 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Design and Comparison of Reward Functions in Reinforcement Learning for Energy Management of Sensor Nodes
Jun 02, 2021
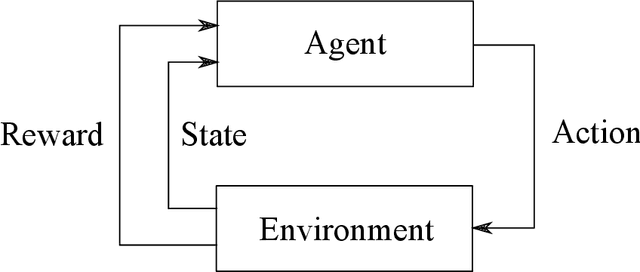
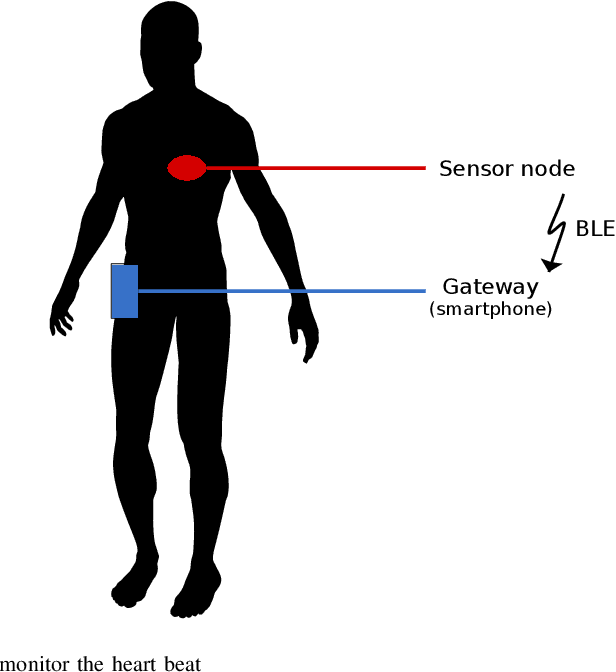
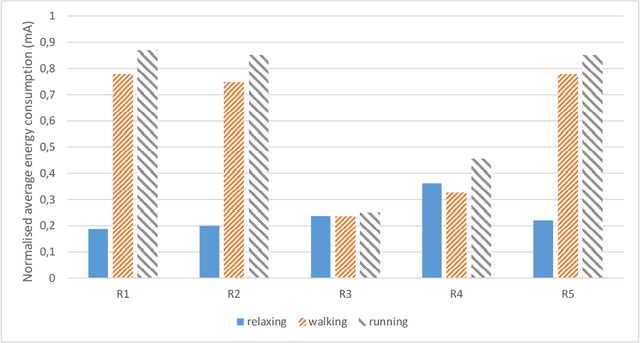
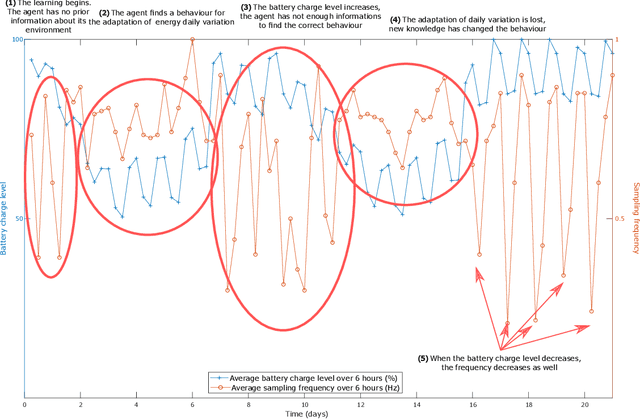
Interest in remote monitoring has grown thanks to recent advancements in Internet-of-Things (IoT) paradigms. New applications have emerged, using small devices called sensor nodes capable of collecting data from the environment and processing it. However, more and more data are processed and transmitted with longer operational periods. At the same, the battery technologies have not improved fast enough to cope with these increasing needs. This makes the energy consumption issue increasingly challenging and thus, miniaturized energy harvesting devices have emerged to complement traditional energy sources. Nevertheless, the harvested energy fluctuates significantly during the node operation, increasing uncertainty in actually available energy resources. Recently, approaches in energy management have been developed, in particular using reinforcement learning approaches. However, in reinforcement learning, the algorithm's performance relies greatly on the reward function. In this paper, we present two contributions. First, we explore five different reward functions to identify the most suitable variables to use in such functions to obtain the desired behaviour. Experiments were conducted using the Q-learning algorithm to adjust the energy consumption depending on the energy harvested. Results with the five reward functions illustrate how the choice thereof impacts the energy consumption of the node. Secondly, we propose two additional reward functions able to find the compromise between energy consumption and a node performance using a non-fixed balancing parameter. Our simulation results show that the proposed reward functions adjust the node's performance depending on the battery level and reduce the learning time.
Fisheye Lens Camera based Autonomous Valet Parking System
Apr 27, 2021



This paper proposes an efficient autonomous valet parking system utilizing only cameras which are the most widely used sensor. To capture more information instantaneously and respond rapidly to changes in the surrounding environment, fisheye cameras which have a wider angle of view compared to pinhole cameras are used. Accordingly, visual simultaneous localization and mapping is used to identify the layout of the parking lot and track the location of the vehicle. In addition, the input image frames are converted into around view monitor images to resolve the distortion of fisheye lens because the algorithm to detect edges are supposed to be applied to images taken with pinhole cameras. The proposed system adopts a look up table for real time operation by minimizing the computational complexity encountered when processing AVM images. The detection rate of each process and the success rate of autonomous parking were measured to evaluate performance. The experimental results confirm that autonomous parking can be achieved using only visual sensors.
One Backward from Ten Forward, Subsampling for Large-Scale Deep Learning
Apr 27, 2021
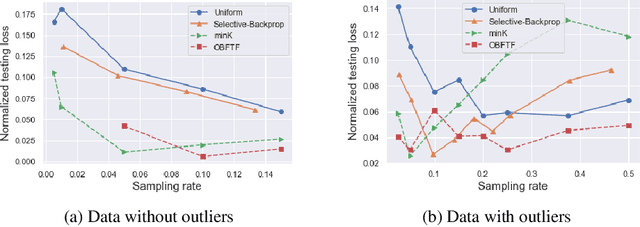

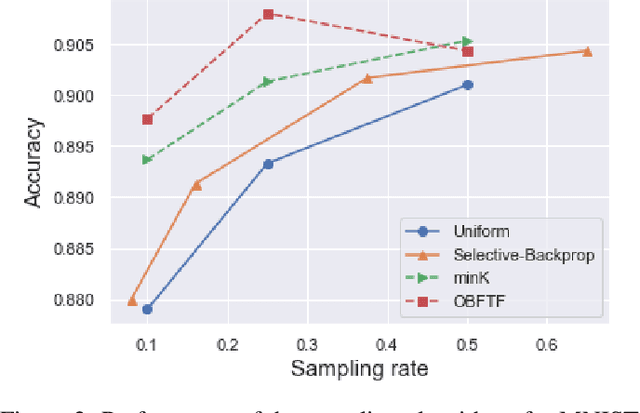
Deep learning models in large-scale machine learning systems are often continuously trained with enormous data from production environments. The sheer volume of streaming training data poses a significant challenge to real-time training subsystems and ad-hoc sampling is the standard practice. Our key insight is that these deployed ML systems continuously perform forward passes on data instances during inference, but ad-hoc sampling does not take advantage of this substantial computational effort. Therefore, we propose to record a constant amount of information per instance from these forward passes. The extra information measurably improves the selection of which data instances should participate in forward and backward passes. A novel optimization framework is proposed to analyze this problem and we provide an efficient approximation algorithm under the framework of Mini-batch gradient descent as a practical solution. We also demonstrate the effectiveness of our framework and algorithm on several large-scale classification and regression tasks, when compared with competitive baselines widely used in industry.
Causally-motivated Shortcut Removal Using Auxiliary Labels
May 13, 2021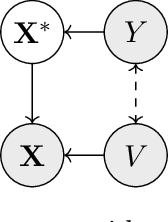

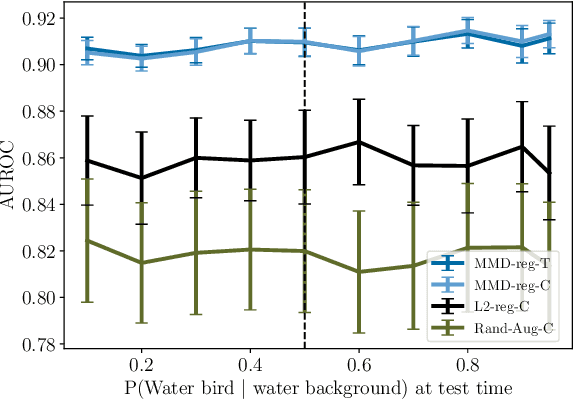
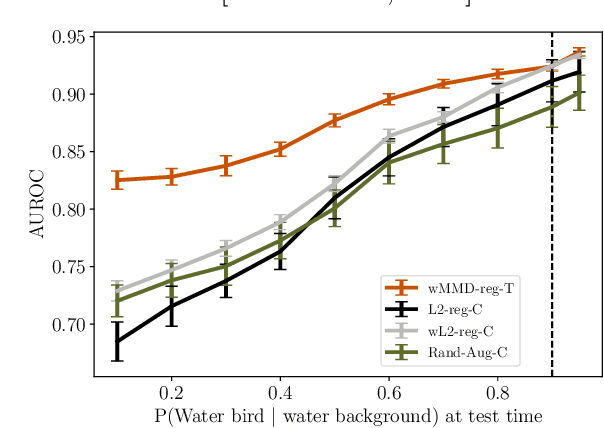
Robustness to certain distribution shifts is a key requirement in many ML applications. Often, relevant distribution shifts can be formulated in terms of interventions on the process that generates the input data. Here, we consider the problem of learning a predictor whose risk across such shifts is invariant. A key challenge to learning such risk-invariant predictors is shortcut learning, or the tendency for models to rely on spurious correlations in practice, even when a predictor based on shift-invariant features could achieve optimal i.i.d generalization in principle. We propose a flexible, causally-motivated approach to address this challenge. Specifically, we propose a regularization scheme that makes use of auxiliary labels for potential shortcut features, which are often available at training time. Drawing on the causal structure of the problem, we enforce a conditional independence between the representation used to predict the main label and the auxiliary labels. We show both theoretically and empirically that this causally-motivated regularization scheme yields robust predictors that generalize well both in-distribution and under distribution shifts, and does so with better sample efficiency than standard regularization or weighting approaches.
Aleatoric uncertainty estimation with test-time augmentation for medical image segmentation with convolutional neural networks
Jul 20, 2018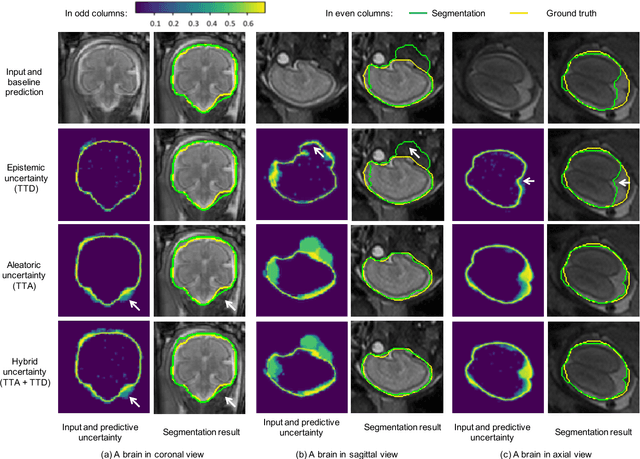
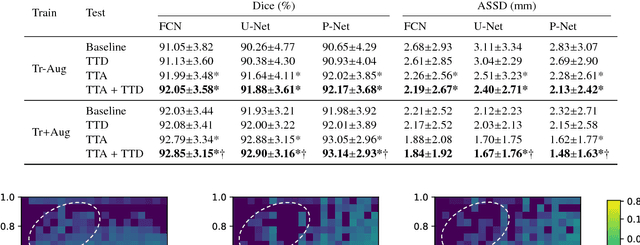
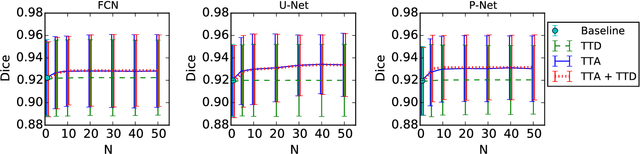
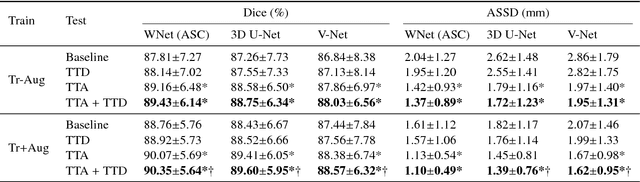
Despite the state-of-the-art performance for medical image segmentation, deep convolutional neural networks (CNNs) have rarely provided uncertainty estimations regarding their segmentation outputs, e.g., model (epistemic) and image-based (aleatoric) uncertainties. In this work, we analyze these different types of uncertainties for CNN-based 2D and 3D medical image segmentation tasks. We additionally propose a test-time augmentation-based aleatoric uncertainty to analyze the effect of different transformations of the input image on the segmentation output. Test-time augmentation has been previously used to improve segmentation accuracy, yet not been formulated in a consistent mathematical framework. Hence, we also propose a theoretical formulation of test-time augmentation, where a distribution of the prediction is estimated by Monte Carlo simulation with prior distributions of parameters in an image acquisition model that involves image transformations and noise. We compare and combine our proposed aleatoric uncertainty with model uncertainty. Experiments with segmentation of fetal brains and brain tumors from 2D and 3D Magnetic Resonance Images (MRI) showed that 1) the test-time augmentation-based aleatoric uncertainty provides a better uncertainty estimation than calculating the test-time dropout-based model uncertainty alone and helps to reduce overconfident incorrect predictions, and 2) our test-time augmentation outperforms a single-prediction baseline and dropout-based multiple predictions.
Policy Learning with Adaptively Collected Data
May 05, 2021

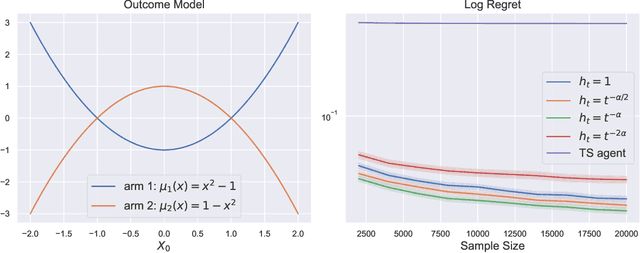

Learning optimal policies from historical data enables the gains from personalization to be realized in a wide variety of applications. The growing policy learning literature focuses on a setting where the treatment assignment policy does not adapt to the data. However, adaptive data collection is becoming more common in practice, from two primary sources: 1) data collected from adaptive experiments that are designed to improve inferential efficiency; 2) data collected from production systems that are adaptively evolving an operational policy to improve performance over time (e.g. contextual bandits). In this paper, we aim to address the challenge of learning the optimal policy with adaptively collected data and provide one of the first theoretical inquiries into this problem. We propose an algorithm based on generalized augmented inverse propensity weighted estimators and establish its finite-sample regret bound. We complement this regret upper bound with a lower bound that characterizes the fundamental difficulty of policy learning with adaptive data. Finally, we demonstrate our algorithm's effectiveness using both synthetic data and public benchmark datasets.
Compressive Sampling Using a Pushframe Camera
Apr 27, 2021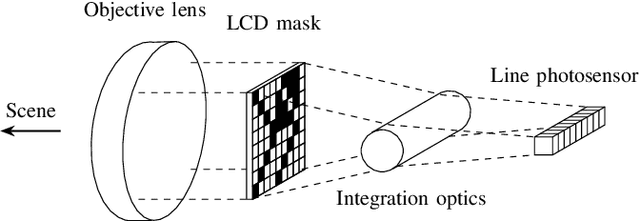

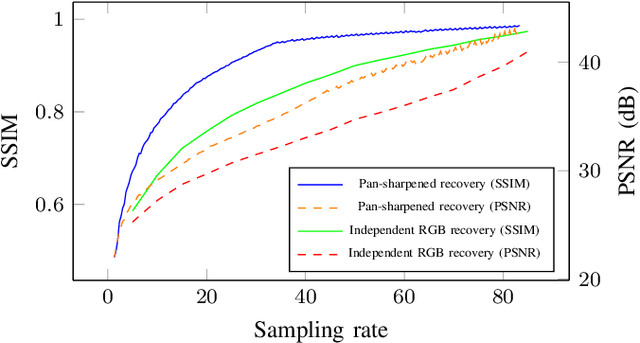
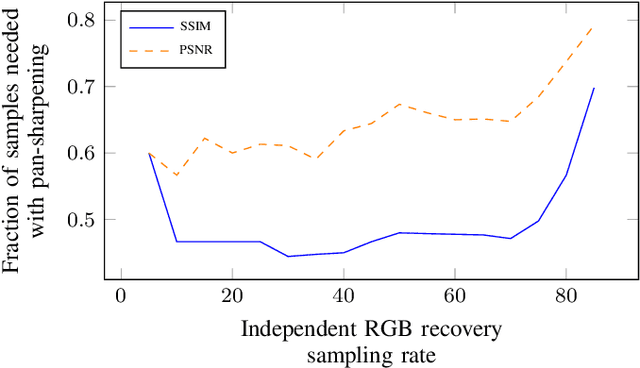
The recently described pushframe imager, a parallelized single pixel camera capturing with a pushbroom-like motion, is intrinsically suited to both remote-sensing and compressive sampling. It optically applies a 2D mask to the imaged scene, before performing light integration along a single spatial axis, but previous work has not made use of the architecture's potential for taking measurements sparsely. In this paper we develop a strongly performing static binarized noiselet compressive sampling mask design, tailored to pushframe hardware, allowing both a single exposure per motion time-step, and retention of 2D correlations in the scene. Results from simulated and real-world captures are presented, with performance shown to be similar to that of immobile -- and hence inappropriate for satellite use -- whole-scene imagers. A particular feature of our sampling approach is that the degree of compression can be varied without altering the pattern, and we demonstrate the utility of this for efficiently storing and transmitting multi-spectral images.
Better Regularization for Sequential Decision Spaces: Fast Convergence Rates for Nash, Correlated, and Team Equilibria
May 27, 2021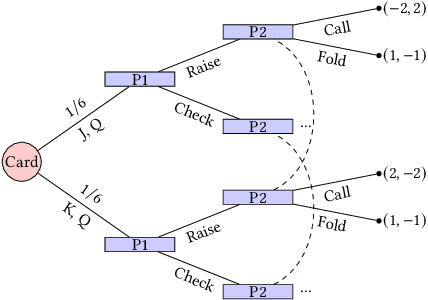
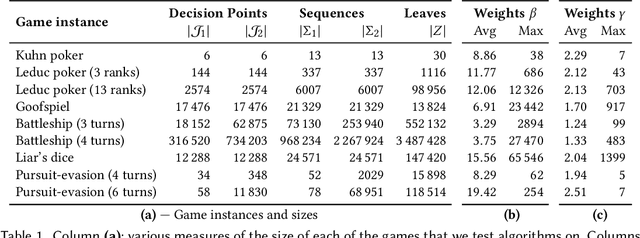
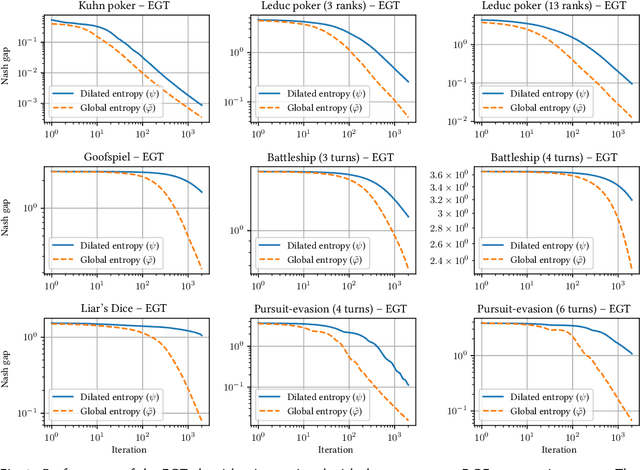
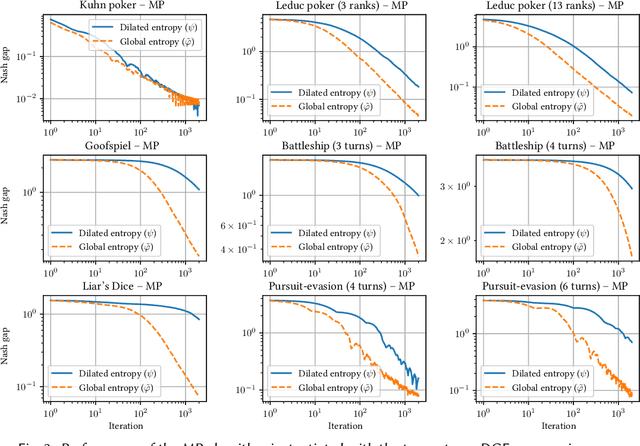
We study the application of iterative first-order methods to the problem of computing equilibria of large-scale two-player extensive-form games. First-order methods must typically be instantiated with a regularizer that serves as a distance-generating function for the decision sets of the players. For the case of two-player zero-sum games, the state-of-the-art theoretical convergence rate for Nash equilibrium is achieved by using the dilated entropy function. In this paper, we introduce a new entropy-based distance-generating function for two-player zero-sum games, and show that this function achieves significantly better strong convexity properties than the dilated entropy, while maintaining the same easily-implemented closed-form proximal mapping. Extensive numerical simulations show that these superior theoretical properties translate into better numerical performance as well. We then generalize our new entropy distance function, as well as general dilated distance functions, to the scaled extension operator. The scaled extension operator is a way to recursively construct convex sets, which generalizes the decision polytope of extensive-form games, as well as the convex polytopes corresponding to correlated and team equilibria. By instantiating first-order methods with our regularizers, we develop the first accelerated first-order methods for computing correlated equilibra and ex-ante coordinated team equilibria. Our methods have a guaranteed $1/T$ rate of convergence, along with linear-time proximal updates.
EiGLasso for Scalable Sparse Kronecker-Sum Inverse Covariance Estimation
May 20, 2021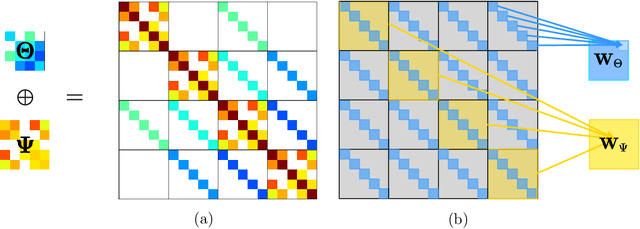
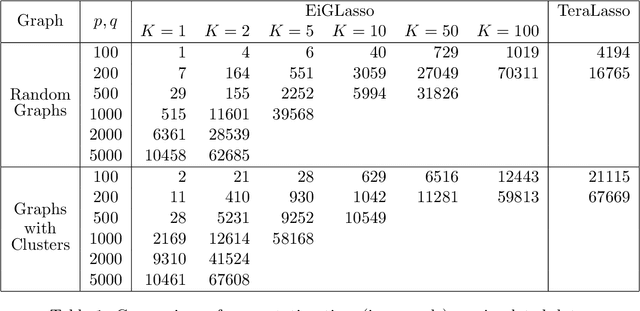
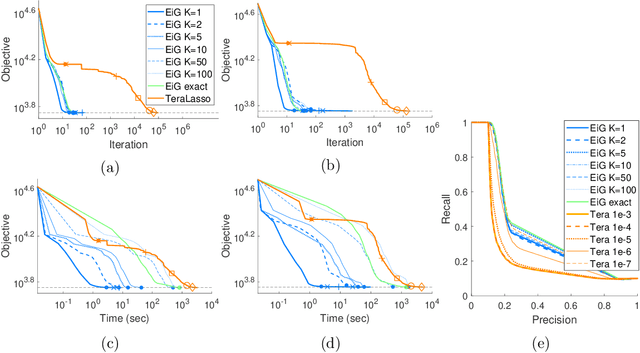
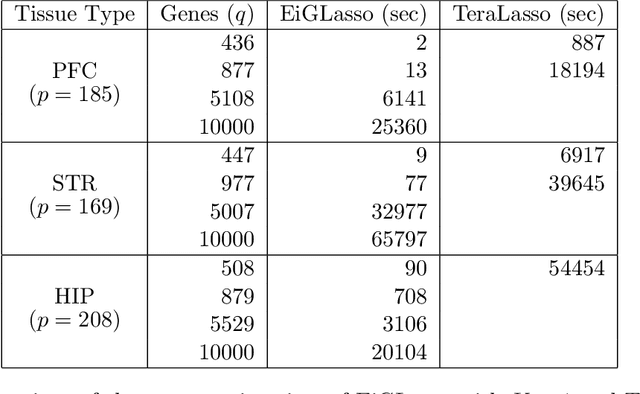
In many real-world problems, complex dependencies are present both among samples and among features. The Kronecker sum or the Cartesian product of two graphs, each modeling dependencies across features and across samples, has been used as an inverse covariance matrix for a matrix-variate Gaussian distribution, as an alternative to a Kronecker-product inverse covariance matrix, due to its more intuitive sparse structure. However, the existing methods for sparse Kronecker-sum inverse covariance estimation are limited in that they do not scale to more than a few hundred features and samples and that the unidentifiable parameters pose challenges in estimation. In this paper, we introduce EiGLasso, a highly scalable method for sparse Kronecker-sum inverse covariance estimation, based on Newton's method combined with eigendecomposition of the two graphs for exploiting the structure of Kronecker sum. EiGLasso further reduces computation time by approximating the Hessian based on the eigendecomposition of the sample and feature graphs. EiGLasso achieves quadratic convergence with the exact Hessian and linear convergence with the approximate Hessian. We describe a simple new approach to estimating the unidentifiable parameters that generalizes the existing methods. On simulated and real-world data, we demonstrate that EiGLasso achieves two to three orders-of-magnitude speed-up compared to the existing methods.
A One-Class Support Vector Machine Calibration Method for Time Series Change Point Detection
Feb 18, 2019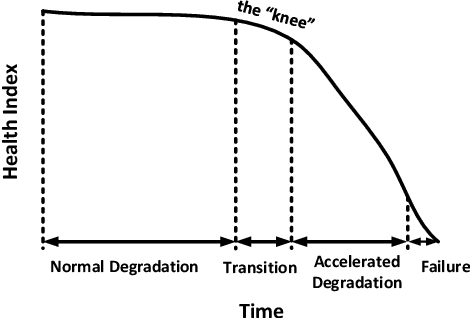
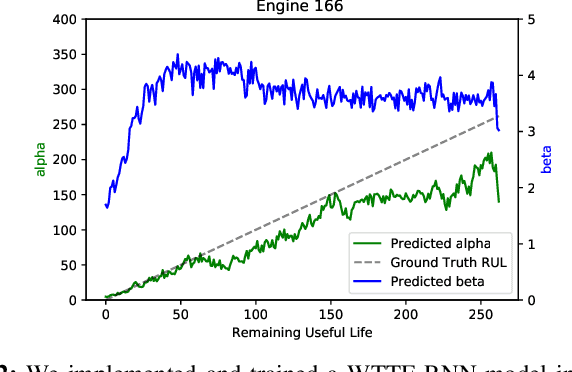
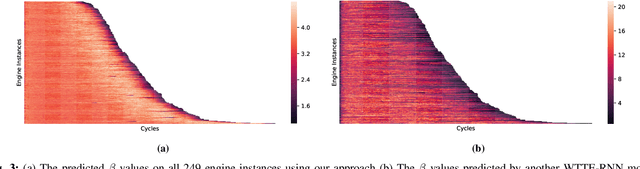
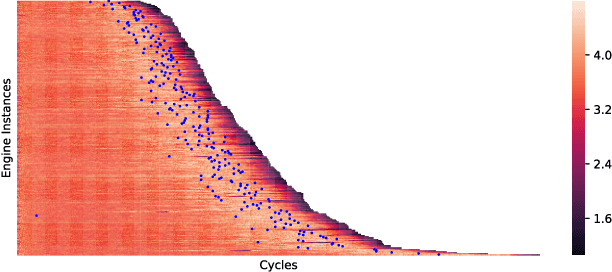
It is important to identify the change point of a system's health status, which usually signifies an incipient fault under development. The One-Class Support Vector Machine (OC-SVM) is a popular machine learning model for anomaly detection and hence could be used for identifying change points; however, it is sometimes difficult to obtain a good OC-SVM model that can be used on sensor measurement time series to identify the change points in system health status. In this paper, we propose a novel approach for calibrating OC-SVM models. The approach uses a heuristic search method to find a good set of input data and hyperparameters that yield a well-performing model. Our results on the C-MAPSS dataset demonstrate that OC-SVM can also achieve satisfactory accuracy in detecting change point in time series with fewer training data, compared to state-of-the-art deep learning approaches. In our case study, the OC-SVM calibrated by the proposed model is shown to be useful especially in scenarios with limited amount of training data.