 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-end Audio-visual Speech Recognition with Conformers
Paper and Code
Feb 12, 2021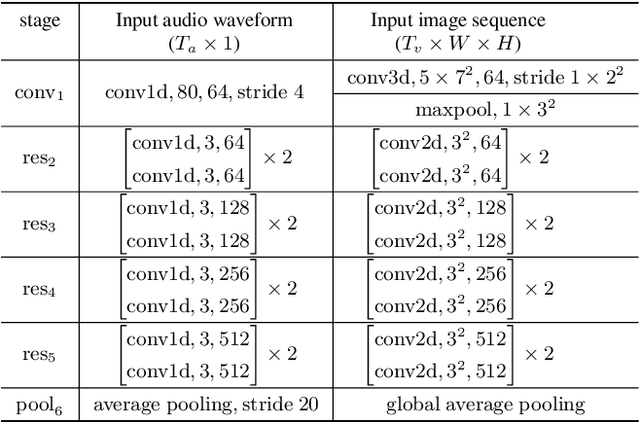
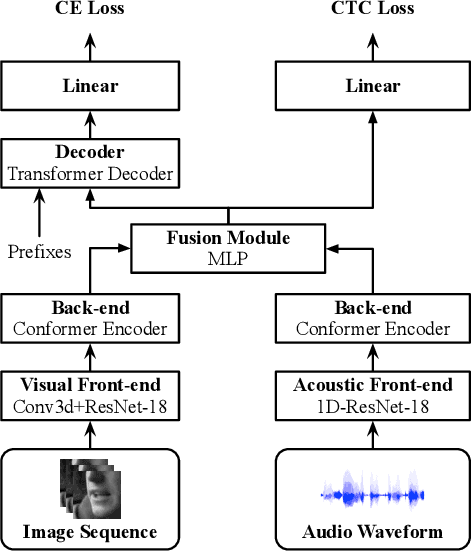

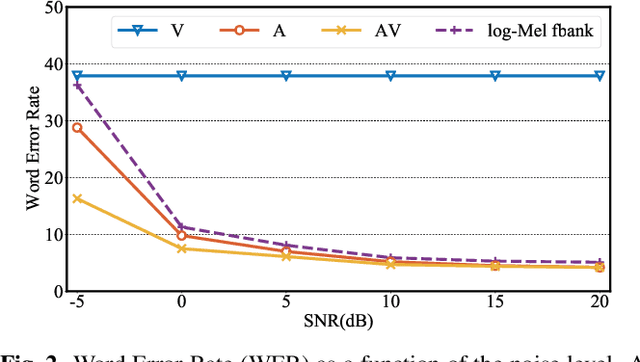
In this work, we present a hybrid CTC/Attention model based on a ResNet-18 and Convolution-augmented transformer (Conformer), that can be trained in an end-to-end manner. In particular, the audio and visual encoders learn to extract features directly from raw pixels and audio waveforms, respectively, which are then fed to conformers and then fusion takes place via a Multi-Layer Perceptron (MLP). The model learns to recognise characters using a combination of CTC and an attention mechanism. We show that end-to-end training, instead of using pre-computed visual features which is common in the literature, the use of a conformer, instead of a recurrent network, and the use of a transformer-based language model, significantly improve the performance of our model. We present results on the largest publicly available datasets for sentence-level speech recognition, Lip Reading Sentences 2 (LRS2) and Lip Reading Sentences 3 (LRS3), respectively. The results show that our proposed models raise the state-of-the-art performance by a large margin in audio-only, visual-only, and audio-visual experiments.