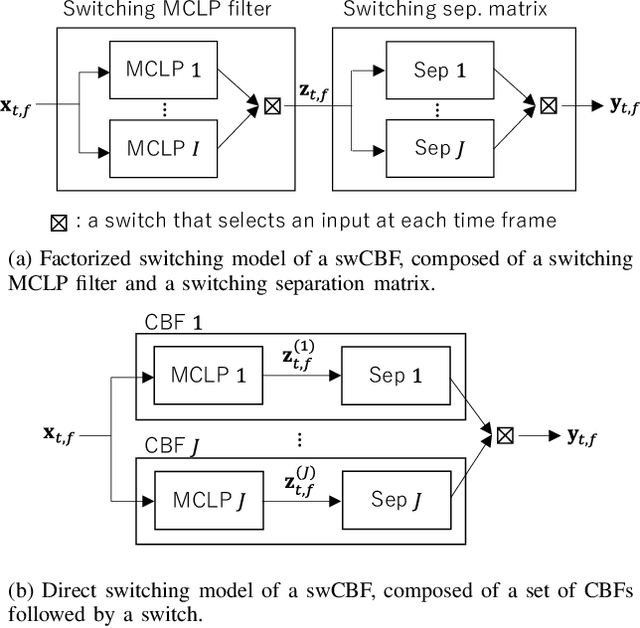
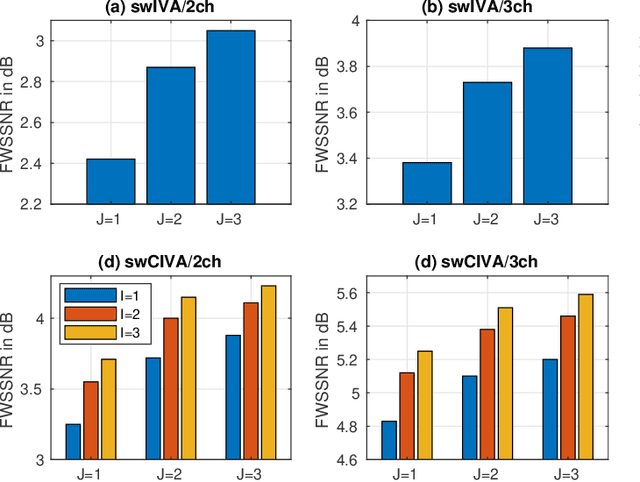
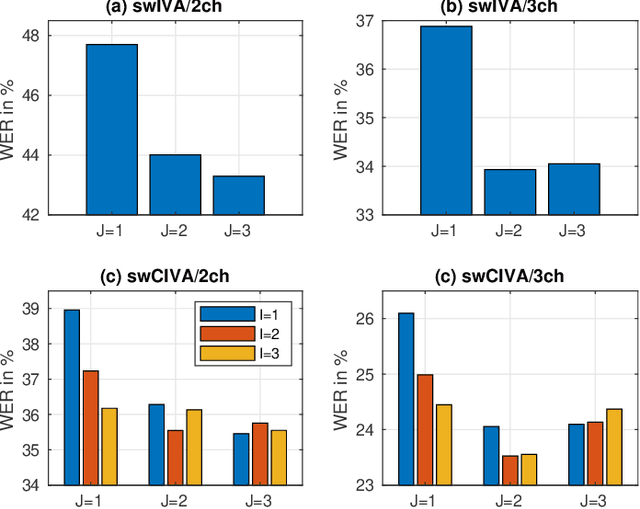
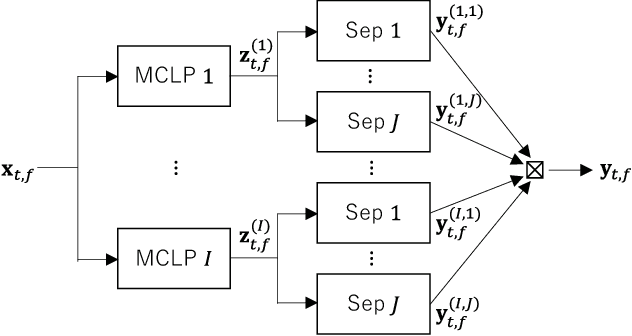
This paper develops a framework that can perform denoising, dereverberation, and source separation accurately by using a relatively small number of microphones. It has been empirically confirmed that Independent Vector Analysis (IVA) can blindly separate $N$ sources from their sound mixture even with diffuse noise when a sufficiently large number ($=M$) of microphones are available (i.e., $M\gg N)$. However, the estimation accuracy seriously degrades as the number of microphones, or more specifically $M-N$ $(\ge 0)$, decreases. To overcome this limitation of IVA, we propose switching IVA (swIVA) in this paper. With swIVA, time frames of an observed signal with time-varying characteristics are clustered into several groups, each of which can be well handled by IVA using a small number of microphones, and thus accurate estimation can be achieved by applying {\IVA} individually to each of the groups. Conventionally, a switching mechanism was introduced into a beamformer; however, no blind source separation algorithms with a switching mechanism have been successfully developed until this paper. In order to incorporate dereverberation capability, this paper further extends swIVA to blind Convolutional beamforming algorithm (swCIVA). It integrates swIVA and switching Weighted Prediction Error-based dereverberation (swWPE) in a jointly optimal way. We show that both swIVA and swIVAconv can be optimized effectively based on blind signal processing, and that their performance can be further improved using a spatial guide for the initialization. Experiments show that the both proposed methods largely outperform conventional IVA and its Convolutional beamforming extension (CIVA) in terms of objective signal quality and automatic speech recognition scores when using a relatively small number of microphones.
Blind and neural network-guided convolutional beamformer for joint denoising, dereverberation, and source separation
Aug 04, 2021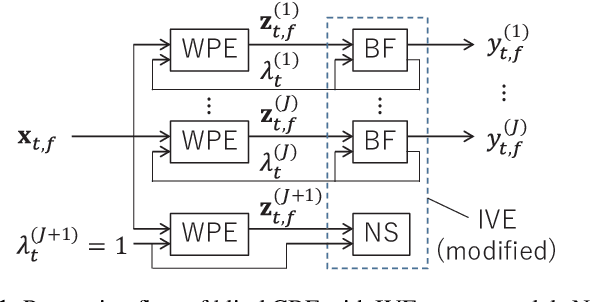
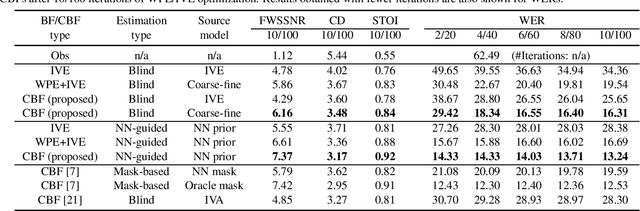
This paper proposes an approach for optimizing a Convolutional BeamFormer (CBF) that can jointly perform denoising (DN), dereverberation (DR), and source separation (SS). First, we develop a blind CBF optimization algorithm that requires no prior information on the sources or the room acoustics, by extending a conventional joint DR and SS method. For making the optimization computationally tractable, we incorporate two techniques into the approach: the Source-Wise Factorization (SW-Fact) of a CBF and the Independent Vector Extraction (IVE). To further improve the performance, we develop a method that integrates a neural network(NN) based source power spectra estimation with CBF optimization by an inverse-Gamma prior. Experiments using noisy reverberant mixtures reveal that our proposed method with both blind and NN-guided scenarios greatly outperforms the conventional state-of-the-art NN-supported mask-based CBF in terms of the improvement in automatic speech recognition and signal distortion reduction performance.