 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Machine Learning Is Not a Panacea: A Roadmap for Observational Causal Inference in Health
May 20, 2026Objective: The growing availability of large-scale observational clinical datasets and challenges in conducting randomized controlled trials have spurred enthusiasm in using causal machine learning (ML) for causal inference in observational data. We present a roadmap for applying causal ML to observational data. Materials and methods: We outline the importance of assessing validity assumptions within available data and applying causal ML responsibly for clinical experts using causal ML and ML practitioners with limited clinical expertise. Observations: Despite advances in causal ML, its limitations remain largely under-appreciated across disciplines. This gap in shared knowledge may impact the validity of findings. Discussion: Causal assumptions must be satisfied and modeling choices justified. Otherwise, these approaches risk producing biased or misleading results, with consequences for clinical research and patient care. Conclusion: Causal ML can be a powerful tool for generating causal hypotheses. We provide a template to strengthen the rigor and interpretability of causal analyses.
Estimating Misreporting in the Presence of Genuine Modification: A Causal Perspective
May 29, 2025



In settings where ML models are used to inform the allocation of resources, agents affected by the allocation decisions might have an incentive to strategically change their features to secure better outcomes. While prior work has studied strategic responses broadly, disentangling misreporting from genuine modification remains a fundamental challenge. In this paper, we propose a causally-motivated approach to identify and quantify how much an agent misreports on average by distinguishing deceptive changes in their features from genuine modification. Our key insight is that, unlike genuine modification, misreported features do not causally affect downstream variables (i.e., causal descendants). We exploit this asymmetry by comparing the causal effect of misreported features on their causal descendants as derived from manipulated datasets against those from unmanipulated datasets. We formally prove identifiability of the misreporting rate and characterize the variance of our estimator. We empirically validate our theoretical results using a semi-synthetic and real Medicare dataset with misreported data, demonstrating that our approach can be employed to identify misreporting in real-world scenarios.
Who's Gaming the System? A Causally-Motivated Approach for Detecting Strategic Adaptation
Dec 02, 2024



In many settings, machine learning models may be used to inform decisions that impact individuals or entities who interact with the model. Such entities, or agents, may game model decisions by manipulating their inputs to the model to obtain better outcomes and maximize some utility. We consider a multi-agent setting where the goal is to identify the "worst offenders:" agents that are gaming most aggressively. However, identifying such agents is difficult without knowledge of their utility function. Thus, we introduce a framework in which each agent's tendency to game is parameterized via a scalar. We show that this gaming parameter is only partially identifiable. By recasting the problem as a causal effect estimation problem where different agents represent different "treatments," we prove that a ranking of all agents by their gaming parameters is identifiable. We present empirical results in a synthetic data study validating the usage of causal effect estimation for gaming detection and show in a case study of diagnosis coding behavior in the U.S. that our approach highlights features associated with gaming.
Hypothesis Testing the Circuit Hypothesis in LLMs
Oct 16, 2024Large language models (LLMs) demonstrate surprising capabilities, but we do not understand how they are implemented. One hypothesis suggests that these capabilities are primarily executed by small subnetworks within the LLM, known as circuits. But how can we evaluate this hypothesis? In this paper, we formalize a set of criteria that a circuit is hypothesized to meet and develop a suite of hypothesis tests to evaluate how well circuits satisfy them. The criteria focus on the extent to which the LLM's behavior is preserved, the degree of localization of this behavior, and whether the circuit is minimal. We apply these tests to six circuits described in the research literature. We find that synthetic circuits -- circuits that are hard-coded in the model -- align with the idealized properties. Circuits discovered in Transformer models satisfy the criteria to varying degrees. To facilitate future empirical studies of circuits, we created the \textit{circuitry} package, a wrapper around the \textit{TransformerLens} library, which abstracts away lower-level manipulations of hooks and activations. The software is available at \url{https://github.com/blei-lab/circuitry}.
Partial identification of kernel based two sample tests with mismeasured data
Aug 07, 2023Nonparametric two-sample tests such as the Maximum Mean Discrepancy (MMD) are often used to detect differences between two distributions in machine learning applications. However, the majority of existing literature assumes that error-free samples from the two distributions of interest are available.We relax this assumption and study the estimation of the MMD under $\epsilon$-contamination, where a possibly non-random $\epsilon$ proportion of one distribution is erroneously grouped with the other. We show that under $\epsilon$-contamination, the typical estimate of the MMD is unreliable. Instead, we study partial identification of the MMD, and characterize sharp upper and lower bounds that contain the true, unknown MMD. We propose a method to estimate these bounds, and show that it gives estimates that converge to the sharpest possible bounds on the MMD as sample size increases, with a convergence rate that is faster than alternative approaches. Using three datasets, we empirically validate that our approach is superior to the alternatives: it gives tight bounds with a low false coverage rate.
Multi-Similarity Contrastive Learning
Jul 06, 2023Given a similarity metric, contrastive methods learn a representation in which examples that are similar are pushed together and examples that are dissimilar are pulled apart. Contrastive learning techniques have been utilized extensively to learn representations for tasks ranging from image classification to caption generation. However, existing contrastive learning approaches can fail to generalize because they do not take into account the possibility of different similarity relations. In this paper, we propose a novel multi-similarity contrastive loss (MSCon), that learns generalizable embeddings by jointly utilizing supervision from multiple metrics of similarity. Our method automatically learns contrastive similarity weightings based on the uncertainty in the corresponding similarity, down-weighting uncertain tasks and leading to better out-of-domain generalization to new tasks. We show empirically that networks trained with MSCon outperform state-of-the-art baselines on in-domain and out-of-domain settings.
Leveraging Factored Action Spaces for Efficient Offline Reinforcement Learning in Healthcare
May 02, 2023Many reinforcement learning (RL) applications have combinatorial action spaces, where each action is a composition of sub-actions. A standard RL approach ignores this inherent factorization structure, resulting in a potential failure to make meaningful inferences about rarely observed sub-action combinations; this is particularly problematic for offline settings, where data may be limited. In this work, we propose a form of linear Q-function decomposition induced by factored action spaces. We study the theoretical properties of our approach, identifying scenarios where it is guaranteed to lead to zero bias when used to approximate the Q-function. Outside the regimes with theoretical guarantees, we show that our approach can still be useful because it leads to better sample efficiency without necessarily sacrificing policy optimality, allowing us to achieve a better bias-variance trade-off. Across several offline RL problems using simulators and real-world datasets motivated by healthcare, we demonstrate that incorporating factored action spaces into value-based RL can result in better-performing policies. Our approach can help an agent make more accurate inferences within underexplored regions of the state-action space when applying RL to observational datasets.
Fairness and robustness in anti-causal prediction
Sep 20, 2022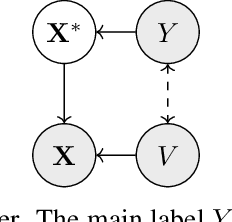
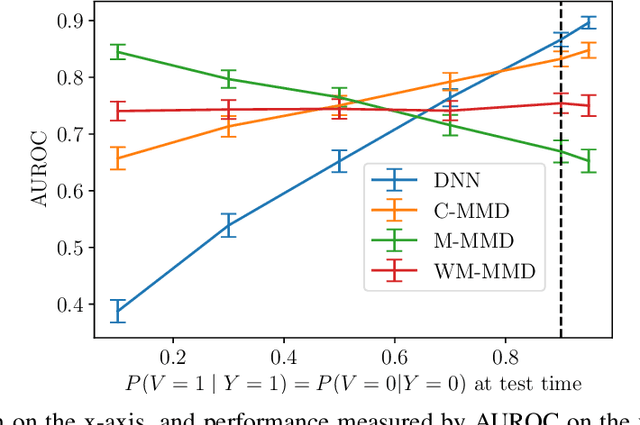
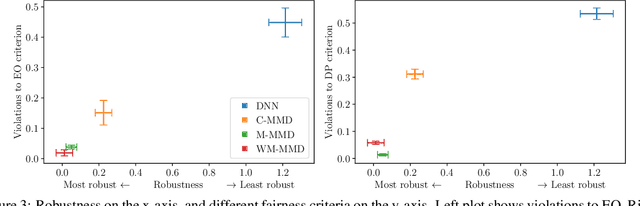
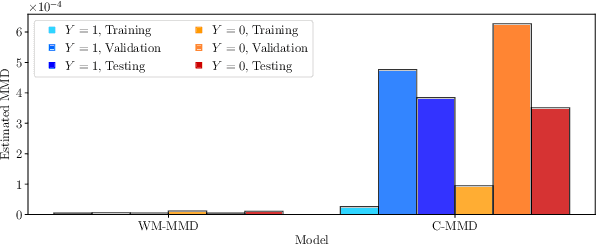
Robustness to distribution shift and fairness have independently emerged as two important desiderata required of modern machine learning models. While these two desiderata seem related, the connection between them is often unclear in practice. Here, we discuss these connections through a causal lens, focusing on anti-causal prediction tasks, where the input to a classifier (e.g., an image) is assumed to be generated as a function of the target label and the protected attribute. By taking this perspective, we draw explicit connections between a common fairness criterion - separation - and a common notion of robustness - risk invariance. These connections provide new motivation for applying the separation criterion in anticausal settings, and inform old discussions regarding fairness-performance tradeoffs. In addition, our findings suggest that robustness-motivated approaches can be used to enforce separation, and that they often work better in practice than methods designed to directly enforce separation. Using a medical dataset, we empirically validate our findings on the task of detecting pneumonia from X-rays, in a setting where differences in prevalence across sex groups motivates a fairness mitigation. Our findings highlight the importance of considering causal structure when choosing and enforcing fairness criteria.
Causally-motivated Shortcut Removal Using Auxiliary Labels
Jun 03, 2021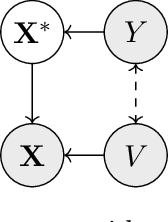

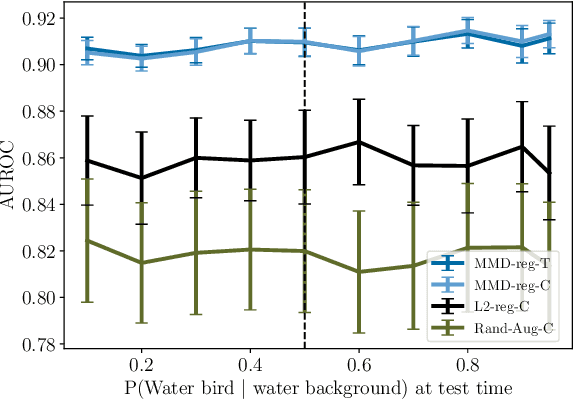
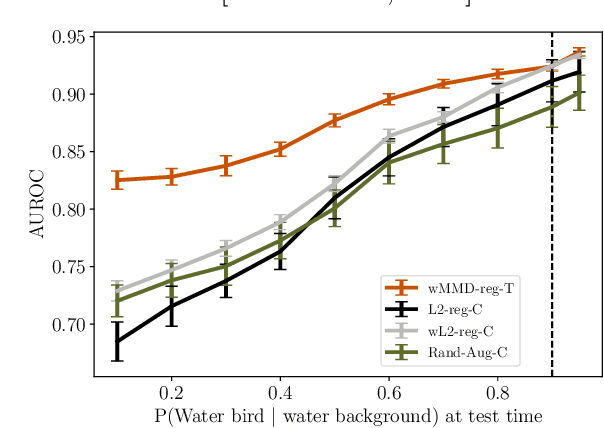
Robustness to certain forms of distribution shift is a key concern in many ML applications. Often, robustness can be formulated as enforcing invariances to particular interventions on the data generating process. Here, we study a flexible, causally-motivated approach to enforcing such invariances, paying special attention to shortcut learning, where a robust predictor can achieve optimal i.i.d generalization in principle, but instead it relies on spurious correlations or shortcuts in practice. Our approach uses auxiliary labels, typically available at training time, to enforce conditional independences between the latent factors that determine these labels. We show both theoretically and empirically that causally-motivated regularization schemes (a) lead to more robust estimators that generalize well under distribution shift, and (b) have better finite sample efficiency compared to usual regularization schemes, even in the absence of distribution shifts. Our analysis highlights important theoretical properties of training techniques commonly used in causal inference, fairness, and disentanglement literature.
Estimation of Utility-Maximizing Bounds on Potential Outcomes
Oct 10, 2019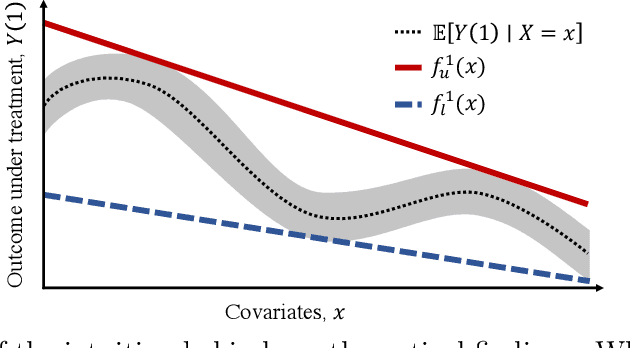
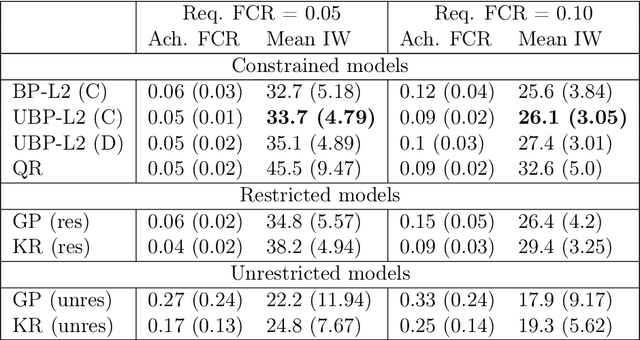
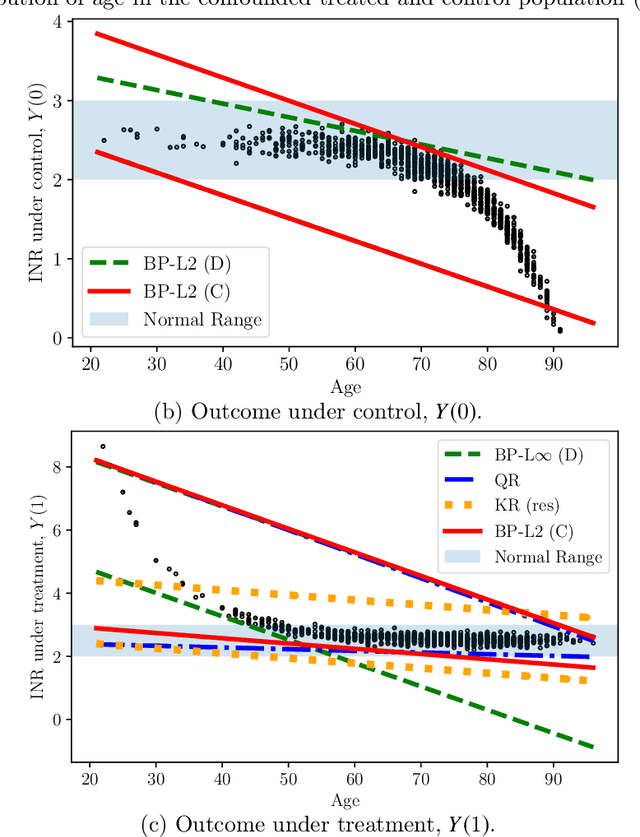
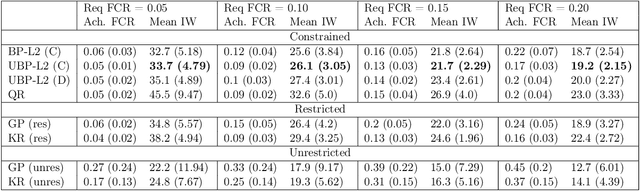
Estimation of individual treatment effects is often used as the basis for contextual decision making in fields such as healthcare, education, and economics. However, in many real-world applications it is sufficient for the decision maker to have upper and lower bounds on the potential outcomes of decision alternatives, allowing them to evaluate the trade-off between benefit and risk. With this in mind, we develop an algorithm for directly learning upper and lower bounds on the potential outcomes under treatment and non-treatment. Our theoretical analysis highlights a trade-off between the complexity of the learning task and the confidence with which the resulting bounds cover the true potential outcomes; the more confident we wish to be, the more complex the learning task is. We suggest a novel algorithm that maximizes a utility function while maintaining valid potential outcome bounds. We illustrate different properties of our algorithm, and highlight how it can be used to guide decision making using two semi-simulated datasets.