 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZIPP:Zero-shot Image Personalization from Personas
Jun 07, 2026Text-to-image diffusion models are increasingly deployed in open-ended creative contexts, yet their outputs remain impersonal, optimized for aggregate aesthetics rather than individual taste. Human preferences are pluralistic: one user favoring muted, nostalgic portraits may prefer vibrant street photography, while another gravitates toward dreamy film aesthetics. Existing methods require dense interaction histories or per-user fine-tuning, failing in cold-start settings and collapsing context-dependent preferences into a static representation. We introduce zero-shot image personalization from personas (ZIPP), which conditions image generation on natural-language personas (concise descriptors of a user's identity and aesthetic sensibilities) without any user-specific data or weight updates. ZIPP uses an LLM to rewrite prompts from the perspective of a given persona, steering diffusion models toward personalized outputs. To mine personas at scale, we train an inductive Graph Attention Network over a 22M-user Reddit interaction graph with dual contrastive objectives aligning graph structure with visual behavior, then verbalize learned representations into natural-language personas via an MLLM. We introduce ZIPBench, the first zero-shot personalization benchmark with 1.5K users, graph-mined personas, and 40K generated images. Across four benchmarks and 14 LLMs spanning five model families, persona conditioning yields consistent gains (13-20%), with frontier models benefiting most. In the few-shot setting, ZIPP matches or exceeds fine-tuned baselines trained on 100+ examples per user. ZIPP achieves the lowest preference distributional divergence (CMMD 0.16 vs. 0.55), and IPF-normalized demographic evaluation shows it substantially reduces subpopulation bias present in existing methods. Human evaluation confirms a 79% win rate over generic generation and 58-65% over all fine-tuned baselines.
Bridging Expert Knowledge and Automated Feature Engineering via Self-Evolution
Jun 07, 2026In high-stakes settings such as brand compliance, clinical care, and content moderation, machine learning cannot be deployed as opaque oracles: practitioners inspect the features driving model decisions, and models must leverage the expert documentation governing these domains. In practice, the data arrives as unstructured content, and features extracted from it must be interpretable, discriminative, and aligned with what experts consider important. Existing methods fall short: they target tabular inputs, lack demonstrated expert alignment, and cannot operationalize qualitative criteria such as 'maintain professional tone' into precise features. We present FEST (Feature Engineering with Self-evolving Trees), combining dual-stream feature generation (semantic and deterministic), semantic deduplication, and tree-guided iterative evolution to discover auditable features from raw text and images. FEST leads in 17 of 20 classifier-task combinations across brand classification, content authenticity detection, and stress detection, with a mean gain of 4.2 pp over the strongest baseline across five classifiers. An LLM-as-judge evaluation shows FEST achieves 60-80% coverage of expert-designed brand features at strict semantic-alignment thresholds, corroborated by a human expert study rating features highly on relevance, clarity, and actionability. When seeded with expert guidelines, FEST refines qualitative criteria into operational features, improving accuracy by 6-12 pp on average across brands. To enable systematic evaluation of expert alignment in automated feature engineering, we release BrandGuide, the first dataset pairing expert-designed features with 1M+ assets across 2,683 brands. By grounding feature engineering in expert knowledge, FEST opens a practical pathway for interpretable ML in domains demanding human oversight.
Accelerating Social Science Research via Agentic Hypothesization and Experimentation
Feb 08, 2026Data-driven social science research is inherently slow, relying on iterative cycles of observation, hypothesis generation, and experimental validation. While recent data-driven methods promise to accelerate parts of this process, they largely fail to support end-to-end scientific discovery. To address this gap, we introduce EXPERIGEN, an agentic framework that operationalizes end-to-end discovery through a Bayesian optimization inspired two-phase search, in which a Generator proposes candidate hypotheses and an Experimenter evaluates them empirically. Across multiple domains, EXPERIGEN consistently discovers 2-4x more statistically significant hypotheses that are 7-17 percent more predictive than prior approaches, and naturally extends to complex data regimes including multimodal and relational datasets. Beyond statistical performance, hypotheses must be novel, empirically grounded, and actionable to drive real scientific progress. To evaluate these qualities, we conduct an expert review of machine-generated hypotheses, collecting feedback from senior faculty. Among 25 reviewed hypotheses, 88 percent were rated moderately or strongly novel, 70 percent were deemed impactful and worth pursuing, and most demonstrated rigor comparable to senior graduate-level research. Finally, recognizing that ultimate validation requires real-world evidence, we conduct the first A/B test of LLM-generated hypotheses, observing statistically significant results with p less than 1e-6 and a large effect size of 344 percent.
Synthesizing Human Gaze Feedback for Improved NLP Performance
Feb 11, 2023



Integrating human feedback in models can improve the performance of natural language processing (NLP) models. Feedback can be either explicit (e.g. ranking used in training language models) or implicit (e.g. using human cognitive signals in the form of eyetracking). Prior eye tracking and NLP research reveal that cognitive processes, such as human scanpaths, gleaned from human gaze patterns aid in the understanding and performance of NLP models. However, the collection of real eyetracking data for NLP tasks is challenging due to the requirement of expensive and precise equipment coupled with privacy invasion issues. To address this challenge, we propose ScanTextGAN, a novel model for generating human scanpaths over text. We show that ScanTextGAN-generated scanpaths can approximate meaningful cognitive signals in human gaze patterns. We include synthetically generated scanpaths in four popular NLP tasks spanning six different datasets as proof of concept and show that the models augmented with generated scanpaths improve the performance of all downstream NLP tasks.
Persuasion Strategies in Advertisements: Dataset, Modeling, and Baselines
Aug 20, 2022
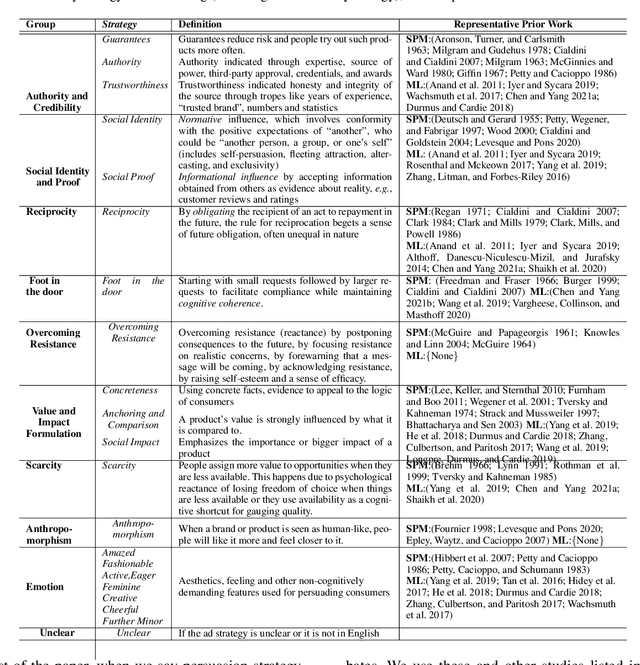

Modeling what makes an advertisement persuasive, i.e., eliciting the desired response from consumer, is critical to the study of propaganda, social psychology, and marketing. Despite its importance, computational modeling of persuasion in computer vision is still in its infancy, primarily due to the lack of benchmark datasets that can provide persuasion-strategy labels associated with ads. Motivated by persuasion literature in social psychology and marketing, we introduce an extensive vocabulary of persuasion strategies and build the first ad image corpus annotated with persuasion strategies. We then formulate the task of persuasion strategy prediction with multi-modal learning, where we design a multi-task attention fusion model that can leverage other ad-understanding tasks to predict persuasion strategies. Further, we conduct a real-world case study on 1600 advertising campaigns of 30 Fortune-500 companies where we use our model's predictions to analyze which strategies work with different demographics (age and gender). The dataset also provides image segmentation masks, which labels persuasion strategies in the corresponding ad images on the test split. We publicly release our code and dataset https://midas-research.github.io/persuasion-advertisements/.
LDKP: A Dataset for Identifying Keyphrases from Long Scientific Documents
Apr 01, 2022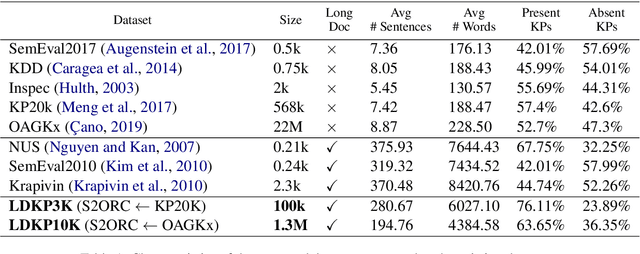
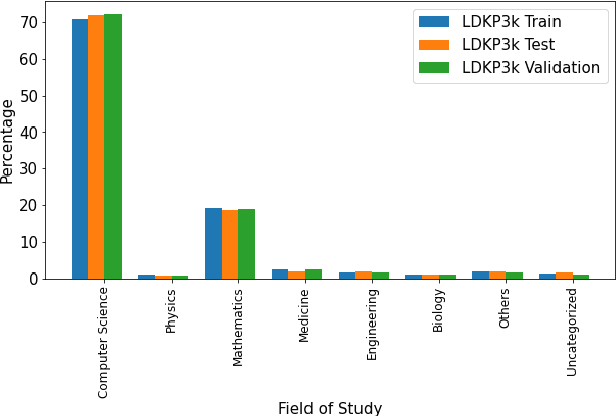
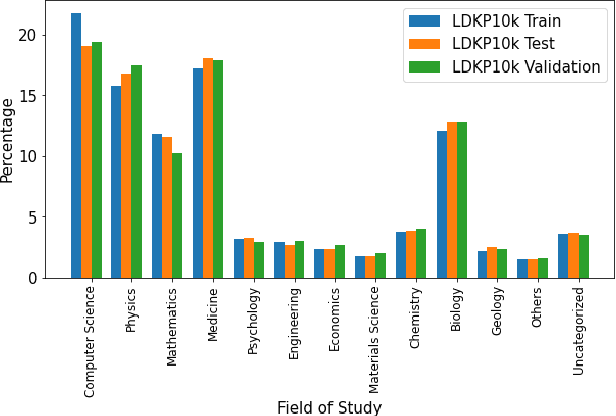
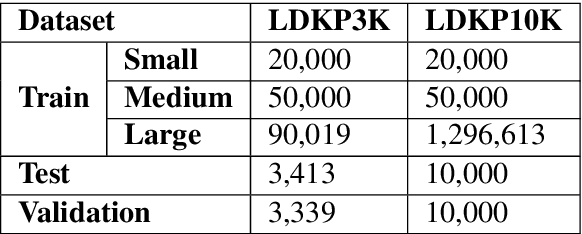
Identifying keyphrases (KPs) from text documents is a fundamental task in natural language processing and information retrieval. Vast majority of the benchmark datasets for this task are from the scientific domain containing only the document title and abstract information. This limits keyphrase extraction (KPE) and keyphrase generation (KPG) algorithms to identify keyphrases from human-written summaries that are often very short (approx 8 sentences). This presents three challenges for real-world applications: human-written summaries are unavailable for most documents, the documents are almost always long, and a high percentage of KPs are directly found beyond the limited context of title and abstract. Therefore, we release two extensive corpora mapping KPs of ~1.3M and ~100K scientific articles with their fully extracted text and additional metadata including publication venue, year, author, field of study, and citations for facilitating research on this real-world problem.
Span Classification with Structured Information for Disfluency Detection in Spoken Utterances
Mar 30, 2022

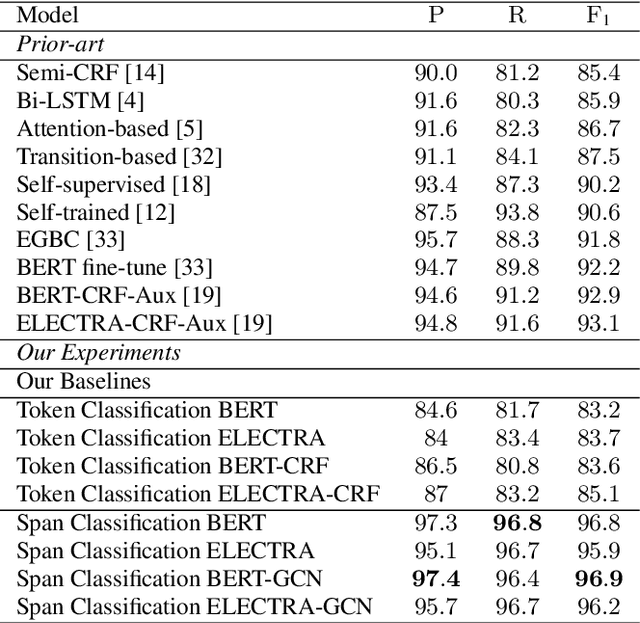
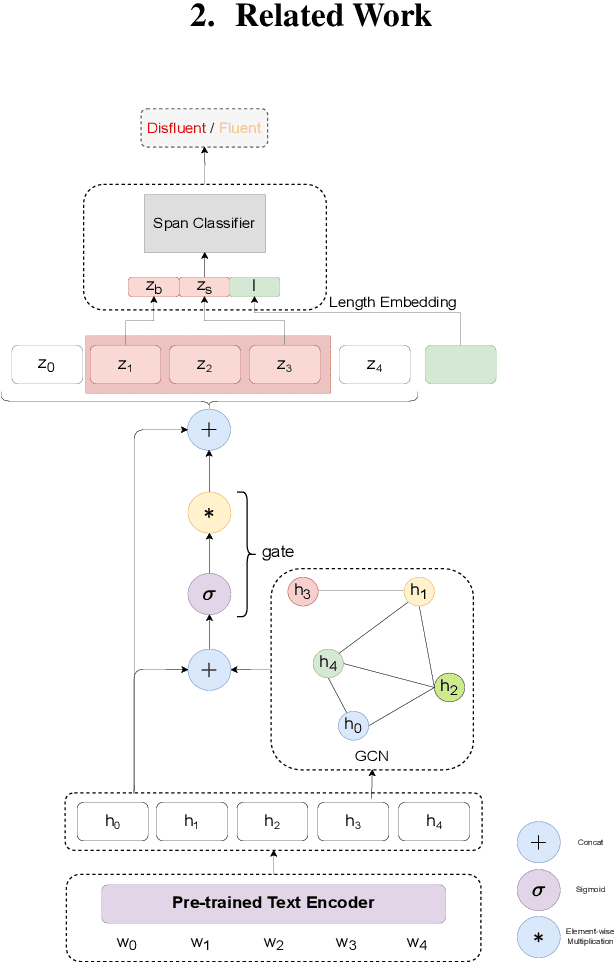
Existing approaches in disfluency detection focus on solving a token-level classification task for identifying and removing disfluencies in text. Moreover, most works focus on leveraging only contextual information captured by the linear sequences in text, thus ignoring the structured information in text which is efficiently captured by dependency trees. In this paper, building on the span classification paradigm of entity recognition, we propose a novel architecture for detecting disfluencies in transcripts from spoken utterances, incorporating both contextual information through transformers and long-distance structured information captured by dependency trees, through graph convolutional networks (GCNs). Experimental results show that our proposed model achieves state-of-the-art results on the widely used English Switchboard for disfluency detection and outperforms prior-art by a significant margin. We make all our codes publicly available on GitHub (https://github.com/Sreyan88/Disfluency-Detection-with-Span-Classification)
Automated Speech Scoring System Under The Lens: Evaluating and interpreting the linguistic cues for language proficiency
Nov 30, 2021
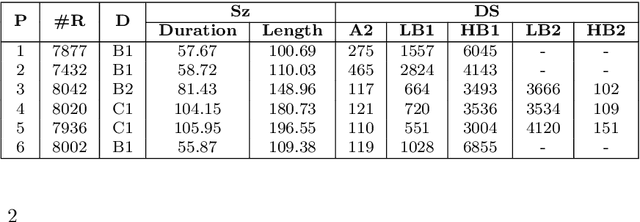
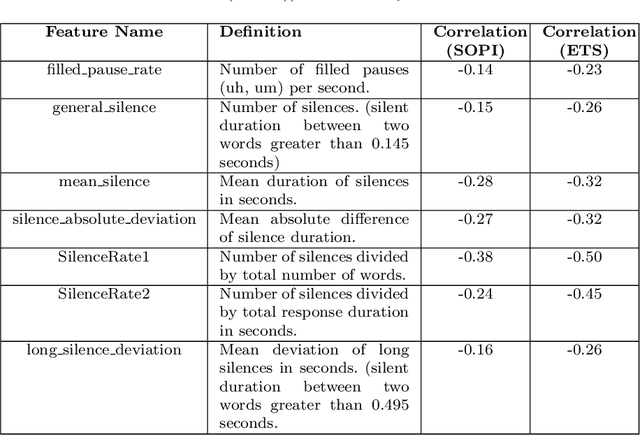
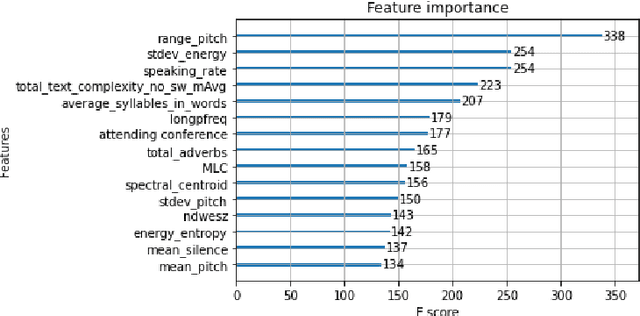
English proficiency assessments have become a necessary metric for filtering and selecting prospective candidates for both academia and industry. With the rise in demand for such assessments, it has become increasingly necessary to have the automated human-interpretable results to prevent inconsistencies and ensure meaningful feedback to the second language learners. Feature-based classical approaches have been more interpretable in understanding what the scoring model learns. Therefore, in this work, we utilize classical machine learning models to formulate a speech scoring task as both a classification and a regression problem, followed by a thorough study to interpret and study the relation between the linguistic cues and the English proficiency level of the speaker. First, we extract linguist features under five categories (fluency, pronunciation, content, grammar and vocabulary, and acoustic) and train models to grade responses. In comparison, we find that the regression-based models perform equivalent to or better than the classification approach. Second, we perform ablation studies to understand the impact of each of the feature and feature categories on the performance of proficiency grading. Further, to understand individual feature contributions, we present the importance of top features on the best performing algorithm for the grading task. Third, we make use of Partial Dependence Plots and Shapley values to explore feature importance and conclude that the best performing trained model learns the underlying rubrics used for grading the dataset used in this study.
Using Sampling to Estimate and Improve Performance of Automated Scoring Systems with Guarantees
Nov 17, 2021
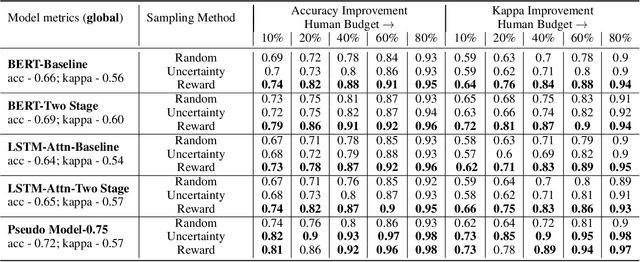
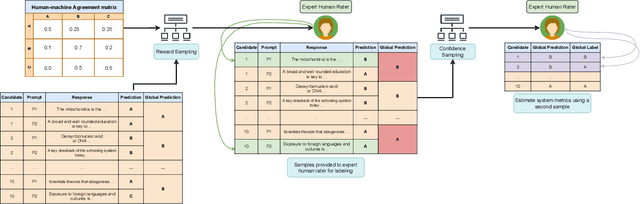
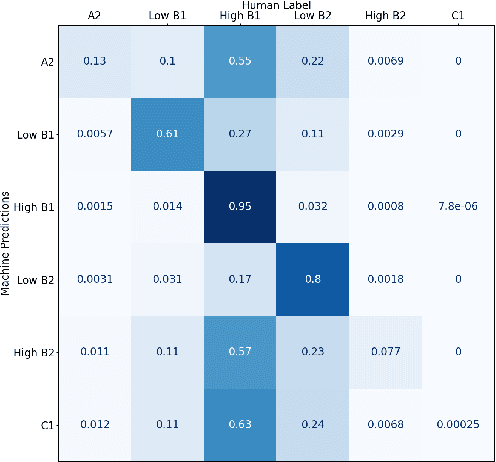
Automated Scoring (AS), the natural language processing task of scoring essays and speeches in an educational testing setting, is growing in popularity and being deployed across contexts from government examinations to companies providing language proficiency services. However, existing systems either forgo human raters entirely, thus harming the reliability of the test, or score every response by both human and machine thereby increasing costs. We target the spectrum of possible solutions in between, making use of both humans and machines to provide a higher quality test while keeping costs reasonable to democratize access to AS. In this work, we propose a combination of the existing paradigms, sampling responses to be scored by humans intelligently. We propose reward sampling and observe significant gains in accuracy (19.80% increase on average) and quadratic weighted kappa (QWK) (25.60% on average) with a relatively small human budget (30% samples) using our proposed sampling. The accuracy increase observed using standard random and importance sampling baselines are 8.6% and 12.2% respectively. Furthermore, we demonstrate the system's model agnostic nature by measuring its performance on a variety of models currently deployed in an AS setting as well as pseudo models. Finally, we propose an algorithm to estimate the accuracy/QWK with statistical guarantees (Our code is available at https://git.io/J1IOy).
AES Systems Are Both Overstable And Oversensitive: Explaining Why And Proposing Defenses
Oct 14, 2021

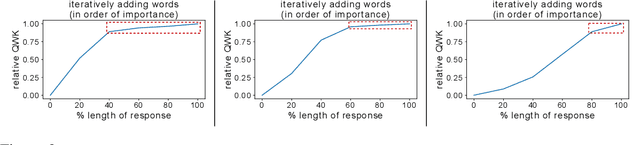
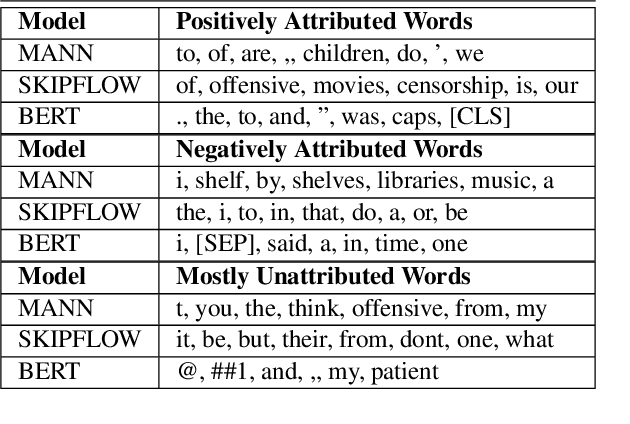
Deep-learning based Automatic Essay Scoring (AES) systems are being actively used by states and language testing agencies alike to evaluate millions of candidates for life-changing decisions ranging from college applications to visa approvals. However, little research has been put to understand and interpret the black-box nature of deep-learning based scoring algorithms. Previous studies indicate that scoring models can be easily fooled. In this paper, we explore the reason behind their surprising adversarial brittleness. We utilize recent advances in interpretability to find the extent to which features such as coherence, content, vocabulary, and relevance are important for automated scoring mechanisms. We use this to investigate the oversensitivity i.e., large change in output score with a little change in input essay content) and overstability i.e., little change in output scores with large changes in input essay content) of AES. Our results indicate that autoscoring models, despite getting trained as "end-to-end" models with rich contextual embeddings such as BERT, behave like bag-of-words models. A few words determine the essay score without the requirement of any context making the model largely overstable. This is in stark contrast to recent probing studies on pre-trained representation learning models, which show that rich linguistic features such as parts-of-speech and morphology are encoded by them. Further, we also find that the models have learnt dataset biases, making them oversensitive. To deal with these issues, we propose detection-based protection models that can detect oversensitivity and overstability causing samples with high accuracies. We find that our proposed models are able to detect unusual attribution patterns and flag adversarial samples successfully.