 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Bidirectional Representations for Low Resource Spoken Language Understanding
Nov 24, 2022
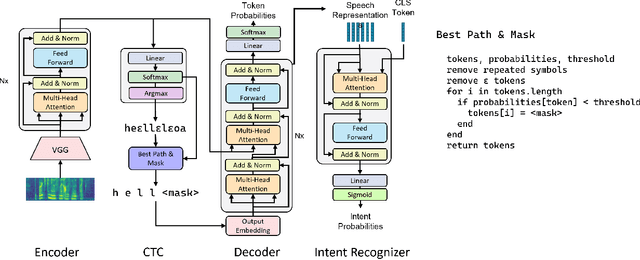


Most spoken language understanding systems use a pipeline approach composed of an automatic speech recognition interface and a natural language understanding module. This approach forces hard decisions when converting continuous inputs into discrete language symbols. Instead, we propose a representation model to encode speech in rich bidirectional encodings that can be used for downstream tasks such as intent prediction. The approach uses a masked language modelling objective to learn the representations, and thus benefits from both the left and right contexts. We show that the performance of the resulting encodings before fine-tuning is better than comparable models on multiple datasets, and that fine-tuning the top layers of the representation model improves the current state of the art on the Fluent Speech Command dataset, also in a low-data regime, when a limited amount of labelled data is used for training. Furthermore, we propose class attention as a spoken language understanding module, efficient both in terms of speed and number of parameters. Class attention can be used to visually explain the predictions of our model, which goes a long way in understanding how the model makes predictions. We perform experiments in English and in Dutch.
Biased Self-supervised learning for ASR
Nov 04, 2022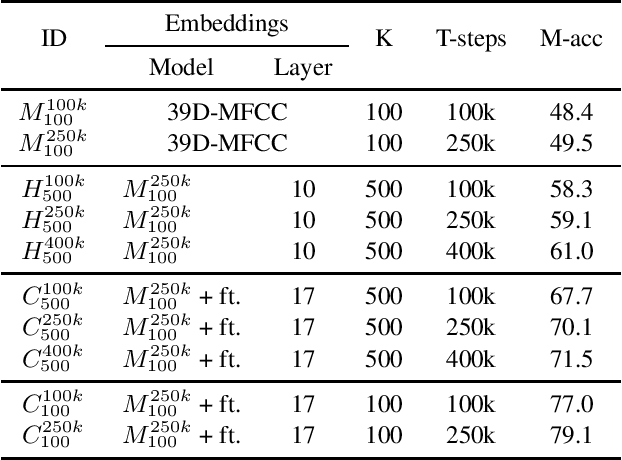
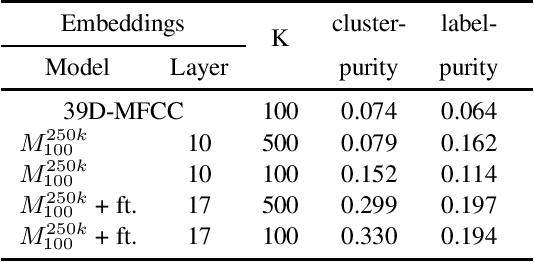
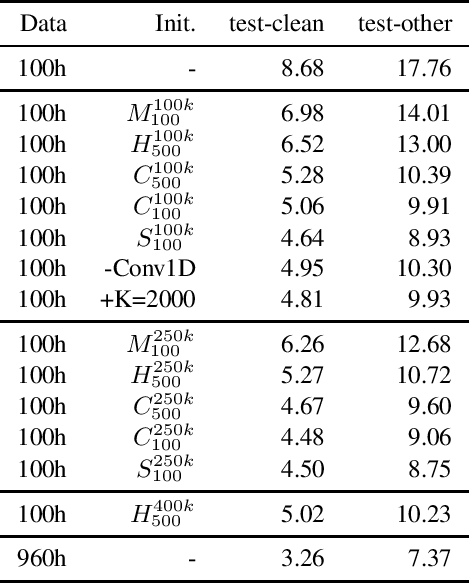
Self-supervised learning via masked prediction pre-training (MPPT) has shown impressive performance on a range of speech-processing tasks. This paper proposes a method to bias self-supervised learning towards a specific task. The core idea is to slightly finetune the model that is used to obtain the target sequence. This leads to better performance and a substantial increase in training speed. Furthermore, this paper proposes a variant of MPPT that allows low-footprint streaming models to be trained effectively by computing the MPPT loss on masked and unmasked frames. These approaches are evaluated for automatic speech recognition on the Librispeech corpus, where 100 hours of data served as the labelled data and 860 hours as the unlabelled data. The biased training outperforms the unbiased training by 15.5% after 250k updates and 23.8% after 100k updates on test-other. For the streaming models, the pre-training approach yields a reduction in word error rate of 44.1%.
End-to-end Audio-visual Speech Recognition with Conformers
Feb 12, 2021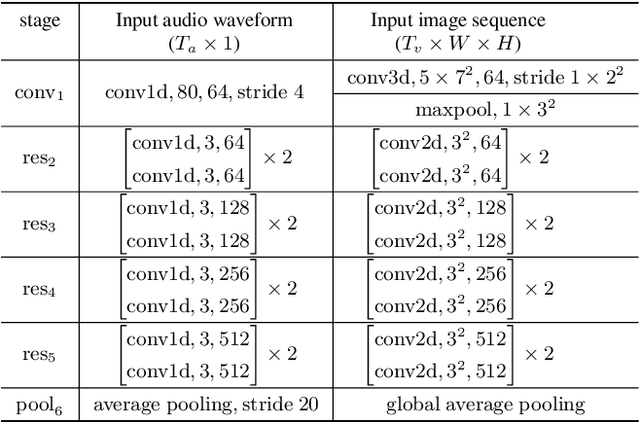
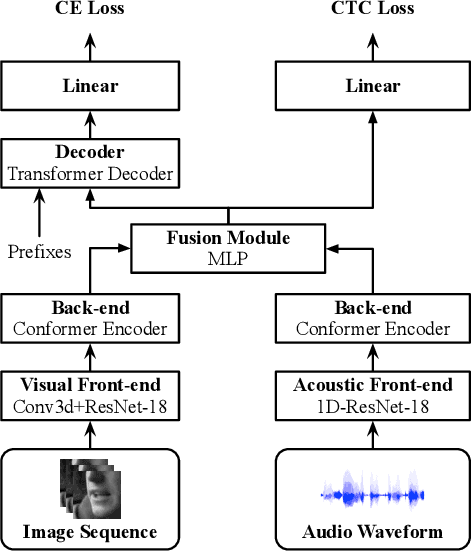

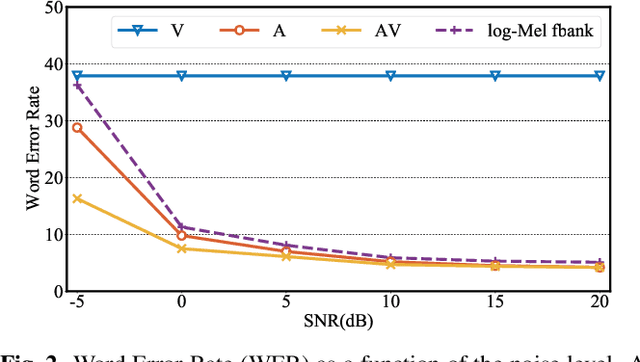
In this work, we present a hybrid CTC/Attention model based on a ResNet-18 and Convolution-augmented transformer (Conformer), that can be trained in an end-to-end manner. In particular, the audio and visual encoders learn to extract features directly from raw pixels and audio waveforms, respectively, which are then fed to conformers and then fusion takes place via a Multi-Layer Perceptron (MLP). The model learns to recognise characters using a combination of CTC and an attention mechanism. We show that end-to-end training, instead of using pre-computed visual features which is common in the literature, the use of a conformer, instead of a recurrent network, and the use of a transformer-based language model, significantly improve the performance of our model. We present results on the largest publicly available datasets for sentence-level speech recognition, Lip Reading Sentences 2 (LRS2) and Lip Reading Sentences 3 (LRS3), respectively. The results show that our proposed models raise the state-of-the-art performance by a large margin in audio-only, visual-only, and audio-visual experiments.
SpeechUT: Bridging Speech and Text with Hidden-Unit for Encoder-Decoder Based Speech-Text Pre-training
Oct 07, 2022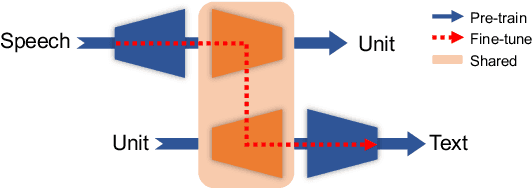
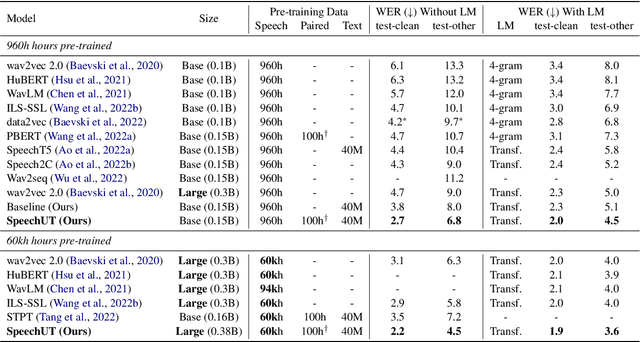
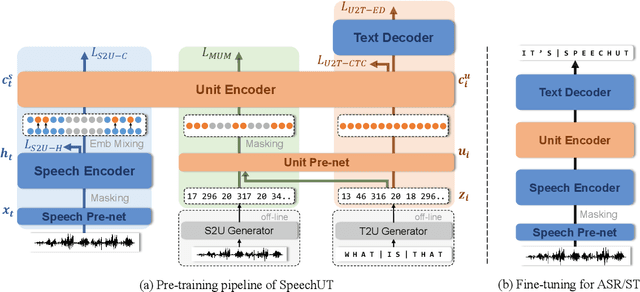
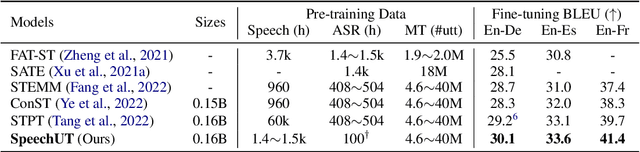
The rapid development of single-modal pre-training has prompted researchers to pay more attention to cross-modal pre-training methods. In this paper, we propose a unified-modal speech-unit-text pre-training model, SpeechUT, to connect the representations of a speech encoder and a text decoder with a shared unit encoder. Leveraging hidden-unit as an interface to align speech and text, we can decompose the speech-to-text model into a speech-to-unit model and a unit-to-text model, which can be jointly pre-trained with unpaired speech and text data respectively. Our proposed SpeechUT is fine-tuned and evaluated on automatic speech recognition (ASR) and speech translation (ST) tasks. Experimental results show that SpeechUT gets substantial improvements over strong baselines, and achieves state-of-the-art performance on both the LibriSpeech ASR and MuST-C ST tasks. To better understand the proposed SpeechUT, detailed analyses are conducted. The code and pre-trained models are available at https://aka.ms/SpeechUT.
Dual-decoder Transformer for Joint Automatic Speech Recognition and Multilingual Speech Translation
Nov 02, 2020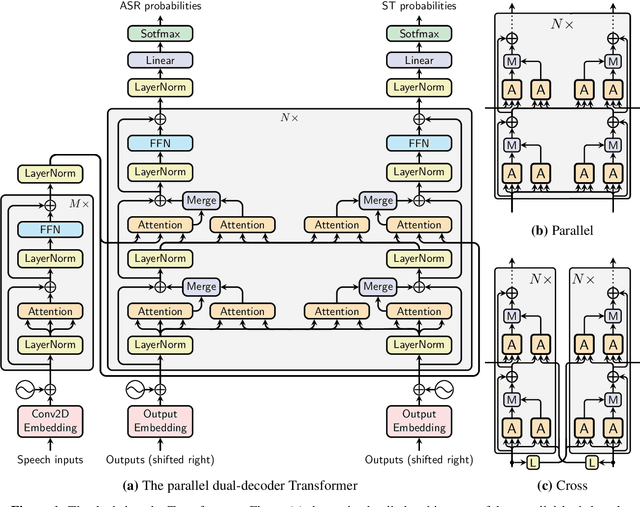
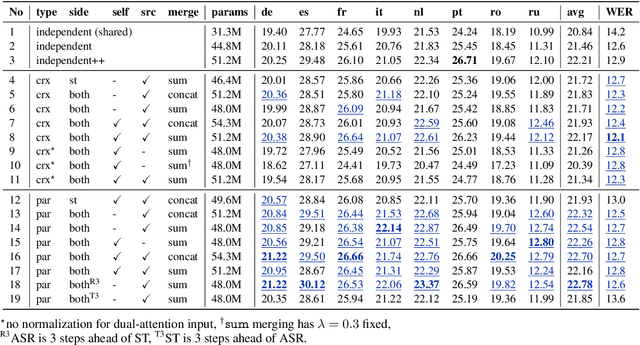
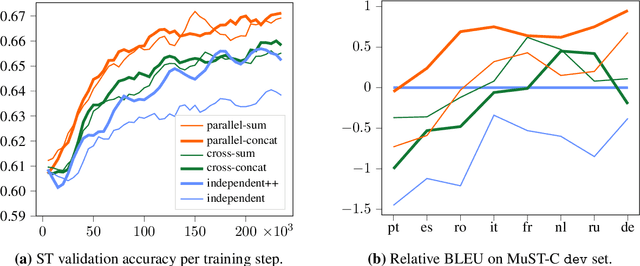
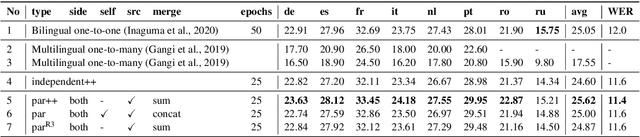
We introduce dual-decoder Transformer, a new model architecture that jointly performs automatic speech recognition (ASR) and multilingual speech translation (ST). Our models are based on the original Transformer architecture (Vaswani et al., 2017) but consist of two decoders, each responsible for one task (ASR or ST). Our major contribution lies in how these decoders interact with each other: one decoder can attend to different information sources from the other via a dual-attention mechanism. We propose two variants of these architectures corresponding to two different levels of dependencies between the decoders, called the parallel and cross dual-decoder Transformers, respectively. Extensive experiments on the MuST-C dataset show that our models outperform the previously-reported highest translation performance in the multilingual settings, and outperform as well bilingual one-to-one results. Furthermore, our parallel models demonstrate no trade-off between ASR and ST compared to the vanilla multi-task architecture. Our code and pre-trained models are available at https://github.com/formiel/speech-translation.
* Accepted at COLING 2020 (Oral)
Robust Speech Recognition Using Generative Adversarial Networks
Nov 05, 2017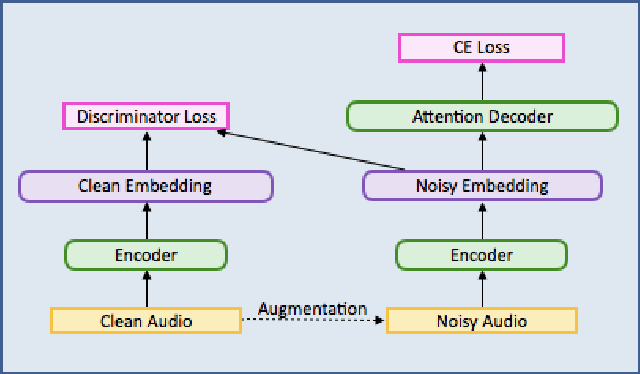
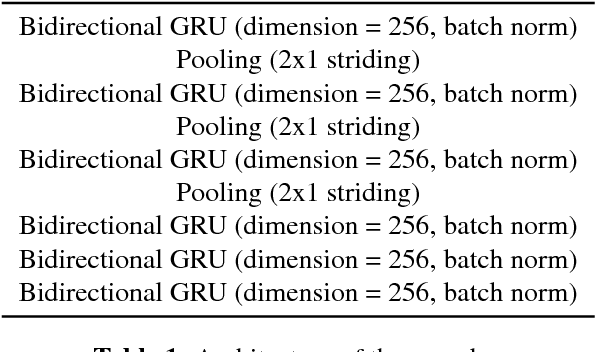

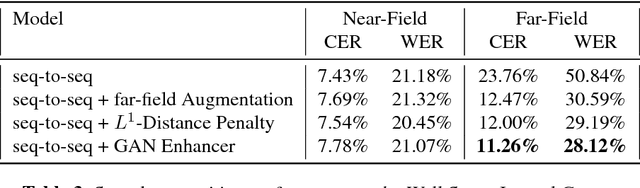
This paper describes a general, scalable, end-to-end framework that uses the generative adversarial network (GAN) objective to enable robust speech recognition. Encoders trained with the proposed approach enjoy improved invariance by learning to map noisy audio to the same embedding space as that of clean audio. Unlike previous methods, the new framework does not rely on domain expertise or simplifying assumptions as are often needed in signal processing, and directly encourages robustness in a data-driven way. We show the new approach improves simulated far-field speech recognition of vanilla sequence-to-sequence models without specialized front-ends or preprocessing.
Optimizing Alignment of Speech and Language Latent Spaces for End-to-End Speech Recognition and Understanding
Oct 23, 2021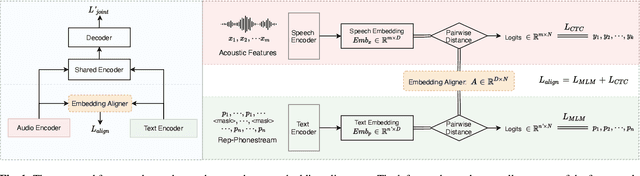
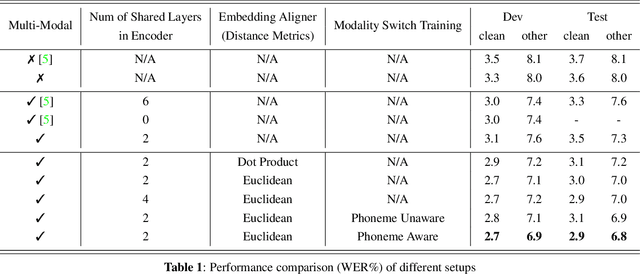
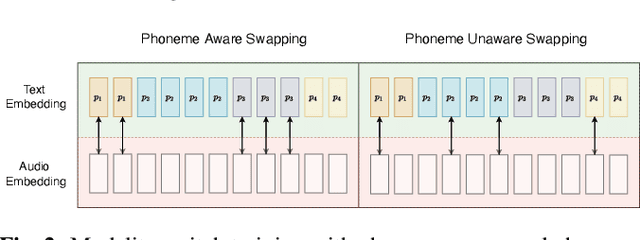
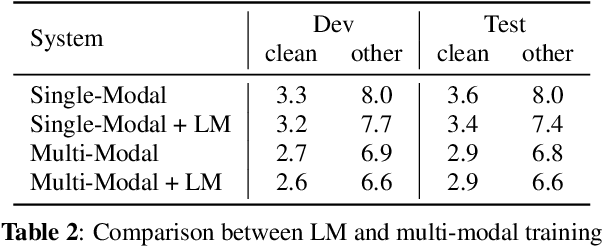
The advances in attention-based encoder-decoder (AED) networks have brought great progress to end-to-end (E2E) automatic speech recognition (ASR). One way to further improve the performance of AED-based E2E ASR is to introduce an extra text encoder for leveraging extensive text data and thus capture more context-aware linguistic information. However, this approach brings a mismatch problem between the speech encoder and the text encoder due to the different units used for modeling. In this paper, we propose an embedding aligner and modality switch training to better align the speech and text latent spaces. The embedding aligner is a shared linear projection between text encoder and speech encoder trained by masked language modeling (MLM) loss and connectionist temporal classification (CTC), respectively. The modality switch training randomly swaps speech and text embeddings based on the forced alignment result to learn a joint representation space. Experimental results show that our proposed approach achieves a relative 14% to 19% word error rate (WER) reduction on Librispeech ASR task. We further verify its effectiveness on spoken language understanding (SLU), i.e., an absolute 2.5% to 2.8% F1 score improvement on SNIPS slot filling task.
LSTM-LM with Long-Term History for First-Pass Decoding in Conversational Speech Recognition
Oct 21, 2020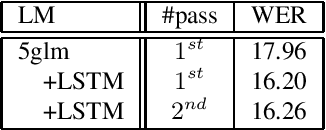
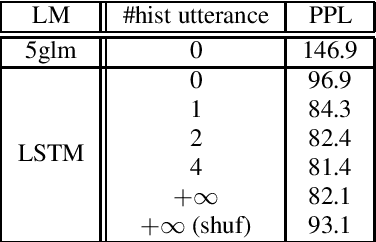
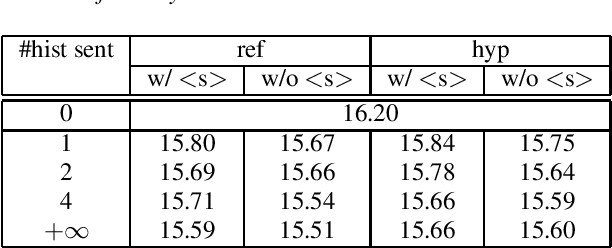

LSTM language models (LSTM-LMs) have been proven to be powerful and yielded significant performance improvements over count based n-gram LMs in modern speech recognition systems. Due to its infinite history states and computational load, most previous studies focus on applying LSTM-LMs in the second-pass for rescoring purpose. Recent work shows that it is feasible and computationally affordable to adopt the LSTM-LMs in the first-pass decoding within a dynamic (or tree based) decoder framework. In this work, the LSTM-LM is composed with a WFST decoder on-the-fly for the first-pass decoding. Furthermore, motivated by the long-term history nature of LSTM-LMs, the use of context beyond the current utterance is explored for the first-pass decoding in conversational speech recognition. The context information is captured by the hidden states of LSTM-LMs across utterance and can be used to guide the first-pass search effectively. The experimental results in our internal meeting transcription system show that significant performance improvements can be obtained by incorporating the contextual information with LSTM-LMs in the first-pass decoding, compared to applying the contextual information in the second-pass rescoring.
More Speaking or More Speakers?
Nov 02, 2022
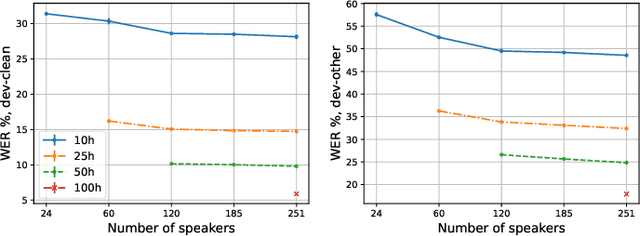
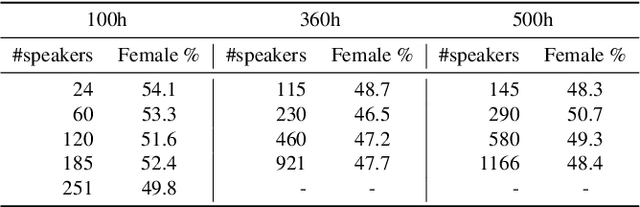
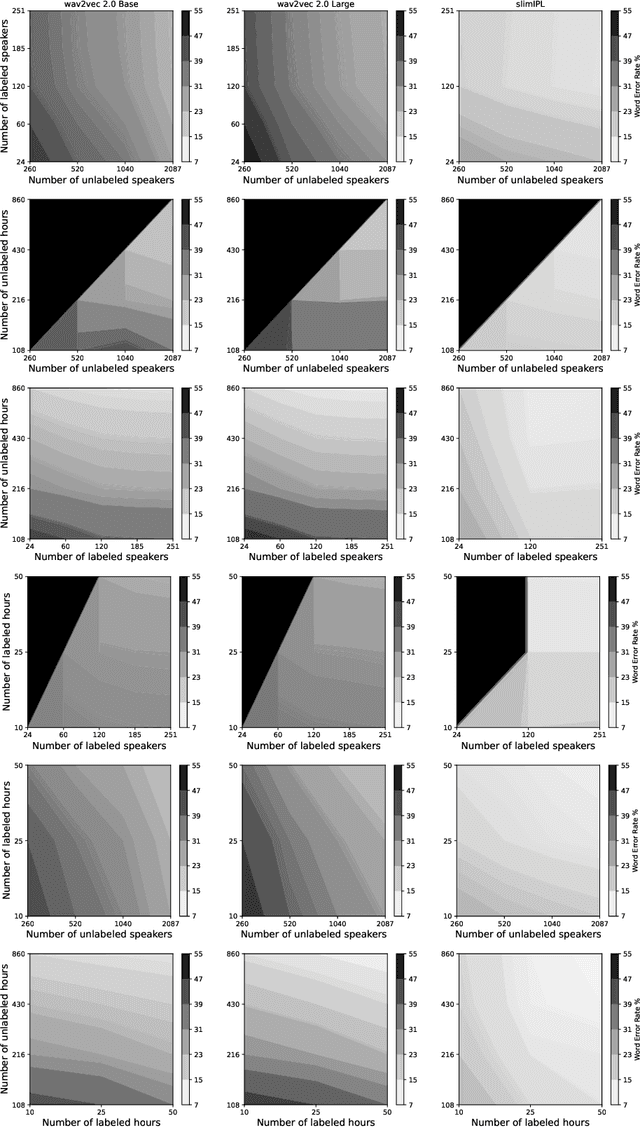
Self-training (ST) and self-supervised learning (SSL) methods have demonstrated strong improvements in automatic speech recognition (ASR). In spite of these advances, to the best of our knowledge, there is no analysis of how the composition of the labelled and unlabelled datasets used in these methods affects the results. In this work we aim to analyse the effect of numbers of speakers in the training data on a recent SSL algorithm (wav2vec 2.0), and a recent ST algorithm (slimIPL). We perform a systematic analysis on both labeled and unlabeled data by varying the number of speakers while keeping the number of hours fixed and vice versa. Our findings suggest that SSL requires a large amount of unlabeled data to produce high accuracy results, while ST requires a sufficient number of speakers in the labelled data, especially in the low-regime setting. In this manner these two approaches improve supervised learning in different regimes of dataset composition.
Simulating realistic speech overlaps improves multi-talker ASR
Oct 27, 2022
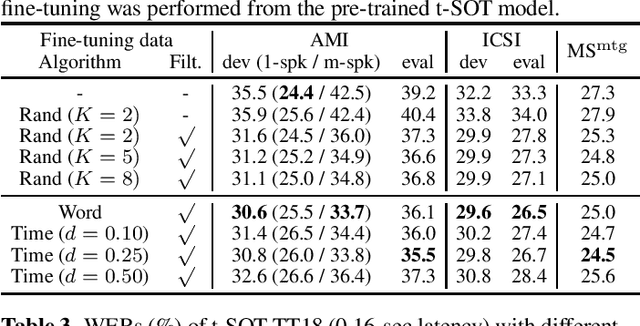

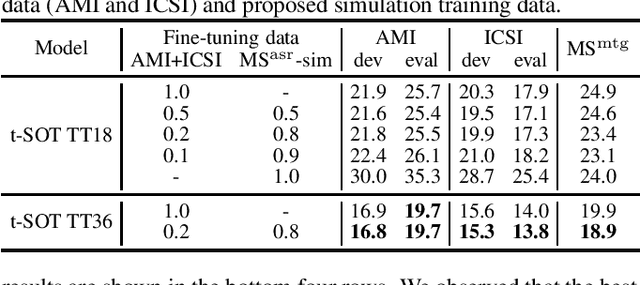
Multi-talker automatic speech recognition (ASR) has been studied to generate transcriptions of natural conversation including overlapping speech of multiple speakers. Due to the difficulty in acquiring real conversation data with high-quality human transcriptions, a na\"ive simulation of multi-talker speech by randomly mixing multiple utterances was conventionally used for model training. In this work, we propose an improved technique to simulate multi-talker overlapping speech with realistic speech overlaps, where an arbitrary pattern of speech overlaps is represented by a sequence of discrete tokens. With this representation, speech overlapping patterns can be learned from real conversations based on a statistical language model, such as N-gram, which can be then used to generate multi-talker speech for training. In our experiments, multi-talker ASR models trained with the proposed method show consistent improvement on the word error rates across multiple datasets.