 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenCSSmark: Making the Social Sciences Count in LLM Research
May 06, 2026This position paper argues that the under-representation of social science tasks in contemporary LLM benchmarks limits advances in both LLM evaluation and social scientific inquiry. Benchmarks -- standardized tools for assessing computational systems -- are pivotal in the development of artificial intelligence (AI), including large language models (LLMs). Benchmarks do more than measure progress -- they actively structure it, shaping reputations, research agendas, and commercial outcomes. Despite this central role, the social sciences are largely absent from mainstream evaluation frameworks, even though scholars in these fields generate dozens of rigorously annotated, context-sensitive datasets each year. Integrating this work into benchmark design could significantly improve the generalization and robustness of AI models. In turn, models trained on social scientific tasks would likely yield better performance on classic and contemporary tasks in disciplines as diverse as history, sociology, political science or economics. This is all the more pressing as these disciplines are quickly turning to LLMs for assistance. To address this gap, we introduce BenCSSmark, a benchmark composed of datasets annotated by computational social scientists. By integrating social scientific perspectives into benchmarking, BenCSSmark seeks to promote more robust, transparent, and socially relevant AI systems and to foster efficient collaboration.
Is Biomedical Specialization Still Worth It? Insights from Domain-Adaptive Language Modelling with a New French Health Corpus
Apr 08, 2026Large language models (LLMs) have demonstrated remarkable capabilities across diverse domains, yet their adaptation to specialized fields remains challenging, particularly for non-English languages. This study investigates domain-adaptive pre-training (DAPT) as a strategy for specializing small to mid-sized LLMs in the French biomedical domain through continued pre-training. We address two key research questions: the viability of specialized continued pre-training for domain adaptation and the relationship between domain-specific performance gains and general capability degradation. Our contributions include the release of a fully open-licensed French biomedical corpus suitable for commercial and open-source applications, the training and release of specialized French biomedical LLMs, and novel insights for DAPT implementation. Our methodology encompasses the collection and refinement of high-quality French biomedical texts, the exploration of causal language modeling approaches using DAPT, and conducting extensive comparative evaluations. Our results cast doubt on the efficacy of DAPT, in contrast to previous works, but we highlight its viability in smaller-scale, resource-constrained scenarios under the right conditions. Findings in this paper further suggest that model merging post-DAPT is essential to mitigate generalization trade-offs, and in some cases even improves performance on specialized tasks at which the DAPT was directed.
What Matters to an LLM? Behavioral and Computational Evidences from Summarization
Jan 31, 2026Large Language Models (LLMs) are now state-of-the-art at summarization, yet the internal notion of importance that drives their information selections remains hidden. We propose to investigate this by combining behavioral and computational analyses. Behaviorally, we generate a series of length-controlled summaries for each document and derive empirical importance distributions based on how often each information unit is selected. These reveal that LLMs converge on consistent importance patterns, sharply different from pre-LLM baselines, and that LLMs cluster more by family than by size. Computationally, we identify that certain attention heads align well with empirical importance distributions, and that middle-to-late layers are strongly predictive of importance. Together, these results provide initial insights into what LLMs prioritize in summarization and how this priority is internally represented, opening a path toward interpreting and ultimately controlling information selection in these models.
Pantagruel: Unified Self-Supervised Encoders for French Text and Speech
Jan 09, 2026We release Pantagruel models, a new family of self-supervised encoder models for French text and speech. Instead of predicting modality-tailored targets such as textual tokens or speech units, Pantagruel learns contextualized target representations in the feature space, allowing modality-specific encoders to capture linguistic and acoustic regularities more effectively. Separate models are pre-trained on large-scale French corpora, including Wikipedia, OSCAR and CroissantLLM for text, together with MultilingualLibriSpeech, LeBenchmark, and INA-100k for speech. INA-100k is a newly introduced 100,000-hour corpus of French audio derived from the archives of the Institut National de l'Audiovisuel (INA), the national repository of French radio and television broadcasts, providing highly diverse audio data. We evaluate Pantagruel across a broad range of downstream tasks spanning both modalities, including those from the standard French benchmarks such as FLUE or LeBenchmark. Across these tasks, Pantagruel models show competitive or superior performance compared to strong French baselines such as CamemBERT, FlauBERT, and LeBenchmark2.0, while maintaining a shared architecture that can seamlessly handle either speech or text inputs. These results confirm the effectiveness of feature-space self-supervised objectives for French representation learning and highlight Pantagruel as a robust foundation for multimodal speech-text understanding.
Reassessing Graph Linearization for Sequence-to-sequence AMR Parsing: On the Advantages and Limitations of Triple-Based Encoding
May 13, 2025Sequence-to-sequence models are widely used to train Abstract Meaning Representation (Banarescu et al., 2013, AMR) parsers. To train such models, AMR graphs have to be linearized into a one-line text format. While Penman encoding is typically used for this purpose, we argue that it has limitations: (1) for deep graphs, some closely related nodes are located far apart in the linearized text (2) Penman's tree-based encoding necessitates inverse roles to handle node re-entrancy, doubling the number of relation types to predict. To address these issues, we propose a triple-based linearization method and compare its efficiency with Penman linearization. Although triples are well suited to represent a graph, our results suggest room for improvement in triple encoding to better compete with Penman's concise and explicit representation of a nested graph structure.
Should Cross-Lingual AMR Parsing go Meta? An Empirical Assessment of Meta-Learning and Joint Learning AMR Parsing
Oct 04, 2024Cross-lingual AMR parsing is the task of predicting AMR graphs in a target language when training data is available only in a source language. Due to the small size of AMR training data and evaluation data, cross-lingual AMR parsing has only been explored in a small set of languages such as English, Spanish, German, Chinese, and Italian. Taking inspiration from Langedijk et al. (2022), who apply meta-learning to tackle cross-lingual syntactic parsing, we investigate the use of meta-learning for cross-lingual AMR parsing. We evaluate our models in $k$-shot scenarios (including 0-shot) and assess their effectiveness in Croatian, Farsi, Korean, Chinese, and French. Notably, Korean and Croatian test sets are developed as part of our work, based on the existing The Little Prince English AMR corpus, and made publicly available. We empirically study our method by comparing it to classical joint learning. Our findings suggest that while the meta-learning model performs slightly better in 0-shot evaluation for certain languages, the performance gain is minimal or absent when $k$ is higher than 0.
LeBenchmark 2.0: a Standardized, Replicable and Enhanced Framework for Self-supervised Representations of French Speech
Sep 11, 2023Self-supervised learning (SSL) is at the origin of unprecedented improvements in many different domains including computer vision and natural language processing. Speech processing drastically benefitted from SSL as most of the current domain-related tasks are now being approached with pre-trained models. This work introduces LeBenchmark 2.0 an open-source framework for assessing and building SSL-equipped French speech technologies. It includes documented, large-scale and heterogeneous corpora with up to 14,000 hours of heterogeneous speech, ten pre-trained SSL wav2vec 2.0 models containing from 26 million to one billion learnable parameters shared with the community, and an evaluation protocol made of six downstream tasks to complement existing benchmarks. LeBenchmark 2.0 also presents unique perspectives on pre-trained SSL models for speech with the investigation of frozen versus fine-tuned downstream models, task-agnostic versus task-specific pre-trained models as well as a discussion on the carbon footprint of large-scale model training.
UMLS-KGI-BERT: Data-Centric Knowledge Integration in Transformers for Biomedical Entity Recognition
Jul 20, 2023Pre-trained transformer language models (LMs) have in recent years become the dominant paradigm in applied NLP. These models have achieved state-of-the-art performance on tasks such as information extraction, question answering, sentiment analysis, document classification and many others. In the biomedical domain, significant progress has been made in adapting this paradigm to NLP tasks that require the integration of domain-specific knowledge as well as statistical modelling of language. In particular, research in this area has focused on the question of how best to construct LMs that take into account not only the patterns of token distribution in medical text, but also the wealth of structured information contained in terminology resources such as the UMLS. This work contributes a data-centric paradigm for enriching the language representations of biomedical transformer-encoder LMs by extracting text sequences from the UMLS. This allows for graph-based learning objectives to be combined with masked-language pre-training. Preliminary results from experiments in the extension of pre-trained LMs as well as training from scratch show that this framework improves downstream performance on multiple biomedical and clinical Named Entity Recognition (NER) tasks.
Pre-training for Speech Translation: CTC Meets Optimal Transport
Jan 27, 2023The gap between speech and text modalities is a major challenge in speech-to-text translation (ST). Different methods have been proposed for reducing this gap, but most of them require architectural changes in ST training. In this work, we propose to mitigate this issue at the pre-training stage, requiring no change in the ST model. First, we show that the connectionist temporal classification (CTC) loss can reduce the modality gap by design. We provide a quantitative comparison with the more common cross-entropy loss, showing that pre-training with CTC consistently achieves better final ST accuracy. Nevertheless, CTC is only a partial solution and thus, in our second contribution, we propose a novel pre-training method combining CTC and optimal transport to further reduce this gap. Our method pre-trains a Siamese-like model composed of two encoders, one for acoustic inputs and the other for textual inputs, such that they produce representations that are close to each other in the Wasserstein space. Extensive experiments on the standard CoVoST-2 and MuST-C datasets show that our pre-training method applied to the vanilla encoder-decoder Transformer achieves state-of-the-art performance under the no-external-data setting, and performs on par with recent strong multi-task learning systems trained with external data. Finally, our method can also be applied on top of these multi-task systems, leading to further improvements for these models.
Effect Of Personalized Calibration On Gaze Estimation Using Deep-Learning
Sep 27, 2021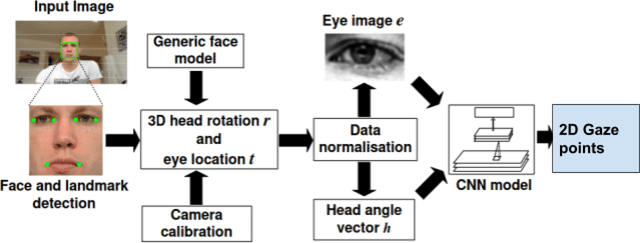

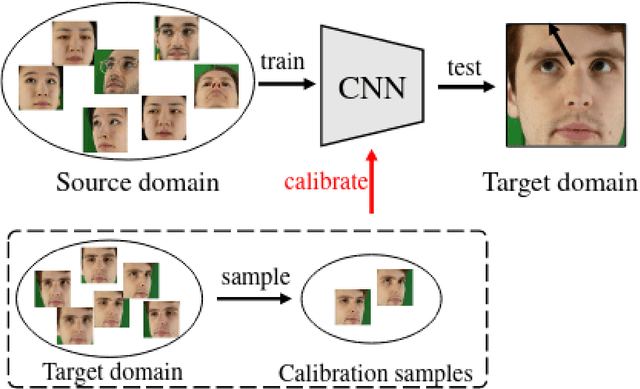
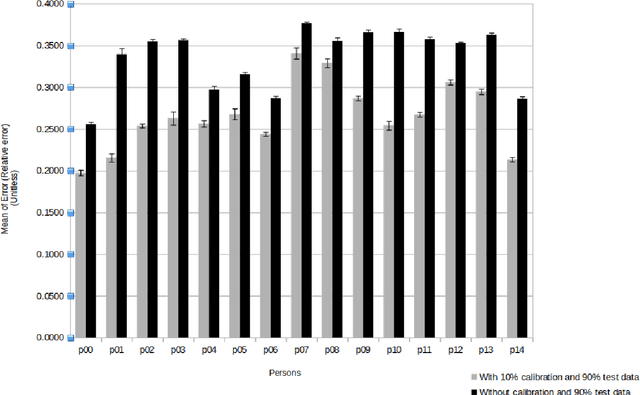
With the increase in computation power and the development of new state-of-the-art deep learning algorithms, appearance-based gaze estimation is becoming more and more popular. It is believed to work well with curated laboratory data sets, however it faces several challenges when deployed in real world scenario. One such challenge is to estimate the gaze of a person about which the Deep Learning model trained for gaze estimation has no knowledge about. To analyse the performance in such scenarios we have tried to simulate a calibration mechanism. In this work we use the MPIIGaze data set. We trained a multi modal convolutional neural network and analysed its performance with and without calibration and this evaluation provides clear insights on how calibration improved the performance of the Deep Learning model in estimating gaze in the wild.