 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-Space Knowledge Distillation with Key-Query Matching for Large Language Models with Vocabulary Mismatch
Mar 23, 2026Large language models (LLMs) achieve state-of-the-art (SOTA) performance across language tasks, but are costly to deploy due to their size and resource demands. Knowledge Distillation (KD) addresses this by training smaller Student models to mimic larger Teacher models, improving efficiency without significant performance loss. Dual-Space Knowledge Distillation with Cross-Model Attention (DSKD-CMA) has emerged as a SOTA method for KD between LLMs with distinct tokenizers, yet its internal workings remain largely opaque. In this work, we systematically analyse the attention mechanism of DSKD-CMA through manual token alignment probing and heatmap visualisations, revealing both strengths and limitations. Building on this, we introduce a novel method, DSKD-CMA-GA, based on Generative Adversarial (GA) learning, to address the mismatched distributions between the keys and queries computed from distinct models. Experiments show modest but consistent ROUGE-L gains in text generation quality, particularly on out-of-distribution data (+0.37 on average), narrowing the gap between cross- and same-tokenizer KD.
Effectiveness of Chain-of-Thought in Distilling Reasoning Capability from Large Language Models
Nov 07, 2025Chain-of-Thought (CoT) prompting is a widely used method to improve the reasoning capability of Large Language Models (LLMs). More recently, CoT has been leveraged in Knowledge Distillation (KD) to transfer reasoning capability from a larger LLM to a smaller one. This paper examines the role of CoT in distilling the reasoning capability from larger LLMs to smaller LLMs using white-box KD, analysing its effectiveness in improving the performance of the distilled models for various natural language reasoning and understanding tasks. We conduct white-box KD experiments using LLMs from the Qwen and Llama2 families, employing CoT data from the CoT-Collection dataset. The distilled models are then evaluated on natural language reasoning and understanding tasks from the BIG-Bench-Hard (BBH) benchmark, which presents complex challenges for smaller LLMs. Experimental results demonstrate the role of CoT in improving white-box KD effectiveness, enabling the distilled models to achieve better average performance in natural language reasoning and understanding tasks from BBH.
WHISMA: A Speech-LLM to Perform Zero-shot Spoken Language Understanding
Aug 29, 2024



Speech large language models (speech-LLMs) integrate speech and text-based foundation models to provide a unified framework for handling a wide range of downstream tasks. In this paper, we introduce WHISMA, a speech-LLM tailored for spoken language understanding (SLU) that demonstrates robust performance in various zero-shot settings. WHISMA combines the speech encoder from Whisper with the Llama-3 LLM, and is fine-tuned in a parameter-efficient manner on a comprehensive collection of SLU-related datasets. Our experiments show that WHISMA significantly improves the zero-shot slot filling performance on the SLURP benchmark, achieving a relative gain of 26.6% compared to the current state-of-the-art model. Furthermore, to evaluate WHISMA's generalisation capabilities to unseen domains, we develop a new task-agnostic benchmark named SLU-GLUE. The evaluation results indicate that WHISMA outperforms an existing speech-LLM (Qwen-Audio) with a relative gain of 33.0%.
Improving Accented Speech Recognition using Data Augmentation based on Unsupervised Text-to-Speech Synthesis
Jul 04, 2024



This paper investigates the use of unsupervised text-to-speech synthesis (TTS) as a data augmentation method to improve accented speech recognition. TTS systems are trained with a small amount of accented speech training data and their pseudo-labels rather than manual transcriptions, and hence unsupervised. This approach enables the use of accented speech data without manual transcriptions to perform data augmentation for accented speech recognition. Synthetic accented speech data, generated from text prompts by using the TTS systems, are then combined with available non-accented speech data to train automatic speech recognition (ASR) systems. ASR experiments are performed in a self-supervised learning framework using a Wav2vec2.0 model which was pre-trained on large amount of unsupervised accented speech data. The accented speech data for training the unsupervised TTS are read speech, selected from L2-ARCTIC and British Isles corpora, while spontaneous conversational speech from the Edinburgh international accents of English corpus are used as the evaluation data. Experimental results show that Wav2vec2.0 models which are fine-tuned to downstream ASR task with synthetic accented speech data, generated by the unsupervised TTS, yield up to 6.1% relative word error rate reductions compared to a Wav2vec2.0 baseline which is fine-tuned with the non-accented speech data from Librispeech corpus.
Multiple-hypothesis RNN-T Loss for Unsupervised Fine-tuning and Self-training of Neural Transducer
Jul 29, 2022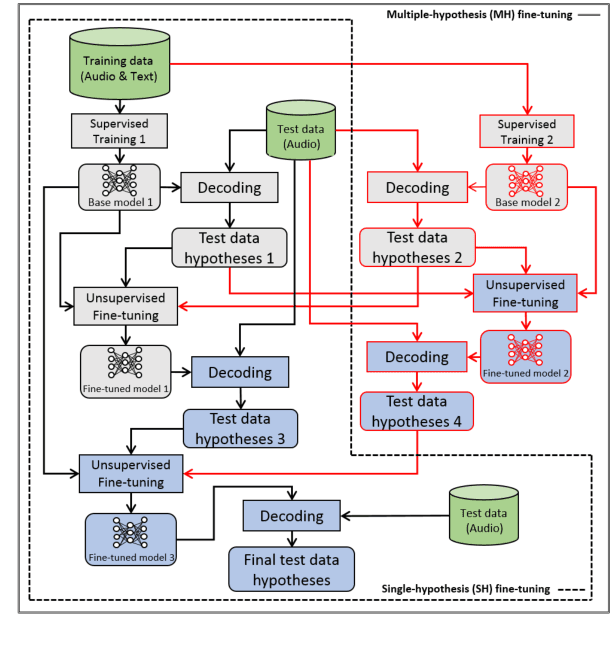
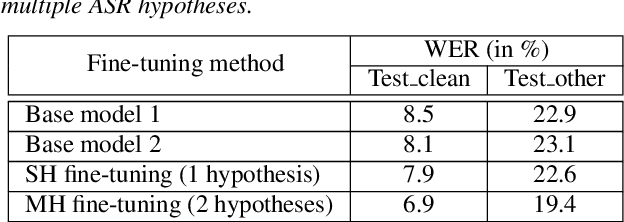
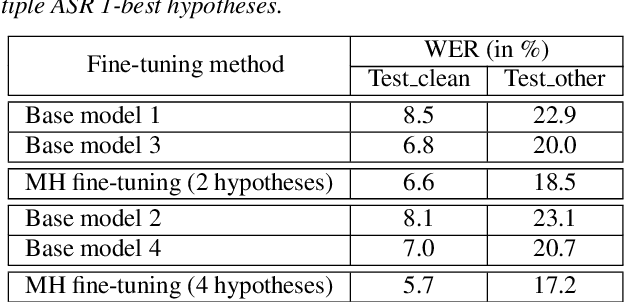
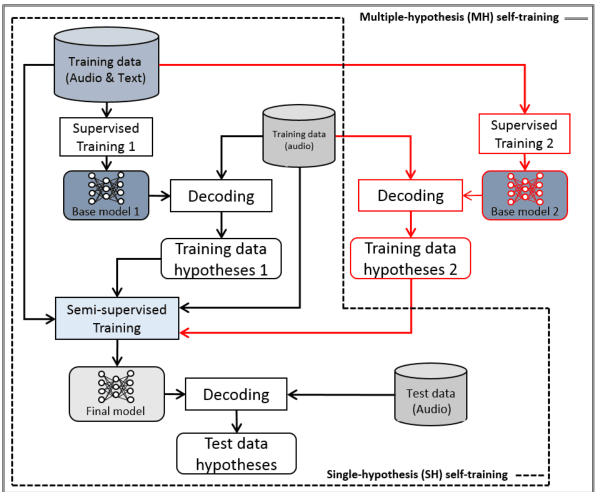
This paper proposes a new approach to perform unsupervised fine-tuning and self-training using unlabeled speech data for recurrent neural network (RNN)-Transducer (RNN-T) end-to-end (E2E) automatic speech recognition (ASR) systems. Conventional systems perform fine-tuning/self-training using ASR hypothesis as the targets when using unlabeled audio data and are susceptible to the ASR performance of the base model. Here in order to alleviate the influence of ASR errors while using unlabeled data, we propose a multiple-hypothesis RNN-T loss that incorporates multiple ASR 1-best hypotheses into the loss function. For the fine-tuning task, ASR experiments on Librispeech show that the multiple-hypothesis approach achieves a relative reduction of 14.2% word error rate (WER) when compared to the single-hypothesis approach, on the test_other set. For the self-training task, ASR models are trained using supervised data from Wall Street Journal (WSJ), Aurora-4 along with CHiME-4 real noisy data as unlabeled data. The multiple-hypothesis approach yields a relative reduction of 3.3% WER on the CHiME-4's single-channel real noisy evaluation set when compared with the single-hypothesis approach.
Robust multi-sensor GLMB filter: An application to multi-target tracking with bearing-only sensors
Jun 01, 2021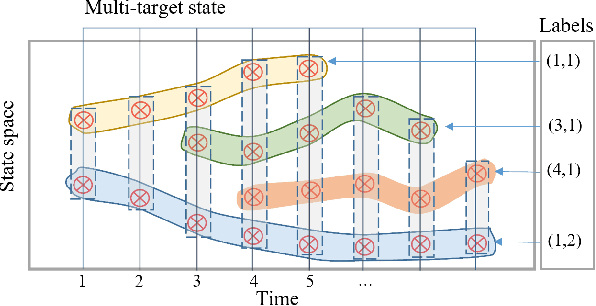

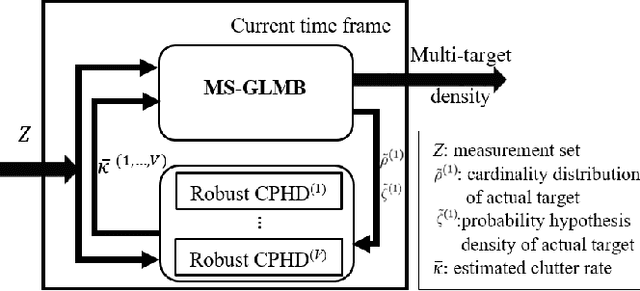

This paper proposes an efficient and robust algorithm to estimate target trajectories via multi-sensor bearing-only measurements with unknown target detection profiles and clutter rates. In particular, we propose to combine the multi-sensor Generalized Labeled Multi-Bernoulli (MS-GLMB) filter to estimate target trajectories and robust Cardinalized Probability Hypothesis Density (CPHD) filters to estimate the clutter rates. Experimental results show that the proposed robust filter exhibits near-optimal performance in the sense that it is comparable to the optimal MS-GLMB operating with the true clutter rate. More importantly, it outperforms other studied filters when the detection profile and clutter rate are unknown an time-variant. This is attributed to the ability of the robust filter to learn the background parameters on-the-fly.
Multiple-hypothesis CTC-based semi-supervised adaptation of end-to-end speech recognition
Mar 31, 2021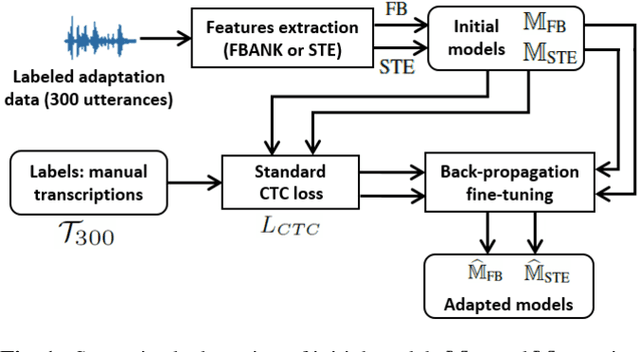

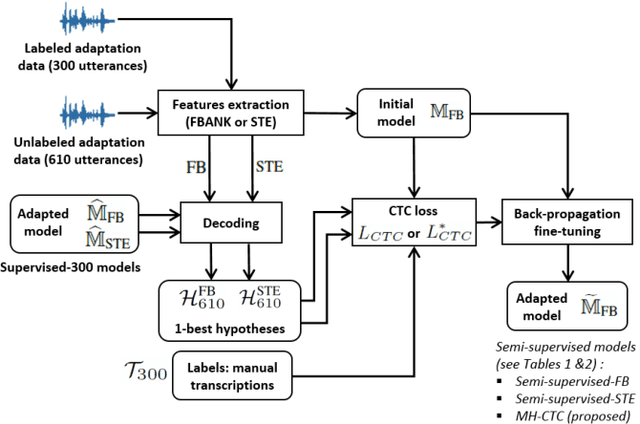
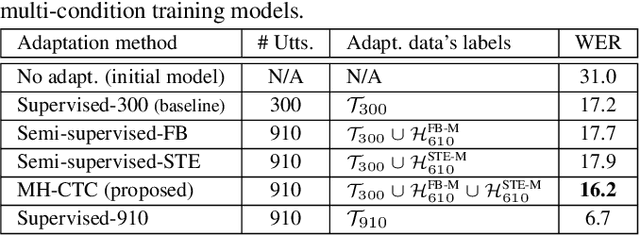
This paper proposes an adaptation method for end-to-end speech recognition. In this method, multiple automatic speech recognition (ASR) 1-best hypotheses are integrated in the computation of the connectionist temporal classification (CTC) loss function. The integration of multiple ASR hypotheses helps alleviating the impact of errors in the ASR hypotheses to the computation of the CTC loss when ASR hypotheses are used. When being applied in semi-supervised adaptation scenarios where part of the adaptation data do not have labels, the CTC loss of the proposed method is computed from different ASR 1-best hypotheses obtained by decoding the unlabeled adaptation data. Experiments are performed in clean and multi-condition training scenarios where the CTC-based end-to-end ASR systems are trained on Wall Street Journal (WSJ) clean training data and CHiME-4 multi-condition training data, respectively, and tested on Aurora-4 test data. The proposed adaptation method yields 6.6% and 5.8% relative word error rate (WER) reductions in clean and multi-condition training scenarios, respectively, compared to a baseline system which is adapted with part of the adaptation data having manual transcriptions using back-propagation fine-tuning.
Train your classifier first: Cascade Neural Networks Training from upper layers to lower layers
Feb 09, 2021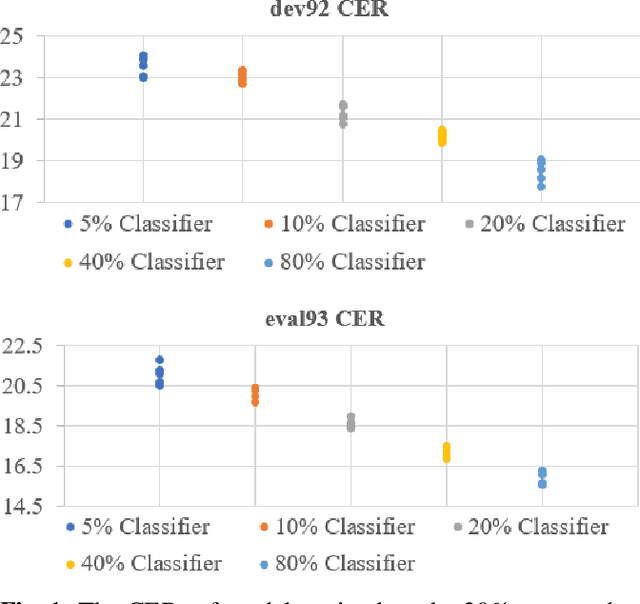
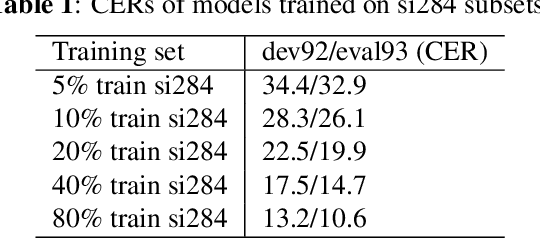
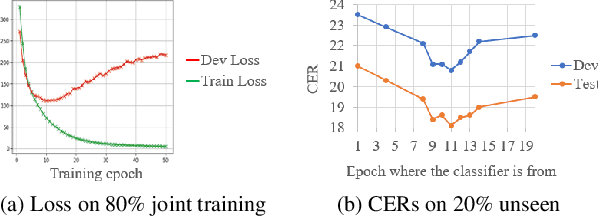
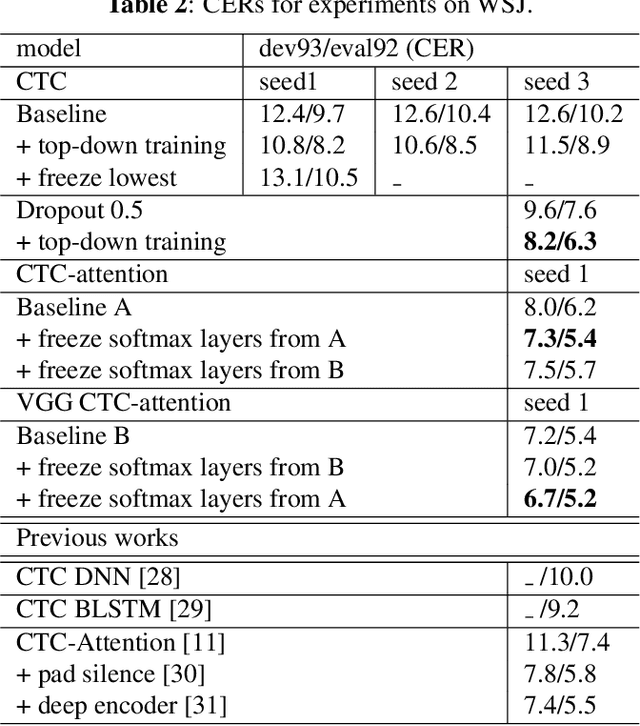
Although the lower layers of a deep neural network learn features which are transferable across datasets, these layers are not transferable within the same dataset. That is, in general, freezing the trained feature extractor (the lower layers) and retraining the classifier (the upper layers) on the same dataset leads to worse performance. In this paper, for the first time, we show that the frozen classifier is transferable within the same dataset. We develop a novel top-down training method which can be viewed as an algorithm for searching for high-quality classifiers. We tested this method on automatic speech recognition (ASR) tasks and language modelling tasks. The proposed method consistently improves recurrent neural network ASR models on Wall Street Journal, self-attention ASR models on Switchboard, and AWD-LSTM language models on WikiText-2.
End-to-End Speech Recognition with High-Frame-Rate Features Extraction
Jul 12, 2019
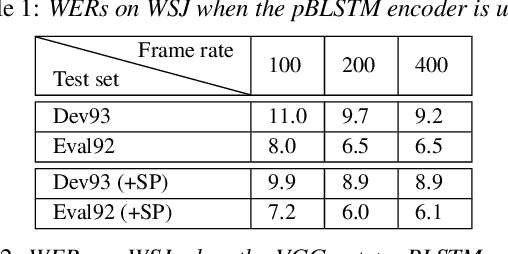
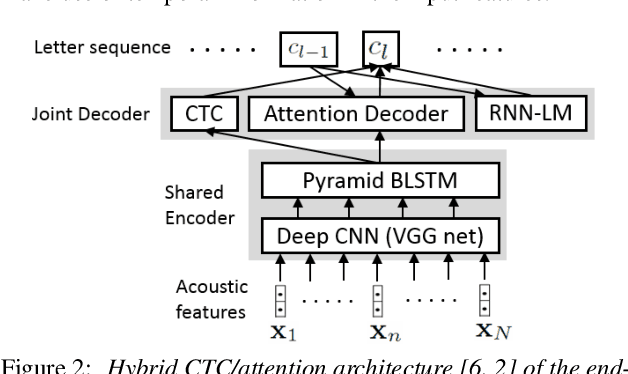
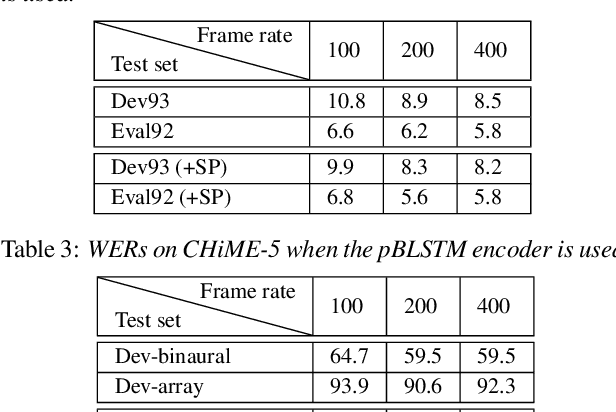
State-of-the-art end-to-end automatic speech recognition (ASR) extracts acoustic features from input speech signal every 10 ms which corresponds to a frame rate of 100 frames/second. In this report, we investigate the use of high-frame-rate features extraction in end-to-end ASR. High frame rates of 200 and 400 frames/second are used in the features extraction and provide additional information for end-to-end ASR. The effectiveness of high-frame-rate features extraction is evaluated independently and in combination with speed perturbation based data augmentation. Experiments performed on two speech corpora, Wall Street Journal (WSJ) and CHiME-5, show that using high-frame-rate features extraction yields improved performance for end-to-end ASR, both independently and in combination with speed perturbation. On WSJ corpus, the relative reduction of word error rate (WER) yielded by high-frame-rate features extraction independently and in combination with speed perturbation are up to 21.3% and 24.1%, respectively. On CHiME-5 corpus, the corresponding relative WER reductions are up to 2.8% and 7.9%, respectively, on the test data recorded by microphone arrays and up to 11.8% and 21.2%, respectively, on the test data recorded by binaural microphones.