 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Improving CTC-based ASR Models with Gated Interlayer Collaboration
May 25, 2022
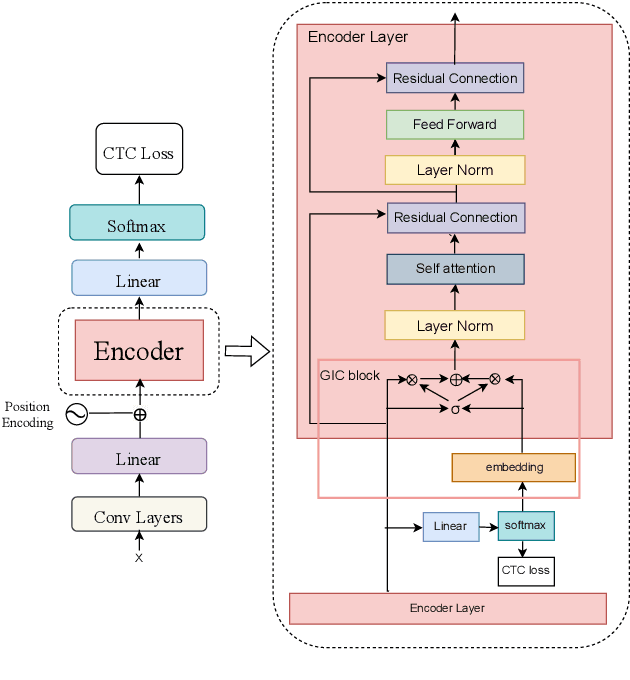
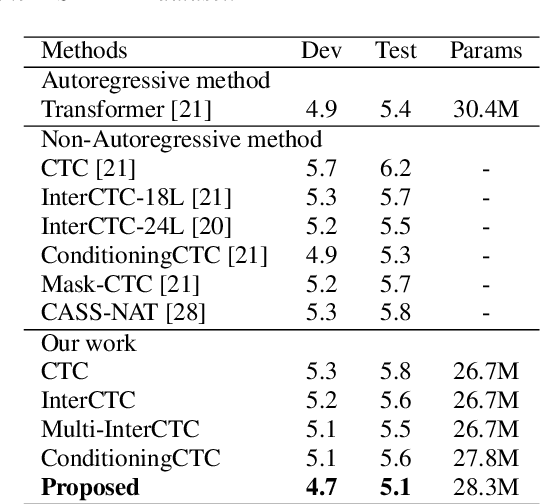
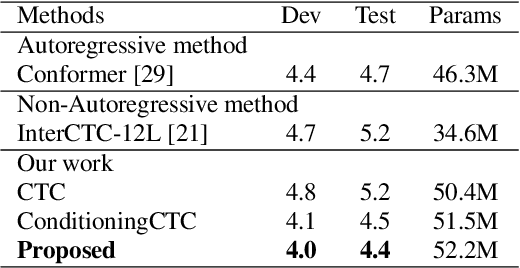
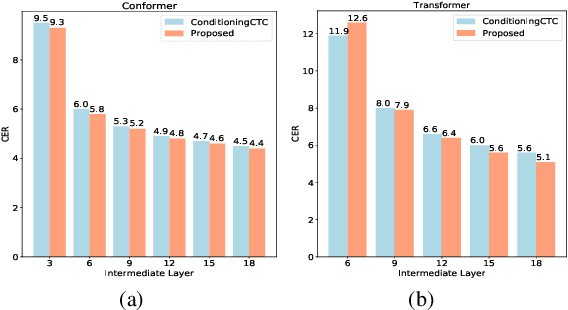
For Automatic Speech Recognition (ASR), the CTC-based methods have become a dominant paradigm due to its simple architecture and efficient non-autoregressive inference manner. However, these methods without external language models usually lack the capacity of modeling the conditional dependencies and the textual interaction. In this work, we present a Gated Interlayer Collaboration (GIC) mechanism which introduces the contextual information into the models and relaxes the conditional independence assumption of the CTC-based models. Specifically, we train the model with intermediate CTC losses calculated by the interlayer outputs of the model, in which the probability distributions of the intermediate layers naturally serve as soft label sequences. The GIC block consists of an embedding layer to obtain the textual embedding of the soft label at each position, and a gate unit to fuse the textual embedding and the acoustic features. Experiments on AISHELL-1 and AIDATATANG benchmarks show that the proposed method outperforms the recently published CTC-based ASR models. Specifically, our method achieves CER of 4.0%/4.4% on AISHELL-1 dev/test sets and CER of 3.8%/4.4% on AIDATATANG dev/test sets using CTC greedy search decoding without external language models.
User-friendly automatic transcription of low-resource languages: Plugging ESPnet into Elpis
Dec 15, 2020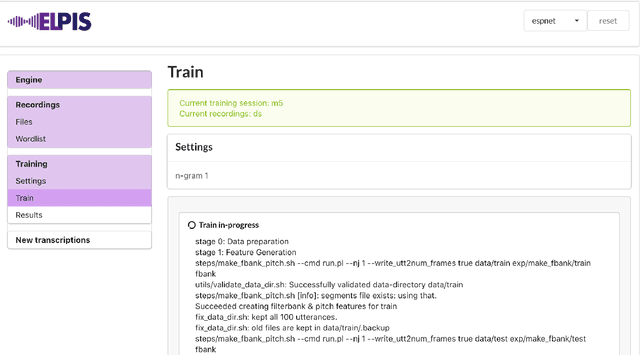

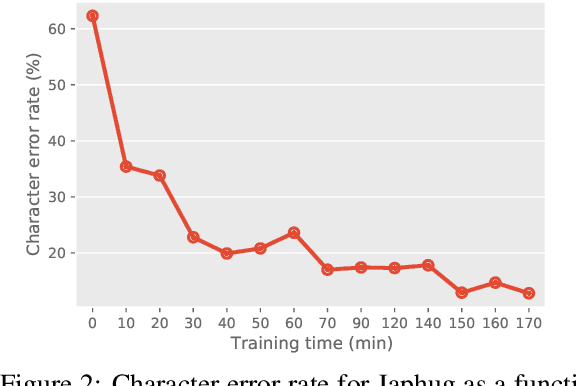
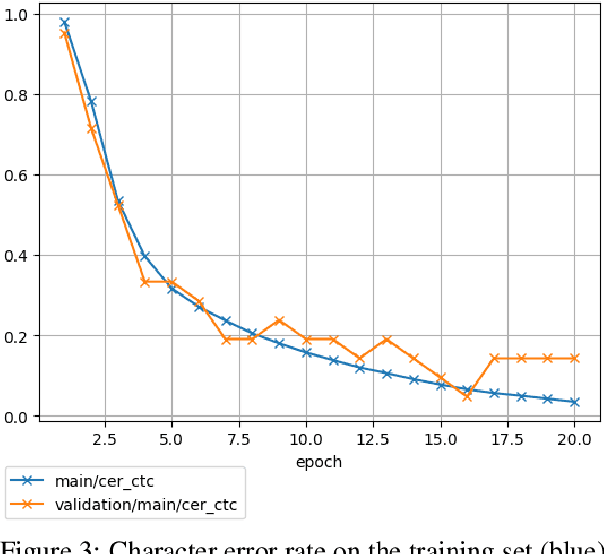
This paper reports on progress integrating the speech recognition toolkit ESPnet into Elpis, a web front-end originally designed to provide access to the Kaldi automatic speech recognition toolkit. The goal of this work is to make end-to-end speech recognition models available to language workers via a user-friendly graphical interface. Encouraging results are reported on (i) development of an ESPnet recipe for use in Elpis, with preliminary results on data sets previously used for training acoustic models with the Persephone toolkit along with a new data set that had not previously been used in speech recognition, and (ii) incorporating ESPnet into Elpis along with UI enhancements and a CUDA-supported Dockerfile.
A Unified Cascaded Encoder ASR Model for Dynamic Model Sizes
Apr 13, 2022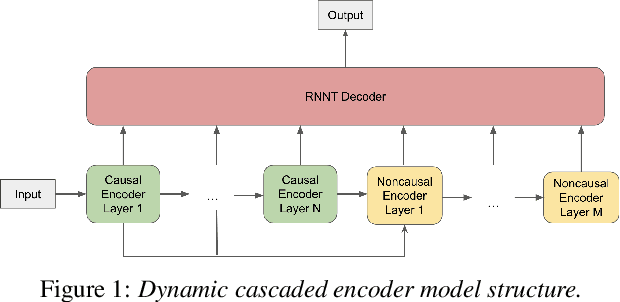
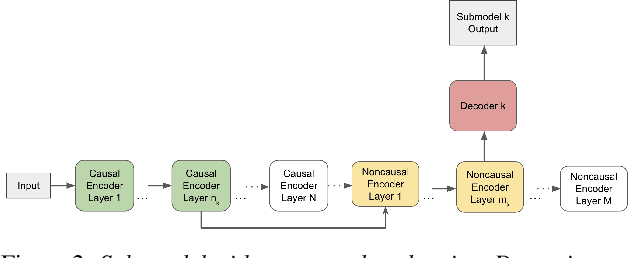
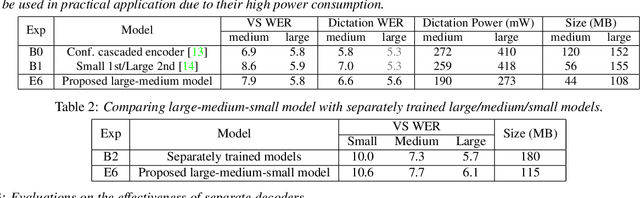
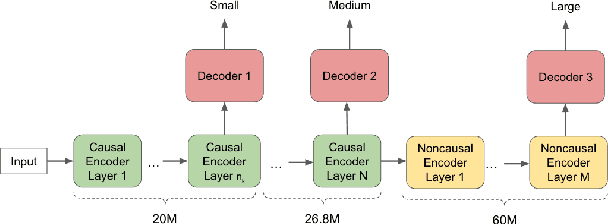
In this paper, we propose a dynamic cascaded encoder Automatic Speech Recognition (ASR) model, which unifies models for different deployment scenarios. Moreover, the model can significantly reduce model size and power consumption without loss of quality. Namely, with the dynamic cascaded encoder model, we explore three techniques to maximally boost the performance of each model size: 1) Use separate decoders for each sub-model while sharing the encoders; 2) Use funnel-pooling to improve the encoder efficiency; 3) Balance the size of causal and non-causal encoders to improve quality and fit deployment constraints. Overall, the proposed large-medium model has 30% smaller size and reduces power consumption by 33%, compared to the baseline cascaded encoder model. The triple-size model that unifies the large, medium, and small models achieves 37% total size reduction with minimal quality loss, while substantially reducing the engineering efforts of having separate models.
DPSNN: A Differentially Private Spiking Neural Network
May 24, 2022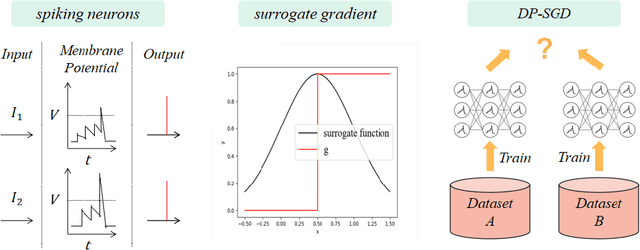

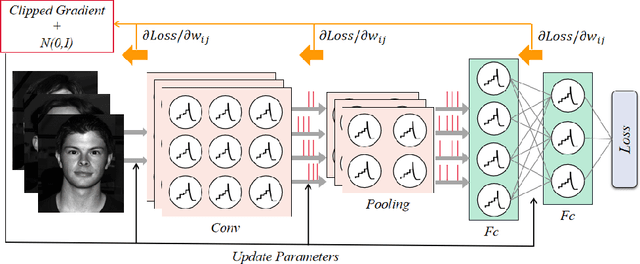
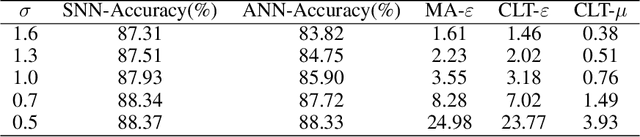
Privacy-preserving is a key problem for the machine learning algorithm. Spiking neural network (SNN) plays an important role in many domains, such as image classification, object detection, and speech recognition, but the study on the privacy protection of SNN is urgently needed. This study combines the differential privacy (DP) algorithm and SNN and proposes differentially private spiking neural network (DPSNN). DP injects noise into the gradient, and SNN transmits information in discrete spike trains so that our differentially private SNN can maintain strong privacy protection while still ensuring high accuracy. We conducted experiments on MNIST, Fashion-MNIST, and the face recognition dataset Extended YaleB. When the privacy protection is improved, the accuracy of the artificial neural network(ANN) drops significantly, but our algorithm shows little change in performance. Meanwhile, we analyzed different factors that affect the privacy protection of SNN. Firstly, the less precise the surrogate gradient is, the better the privacy protection of the SNN. Secondly, the Integrate-And-Fire (IF) neurons perform better than leaky Integrate-And-Fire (LIF) neurons. Thirdly, a large time window contributes more to privacy protection and performance.
Open Source MagicData-RAMC: A Rich Annotated Mandarin Conversational(RAMC) Speech Dataset
Mar 31, 2022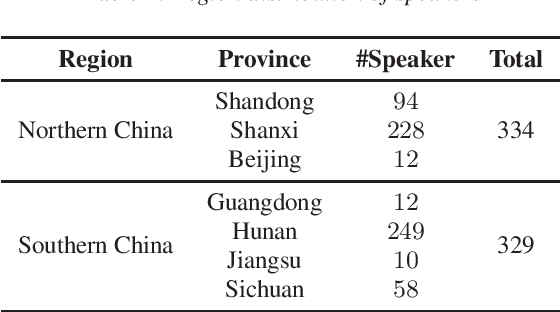
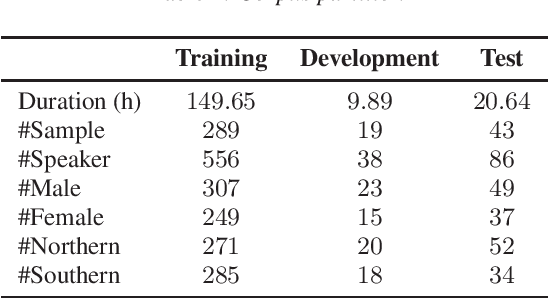
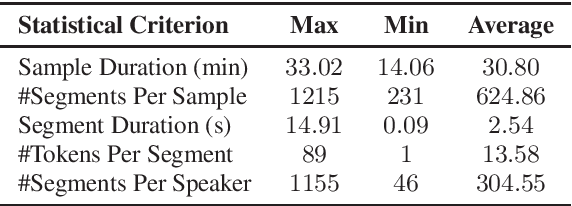
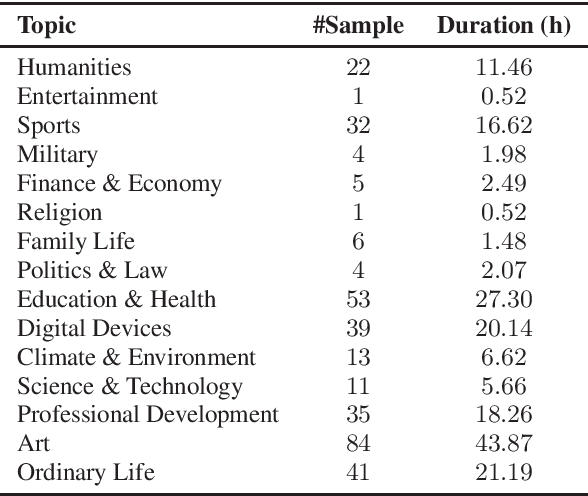
This paper introduces a high-quality rich annotated Mandarin conversational (RAMC) speech dataset called MagicData-RAMC. The MagicData-RAMC corpus contains 180 hours of conversational speech data recorded from native speakers of Mandarin Chinese over mobile phones with a sampling rate of 16 kHz. The dialogs in MagicData-RAMC are classified into 15 diversified domains and tagged with topic labels, ranging from science and technology to ordinary life. Accurate transcription and precise speaker voice activity timestamps are manually labeled for each sample. Speakers' detailed information is also provided. As a Mandarin speech dataset designed for dialog scenarios with high quality and rich annotations, MagicData-RAMC enriches the data diversity in the Mandarin speech community and allows extensive research on a series of speech-related tasks, including automatic speech recognition, speaker diarization, topic detection, keyword search, text-to-speech, etc. We also conduct several relevant tasks and provide experimental results to help evaluate the dataset.
Deep Learning for Distant Speech Recognition
Dec 17, 2017
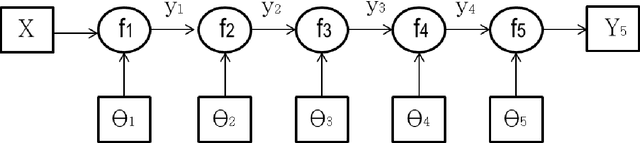
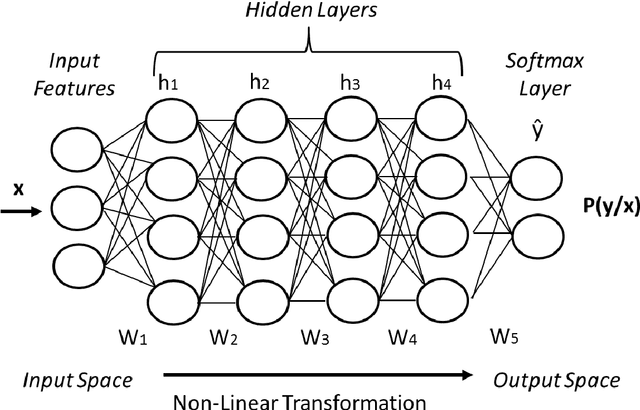
Deep learning is an emerging technology that is considered one of the most promising directions for reaching higher levels of artificial intelligence. Among the other achievements, building computers that understand speech represents a crucial leap towards intelligent machines. Despite the great efforts of the past decades, however, a natural and robust human-machine speech interaction still appears to be out of reach, especially when users interact with a distant microphone in noisy and reverberant environments. The latter disturbances severely hamper the intelligibility of a speech signal, making Distant Speech Recognition (DSR) one of the major open challenges in the field. This thesis addresses the latter scenario and proposes some novel techniques, architectures, and algorithms to improve the robustness of distant-talking acoustic models. We first elaborate on methodologies for realistic data contamination, with a particular emphasis on DNN training with simulated data. We then investigate on approaches for better exploiting speech contexts, proposing some original methodologies for both feed-forward and recurrent neural networks. Lastly, inspired by the idea that cooperation across different DNNs could be the key for counteracting the harmful effects of noise and reverberation, we propose a novel deep learning paradigm called network of deep neural networks. The analysis of the original concepts were based on extensive experimental validations conducted on both real and simulated data, considering different corpora, microphone configurations, environments, noisy conditions, and ASR tasks.
Large-Scale Streaming End-to-End Speech Translation with Neural Transducers
Apr 11, 2022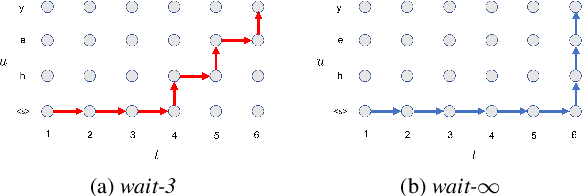
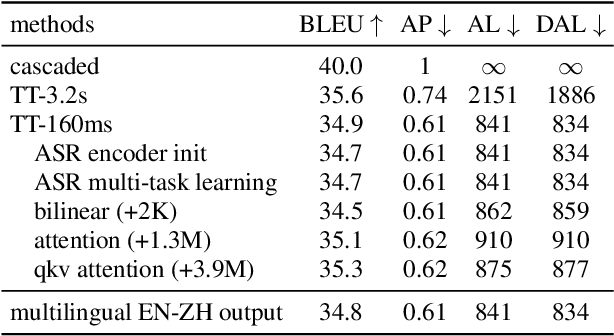
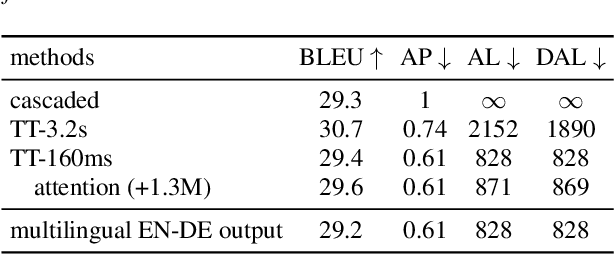
Neural transducers have been widely used in automatic speech recognition (ASR). In this paper, we introduce it to streaming end-to-end speech translation (ST), which aims to convert audio signals to texts in other languages directly. Compared with cascaded ST that performs ASR followed by text-based machine translation (MT), the proposed Transformer transducer (TT)-based ST model drastically reduces inference latency, exploits speech information, and avoids error propagation from ASR to MT. To improve the modeling capacity, we propose attention pooling for the joint network in TT. In addition, we extend TT-based ST to multilingual ST, which generates texts of multiple languages at the same time. Experimental results on a large-scale 50 thousand (K) hours pseudo-labeled training set show that TT-based ST not only significantly reduces inference time but also outperforms non-streaming cascaded ST for English-German translation.
Invariant Representations for Noisy Speech Recognition
Nov 27, 2016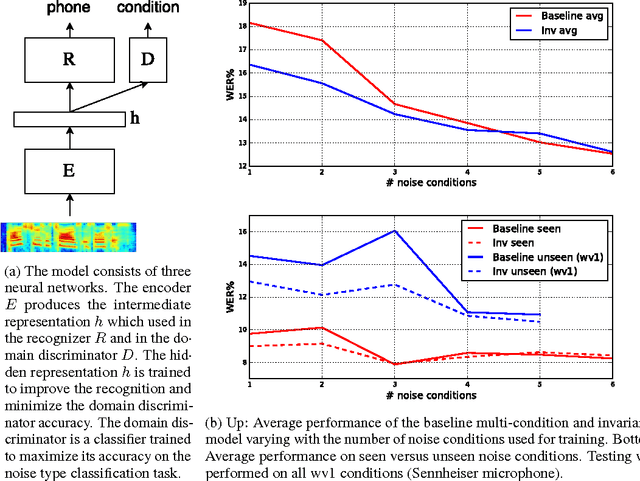
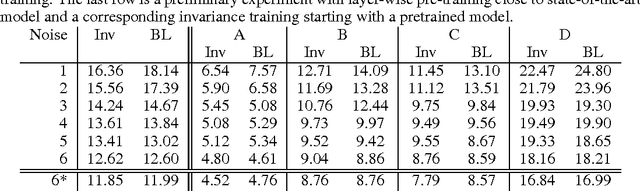
Modern automatic speech recognition (ASR) systems need to be robust under acoustic variability arising from environmental, speaker, channel, and recording conditions. Ensuring such robustness to variability is a challenge in modern day neural network-based ASR systems, especially when all types of variability are not seen during training. We attempt to address this problem by encouraging the neural network acoustic model to learn invariant feature representations. We use ideas from recent research on image generation using Generative Adversarial Networks and domain adaptation ideas extending adversarial gradient-based training. A recent work from Ganin et al. proposes to use adversarial training for image domain adaptation by using an intermediate representation from the main target classification network to deteriorate the domain classifier performance through a separate neural network. Our work focuses on investigating neural architectures which produce representations invariant to noise conditions for ASR. We evaluate the proposed architecture on the Aurora-4 task, a popular benchmark for noise robust ASR. We show that our method generalizes better than the standard multi-condition training especially when only a few noise categories are seen during training.
Integrating Source-channel and Attention-based Sequence-to-sequence Models for Speech Recognition
Oct 01, 2019
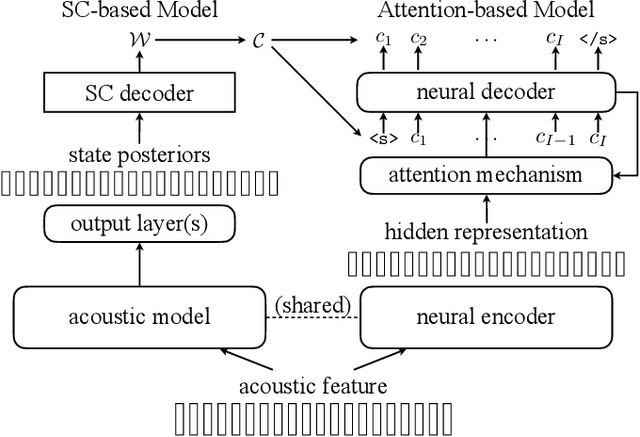

This paper proposes a novel automatic speech recognition (ASR) framework called Integrated Source-Channel and Attention (ISCA) that combines the advantages of traditional systems based on the noisy source-channel model (SC) and end-to-end style systems using attention-based sequence-to-sequence models. The traditional SC system framework includes hidden Markov models and connectionist temporal classification (CTC) based acoustic models, language models (LMs), and a decoding procedure based on a lexicon, whereas the end-to-end style attention-based system jointly models the whole process with a single model. By rescoring the hypotheses produced by traditional systems using end-to-end style systems based on an extended noisy source-channel model, ISCA allows structured knowledge to be easily incorporated via the SC-based model while exploiting the complementarity of the attention-based model. Experiments on the AMI meeting corpus show that ISCA is able to give a relative word error rate reduction up to 21% over an individual system, and by 13% over an alternative method which also involves combining CTC and attention-based models.
Speech Emotion Recognition System by Quaternion Nonlinear Echo State Network
Nov 14, 2021
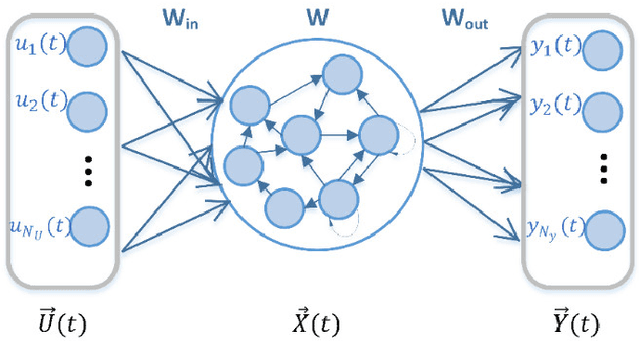
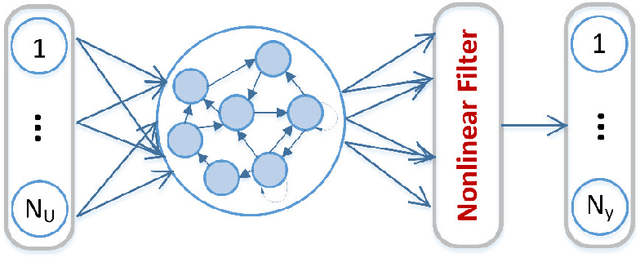
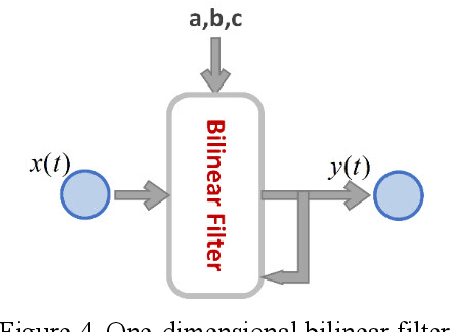
The echo state network (ESN) is a powerful and efficient tool for displaying dynamic data. However, many existing ESNs have limitations for properly modeling high-dimensional data. The most important limitation of these networks is the high memory consumption due to their reservoir structure, which has prevented the increase of reservoir units and the maximum use of special capabilities of this type of network. One way to solve this problem is to use quaternion algebra. Because quaternions have four different dimensions, high-dimensional data are easily represented and, using Hamilton multiplication, with fewer parameters than real numbers, make external relations between the multidimensional features easier. In addition to the memory problem in the ESN network, the linear output of the ESN network poses an indescribable limit to its processing capacity, as it cannot effectively utilize higher-order statistics of features provided by the nonlinear dynamics of reservoir neurons. In this research, a new structure based on ESN is presented, in which quaternion algebra is used to compress the network data with the simple split function, and the output linear combiner is replaced by a multidimensional bilinear filter. This filter will be used for nonlinear calculations of the output layer of the ESN. In addition, the two-dimensional principal component analysis technique is used to reduce the number of data transferred to the bilinear filter. In this study, the coefficients and the weights of the quaternion nonlinear ESN (QNESN) are optimized using the genetic algorithm. In order to prove the effectiveness of the proposed model compared to the previous methods, experiments for speech emotion recognition have been performed on EMODB, SAVEE, and IEMOCAP speech emotional datasets. Comparisons show that the proposed QNESN network performs better than the ESN and most currently SER systems.