 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Investigation of End-to-End Multichannel Speech Recognition for Reverberant and Mismatch Conditions
Paper and Code
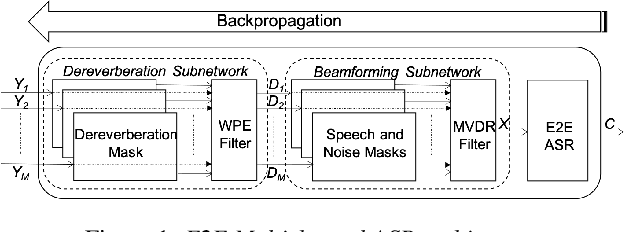
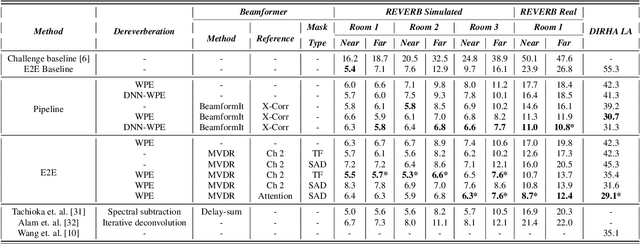
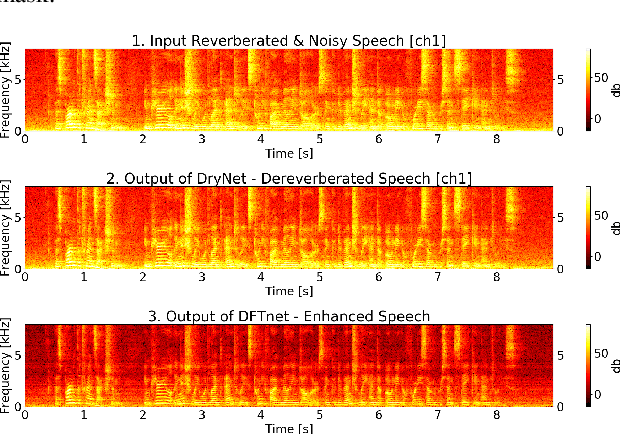
Sequence-to-sequence (S2S) modeling is becoming a popular paradigm for automatic speech recognition (ASR) because of its ability to jointly optimize all the conventional ASR components in an end-to-end (E2E) fashion. This report investigates the ability of E2E ASR from standard close-talk to far-field applications by encompassing entire multichannel speech enhancement and ASR components within the S2S model. There have been previous studies on jointly optimizing neural beamforming alongside E2E ASR for denoising. It is clear from both recent challenge outcomes and successful products that far-field systems would be incomplete without solving both denoising and dereverberation simultaneously. This report uses a recently developed architecture for far-field ASR by composing neural extensions of dereverberation and beamforming modules with the S2S ASR module as a single differentiable neural network and also clearly defining the role of each subnetwork. The original implementation of this architecture was successfully applied to the noisy speech recognition task (CHiME-4), while we applied this implementation to noisy reverberant tasks (DIRHA and REVERB). Our investigation shows that the method achieves better performance than conventional pipeline methods on the DIRHA English dataset and comparable performance on the REVERB dataset. It also has additional advantages of being neither iterative nor requiring parallel noisy and clean speech data.