 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Big-Little Net: An Efficient Multi-Scale Feature Representation for Visual and Speech Recognition
Jul 10, 2018
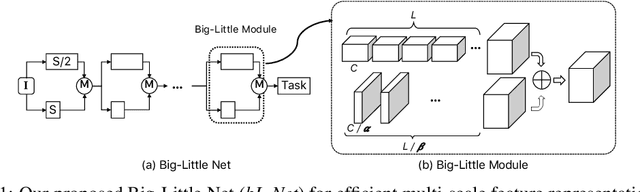
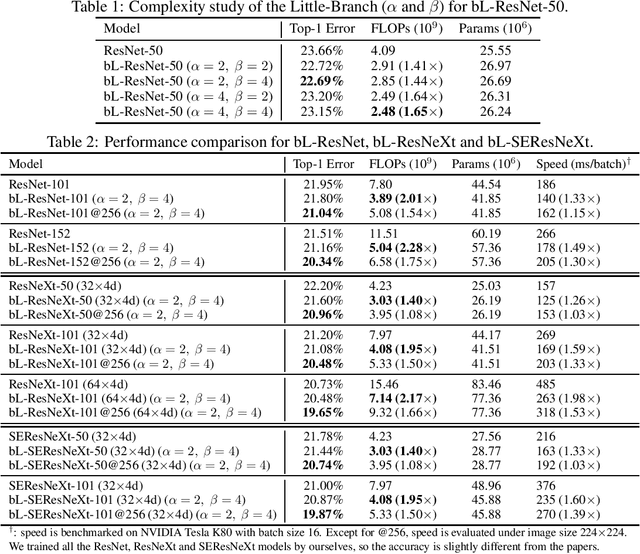
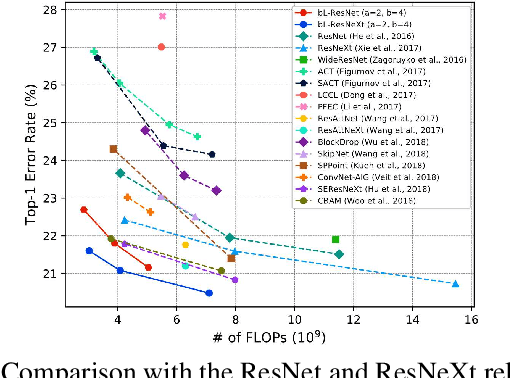
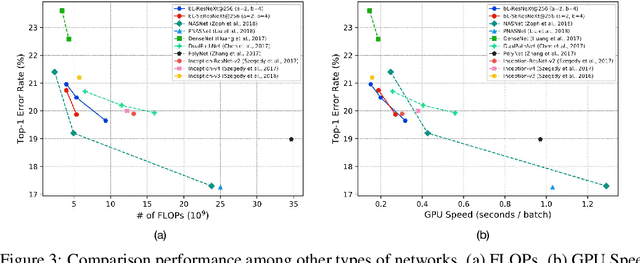
In this paper, we propose a novel Convolutional Neural Network (CNN) architecture for learning multi-scale feature representations with good tradeoffs between speed and accuracy. This is achieved by using a multi-branch network, which has different computational complexity at different branches. Through frequent merging of features from branches at distinct scales, our model obtains multi-scale features while using less computation. The proposed approach demonstrates improvement of model efficiency and performance on both object recognition and speech recognition tasks,using popular architectures including ResNet and ResNeXt. For object recognition, our approach reduces computation by 33% on object recognition while improving accuracy with 0.9%. Furthermore, our model surpasses state-of-the-art CNN acceleration approaches by a large margin in accuracy and FLOPs reduction. On the task of speech recognition, our proposed multi-scale CNNs save 30% FLOPs with slightly better word error rates, showing good generalization across domains.
Self Supervised Adversarial Domain Adaptation for Cross-Corpus and Cross-Language Speech Emotion Recognition
Apr 19, 2022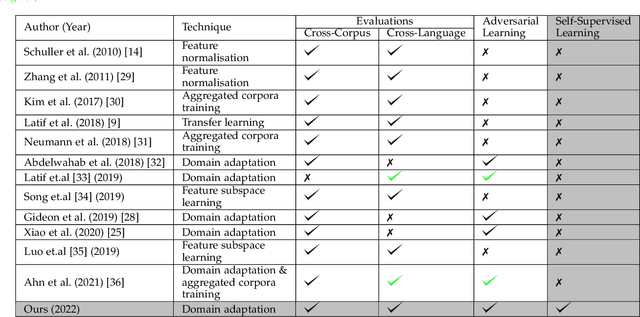
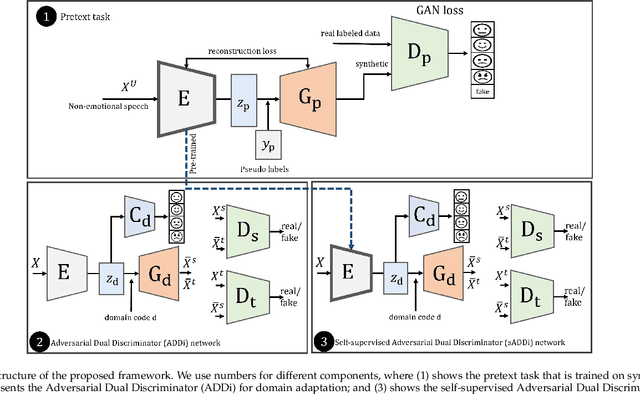
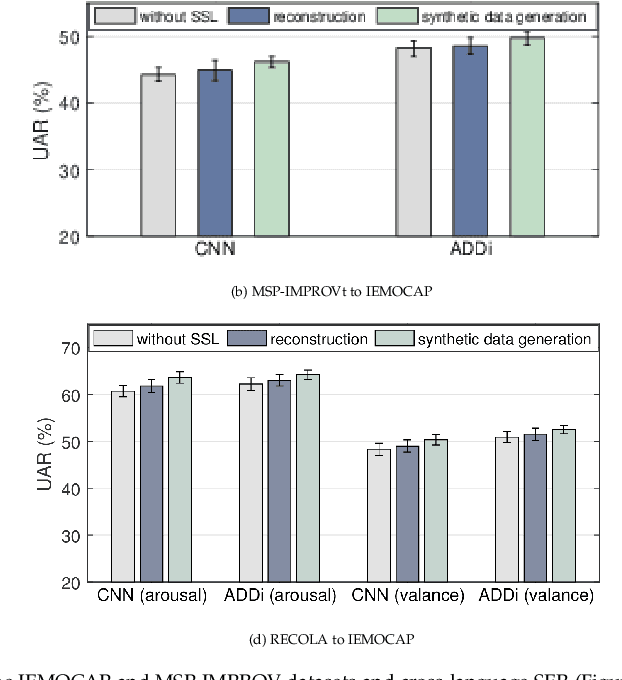
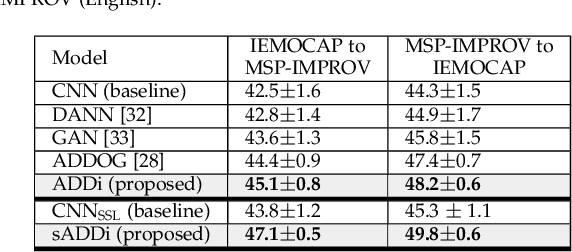
Despite the recent advancement in speech emotion recognition (SER) within a single corpus setting, the performance of these SER systems degrades significantly for cross-corpus and cross-language scenarios. The key reason is the lack of generalisation in SER systems towards unseen conditions, which causes them to perform poorly in cross-corpus and cross-language settings. Recent studies focus on utilising adversarial methods to learn domain generalised representation for improving cross-corpus and cross-language SER to address this issue. However, many of these methods only focus on cross-corpus SER without addressing the cross-language SER performance degradation due to a larger domain gap between source and target language data. This contribution proposes an adversarial dual discriminator (ADDi) network that uses the three-players adversarial game to learn generalised representations without requiring any target data labels. We also introduce a self-supervised ADDi (sADDi) network that utilises self-supervised pre-training with unlabelled data. We propose synthetic data generation as a pretext task in sADDi, enabling the network to produce emotionally discriminative and domain invariant representations and providing complementary synthetic data to augment the system. The proposed model is rigorously evaluated using five publicly available datasets in three languages and compared with multiple studies on cross-corpus and cross-language SER. Experimental results demonstrate that the proposed model achieves improved performance compared to the state-of-the-art methods.
ContextNet: Improving Convolutional Neural Networks for Automatic Speech Recognition with Global Context
May 07, 2020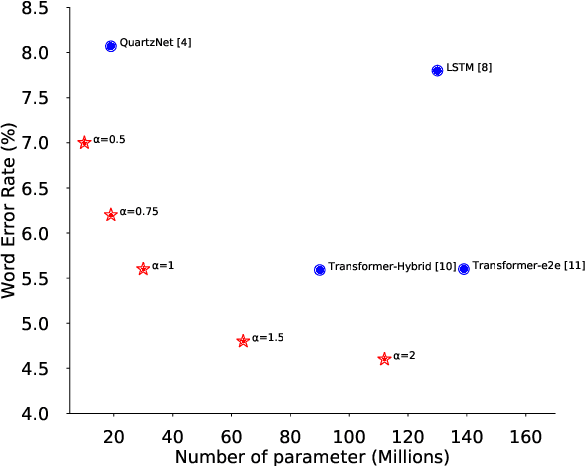
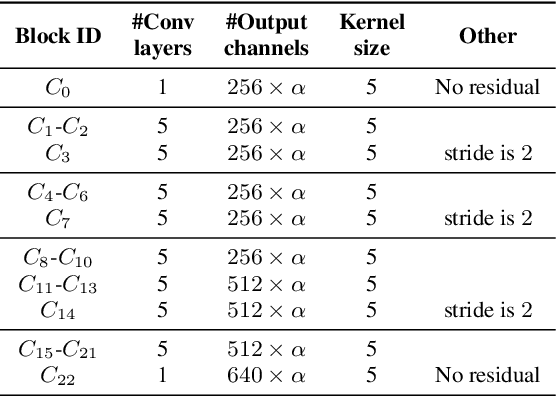
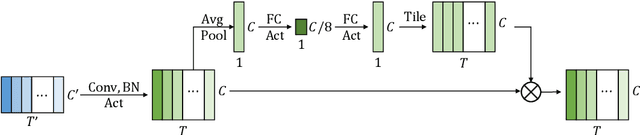
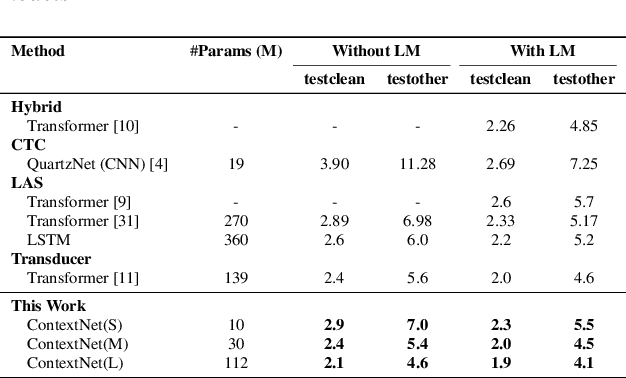
Convolutional neural networks (CNN) have shown promising results for end-to-end speech recognition, albeit still behind other state-of-the-art methods in performance. In this paper, we study how to bridge this gap and go beyond with a novel CNN-RNN-transducer architecture, which we call ContextNet. ContextNet features a fully convolutional encoder that incorporates global context information into convolution layers by adding squeeze-and-excitation modules. In addition, we propose a simple scaling method that scales the widths of ContextNet that achieves good trade-off between computation and accuracy. We demonstrate that on the widely used LibriSpeech benchmark, ContextNet achieves a word error rate (WER) of 2.1\%/4.6\% without external language model (LM), 1.9\%/4.1\% with LM and 2.9\%/7.0\% with only 10M parameters on the clean/noisy LibriSpeech test sets. This compares to the previous best published system of 2.0\%/4.6\% with LM and 3.9\%/11.3\% with 20M parameters. The superiority of the proposed ContextNet model is also verified on a much larger internal dataset.
An Investigation of End-to-End Multichannel Speech Recognition for Reverberant and Mismatch Conditions
Apr 28, 2019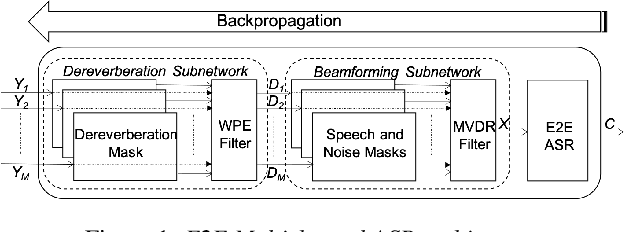
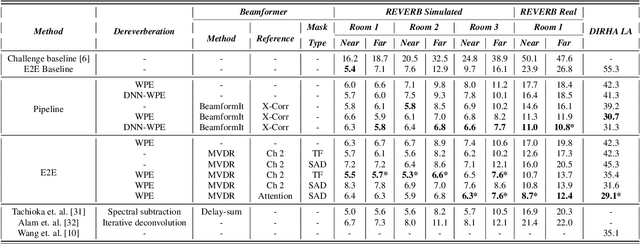
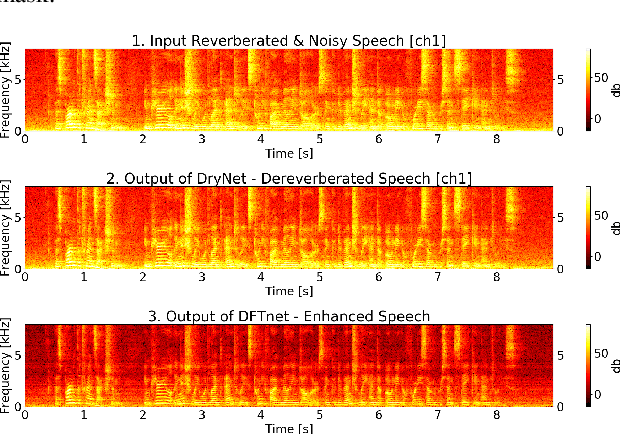
Sequence-to-sequence (S2S) modeling is becoming a popular paradigm for automatic speech recognition (ASR) because of its ability to jointly optimize all the conventional ASR components in an end-to-end (E2E) fashion. This report investigates the ability of E2E ASR from standard close-talk to far-field applications by encompassing entire multichannel speech enhancement and ASR components within the S2S model. There have been previous studies on jointly optimizing neural beamforming alongside E2E ASR for denoising. It is clear from both recent challenge outcomes and successful products that far-field systems would be incomplete without solving both denoising and dereverberation simultaneously. This report uses a recently developed architecture for far-field ASR by composing neural extensions of dereverberation and beamforming modules with the S2S ASR module as a single differentiable neural network and also clearly defining the role of each subnetwork. The original implementation of this architecture was successfully applied to the noisy speech recognition task (CHiME-4), while we applied this implementation to noisy reverberant tasks (DIRHA and REVERB). Our investigation shows that the method achieves better performance than conventional pipeline methods on the DIRHA English dataset and comparable performance on the REVERB dataset. It also has additional advantages of being neither iterative nor requiring parallel noisy and clean speech data.
Data Augmentation for Training Dialog Models Robust to Speech Recognition Errors
Jun 10, 2020
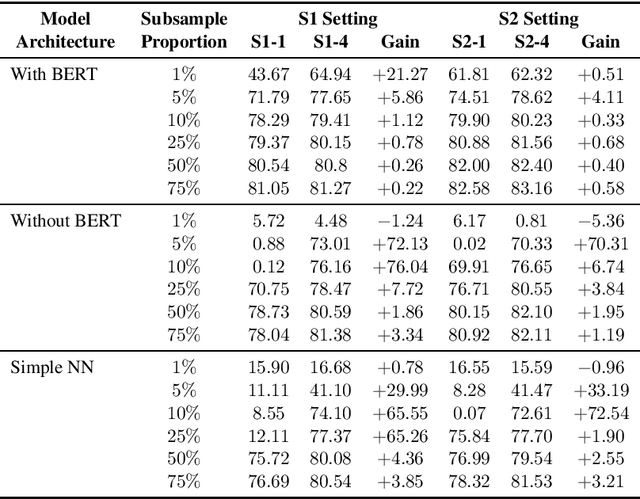
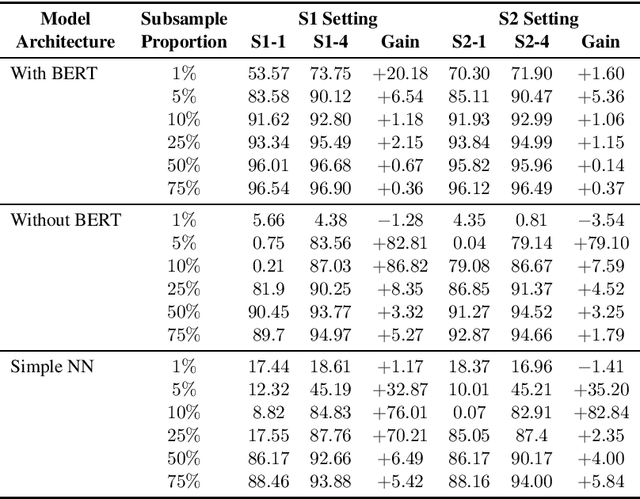
Speech-based virtual assistants, such as Amazon Alexa, Google assistant, and Apple Siri, typically convert users' audio signals to text data through automatic speech recognition (ASR) and feed the text to downstream dialog models for natural language understanding and response generation. The ASR output is error-prone; however, the downstream dialog models are often trained on error-free text data, making them sensitive to ASR errors during inference time. To bridge the gap and make dialog models more robust to ASR errors, we leverage an ASR error simulator to inject noise into the error-free text data, and subsequently train the dialog models with the augmented data. Compared to other approaches for handling ASR errors, such as using ASR lattice or end-to-end methods, our data augmentation approach does not require any modification to the ASR or downstream dialog models; our approach also does not introduce any additional latency during inference time. We perform extensive experiments on benchmark data and show that our approach improves the performance of downstream dialog models in the presence of ASR errors, and it is particularly effective in the low-resource situations where there are constraints on model size or the training data is scarce.
Multiple-hypothesis RNN-T Loss for Unsupervised Fine-tuning and Self-training of Neural Transducer
Jul 29, 2022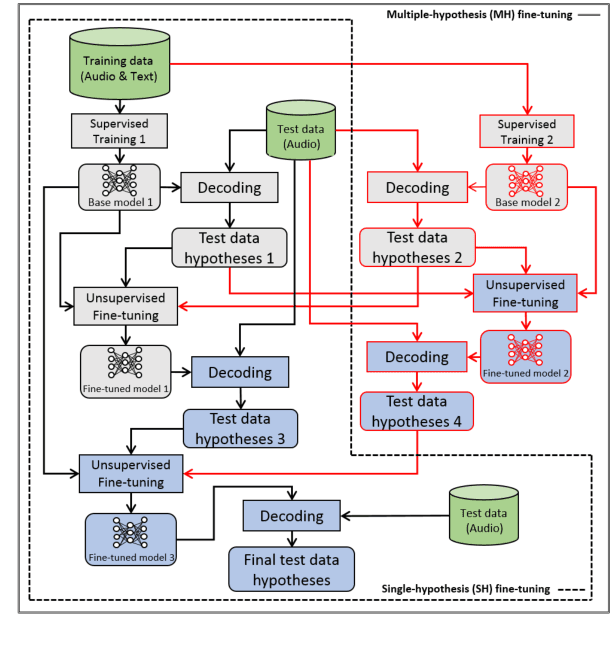
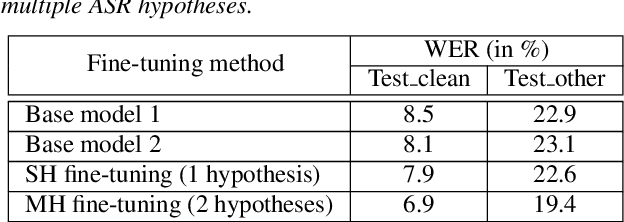
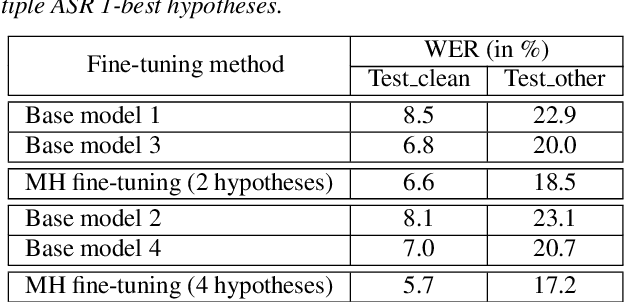
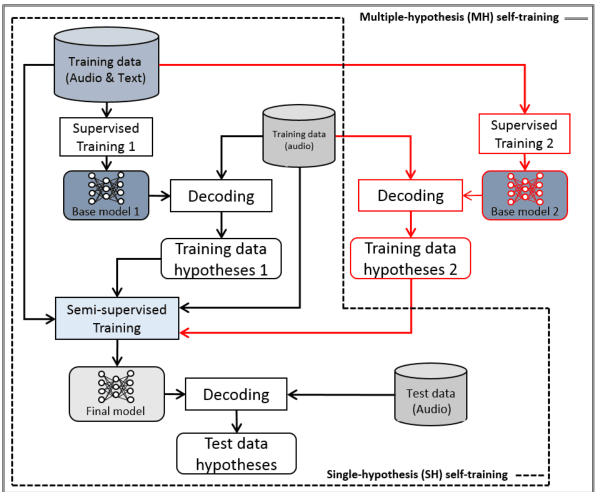
This paper proposes a new approach to perform unsupervised fine-tuning and self-training using unlabeled speech data for recurrent neural network (RNN)-Transducer (RNN-T) end-to-end (E2E) automatic speech recognition (ASR) systems. Conventional systems perform fine-tuning/self-training using ASR hypothesis as the targets when using unlabeled audio data and are susceptible to the ASR performance of the base model. Here in order to alleviate the influence of ASR errors while using unlabeled data, we propose a multiple-hypothesis RNN-T loss that incorporates multiple ASR 1-best hypotheses into the loss function. For the fine-tuning task, ASR experiments on Librispeech show that the multiple-hypothesis approach achieves a relative reduction of 14.2% word error rate (WER) when compared to the single-hypothesis approach, on the test_other set. For the self-training task, ASR models are trained using supervised data from Wall Street Journal (WSJ), Aurora-4 along with CHiME-4 real noisy data as unlabeled data. The multiple-hypothesis approach yields a relative reduction of 3.3% WER on the CHiME-4's single-channel real noisy evaluation set when compared with the single-hypothesis approach.
Comparison and Analysis of New Curriculum Criteria for End-to-End ASR
Aug 10, 2022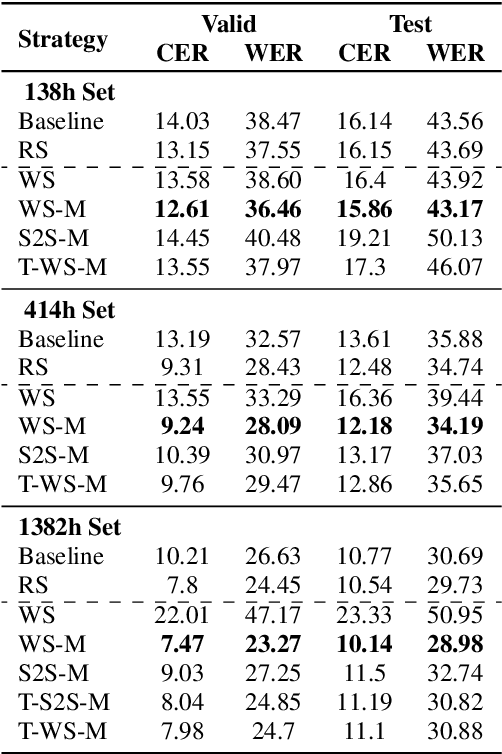
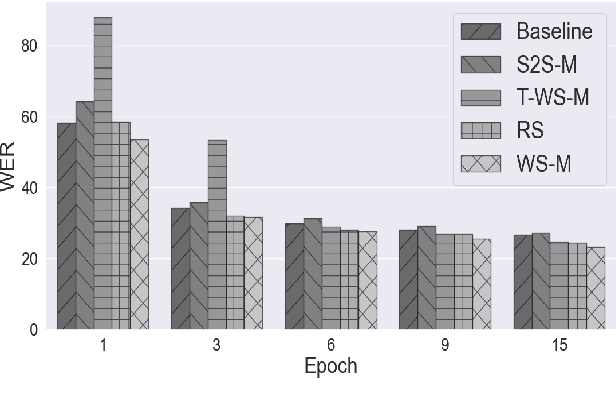
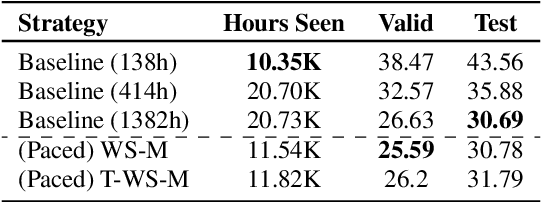
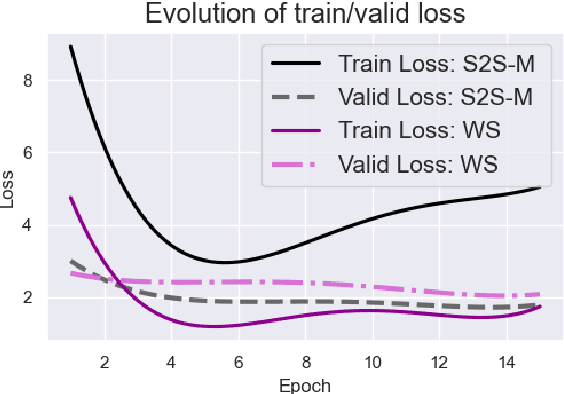
It is common knowledge that the quantity and quality of the training data play a significant role in the creation of a good machine learning model. In this paper, we take it one step further and demonstrate that the way the training examples are arranged is also of crucial importance. Curriculum Learning is built on the observation that organized and structured assimilation of knowledge has the ability to enable faster training and better comprehension. When humans learn to speak, they first try to utter basic phones and then gradually move towards more complex structures such as words and sentences. This methodology is known as Curriculum Learning, and we employ it in the context of Automatic Speech Recognition. We hypothesize that end-to-end models can achieve better performance when provided with an organized training set consisting of examples that exhibit an increasing level of difficulty (i.e. a curriculum). To impose structure on the training set and to define the notion of an easy example, we explored multiple scoring functions that either use feedback from an external neural network or incorporate feedback from the model itself. Empirical results show that with different curriculums we can balance the training times and the network's performance.
A Comparative Study of Data Augmentation Techniques for Deep Learning Based Emotion Recognition
Nov 09, 2022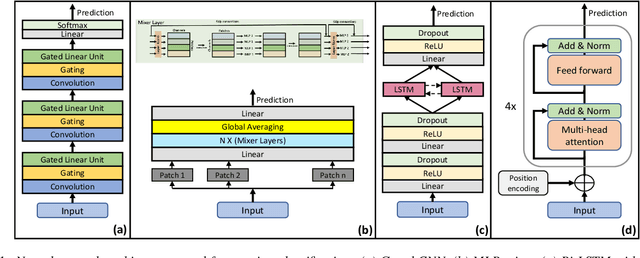
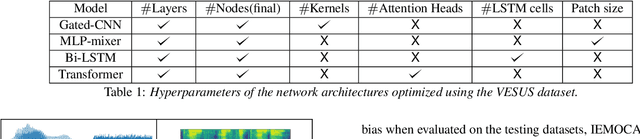
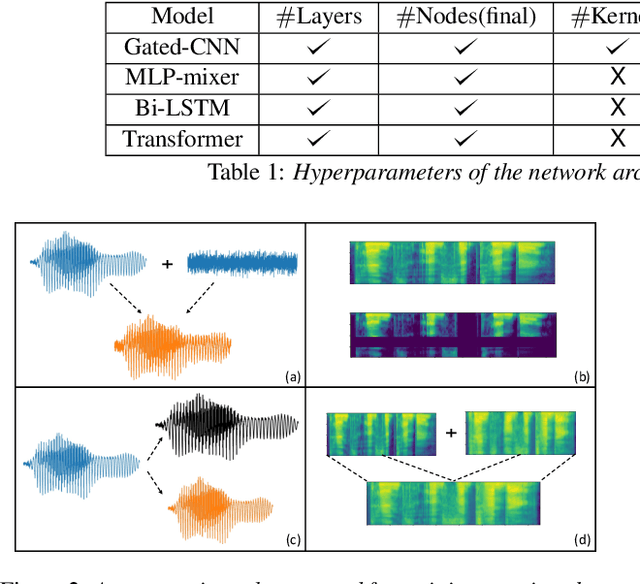
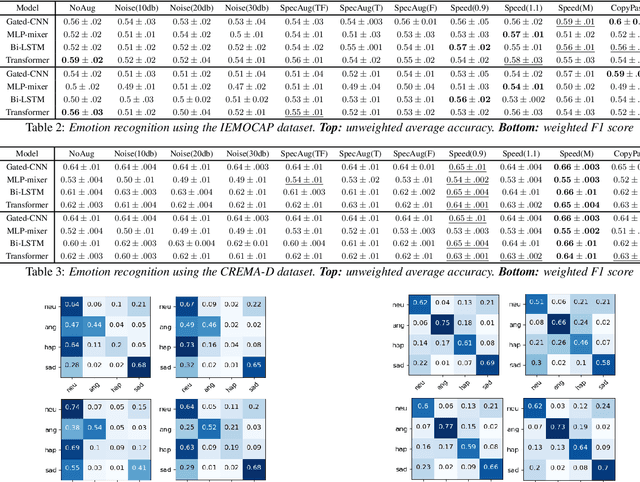
Automated emotion recognition in speech is a long-standing problem. While early work on emotion recognition relied on hand-crafted features and simple classifiers, the field has now embraced end-to-end feature learning and classification using deep neural networks. In parallel to these models, researchers have proposed several data augmentation techniques to increase the size and variability of existing labeled datasets. Despite many seminal contributions in the field, we still have a poor understanding of the interplay between the network architecture and the choice of data augmentation. Moreover, only a handful of studies demonstrate the generalizability of a particular model across multiple datasets, which is a prerequisite for robust real-world performance. In this paper, we conduct a comprehensive evaluation of popular deep learning approaches for emotion recognition. To eliminate bias, we fix the model architectures and optimization hyperparameters using the VESUS dataset and then use repeated 5-fold cross validation to evaluate the performance on the IEMOCAP and CREMA-D datasets. Our results demonstrate that long-range dependencies in the speech signal are critical for emotion recognition and that speed/rate augmentation offers the most robust performance gain across models.
VAIS ASR: Building a conversational speech recognition system using language model combination
Oct 12, 2019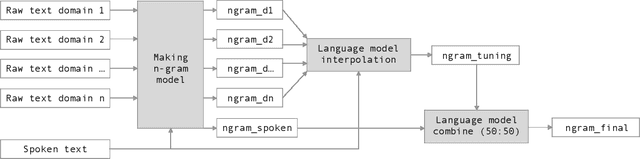
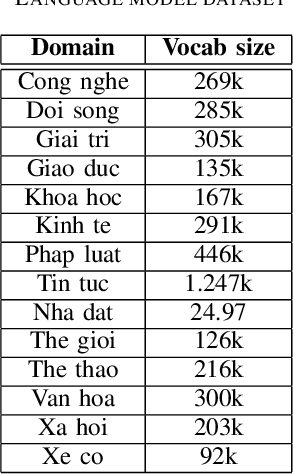
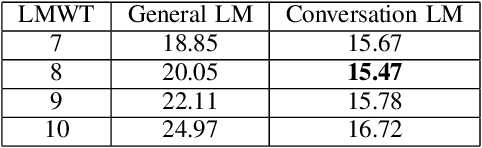
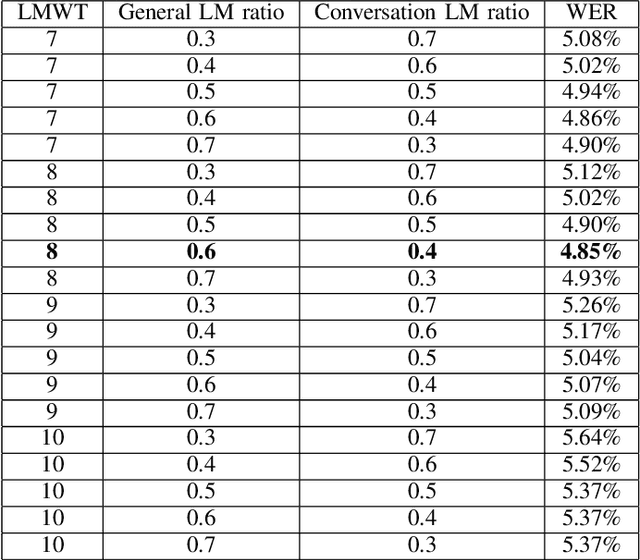
Automatic Speech Recognition (ASR) systems have been evolving quickly and reaching human parity in certain cases. The systems usually perform pretty well on reading style and clean speech, however, most of the available systems suffer from situation where the speaking style is conversation and in noisy environments. It is not straight-forward to tackle such problems due to difficulties in data collection for both speech and text. In this paper, we attempt to mitigate the problems using language models combination techniques that allows us to utilize both large amount of writing style text and small number of conversation text data. Evaluation on the VLSP 2019 ASR challenges showed that our system achieved 4.85% WER on the VLSP 2018 and 15.09% WER on the VLSP 2019 data sets.
Character-Aware Attention-Based End-to-End Speech Recognition
Jan 06, 2020
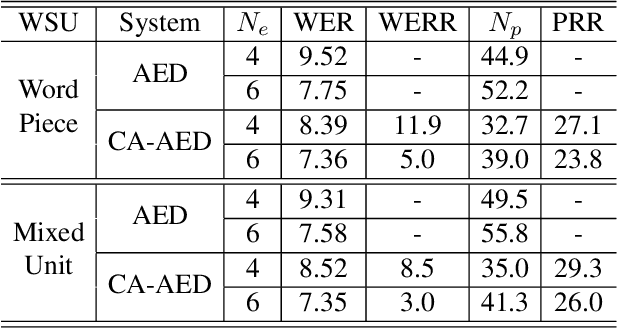
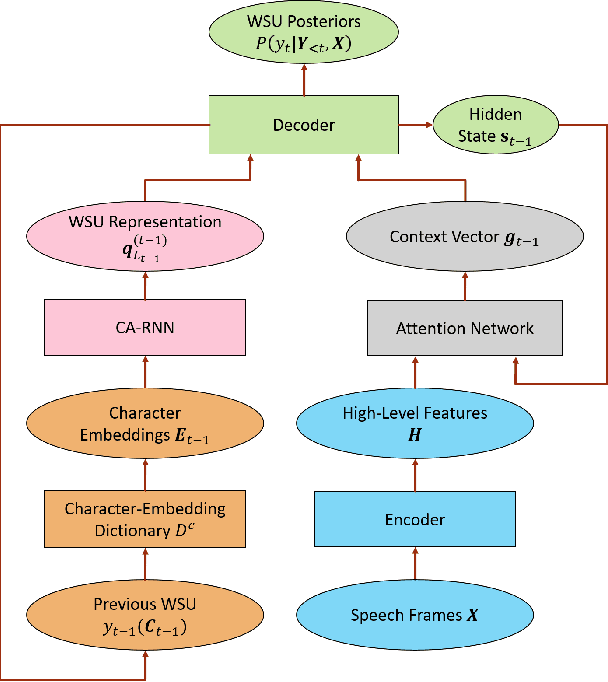
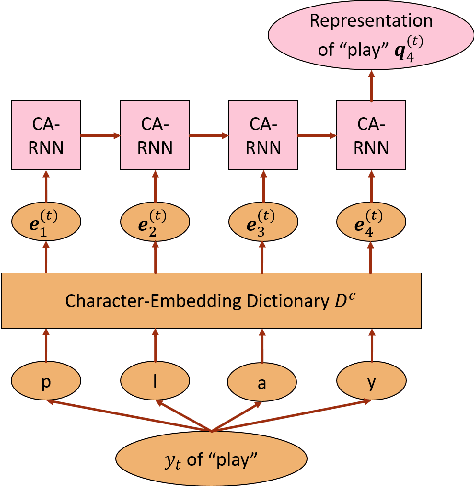
Predicting words and subword units (WSUs) as the output has shown to be effective for the attention-based encoder-decoder (AED) model in end-to-end speech recognition. However, as one input to the decoder recurrent neural network (RNN), each WSU embedding is learned independently through context and acoustic information in a purely data-driven fashion. Little effort has been made to explicitly model the morphological relationships among WSUs. In this work, we propose a novel character-aware (CA) AED model in which each WSU embedding is computed by summarizing the embeddings of its constituent characters using a CA-RNN. This WSU-independent CA-RNN is jointly trained with the encoder, the decoder and the attention network of a conventional AED to predict WSUs. With CA-AED, the embeddings of morphologically similar WSUs are naturally and directly correlated through the CA-RNN in addition to the semantic and acoustic relations modeled by a traditional AED. Moreover, CA-AED significantly reduces the model parameters in a traditional AED by replacing the large pool of WSU embeddings with a much smaller set of character embeddings. On a 3400 hours Microsoft Cortana dataset, CA-AED achieves up to 11.9% relative WER improvement over a strong AED baseline with 27.1% fewer model parameters.
* 7 pages, 3 figures, ASRU 2019