 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified Causal-Origin Taxonomy of Distributional Shifts in Reinforcement Learning
Jun 15, 2026Reinforcement learning (RL) systems often degrade when operating conditions differ from those previously encountered, reflecting distributional shifts in the underlying data-generating process. Such shifts may occur between training and evaluation, as in In-Distribution (ID) and Out-of-Distribution (OOD) generalization, or within non-stationary settings where environment dynamics evolve over time. However, the formal relationship between these views remains unclear, and existing work mainly focuses on mitigation rather than the causal origin of shift within the agent-environment interaction. This work develops a unified causal-origin taxonomy that characterizes sources of distributional shift in RL and relates ID/OOD generalization to non-stationary settings. We transfer the classical dataset-shift principle from supervised learning to RL by reformulating distributional shift in terms of the generative interaction process. Using a Partially Observable Markov Decision Process (POMDP), we decompose the interaction into structural components, including the state distribution, observation process, policy, reward, and transition dynamics, together with the shifted-time boundary. The proposed taxonomy distinguishes internal, agent-driven, and external, environment-driven, distributional shifts. The shifted-time boundary perspective further characterizes explicit, implicit, and hybrid shifts. This formulation unifies ID/OOD generalization and non-stationarity as structured changes in the underlying process. We also introduce an evaluation framework for measuring shift impact and adaptation through performance degradation and recovery metrics. By grounding distributional shift in the causal-origin structure of RL, this work supports systematic analysis of robustness under distributional shift.
Few and Fewer: Learning Better from Few Examples Using Fewer Base Classes
Jan 29, 2024When training data is scarce, it is common to make use of a feature extractor that has been pre-trained on a large base dataset, either by fine-tuning its parameters on the ``target'' dataset or by directly adopting its representation as features for a simple classifier. Fine-tuning is ineffective for few-shot learning, since the target dataset contains only a handful of examples. However, directly adopting the features without fine-tuning relies on the base and target distributions being similar enough that these features achieve separability and generalization. This paper investigates whether better features for the target dataset can be obtained by training on fewer base classes, seeking to identify a more useful base dataset for a given task.We consider cross-domain few-shot image classification in eight different domains from Meta-Dataset and entertain multiple real-world settings (domain-informed, task-informed and uninformed) where progressively less detail is known about the target task. To our knowledge, this is the first demonstration that fine-tuning on a subset of carefully selected base classes can significantly improve few-shot learning. Our contributions are simple and intuitive methods that can be implemented in any few-shot solution. We also give insights into the conditions in which these solutions are likely to provide a boost in accuracy. We release the code to reproduce all experiments from this paper on GitHub. https://github.com/RafLaf/Few-and-Fewer.git
Design and Comparison of Reward Functions in Reinforcement Learning for Energy Management of Sensor Nodes
Jun 02, 2021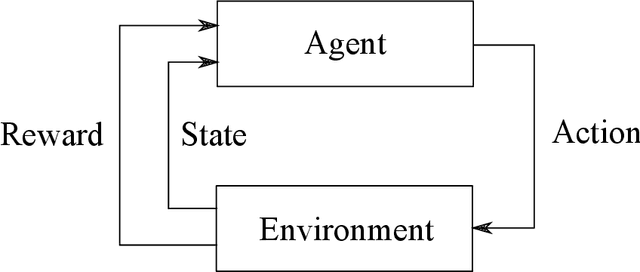
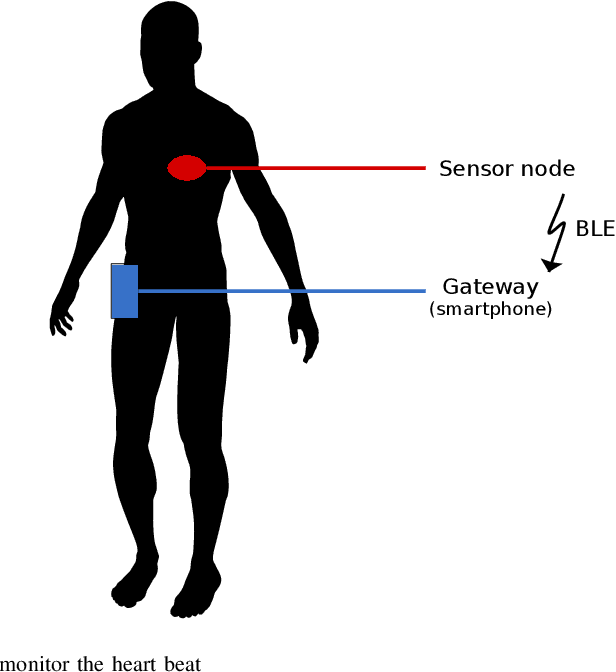
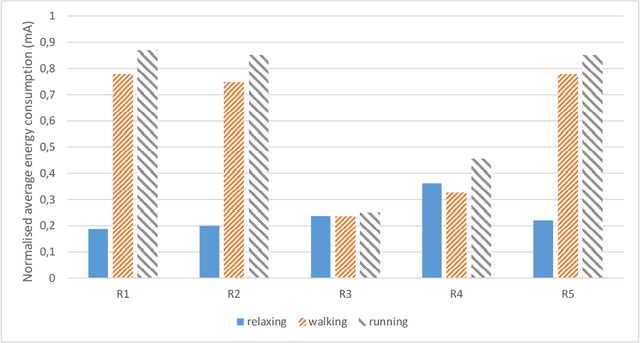
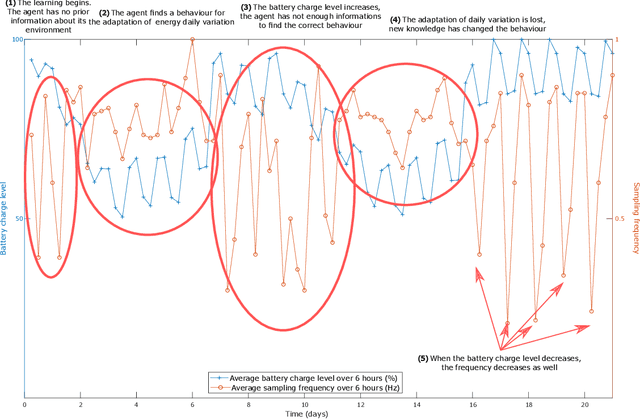
Interest in remote monitoring has grown thanks to recent advancements in Internet-of-Things (IoT) paradigms. New applications have emerged, using small devices called sensor nodes capable of collecting data from the environment and processing it. However, more and more data are processed and transmitted with longer operational periods. At the same, the battery technologies have not improved fast enough to cope with these increasing needs. This makes the energy consumption issue increasingly challenging and thus, miniaturized energy harvesting devices have emerged to complement traditional energy sources. Nevertheless, the harvested energy fluctuates significantly during the node operation, increasing uncertainty in actually available energy resources. Recently, approaches in energy management have been developed, in particular using reinforcement learning approaches. However, in reinforcement learning, the algorithm's performance relies greatly on the reward function. In this paper, we present two contributions. First, we explore five different reward functions to identify the most suitable variables to use in such functions to obtain the desired behaviour. Experiments were conducted using the Q-learning algorithm to adjust the energy consumption depending on the energy harvested. Results with the five reward functions illustrate how the choice thereof impacts the energy consumption of the node. Secondly, we propose two additional reward functions able to find the compromise between energy consumption and a node performance using a non-fixed balancing parameter. Our simulation results show that the proposed reward functions adjust the node's performance depending on the battery level and reduce the learning time.