 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpertEdit: Learning Skill-Aware Motion Editing from Expert Videos
Apr 12, 2026Visual feedback is critical for motor skill acquisition in sports and rehabilitation, and psychological studies show that observing near-perfect versions of one's own performance accelerates learning more effectively than watching expert demonstrations alone. We propose to enable such personalized feedback by automatically editing a person's motion to reflect higher skill. Existing motion editing approaches are poorly suited for this setting because they assume paired input-output data -- rare and expensive to curate for skill-driven tasks -- and explicit edit guidance at inference. We introduce ExpertEdit, a framework for skill-driven motion editing trained exclusively on unpaired expert video demonstrations. ExpertEdit learns an expert motion prior with a masked language modeling objective that infills masked motion spans with expert-level refinements. At inference, novice motion is masked at skill-critical moments and projected into the learned expert manifold, producing localized skill improvements without paired supervision or manual edit guidance. Across eight diverse techniques and three sports from Ego-Exo4D and Karate Kyokushin, ExpertEdit outperforms state-of-the-art supervised motion editing methods on multiple metrics of motion realism and expert quality. Project page: https://vision.cs.utexas.edu/projects/expert_edit/ .
Learning Activity View-invariance Under Extreme Viewpoint Changes via Curriculum Knowledge Distillation
Apr 07, 2025
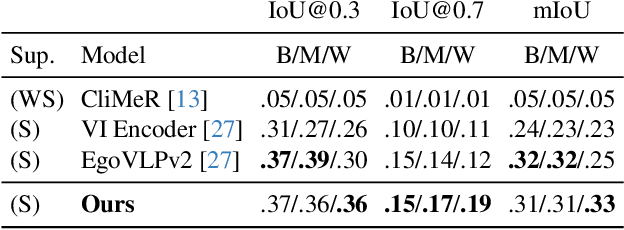

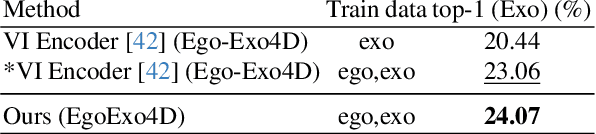
Traditional methods for view-invariant learning from video rely on controlled multi-view settings with minimal scene clutter. However, they struggle with in-the-wild videos that exhibit extreme viewpoint differences and share little visual content. We introduce a method for learning rich video representations in the presence of such severe view-occlusions. We first define a geometry-based metric that ranks views at a fine-grained temporal scale by their likely occlusion level. Then, using those rankings, we formulate a knowledge distillation objective that preserves action-centric semantics with a novel curriculum learning procedure that pairs incrementally more challenging views over time, thereby allowing smooth adaptation to extreme viewpoint differences. We evaluate our approach on two tasks, outperforming SOTA models on both temporal keystep grounding and fine-grained keystep recognition benchmarks - particularly on views that exhibit severe occlusion.
ActiveRIR: Active Audio-Visual Exploration for Acoustic Environment Modeling
Apr 24, 2024



An environment acoustic model represents how sound is transformed by the physical characteristics of an indoor environment, for any given source/receiver location. Traditional methods for constructing acoustic models involve expensive and time-consuming collection of large quantities of acoustic data at dense spatial locations in the space, or rely on privileged knowledge of scene geometry to intelligently select acoustic data sampling locations. We propose active acoustic sampling, a new task for efficiently building an environment acoustic model of an unmapped environment in which a mobile agent equipped with visual and acoustic sensors jointly constructs the environment acoustic model and the occupancy map on-the-fly. We introduce ActiveRIR, a reinforcement learning (RL) policy that leverages information from audio-visual sensor streams to guide agent navigation and determine optimal acoustic data sampling positions, yielding a high quality acoustic model of the environment from a minimal set of acoustic samples. We train our policy with a novel RL reward based on information gain in the environment acoustic model. Evaluating on diverse unseen indoor environments from a state-of-the-art acoustic simulation platform, ActiveRIR outperforms an array of methods--both traditional navigation agents based on spatial novelty and visual exploration as well as existing state-of-the-art methods.
Ego-Exo4D: Understanding Skilled Human Activity from First- and Third-Person Perspectives
Nov 30, 2023



We present Ego-Exo4D, a diverse, large-scale multimodal multiview video dataset and benchmark challenge. Ego-Exo4D centers around simultaneously-captured egocentric and exocentric video of skilled human activities (e.g., sports, music, dance, bike repair). More than 800 participants from 13 cities worldwide performed these activities in 131 different natural scene contexts, yielding long-form captures from 1 to 42 minutes each and 1,422 hours of video combined. The multimodal nature of the dataset is unprecedented: the video is accompanied by multichannel audio, eye gaze, 3D point clouds, camera poses, IMU, and multiple paired language descriptions -- including a novel "expert commentary" done by coaches and teachers and tailored to the skilled-activity domain. To push the frontier of first-person video understanding of skilled human activity, we also present a suite of benchmark tasks and their annotations, including fine-grained activity understanding, proficiency estimation, cross-view translation, and 3D hand/body pose. All resources will be open sourced to fuel new research in the community.
Self-Supervised Visual Acoustic Matching
Jul 27, 2023



Acoustic matching aims to re-synthesize an audio clip to sound as if it were recorded in a target acoustic environment. Existing methods assume access to paired training data, where the audio is observed in both source and target environments, but this limits the diversity of training data or requires the use of simulated data or heuristics to create paired samples. We propose a self-supervised approach to visual acoustic matching where training samples include only the target scene image and audio -- without acoustically mismatched source audio for reference. Our approach jointly learns to disentangle room acoustics and re-synthesize audio into the target environment, via a conditional GAN framework and a novel metric that quantifies the level of residual acoustic information in the de-biased audio. Training with either in-the-wild web data or simulated data, we demonstrate it outperforms the state-of-the-art on multiple challenging datasets and a wide variety of real-world audio and environments.
A Comparative Study of Data Augmentation Techniques for Deep Learning Based Emotion Recognition
Nov 09, 2022



Automated emotion recognition in speech is a long-standing problem. While early work on emotion recognition relied on hand-crafted features and simple classifiers, the field has now embraced end-to-end feature learning and classification using deep neural networks. In parallel to these models, researchers have proposed several data augmentation techniques to increase the size and variability of existing labeled datasets. Despite many seminal contributions in the field, we still have a poor understanding of the interplay between the network architecture and the choice of data augmentation. Moreover, only a handful of studies demonstrate the generalizability of a particular model across multiple datasets, which is a prerequisite for robust real-world performance. In this paper, we conduct a comprehensive evaluation of popular deep learning approaches for emotion recognition. To eliminate bias, we fix the model architectures and optimization hyperparameters using the VESUS dataset and then use repeated 5-fold cross validation to evaluate the performance on the IEMOCAP and CREMA-D datasets. Our results demonstrate that long-range dependencies in the speech signal are critical for emotion recognition and that speed/rate augmentation offers the most robust performance gain across models.