 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating Source-channel and Attention-based Sequence-to-sequence Models for Speech Recognition
Paper and Code
Oct 01, 2019
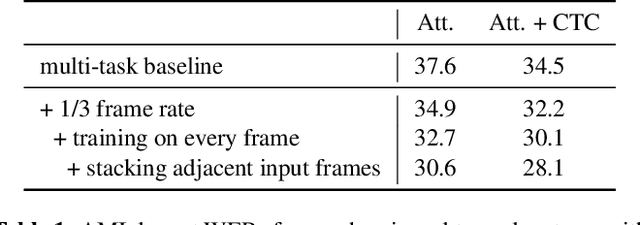
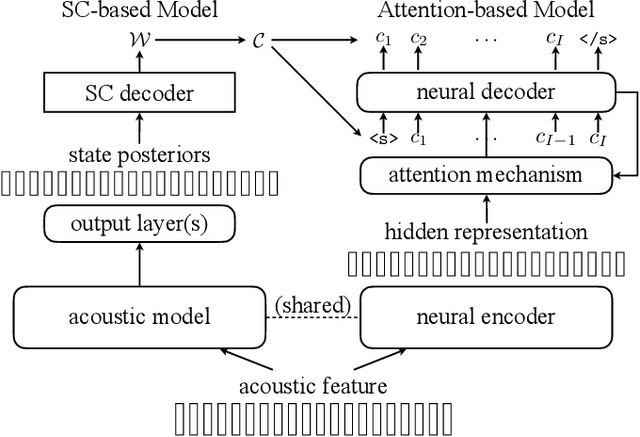

This paper proposes a novel automatic speech recognition (ASR) framework called Integrated Source-Channel and Attention (ISCA) that combines the advantages of traditional systems based on the noisy source-channel model (SC) and end-to-end style systems using attention-based sequence-to-sequence models. The traditional SC system framework includes hidden Markov models and connectionist temporal classification (CTC) based acoustic models, language models (LMs), and a decoding procedure based on a lexicon, whereas the end-to-end style attention-based system jointly models the whole process with a single model. By rescoring the hypotheses produced by traditional systems using end-to-end style systems based on an extended noisy source-channel model, ISCA allows structured knowledge to be easily incorporated via the SC-based model while exploiting the complementarity of the attention-based model. Experiments on the AMI meeting corpus show that ISCA is able to give a relative word error rate reduction up to 21% over an individual system, and by 13% over an alternative method which also involves combining CTC and attention-based models.