 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
Deep Image Synthesis from Intuitive User Input: A Review and Perspectives
Jul 09, 2021
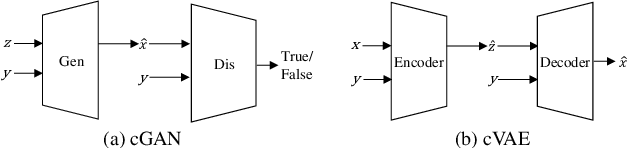
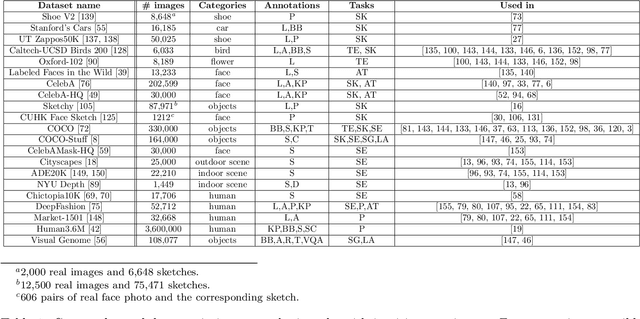

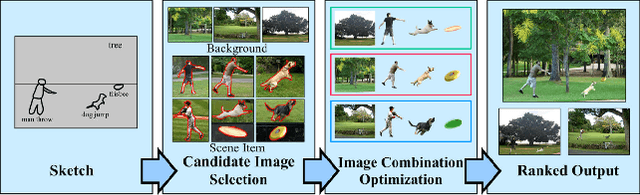
In many applications of computer graphics, art and design, it is desirable for a user to provide intuitive non-image input, such as text, sketch, stroke, graph or layout, and have a computer system automatically generate photo-realistic images that adhere to the input content. While classic works that allow such automatic image content generation have followed a framework of image retrieval and composition, recent advances in deep generative models such as generative adversarial networks (GANs), variational autoencoders (VAEs), and flow-based methods have enabled more powerful and versatile image generation tasks. This paper reviews recent works for image synthesis given intuitive user input, covering advances in input versatility, image generation methodology, benchmark datasets, and evaluation metrics. This motivates new perspectives on input representation and interactivity, cross pollination between major image generation paradigms, and evaluation and comparison of generation methods.
* 26 pages, 7 figures, 1 table
GPU-Accelerated Mobile Multi-view Style Transfer
Mar 02, 2020
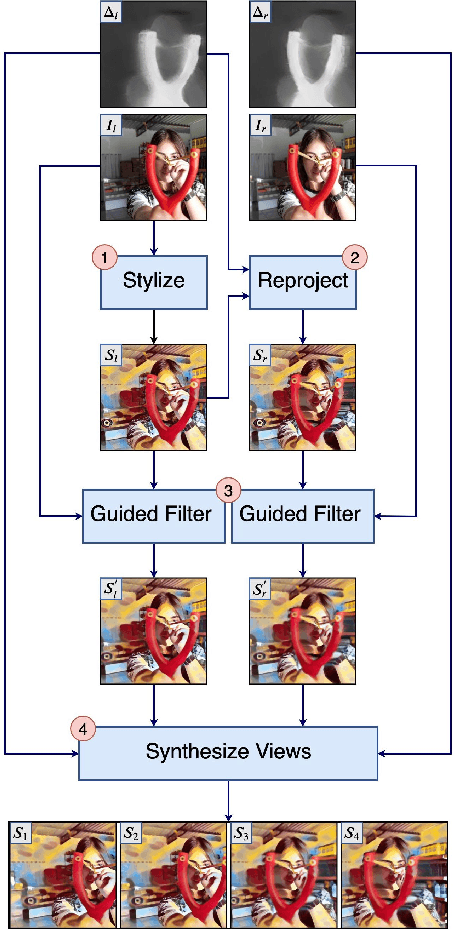
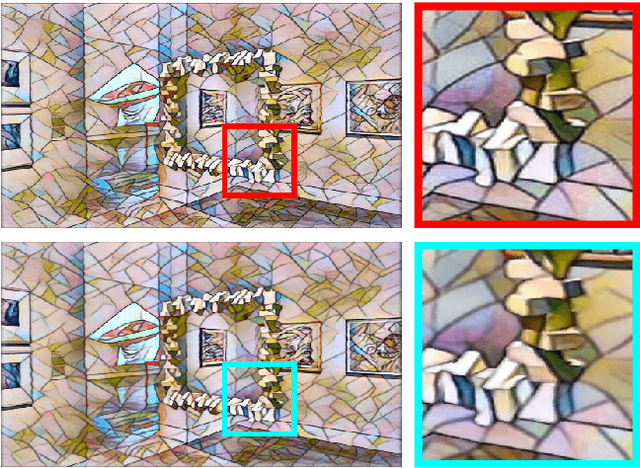

An estimated 60% of smartphones sold in 2018 were equipped with multiple rear cameras, enabling a wide variety of 3D-enabled applications such as 3D Photos. The success of 3D Photo platforms (Facebook 3D Photo, Holopix, etc) depend on a steady influx of user generated content. These platforms must provide simple image manipulation tools to facilitate content creation, akin to traditional photo platforms. Artistic neural style transfer, propelled by recent advancements in GPU technology, is one such tool for enhancing traditional photos. However, naively extrapolating single-view neural style transfer to the multi-view scenario produces visually inconsistent results and is prohibitively slow on mobile devices. We present a GPU-accelerated multi-view style transfer pipeline which enforces style consistency between views with on-demand performance on mobile platforms. Our pipeline is modular and creates high quality depth and parallax effects from a stereoscopic image pair.
Identity-Guided Face Generation with Multi-modal Contour Conditions
Oct 10, 2021
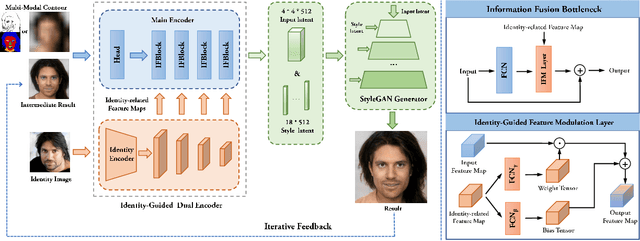
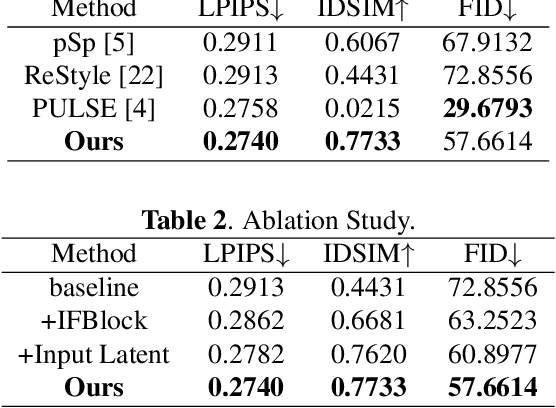

Recent face generation methods have tried to synthesize faces based on the given contour condition, like a low-resolution image or a sketch. However, the problem of identity ambiguity remains unsolved, which usually occurs when the contour is too vague to provide reliable identity information (e.g., when its resolution is extremely low). In this work, we propose a framework that takes the contour and an extra image specifying the identity as the inputs, where the contour can be of various modalities, including the low-resolution image, sketch, and semantic label map. This task especially fits the situation of tracking the known criminals or making intelligent creations for entertainment. Concretely, we propose a novel dual-encoder architecture, in which an identity encoder extracts the identity-related feature, accompanied by a main encoder to obtain the rough contour information and further fuse all the information together. The encoder output is iteratively fed into a pre-trained StyleGAN generator until getting a satisfying result. To the best of our knowledge, this is the first work that achieves identity-guided face generation conditioned on multi-modal contour images. Moreover, our method can produce photo-realistic results with 1024$\times$1024 resolution. Code will be available at https://git.io/Jo4yh.
Controllable and Compositional Generation with Latent-Space Energy-Based Models
Oct 21, 2021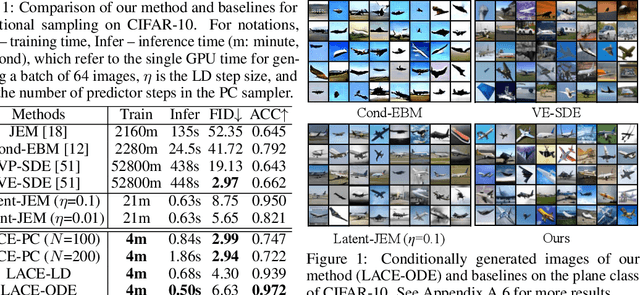

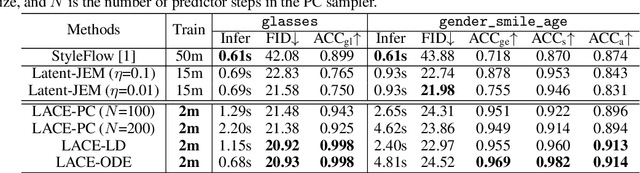

Controllable generation is one of the key requirements for successful adoption of deep generative models in real-world applications, but it still remains as a great challenge. In particular, the compositional ability to generate novel concept combinations is out of reach for most current models. In this work, we use energy-based models (EBMs) to handle compositional generation over a set of attributes. To make them scalable to high-resolution image generation, we introduce an EBM in the latent space of a pre-trained generative model such as StyleGAN. We propose a novel EBM formulation representing the joint distribution of data and attributes together, and we show how sampling from it is formulated as solving an ordinary differential equation (ODE). Given a pre-trained generator, all we need for controllable generation is to train an attribute classifier. Sampling with ODEs is done efficiently in the latent space and is robust to hyperparameters. Thus, our method is simple, fast to train, and efficient to sample. Experimental results show that our method outperforms the state-of-the-art in both conditional sampling and sequential editing. In compositional generation, our method excels at zero-shot generation of unseen attribute combinations. Also, by composing energy functions with logical operators, this work is the first to achieve such compositionality in generating photo-realistic images of resolution 1024x1024.
Cali-Sketch: Stroke Calibration and Completion for High-Quality Face Image Generation from Poorly-Drawn Sketches
Nov 01, 2019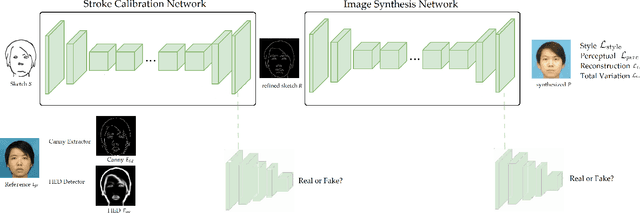



Image generation task has received increasing attention because of its wide application in security and entertainment. Sketch-based face generation brings more fun and better quality of image generation due to supervised interaction. However, When a sketch poorly aligned with the true face is given as input, existing supervised image-to-image translation methods often cannot generate acceptable photo-realistic face images. To address this problem, in this paper we propose Cali-Sketch, a poorly-drawn-sketch to photo-realistic-image generation method. Cali-Sketch explicitly models stroke calibration and image generation using two constituent networks: a Stroke Calibration Network (SCN), which calibrates strokes of facial features and enriches facial details while preserving the original intent features; and an Image Synthesis Network (ISN), which translates the calibrated and enriched sketches to photo-realistic face images. In this way, we manage to decouple a difficult cross-domain translation problem into two easier steps. Extensive experiments verify that the face photos generated by Cali-Sketch are both photo-realistic and faithful to the input sketches, compared with state-of-the-art methods
FDMA-CDMA Mode CAOS Camera Demonstration using UV to NIR Full Spectrum
Jan 06, 2021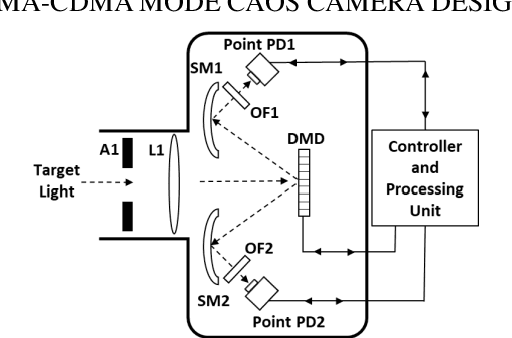
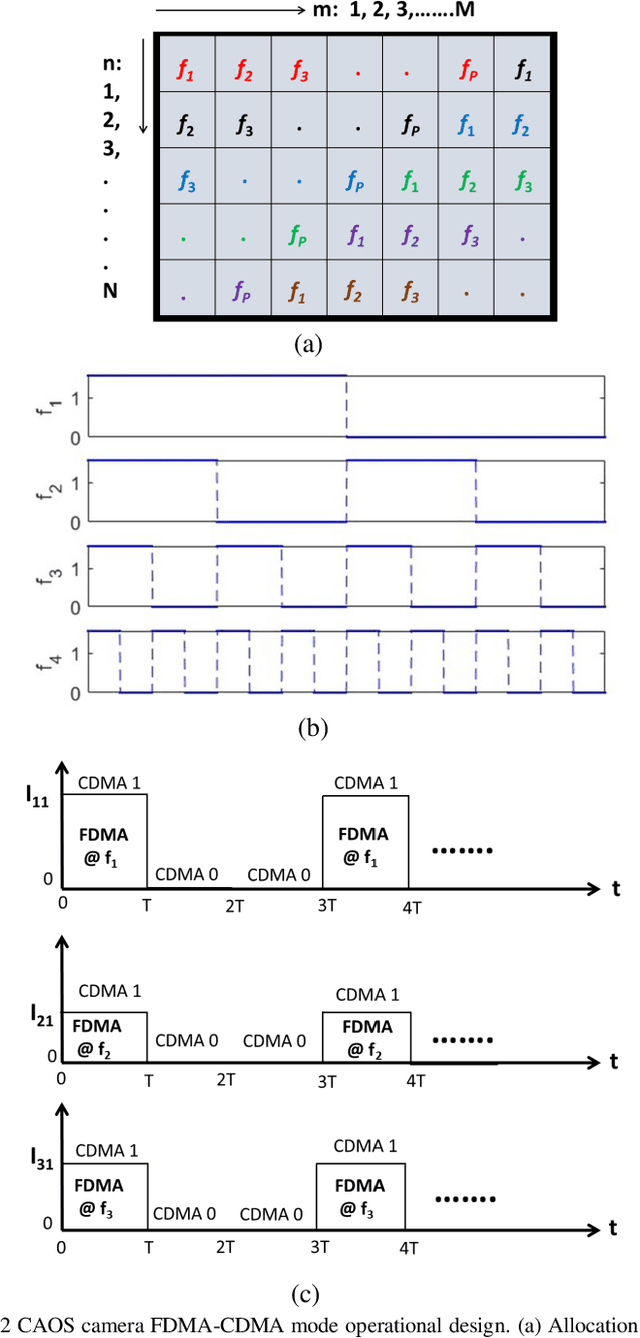
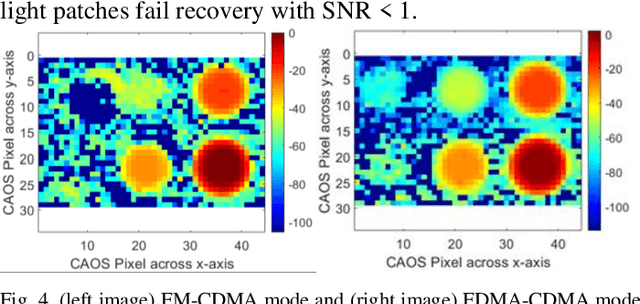
For the first time, the hybrid Frequency Division Multiple Access (FDMA) Code Division Multiple Access (CDMA) mode of the CAOS (i.e., Coded Access Optical Sensor) camera is demonstrated. The FDMA CDMA mode is a time frequency double signal encoding design for robust and faster linear High Dynamic Range (HDR) image irradiance extraction. Specifically, it simultaneously combines the strength of the FDMA-mode linear HDR Fast Fourier Transform (FFT) Digital Signal Processing (DSP) based spectrum analysis with the CDMA mode provided many simultaneous CAOS pixels high Signal to Noise Ratio (SNR) photo-detection. The FDMA CDMA mode with P FDMA channels provides a faster camera operation versus the linear HDR Frequency Modulation (FM) CDMA mode. Visible band imaging experiments using a Digital Micromirror Device (DMD) based CAOS camera demonstrate a P equal to 4 channels FDMA CDMA mode high quality image recovery of a calibrated 64 dB 6 patches HDR target versus the CDMA and FM CDMA CAOS modes that limit dynamic range and speed, respectively. Simultaneous dual image capture capability of the FDMA-CDMA mode is also demonstrated for the first time in Ultraviolet (UV) to Near Infrared (NIR) 350 to 1800 nm full spectrum using Silicon (Si) and Germanium (Ge) point photo-detectors.
Machine Learning Based Analysis of Finnish World War II Photographers
Apr 26, 2019

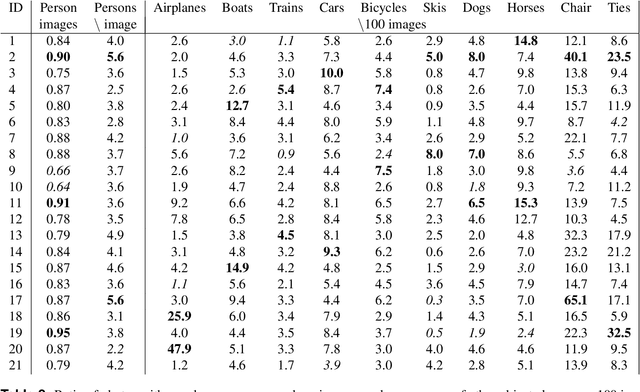

In this paper, we demonstrate the benefits of using state-of-the-art machine learning methods in the analysis of historical photo archives. Specifically, we analyze prominent Finnish World War II photographers, who have captured high numbers of photographs in the publicly available SA photo archive, which contains 160,000 photographs from Finnish Winter, Continuation, and Lapland Wars captures in 1939-1945. We were able to find some special characteristics for different photographers in terms of their typical photo content and photo types (e.g., close-ups vs. overview images, number of people). Furthermore, we managed to train a neural network that can successfully recognize the photographer from some of the photos, which shows that such photos are indeed characteristic for certain photographers. We further analyze the similarities and differences between the photographers using the features extracted from the photographer classifier network. All the extracted information will help historical and societal studies over the photo archive.
UniFaceGAN: A Unified Framework for Temporally Consistent Facial Video Editing
Aug 12, 2021



Recent research has witnessed advances in facial image editing tasks including face swapping and face reenactment. However, these methods are confined to dealing with one specific task at a time. In addition, for video facial editing, previous methods either simply apply transformations frame by frame or utilize multiple frames in a concatenated or iterative fashion, which leads to noticeable visual flickers. In this paper, we propose a unified temporally consistent facial video editing framework termed UniFaceGAN. Based on a 3D reconstruction model and a simple yet efficient dynamic training sample selection mechanism, our framework is designed to handle face swapping and face reenactment simultaneously. To enforce the temporal consistency, a novel 3D temporal loss constraint is introduced based on the barycentric coordinate interpolation. Besides, we propose a region-aware conditional normalization layer to replace the traditional AdaIN or SPADE to synthesize more context-harmonious results. Compared with the state-of-the-art facial image editing methods, our framework generates video portraits that are more photo-realistic and temporally smooth.
Learning Efficient Multi-Agent Cooperative Visual Exploration
Oct 12, 2021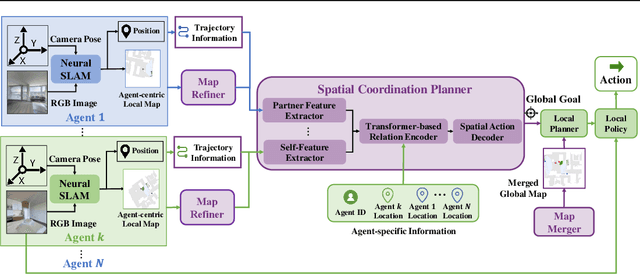
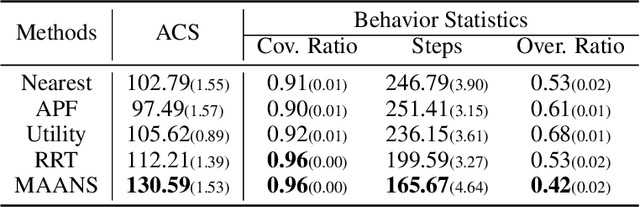
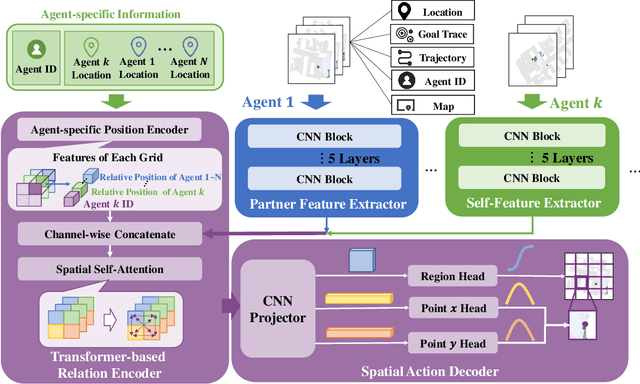
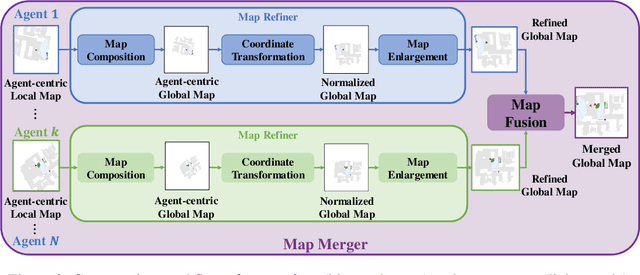
We consider the task of visual indoor exploration with multiple agents, where the agents need to cooperatively explore the entire indoor region using as few steps as possible. Classical planning-based methods often suffer from particularly expensive computation at each inference step and a limited expressiveness of cooperation strategy. By contrast, reinforcement learning (RL) has become a trending paradigm for tackling this challenge due to its modeling capability of arbitrarily complex strategies and minimal inference overhead. We extend the state-of-the-art single-agent RL solution, Active Neural SLAM (ANS), to the multi-agent setting by introducing a novel RL-based global-goal planner, Spatial Coordination Planner (SCP), which leverages spatial information from each individual agent in an end-to-end manner and effectively guides the agents to navigate towards different spatial goals with high exploration efficiency. SCP consists of a transformer-based relation encoder to capture intra-agent interactions and a spatial action decoder to produce accurate goals. In addition, we also implement a few multi-agent enhancements to process local information from each agent for an aligned spatial representation and more precise planning. Our final solution, Multi-Agent Active Neural SLAM (MAANS), combines all these techniques and substantially outperforms 4 different planning-based methods and various RL baselines in the photo-realistic physical testbed, Habitat.
Overcoming Obstructions via Bandwidth-Limited Multi-Agent Spatial Handshaking
Jul 01, 2021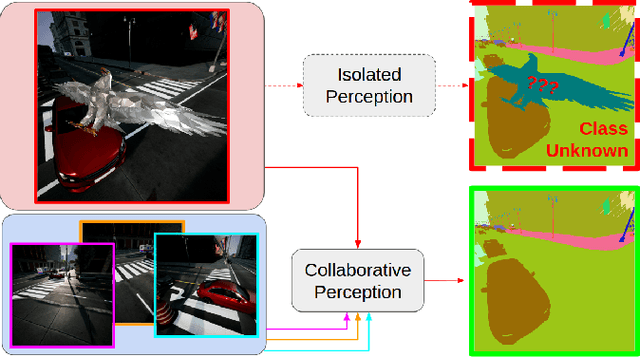
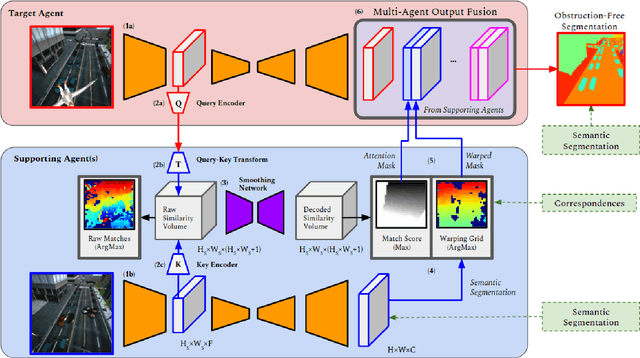
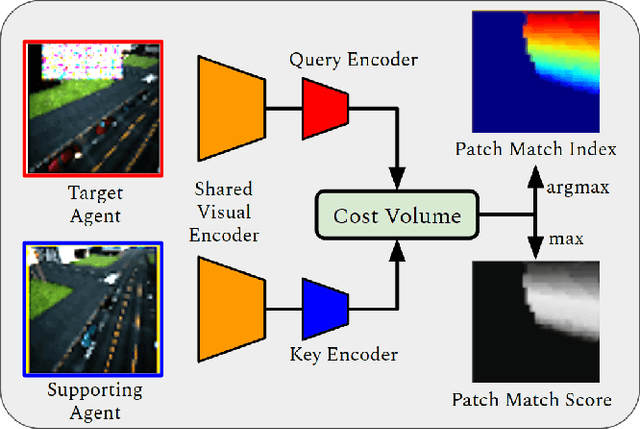
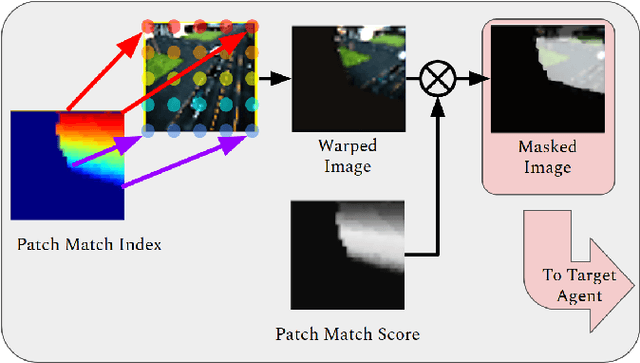
In this paper, we address bandwidth-limited and obstruction-prone collaborative perception, specifically in the context of multi-agent semantic segmentation. This setting presents several key challenges, including processing and exchanging unregistered robotic swarm imagery. To be successful, solutions must effectively leverage multiple non-static and intermittently-overlapping RGB perspectives, while heeding bandwidth constraints and overcoming unwanted foreground obstructions. As such, we propose an end-to-end learn-able Multi-Agent Spatial Handshaking network (MASH) to process, compress, and propagate visual information across a robotic swarm. Our distributed communication module operates directly (and exclusively) on raw image data, without additional input requirements such as pose, depth, or warping data. We demonstrate superior performance of our model compared against several baselines in a photo-realistic multi-robot AirSim environment, especially in the presence of image occlusions. Our method achieves an absolute 11% IoU improvement over strong baselines.