 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgephoto style transfer
Papers and Code
CariGANs: Unpaired Photo-to-Caricature Translation
Nov 02, 2018
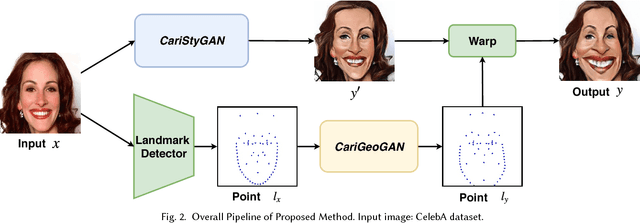
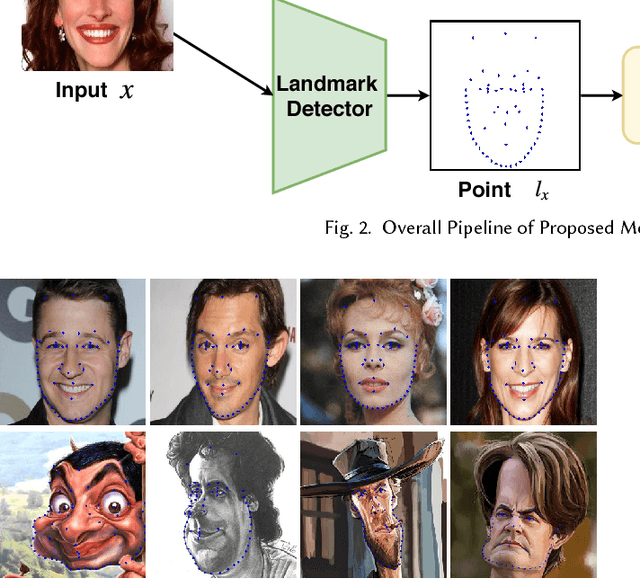
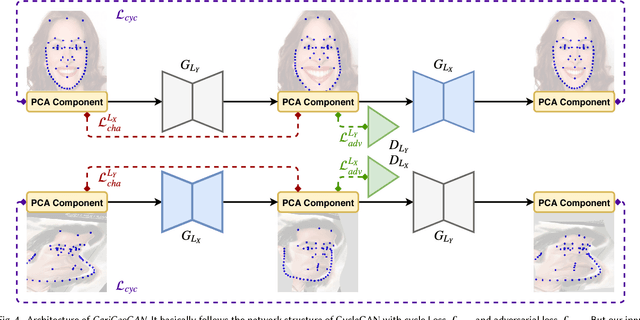
Facial caricature is an art form of drawing faces in an exaggerated way to convey humor or sarcasm. In this paper, we propose the first Generative Adversarial Network (GAN) for unpaired photo-to-caricature translation, which we call "CariGANs". It explicitly models geometric exaggeration and appearance stylization using two components: CariGeoGAN, which only models the geometry-to-geometry transformation from face photos to caricatures, and CariStyGAN, which transfers the style appearance from caricatures to face photos without any geometry deformation. In this way, a difficult cross-domain translation problem is decoupled into two easier tasks. The perceptual study shows that caricatures generated by our CariGANs are closer to the hand-drawn ones, and at the same time better persevere the identity, compared to state-of-the-art methods. Moreover, our CariGANs allow users to control the shape exaggeration degree and change the color/texture style by tuning the parameters or giving an example caricature.
* To appear at SIGGRAPH Asia 2018
Face-to-Parameter Translation for Game Character Auto-Creation
Sep 03, 2019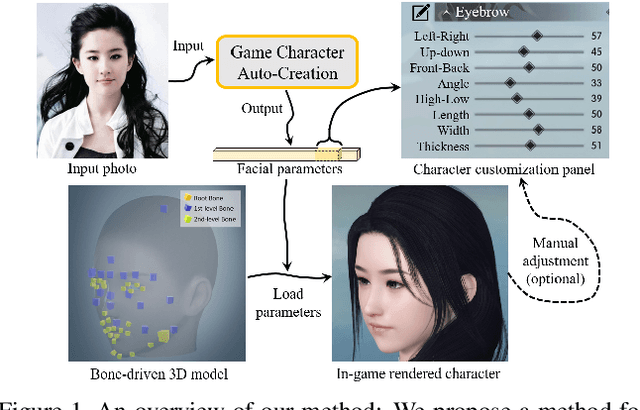

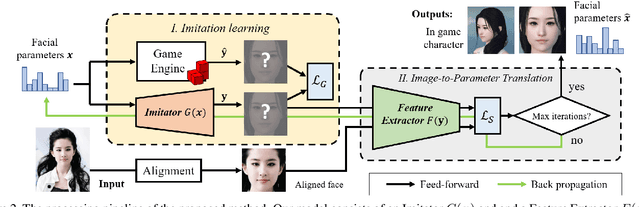

Character customization system is an important component in Role-Playing Games (RPGs), where players are allowed to edit the facial appearance of their in-game characters with their own preferences rather than using default templates. This paper proposes a method for automatically creating in-game characters of players according to an input face photo. We formulate the above "artistic creation" process under a facial similarity measurement and parameter searching paradigm by solving an optimization problem over a large set of physically meaningful facial parameters. To effectively minimize the distance between the created face and the real one, two loss functions, i.e. a "discriminative loss" and a "facial content loss", are specifically designed. As the rendering process of a game engine is not differentiable, a generative network is further introduced as an "imitator" to imitate the physical behavior of the game engine so that the proposed method can be implemented under a neural style transfer framework and the parameters can be optimized by gradient descent. Experimental results demonstrate that our method achieves a high degree of generation similarity between the input face photo and the created in-game character in terms of both global appearance and local details. Our method has been deployed in a new game last year and has now been used by players over 1 million times.
Automated Testing for Deep Learning Systems with Differential Behavior Criteria
Dec 31, 2019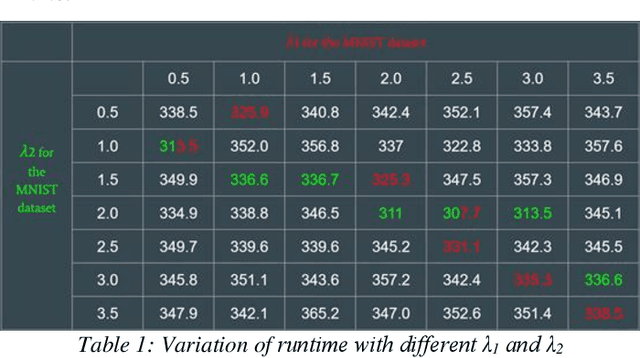

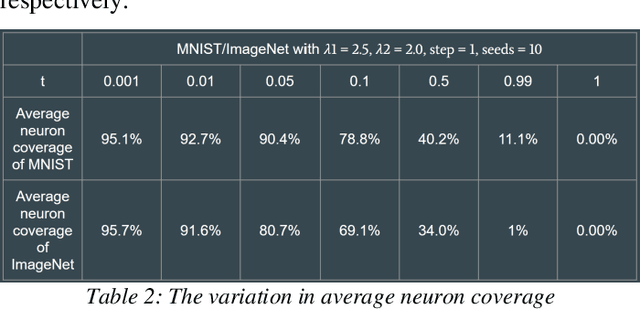
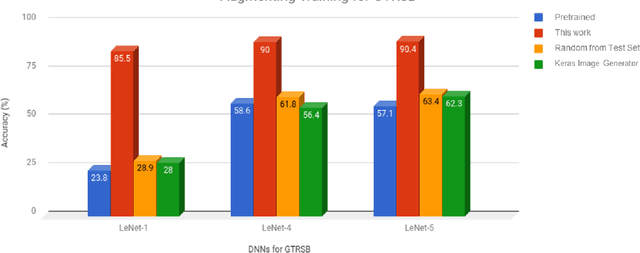
In this work, we conducted a study on building an automated testing system for deep learning systems based on differential behavior criteria. The automated testing goals were achieved by jointly optimizing two objective functions: maximizing differential behaviors from models under testing and maximizing neuron coverage. By observing differential behaviors from three pre-trained models during each testing iteration, the input image that triggered erroneous feedback was registered as a corner-case. The generated corner-cases can be used to examine the robustness of DNNs and consequently improve model accuracy. A project called DeepXplore was also used as a baseline model. After we fully implemented and optimized the baseline system, we explored its application as an augmenting training dataset with newly generated corner cases. With the GTRSB dataset, by retraining the model based on automated generated corner cases, the accuracy of three generic models increased by 259.2%, 53.6%, and 58.3%, respectively. Further, to extend the capability of automated testing, we explored other approaches based on differential behavior criteria to generate photo-realistic images for deep learning systems. One approach was to apply various transformations to the seed images for the deep learning framework. The other approach was to utilize the Generative Adversarial Networks (GAN) technique, which was implemented on MNIST and Driving datasets. The style transferring capability has been observed very effective in adding additional visual effects, replacing image elements, and style-shifting (virtual image to real images). The GAN-based testing sample generation system was shown to be the next frontier for automated testing for deep learning systems.
Weakly-supervised Caricature Face Parsing through Domain Adaptation
May 13, 2019

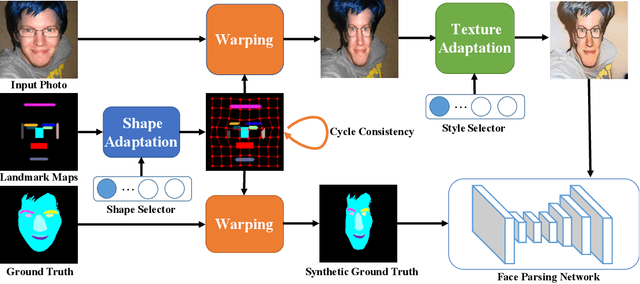

A caricature is an artistic form of a person's picture in which certain striking characteristics are abstracted or exaggerated in order to create a humor or sarcasm effect. For numerous caricature related applications such as attribute recognition and caricature editing, face parsing is an essential pre-processing step that provides a complete facial structure understanding. However, current state-of-the-art face parsing methods require large amounts of labeled data on the pixel-level and such process for caricature is tedious and labor-intensive. For real photos, there are numerous labeled datasets for face parsing. Thus, we formulate caricature face parsing as a domain adaptation problem, where real photos play the role of the source domain, adapting to the target caricatures. Specifically, we first leverage a spatial transformer based network to enable shape domain shifts. A feed-forward style transfer network is then utilized to capture texture-level domain gaps. With these two steps, we synthesize face caricatures from real photos, and thus we can use parsing ground truths of the original photos to learn the parsing model. Experimental results on the synthetic and real caricatures demonstrate the effectiveness of the proposed domain adaptation algorithm. Code is available at: https://github.com/ZJULearning/CariFaceParsing .
Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks
Aug 30, 2018
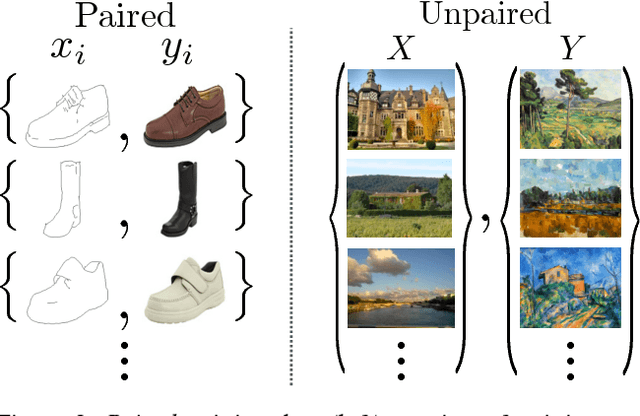
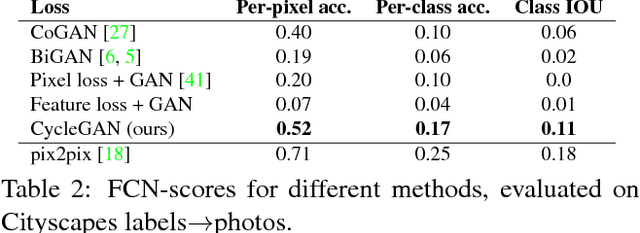
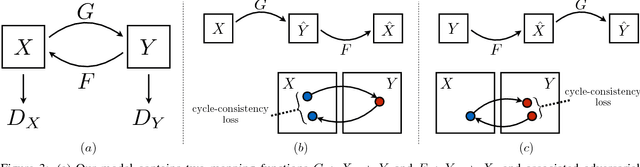
Image-to-image translation is a class of vision and graphics problems where the goal is to learn the mapping between an input image and an output image using a training set of aligned image pairs. However, for many tasks, paired training data will not be available. We present an approach for learning to translate an image from a source domain $X$ to a target domain $Y$ in the absence of paired examples. Our goal is to learn a mapping $G: X \rightarrow Y$ such that the distribution of images from $G(X)$ is indistinguishable from the distribution $Y$ using an adversarial loss. Because this mapping is highly under-constrained, we couple it with an inverse mapping $F: Y \rightarrow X$ and introduce a cycle consistency loss to push $F(G(X)) \approx X$ (and vice versa). Qualitative results are presented on several tasks where paired training data does not exist, including collection style transfer, object transfiguration, season transfer, photo enhancement, etc. Quantitative comparisons against several prior methods demonstrate the superiority of our approach.
Recognizing Instagram Filtered Images with Feature De-stylization
Dec 30, 2019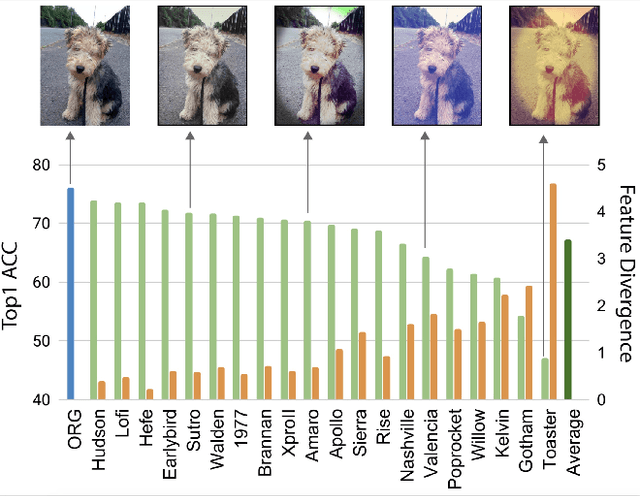


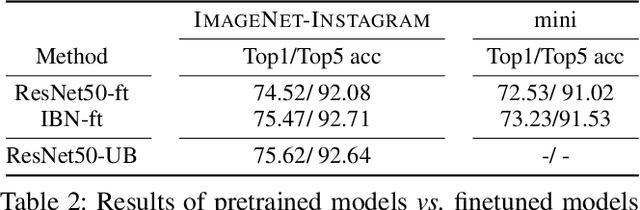
Deep neural networks have been shown to suffer from poor generalization when small perturbations are added (like Gaussian noise), yet little work has been done to evaluate their robustness to more natural image transformations like photo filters. This paper presents a study on how popular pretrained models are affected by commonly used Instagram filters. To this end, we introduce ImageNet-Instagram, a filtered version of ImageNet, where 20 popular Instagram filters are applied to each image in ImageNet. Our analysis suggests that simple structure preserving filters which only alter the global appearance of an image can lead to large differences in the convolutional feature space. To improve generalization, we introduce a lightweight de-stylization module that predicts parameters used for scaling and shifting feature maps to "undo" the changes incurred by filters, inverting the process of style transfer tasks. We further demonstrate the module can be readily plugged into modern CNN architectures together with skip connections. We conduct extensive studies on ImageNet-Instagram, and show quantitatively and qualitatively, that the proposed module, among other things, can effectively improve generalization by simply learning normalization parameters without retraining the entire network, thus recovering the alterations in the feature space caused by the filters.
Deep Photo Style Transfer
Apr 11, 2017

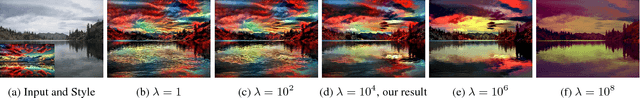

This paper introduces a deep-learning approach to photographic style transfer that handles a large variety of image content while faithfully transferring the reference style. Our approach builds upon the recent work on painterly transfer that separates style from the content of an image by considering different layers of a neural network. However, as is, this approach is not suitable for photorealistic style transfer. Even when both the input and reference images are photographs, the output still exhibits distortions reminiscent of a painting. Our contribution is to constrain the transformation from the input to the output to be locally affine in colorspace, and to express this constraint as a custom fully differentiable energy term. We show that this approach successfully suppresses distortion and yields satisfying photorealistic style transfers in a broad variety of scenarios, including transfer of the time of day, weather, season, and artistic edits.
Neural Abstract Style Transfer for Chinese Traditional Painting
Dec 13, 2018

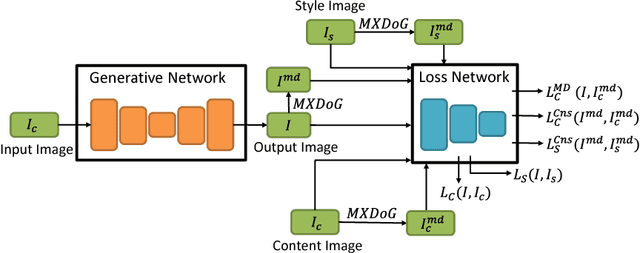

Chinese traditional painting is one of the most historical artworks in the world. It is very popular in Eastern and Southeast Asia due to being aesthetically appealing. Compared with western artistic painting, it is usually more visually abstract and textureless. Recently, neural network based style transfer methods have shown promising and appealing results which are mainly focused on western painting. It remains a challenging problem to preserve abstraction in neural style transfer. In this paper, we present a Neural Abstract Style Transfer method for Chinese traditional painting. It learns to preserve abstraction and other style jointly end-to-end via a novel MXDoG-guided filter (Modified version of the eXtended Difference-of-Gaussians) and three fully differentiable loss terms. To the best of our knowledge, there is little work study on neural style transfer of Chinese traditional painting. To promote research on this direction, we collect a new dataset with diverse photo-realistic images and Chinese traditional paintings. In experiments, the proposed method shows more appealing stylized results in transferring the style of Chinese traditional painting than state-of-the-art neural style transfer methods.
Sensory Optimization: Neural Networks as a Model for Understanding and Creating Art
Nov 16, 2019

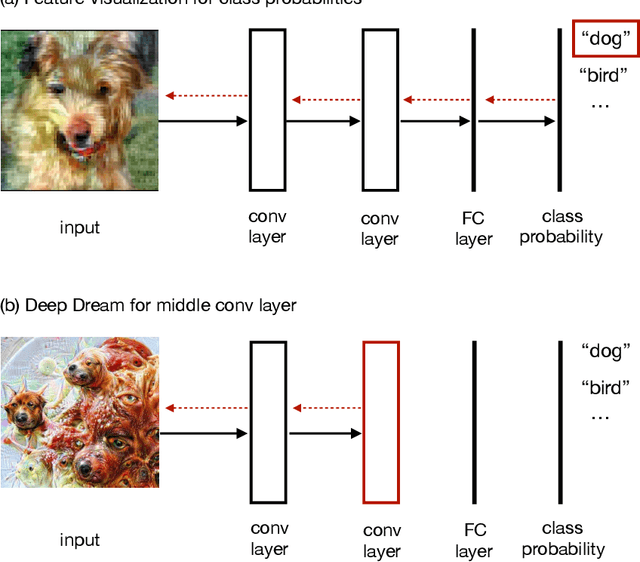
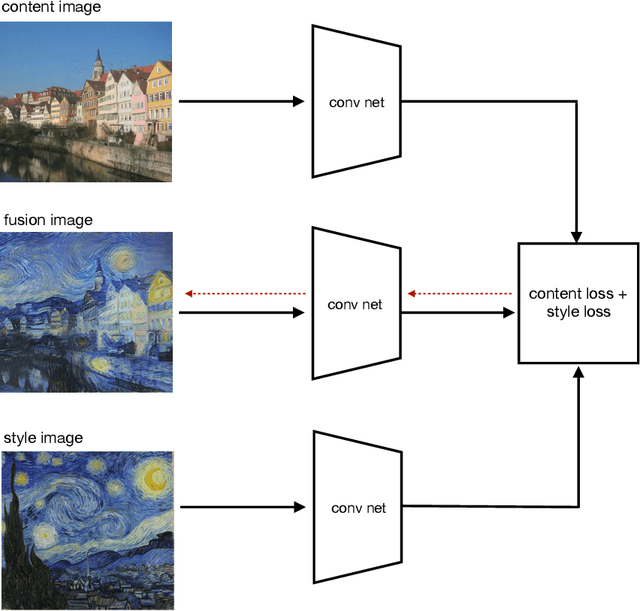
This article is about the cognitive science of visual art. Artists create physical artifacts (such as sculptures or paintings) which depict people, objects, and events. These depictions are usually stylized rather than photo-realistic. How is it that humans are able to understand and create stylized representations? Does this ability depend on general cognitive capacities or an evolutionary adaptation for art? What role is played by learning and culture? Machine Learning can shed light on these questions. It's possible to train convolutional neural networks (CNNs) to recognize objects without training them on any visual art. If such CNNs can generalize to visual art (by creating and understanding stylized representations), then CNNs provide a model for how humans could understand art without innate adaptations or cultural learning. I argue that Deep Dream and Style Transfer show that CNNs can create a basic form of visual art, and that humans could create art by similar processes. This suggests that artists make art by optimizing for effects on the human object-recognition system. Physical artifacts are optimized to evoke real-world objects for this system (e.g. to evoke people or landscapes) and to serve as superstimuli for this system.
Fast Universal Style Transfer for Artistic and Photorealistic Rendering
Jul 06, 2019
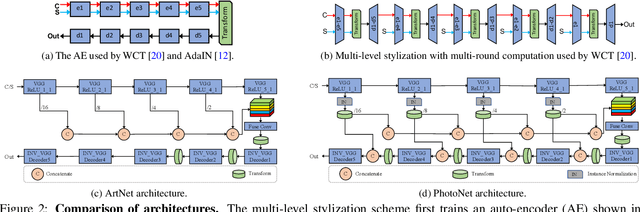
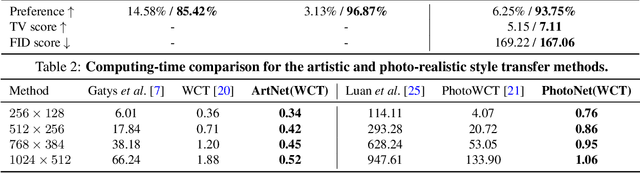

Universal style transfer is an image editing task that renders an input content image using the visual style of arbitrary reference images, including both artistic and photorealistic stylization. Given a pair of images as the source of content and the reference of style, existing solutions usually first train an auto-encoder (AE) to reconstruct the image using deep features and then embeds pre-defined style transfer modules into the AE reconstruction procedure to transfer the style of the reconstructed image through modifying the deep features. While existing methods typically need multiple rounds of time-consuming AE reconstruction for better stylization, our work intends to design novel neural network architectures on top of AE for fast style transfer with fewer artifacts and distortions all in one pass of end-to-end inference. To this end, we propose two network architectures named ArtNet and PhotoNet to improve artistic and photo-realistic stylization, respectively. Extensive experiments demonstrate that ArtNet generates images with fewer artifacts and distortions against the state-of-the-art artistic transfer algorithms, while PhotoNet improves the photorealistic stylization results by creating sharp images faithfully preserving rich details of the input content. Moreover, ArtNet and PhotoNet can achieve 3X to 100X speed-up over the state-of-the-art algorithms, which is a major advantage for large content images.