 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDraft-and-Prune: Improving the Reliability of Auto-formalization for Logical Reasoning
Mar 18, 2026Auto-formalization (AF) translates natural-language reasoning problems into solver-executable programs, enabling symbolic solvers to perform sound logical deduction. In practice, however, AF pipelines are currently brittle: programs may fail to execute, or execute but encode incorrect semantics. While prior work largely mitigates syntactic failures via repairs based on solver feedback, reducing semantics failures remains a major bottleneck. We propose Draft-and-Prune (D&P), an inference-time framework that improves AF-based logical reasoning via diversity and verification. D&P first drafts multiple natural-language plans and conditions program generation on them. It further prunes executable but contradictory or ambiguous formalizations, and aggregates predictions from surviving paths via majority voting. Across four representative benchmarks (AR-LSAT, ProofWriter, PrOntoQA, LogicalDeduction), D&P substantially strengthens AF-based reasoning without extra supervision. On AR-LSAT, in the AF-only setting, D&P achieves 78.43% accuracy with GPT-4 and 78.00% accuracy with GPT-4o, significantly outperforming the strongest AF baselines MAD-LOGIC and CLOVER. D&P then attains near-ceiling performance on the other benchmarks, including 100% on PrOntoQA and LogicalDeduction.
ScenicRules: An Autonomous Driving Benchmark with Multi-Objective Specifications and Abstract Scenarios
Feb 17, 2026Developing autonomous driving systems for complex traffic environments requires balancing multiple objectives, such as avoiding collisions, obeying traffic rules, and making efficient progress. In many situations, these objectives cannot be satisfied simultaneously, and explicit priority relations naturally arise. Also, driving rules require context, so it is important to formally model the environment scenarios within which such rules apply. Existing benchmarks for evaluating autonomous vehicles lack such combinations of multi-objective prioritized rules and formal environment models. In this work, we introduce ScenicRules, a benchmark for evaluating autonomous driving systems in stochastic environments under prioritized multi-objective specifications. We first formalize a diverse set of objectives to serve as quantitative evaluation metrics. Next, we design a Hierarchical Rulebook framework that encodes multiple objectives and their priority relations in an interpretable and adaptable manner. We then construct a compact yet representative collection of scenarios spanning diverse driving contexts and near-accident situations, formally modeled in the Scenic language. Experimental results show that our formalized objectives and Hierarchical Rulebooks align well with human driving judgments and that our benchmark effectively exposes agent failures with respect to the prioritized objectives. Our benchmark can be accessed at https://github.com/BerkeleyLearnVerify/ScenicRules/.
Generating Probabilistic Scenario Programs from Natural Language
May 03, 2024


For cyber-physical systems (CPS), including robotics and autonomous vehicles, mass deployment has been hindered by fatal errors that occur when operating in rare events. To replicate rare events such as vehicle crashes, many companies have created logging systems and employed crash reconstruction experts to meticulously recreate these valuable events in simulation. However, in these methods, "what if" questions are not easily formulated and answered. We present ScenarioNL, an AI System for creating scenario programs from natural language. Specifically, we generate these programs from police crash reports. Reports normally contain uncertainty about the exact details of the incidents which we represent through a Probabilistic Programming Language (PPL), Scenic. By using Scenic, we can clearly and concisely represent uncertainty and variation over CPS behaviors, properties, and interactions. We demonstrate how commonplace prompting techniques with the best Large Language Models (LLM) are incapable of reasoning about probabilistic scenario programs and generating code for low-resource languages such as Scenic. Our system is comprised of several LLMs chained together with several kinds of prompting strategies, a compiler, and a simulator. We evaluate our system on publicly available autonomous vehicle crash reports in California from the last five years and share insights into how we generate code that is both semantically meaningful and syntactically correct.
Beating Backdoor Attack at Its Own Game
Aug 04, 2023



Deep neural networks (DNNs) are vulnerable to backdoor attack, which does not affect the network's performance on clean data but would manipulate the network behavior once a trigger pattern is added. Existing defense methods have greatly reduced attack success rate, but their prediction accuracy on clean data still lags behind a clean model by a large margin. Inspired by the stealthiness and effectiveness of backdoor attack, we propose a simple but highly effective defense framework which injects non-adversarial backdoors targeting poisoned samples. Following the general steps in backdoor attack, we detect a small set of suspected samples and then apply a poisoning strategy to them. The non-adversarial backdoor, once triggered, suppresses the attacker's backdoor on poisoned data, but has limited influence on clean data. The defense can be carried out during data preprocessing, without any modification to the standard end-to-end training pipeline. We conduct extensive experiments on multiple benchmarks with different architectures and representative attacks. Results demonstrate that our method achieves state-of-the-art defense effectiveness with by far the lowest performance drop on clean data. Considering the surprising defense ability displayed by our framework, we call for more attention to utilizing backdoor for backdoor defense. Code is available at https://github.com/damianliumin/non-adversarial_backdoor.
A Grammar for the Representation of Unmanned Aerial Vehicles with 3D Topologies
Feb 27, 2023
We propose a context-sensitive grammar for the systematic exploration of the design space of the topology of 3D robots, particularly unmanned aerial vehicles. It defines production rules for adding components to an incomplete design topology modeled over a 3D grid. The rules are local. The grammar is simple, yet capable of modeling most existing UAVs as well as novel ones. It can be easily generalized to other robotic platforms. It can be thought of as a building block for any design exploration and optimization algorithm.
Contract-Based Specification Refinement and Repair for Mission Planning
Nov 21, 2022

We address the problem of modeling, refining, and repairing formal specifications for robotic missions using assume-guarantee contracts. We show how to model mission specifications at various levels of abstraction and implement them using a library of pre-implemented specifications. Suppose the specification cannot be met using components from the library. In that case, we compute a proxy for the best approximation to the specification that can be generated using elements from the library. Afterward, we propose a systematic way to either 1) search for and refine the `missing part' of the specification that the library cannot meet or 2) repair the current specification such that the existing library can refine it. Our methodology for searching and repairing mission requirements leverages the quotient, separation, composition, and merging operations between contracts.
Querying Labelled Data with Scenario Programs for Sim-to-Real Validation
Dec 01, 2021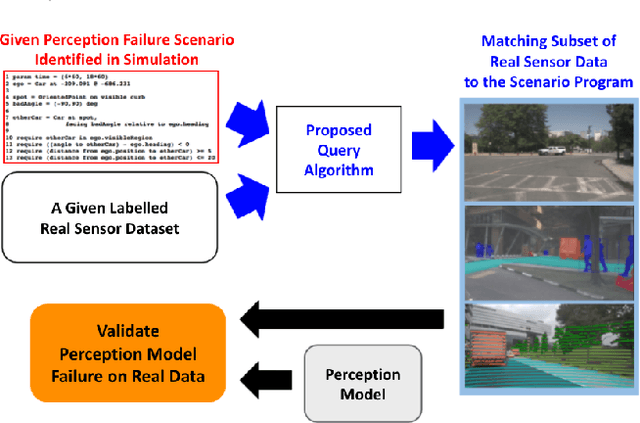

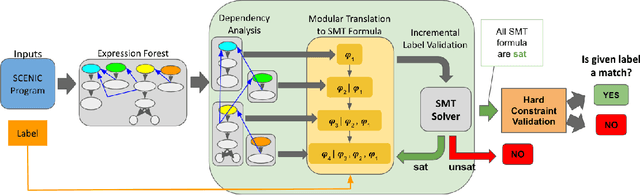
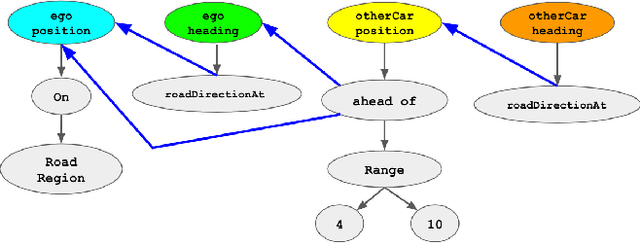
Simulation-based testing of autonomous vehicles (AVs) has become an essential complement to road testing to ensure safety. Consequently, substantial research has focused on searching for failure scenarios in simulation. However, a fundamental question remains: are AV failure scenarios identified in simulation meaningful in reality, i.e., are they reproducible on the real system? Due to the sim-to-real gap arising from discrepancies between simulated and real sensor data, a failure scenario identified in simulation can be either a spurious artifact of the synthetic sensor data or an actual failure that persists with real sensor data. An approach to validate simulated failure scenarios is to identify instances of the scenario in a corpus of real data, and check if the failure persists on the real data. To this end, we propose a formal definition of what it means for a labelled data item to match an abstract scenario, encoded as a scenario program using the SCENIC probabilistic programming language. Using this definition, we develop a querying algorithm which, given a scenario program and a labelled dataset, finds the subset of data matching the scenario. Experiments demonstrate that our algorithm is accurate and efficient on a variety of realistic traffic scenarios, and scales to a reasonable number of agents.
Class-wise Thresholding for Detecting Out-of-Distribution Data
Nov 24, 2021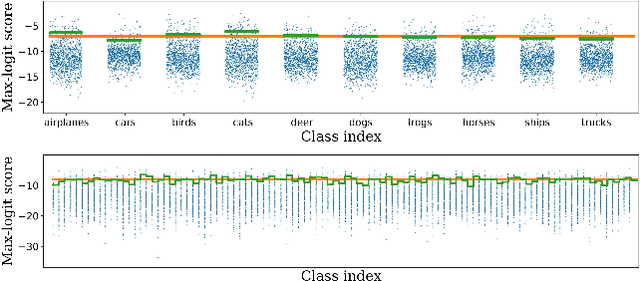

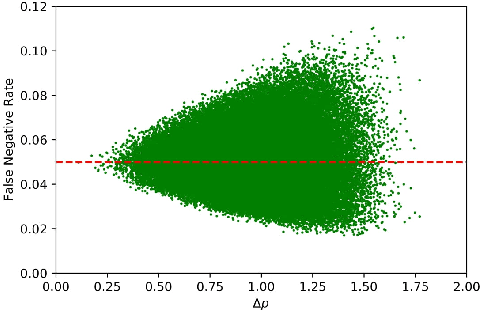
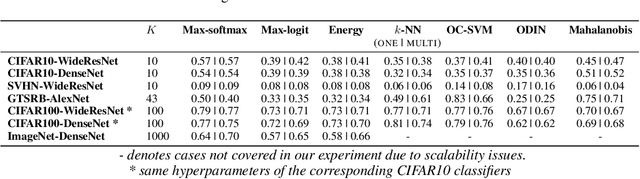
We consider the problem of detecting OoD(Out-of-Distribution) input data when using deep neural networks, and we propose a simple yet effective way to improve the robustness of several popular OoD detection methods against label shift. Our work is motivated by the observation that most existing OoD detection algorithms consider all training/test data as a whole, regardless of which class entry each input activates (inter-class differences). Through extensive experimentation, we have found that such practice leads to a detector whose performance is sensitive and vulnerable to label shift. To address this issue, we propose a class-wise thresholding scheme that can apply to most existing OoD detection algorithms and can maintain similar OoD detection performance even in the presence of label shift in the test distribution.
Conditional Synthetic Data Generation for Robust Machine Learning Applications with Limited Pandemic Data
Sep 14, 2021

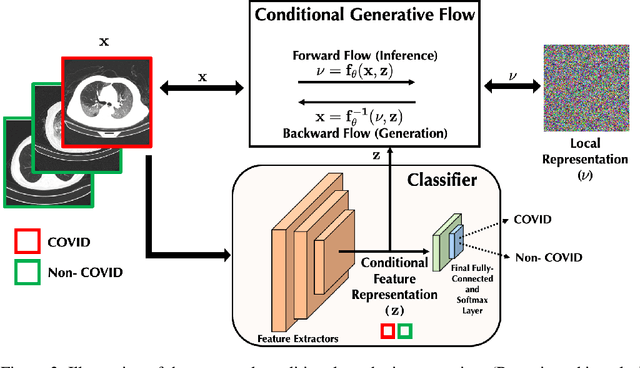
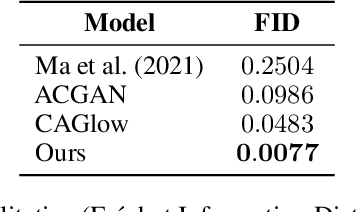
$\textbf{Background:}$ At the onset of a pandemic, such as COVID-19, data with proper labeling/attributes corresponding to the new disease might be unavailable or sparse. Machine Learning (ML) models trained with the available data, which is limited in quantity and poor in diversity, will often be biased and inaccurate. At the same time, ML algorithms designed to fight pandemics must have good performance and be developed in a time-sensitive manner. To tackle the challenges of limited data, and label scarcity in the available data, we propose generating conditional synthetic data, to be used alongside real data for developing robust ML models. $\textbf{Methods:}$ We present a hybrid model consisting of a conditional generative flow and a classifier for conditional synthetic data generation. The classifier decouples the feature representation for the condition, which is fed to the flow to extract the local noise. We generate synthetic data by manipulating the local noise with fixed conditional feature representation. We also propose a semi-supervised approach to generate synthetic samples in the absence of labels for a majority of the available data. $\textbf{Results:}$ We performed conditional synthetic generation for chest computed tomography (CT) scans corresponding to normal, COVID-19, and pneumonia afflicted patients. We show that our method significantly outperforms existing models both on qualitative and quantitative performance, and our semi-supervised approach can efficiently synthesize conditional samples under label scarcity. As an example of downstream use of synthetic data, we show improvement in COVID-19 detection from CT scans with conditional synthetic data augmentation.
A Hierarchical State-Machine-Based Framework for Platoon Manoeuvre Descriptions
Apr 12, 2021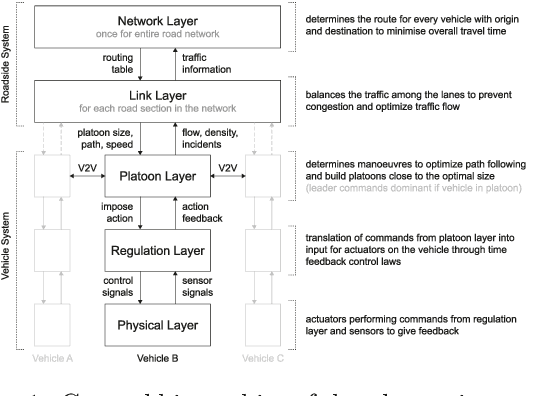
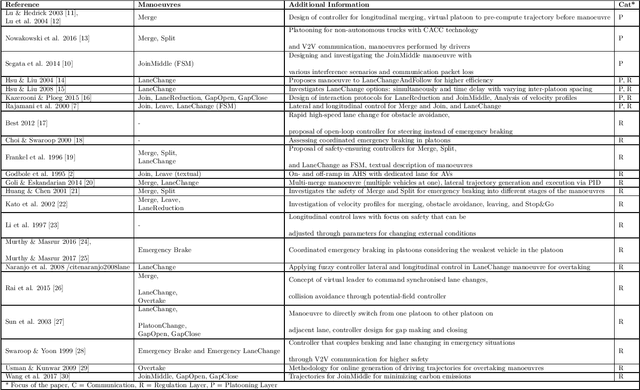
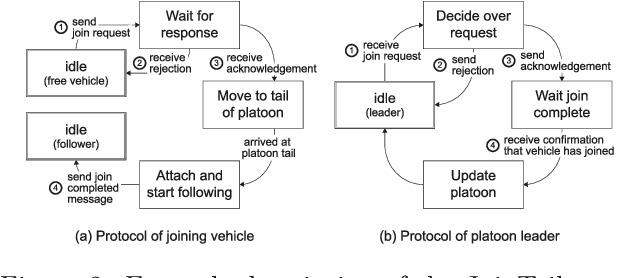
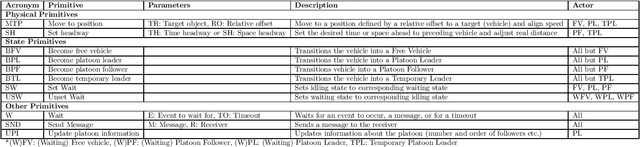
This paper introduces the SEAD framework that simplifies the process of designing and describing autonomous vehicle platooning manoeuvres. Although a large body of research has been formulating platooning manoeuvres, it is still challenging to design, describe, read, and understand them. This difficulty largely arises from missing formalisation. To fill this gap, we analysed existing ways of describing manoeuvres, derived the causes of difficulty, and designed a framework that simplifies the manoeuvre design process. Alongside, a Manoeuvre Design Language was developed to structurally describe manoeuvres in a machine-readable format. Unlike state-of-the-art manoeuvre descriptions that require one state machine for every participating vehicle, the SEAD framework allows describing any manoeuvre from the single perspective of the platoon leader. %As a proof of concept, the proposed framework was implemented in the mixed traffic simulation environment BEHAVE for an autonomous highway scenario. Using this framework, we implemented several manoeuvres as they were described in literature. To demonstrate the applicability of the framework, an experiment was performed to evaluate the execution time performance of multiple alternatives of the Join-Middle manoeuvre. This proof-of-concept experiment revealed that the manoeuvre execution time can be reduced by 28 \% through parallelising various steps without considerable secondary effects. We hope that the SEAD framework will pave the way for further research in the area of new manoeuvre design and optimisation by largely simplifying and unifying platooning manoeuvre representation.