 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegAug: CTC-Aligned Segmented Augmentation For Robust RNN-Transducer Based Speech Recognition
Feb 20, 2025RNN-Transducer (RNN-T) is a widely adopted architecture in speech recognition, integrating acoustic and language modeling in an end-to-end framework. However, the RNN-T predictor tends to over-rely on consecutive word dependencies in training data, leading to high deletion error rates, particularly with less common or out-of-domain phrases. Existing solutions, such as regularization and data augmentation, often compromise other aspects of performance. We propose SegAug, an alignment-based augmentation technique that generates contextually varied audio-text pairs with low sentence-level semantics. This method encourages the model to focus more on acoustic features while diversifying the learned textual patterns of its internal language model, thereby reducing deletion errors and enhancing overall performance. Evaluations on the LibriSpeech and Tedlium-v3 datasets demonstrate a relative WER reduction of up to 12.5% on small-scale and 6.9% on large-scale settings. Notably, most of the improvement stems from reduced deletion errors, with relative reductions of 45.4% and 18.5%, respectively. These results highlight SegAug's effectiveness in improving RNN-T's robustness, offering a promising solution for enhancing speech recognition performance across diverse and challenging scenarios.
ChunkFormer: Masked Chunking Conformer For Long-Form Speech Transcription
Feb 20, 2025



Deploying ASR models at an industrial scale poses significant challenges in hardware resource management, especially for long-form transcription tasks where audio may last for hours. Large Conformer models, despite their capabilities, are limited to processing only 15 minutes of audio on an 80GB GPU. Furthermore, variable input lengths worsen inefficiencies, as standard batching leads to excessive padding, increasing resource consumption and execution time. To address this, we introduce ChunkFormer, an efficient ASR model that uses chunk-wise processing with relative right context, enabling long audio transcriptions on low-memory GPUs. ChunkFormer handles up to 16 hours of audio on an 80GB GPU, 1.5x longer than the current state-of-the-art FastConformer, while also boosting long-form transcription performance with up to 7.7% absolute reduction on word error rate and maintaining accuracy on shorter tasks compared to Conformer. By eliminating the need for padding in standard batching, ChunkFormer's masked batching technique reduces execution time and memory usage by more than 3x in batch processing, substantially reducing costs for a wide range of ASR systems, particularly regarding GPU resources for models serving in real-world applications.
Zero-Shot Text-to-Speech from Continuous Text Streams
Oct 01, 2024



Existing zero-shot text-to-speech (TTS) systems are typically designed to process complete sentences and are constrained by the maximum duration for which they have been trained. However, in many streaming applications, texts arrive continuously in short chunks, necessitating instant responses from the system. We identify the essential capabilities required for chunk-level streaming and introduce LiveSpeech 2, a stream-aware model that supports infinitely long speech generation, text-audio stream synchronization, and seamless transitions between short speech chunks. To achieve these, we propose (1) adopting Mamba, a class of sequence modeling distinguished by linear-time decoding, which is augmented by cross-attention mechanisms for conditioning, (2) utilizing rotary positional embeddings in the computation of cross-attention, enabling the model to process an infinite text stream by sliding a window, and (3) decoding with semantic guidance, a technique that aligns speech with the transcript during inference with minimal overhead. Experimental results demonstrate that our models are competitive with state-of-the-art language model-based zero-shot TTS models, while also providing flexibility to support a wide range of streaming scenarios.
LiveSpeech: Low-Latency Zero-shot Text-to-Speech via Autoregressive Modeling of Audio Discrete Codes
Jun 05, 2024



Prior works have demonstrated zero-shot text-to-speech by using a generative language model on audio tokens obtained via a neural audio codec. It is still challenging, however, to adapt them to low-latency scenarios. In this paper, we present LiveSpeech - a fully autoregressive language model-based approach for zero-shot text-to-speech, enabling low-latency streaming of the output audio. To allow multiple token prediction within a single decoding step, we propose (1) using adaptive codebook loss weights that consider codebook contribution in each frame and focus on hard instances, and (2) grouping codebooks and processing groups in parallel. Experiments show our proposed models achieve competitive results to state-of-the-art baselines in terms of content accuracy, speaker similarity, audio quality, and inference speed while being suitable for low-latency streaming applications.
uaMix-MAE: Efficient Tuning of Pretrained Audio Transformers with Unsupervised Audio Mixtures
Mar 14, 2024Masked Autoencoders (MAEs) learn rich low-level representations from unlabeled data but require substantial labeled data to effectively adapt to downstream tasks. Conversely, Instance Discrimination (ID) emphasizes high-level semantics, offering a potential solution to alleviate annotation requirements in MAEs. Although combining these two approaches can address downstream tasks with limited labeled data, naively integrating ID into MAEs leads to extended training times and high computational costs. To address this challenge, we introduce uaMix-MAE, an efficient ID tuning strategy that leverages unsupervised audio mixtures. Utilizing contrastive tuning, uaMix-MAE aligns the representations of pretrained MAEs, thereby facilitating effective adaptation to task-specific semantics. To optimize the model with small amounts of unlabeled data, we propose an audio mixing technique that manipulates audio samples in both input and virtual label spaces. Experiments in low/few-shot settings demonstrate that \modelname achieves 4-6% accuracy improvements over various benchmarks when tuned with limited unlabeled data, such as AudioSet-20K. Code is available at https://github.com/PLAN-Lab/uamix-MAE
Learned Image Compression with Text Quality Enhancement
Feb 13, 2024Learned image compression has gained widespread popularity for their efficiency in achieving ultra-low bit-rates. Yet, images containing substantial textual content, particularly screen-content images (SCI), often suffers from text distortion at such compressed levels. To address this, we propose to minimize a novel text logit loss designed to quantify the disparity in text between the original and reconstructed images, thereby improving the perceptual quality of the reconstructed text. Through rigorous experimentation across diverse datasets and employing state-of-the-art algorithms, our findings reveal significant enhancements in the quality of reconstructed text upon integration of the proposed loss function with appropriate weighting. Notably, we achieve a Bjontegaard delta (BD) rate of -32.64% for Character Error Rate (CER) and -28.03% for Word Error Rate (WER) on average by applying the text logit loss for two screenshot datasets. Additionally, we present quantitative metrics tailored for evaluating text quality in image compression tasks. Our findings underscore the efficacy and potential applicability of our proposed text logit loss function across various text-aware image compression contexts.
Accelerating Diffusion-Based Text-to-Audio Generation with Consistency Distillation
Sep 19, 2023



Diffusion models power a vast majority of text-to-audio (TTA) generation methods. Unfortunately, these models suffer from slow inference speed due to iterative queries to the underlying denoising network, thus unsuitable for scenarios with inference time or computational constraints. This work modifies the recently proposed consistency distillation framework to train TTA models that require only a single neural network query. In addition to incorporating classifier-free guidance into the distillation process, we leverage the availability of generated audio during distillation training to fine-tune the consistency TTA model with novel loss functions in the audio space, such as the CLAP score. Our objective and subjective evaluation results on the AudioCaps dataset show that consistency models retain diffusion models' high generation quality and diversity while reducing the number of queries by a factor of 400.
Corrupting Data to Remove Deceptive Perturbation: Using Preprocessing Method to Improve System Robustness
Jan 05, 2022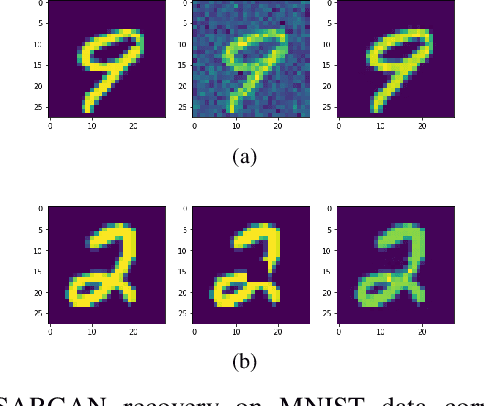
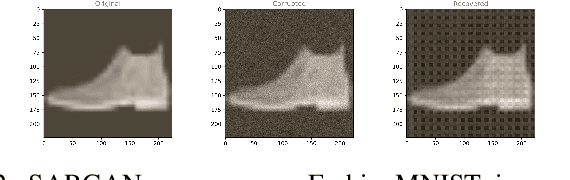


Although deep neural networks have achieved great performance on classification tasks, recent studies showed that well trained networks can be fooled by adding subtle noises. This paper introduces a new approach to improve neural network robustness by applying the recovery process on top of the naturally trained classifier. In this approach, images will be intentionally corrupted by some significant operator and then be recovered before passing through the classifiers. SARGAN -- an extension on Generative Adversarial Networks (GAN) is capable of denoising radar signals. This paper will show that SARGAN can also recover corrupted images by removing the adversarial effects. Our results show that this approach does improve the performance of naturally trained networks.
Augmented Contrastive Self-Supervised Learning for Audio Invariant Representations
Dec 21, 2021
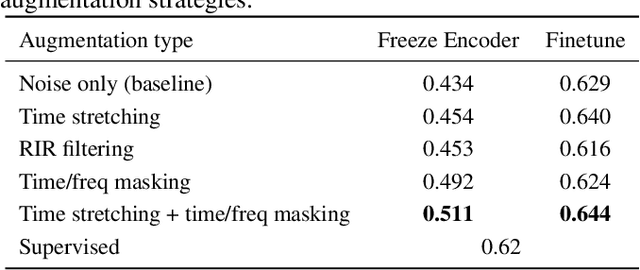
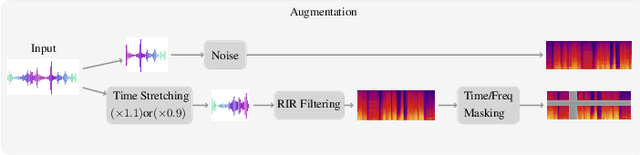
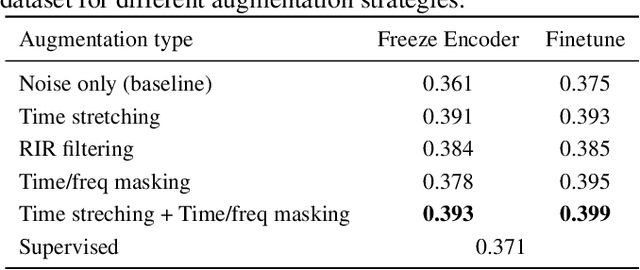
Improving generalization is a major challenge in audio classification due to labeled data scarcity. Self-supervised learning (SSL) methods tackle this by leveraging unlabeled data to learn useful features for downstream classification tasks. In this work, we propose an augmented contrastive SSL framework to learn invariant representations from unlabeled data. Our method applies various perturbations to the unlabeled input data and utilizes contrastive learning to learn representations robust to such perturbations. Experimental results on the Audioset and DESED datasets show that our framework significantly outperforms state-of-the-art SSL and supervised learning methods on sound/event classification tasks.
Training Robust Zero-Shot Voice Conversion Models with Self-supervised Features
Dec 08, 2021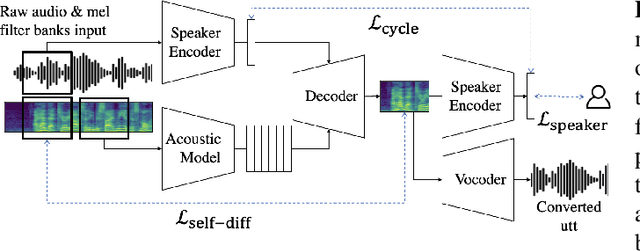
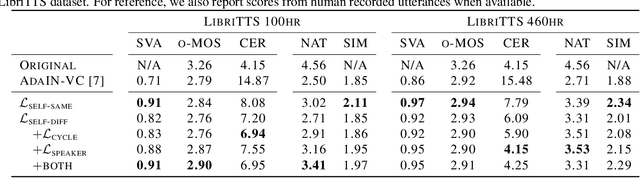
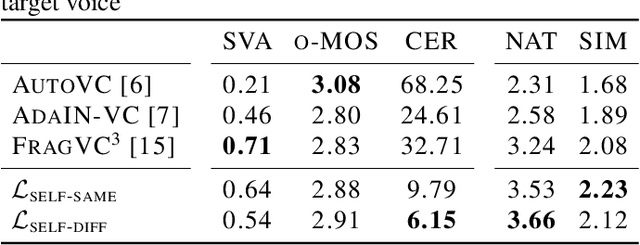
Unsupervised Zero-Shot Voice Conversion (VC) aims to modify the speaker characteristic of an utterance to match an unseen target speaker without relying on parallel training data. Recently, self-supervised learning of speech representation has been shown to produce useful linguistic units without using transcripts, which can be directly passed to a VC model. In this paper, we showed that high-quality audio samples can be achieved by using a length resampling decoder, which enables the VC model to work in conjunction with different linguistic feature extractors and vocoders without requiring them to operate on the same sequence length. We showed that our method can outperform many baselines on the VCTK dataset. Without modifying the architecture, we further demonstrated that a) using pairs of different audio segments from the same speaker, b) adding a cycle consistency loss, and c) adding a speaker classification loss can help to learn a better speaker embedding. Our model trained on LibriTTS using these techniques achieves the best performance, producing audio samples transferred well to the target speaker's voice, while preserving the linguistic content that is comparable with actual human utterances in terms of Character Error Rate.