 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeECG-NAT: A Self-supervised Neighborhood Attention Transformer for Multi-lead Electrocardiogram Classification
May 13, 2026Electrocardiogram (ECG) arrhythmia classification remains challenging due to signal variability, noise, limited labeled data, and the difficulty in achieving both accuracy and efficiency in models. While self-supervised learning reduces label dependency, most methods target either global contextual features or local morphological patterns, but rarely implement hierarchical multi-scale feature extraction. ECG signals require architectures that simultaneously capture fine-grained beat-level morphology and broader rhythm-level dependencies with computational efficiency. To overcome this limitation, this paper proposes the Electrocardiogram Neighborhood Attention Transformer (ECG-NAT), a novel self-supervised learning approach tailored for multi-lead ECG classification. Our two-stage approach begins with generative pretraining, using a masked autoencoder to reconstruct partially masked ECG signals across multiple diverse datasets, enabling the model to learn robust, domain-invariant representations from unlabeled data. This is followed by discriminative fine-tuning with a dual-loss function that combines supervised contrastive and cross-entropy losses, aligning representation learning with label prediction. The hierarchical attention mechanism efficiently captures multi-scale temporal features from localized beat morphology to broader rhythm patterns at low computational cost. ECG-NAT achieves robust performance on benchmark datasets, with 88.1\% accuracy using only 1\% labeled data, demonstrating strong efficacy in low-resource settings. The framework combines superior classification performance with computational efficiency, making it practical for real-time ECG diagnosis. The code will be made available upon acceptance at: https://github.com/Mahsagazeran/ECG-NAT.
GEM-FI: Gated Evidential Mixtures with Fisher Modulation
May 05, 2026Evidential Deep Learning (EDL) enables single-pass uncertainty estimation by predicting Dirichlet evidence, but it can remain overconfident and poorly calibrated, and it often fails to represent multi-modal epistemic uncertainty. We introduce Gated Evidential Mixtures (GEM), a family of models that learns an in-model energy signal and uses it to gate evidential outputs end-to-end in a distance-informed manner. GEM-CORE learns a feature-level energy and maps it to a bounded gate that smoothly suppresses evidence when support is low. To capture epistemic multi-modality without multi-pass ensembling, GEM-MIX adds a lightweight mixture of evidential heads with learned routing weights while preserving single-pass inference. Finally, GEM-FI stabilizes mixture allocations via a Fisher-informed regularizer, reducing head collapse and producing smoother boundary uncertainty. Across image classification and OOD detection benchmarks, GEM improves calibration and ID/OOD separation with single-pass inference. On CIFAR-10, GEM-FI vs. DAEDL improves accuracy from 91.11 to 93.75 (+2.64 pp), reduces Brier x100 from 14.27 to 6.81 (-7.46), and also improves misclassification-detection AUPR from 99.08 to 99.94 (+0.86). For epistemic OOD detection, GEM-FI achieves AUPR/AUROC of 92.59/95.09 on CIFAR-10 to SVHN and 90.20/89.06 on CIFAR-10 to CIFAR-100, compared with 85.54/89.30 and 88.19/86.10 for DAEDL.
Transfer Learning for Low-Resource Sentiment Analysis
Apr 10, 2023



Sentiment analysis is the process of identifying and extracting subjective information from text. Despite the advances to employ cross-lingual approaches in an automatic way, the implementation and evaluation of sentiment analysis systems require language-specific data to consider various sociocultural and linguistic peculiarities. In this paper, the collection and annotation of a dataset are described for sentiment analysis of Central Kurdish. We explore a few classical machine learning and neural network-based techniques for this task. Additionally, we employ an approach in transfer learning to leverage pretrained models for data augmentation. We demonstrate that data augmentation achieves a high F$_1$ score and accuracy despite the difficulty of the task.
Speech Emotion Recognition System by Quaternion Nonlinear Echo State Network
Nov 14, 2021
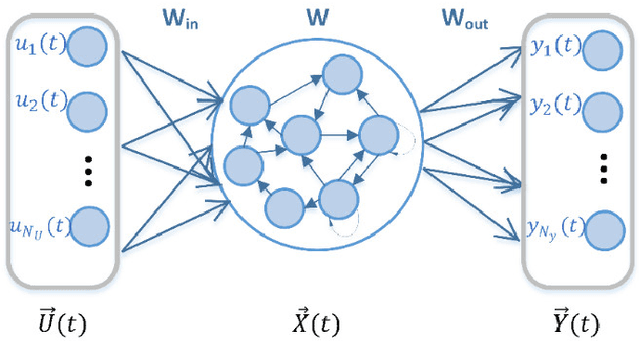
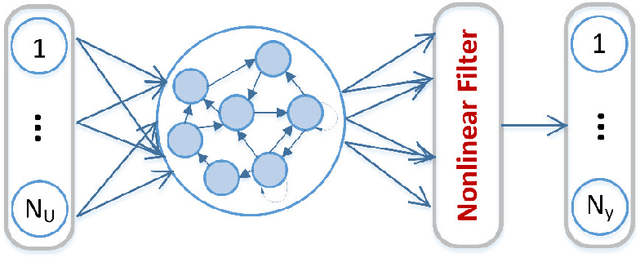
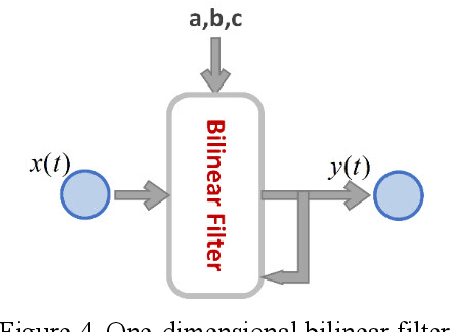
The echo state network (ESN) is a powerful and efficient tool for displaying dynamic data. However, many existing ESNs have limitations for properly modeling high-dimensional data. The most important limitation of these networks is the high memory consumption due to their reservoir structure, which has prevented the increase of reservoir units and the maximum use of special capabilities of this type of network. One way to solve this problem is to use quaternion algebra. Because quaternions have four different dimensions, high-dimensional data are easily represented and, using Hamilton multiplication, with fewer parameters than real numbers, make external relations between the multidimensional features easier. In addition to the memory problem in the ESN network, the linear output of the ESN network poses an indescribable limit to its processing capacity, as it cannot effectively utilize higher-order statistics of features provided by the nonlinear dynamics of reservoir neurons. In this research, a new structure based on ESN is presented, in which quaternion algebra is used to compress the network data with the simple split function, and the output linear combiner is replaced by a multidimensional bilinear filter. This filter will be used for nonlinear calculations of the output layer of the ESN. In addition, the two-dimensional principal component analysis technique is used to reduce the number of data transferred to the bilinear filter. In this study, the coefficients and the weights of the quaternion nonlinear ESN (QNESN) are optimized using the genetic algorithm. In order to prove the effectiveness of the proposed model compared to the previous methods, experiments for speech emotion recognition have been performed on EMODB, SAVEE, and IEMOCAP speech emotional datasets. Comparisons show that the proposed QNESN network performs better than the ESN and most currently SER systems.
Speech Emotion Recognition Using Deep Sparse Auto-Encoder Extreme Learning Machine with a New Weighting Scheme and Spectro-Temporal Features Along with Classical Feature Selection and A New Quantum-Inspired Dimension Reduction Method
Nov 13, 2021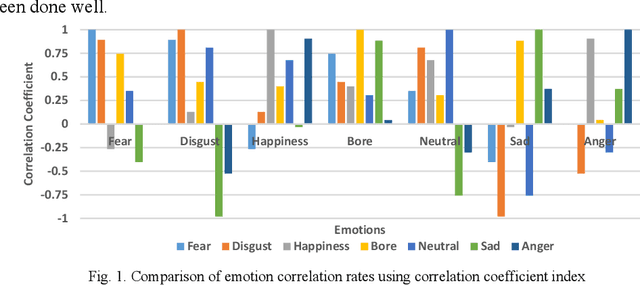
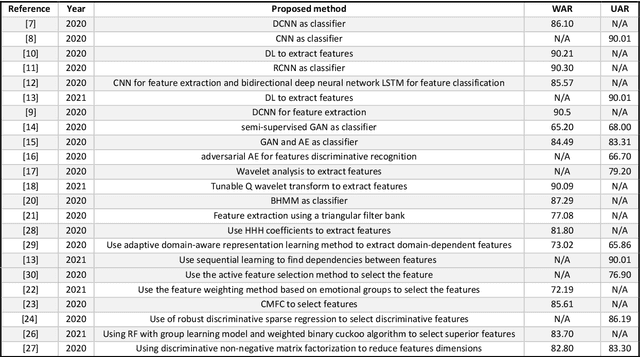
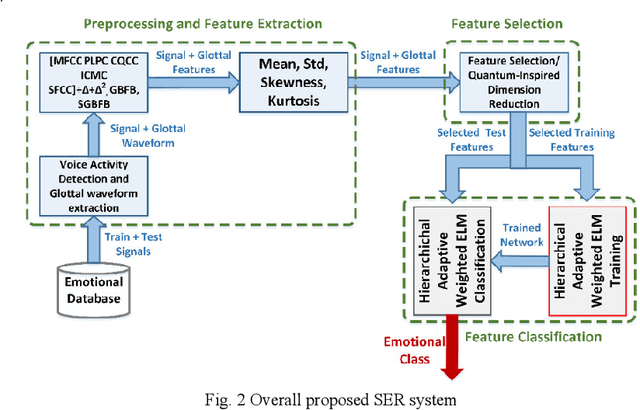

Affective computing is very important in the relationship between man and machine. In this paper, a system for speech emotion recognition (SER) based on speech signal is proposed, which uses new techniques in different stages of processing. The system consists of three stages: feature extraction, feature selection, and finally feature classification. In the first stage, a complex set of long-term statistics features is extracted from both the speech signal and the glottal-waveform signal using a combination of new and diverse features such as prosodic, spectral, and spectro-temporal features. One of the challenges of the SER systems is to distinguish correlated emotions. These features are good discriminators for speech emotions and increase the SER's ability to recognize similar and different emotions. This feature vector with a large number of dimensions naturally has redundancy. In the second stage, using classical feature selection techniques as well as a new quantum-inspired technique to reduce the feature vector dimensionality, the number of feature vector dimensions is reduced. In the third stage, the optimized feature vector is classified by a weighted deep sparse extreme learning machine (ELM) classifier. The classifier performs classification in three steps: sparse random feature learning, orthogonal random projection using the singular value decomposition (SVD) technique, and discriminative classification in the last step using the generalized Tikhonov regularization technique. Also, many existing emotional datasets suffer from the problem of data imbalanced distribution, which in turn increases the classification error and decreases system performance. In this paper, a new weighting method has also been proposed to deal with class imbalance, which is more efficient than existing weighting methods. The proposed method is evaluated on three standard emotional databases.