 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMembership Inference for Contrastive Pre-training Models with Text-only PII Queries
Mar 15, 2026Contrastive pretraining models such as CLIP and CLAP underpin many vision-language and audio-language systems, yet their reliance on web-scale data raises growing concerns about memorizing Personally Identifiable Information (PII). Auditing such models via membership inference is challenging in practice: shadow-model MIAs are computationally prohibitive for large multimodal backbones, and existing multimodal attacks typically require querying the target with paired biometric inputs, thereby directly exposing sensitive biometric information to the target model. We propose Unimodal Membership Inference Detector (UMID), a text-only auditing framework that performs text-guided cross-modal latent inversion and extracts two complementary signals, similarity (alignment to the queried text) and variability (consistency across randomized inversions). UMID compares these statistics to a lightweight non-member reference constructed from synthetic gibberish and makes decisions via an ensemble of unsupervised anomaly detectors. Comprehensive experiments across diverse CLIP and CLAP architectures demonstrate that UMID significantly improves the effectiveness and efficiency over prior MIAs, delivering strong detection performance with sub-second auditing cost while complying with realistic privacy constraints.
EcoAlign: An Economically Rational Framework for Efficient LVLM Alignment
Nov 14, 2025Large Vision-Language Models (LVLMs) exhibit powerful reasoning capabilities but suffer sophisticated jailbreak vulnerabilities. Fundamentally, aligning LVLMs is not just a safety challenge but a problem of economic efficiency. Current alignment methods struggle with the trade-off between safety, utility, and operational costs. Critically, a focus solely on final outputs (process-blindness) wastes significant computational budget on unsafe deliberation. This flaw allows harmful reasoning to be disguised with benign justifications, thereby circumventing simple additive safety scores. To address this, we propose EcoAlign, an inference-time framework that reframes alignment as an economically rational search by treating the LVLM as a boundedly rational agent. EcoAlign incrementally expands a thought graph and scores actions using a forward-looking function (analogous to net present value) that dynamically weighs expected safety, utility, and cost against the remaining budget. To prevent deception, path safety is enforced via the weakest-link principle. Extensive experiments across 3 closed-source and 2 open-source models on 6 datasets show that EcoAlign matches or surpasses state-of-the-art safety and utility at a lower computational cost, thereby offering a principled, economical pathway to robust LVLM alignment.
Re-localization acceleration with Medoid Silhouette Clustering
Jul 30, 2024Two crucial performance criteria for the deployment of visual localization are speed and accuracy. Current research on visual localization with neural networks is limited to examining methods for enhancing the accuracy of networks across various datasets. How to expedite the re-localization process within deep neural network architectures still needs further investigation. In this paper, we present a novel approach for accelerating visual re-localization in practice. A tree-like search strategy, built on the keyframes extracted by a visual clustering algorithm, is designed for matching acceleration. Our method has been validated on two tasks across three public datasets, allowing for 50 up to 90 percent time saving over the baseline while not reducing location accuracy.
Keep the Cost Down: A Review on Methods to Optimize LLM' s KV-Cache Consumption
Jul 28, 2024



Large Language Models (LLMs), epitomized by ChatGPT' s release in late 2022, have revolutionized various industries with their advanced language comprehension. However, their efficiency is challenged by the Transformer architecture' s struggle with handling long texts. KV-Cache has emerged as a pivotal solution to this issue, converting the time complexity of token generation from quadratic to linear, albeit with increased GPU memory overhead proportional to conversation length. With the development of the LLM community and academia, various KV-Cache compression methods have been proposed. In this review, we dissect the various properties of KV-Cache and elaborate on various methods currently used to optimize the KV-Cache space usage of LLMs. These methods span the pre-training phase, deployment phase, and inference phase, and we summarize the commonalities and differences among these methods. Additionally, we list some metrics for evaluating the long-text capabilities of large language models, from both efficiency and capability perspectives. Our review thus sheds light on the evolving landscape of LLM optimization, offering insights into future advancements in this dynamic field.
EdgeFL: A Lightweight Decentralized Federated Learning Framework
Sep 06, 2023



Federated Learning (FL) has emerged as a promising approach for collaborative machine learning, addressing data privacy concerns. However, existing FL platforms and frameworks often present challenges for software engineers in terms of complexity, limited customization options, and scalability limitations. In this paper, we introduce EdgeFL, an edge-only lightweight decentralized FL framework, designed to overcome the limitations of centralized aggregation and scalability in FL deployments. By adopting an edge-only model training and aggregation approach, EdgeFL eliminates the need for a central server, enabling seamless scalability across diverse use cases. With a straightforward integration process requiring just four lines of code (LOC), software engineers can easily incorporate FL functionalities into their AI products. Furthermore, EdgeFL offers the flexibility to customize aggregation functions, empowering engineers to adapt them to specific needs. Based on the results, we demonstrate that EdgeFL achieves superior performance compared to existing FL platforms/frameworks. Our results show that EdgeFL reduces weights update latency and enables faster model evolution, enhancing the efficiency of edge devices. Moreover, EdgeFL exhibits improved classification accuracy compared to traditional centralized FL approaches. By leveraging EdgeFL, software engineers can harness the benefits of federated learning while overcoming the challenges associated with existing FL platforms/frameworks.
5G Network on Wings: A Deep Reinforcement Learning Approach to UAV-based Integrated Access and Backhaul
Feb 07, 2022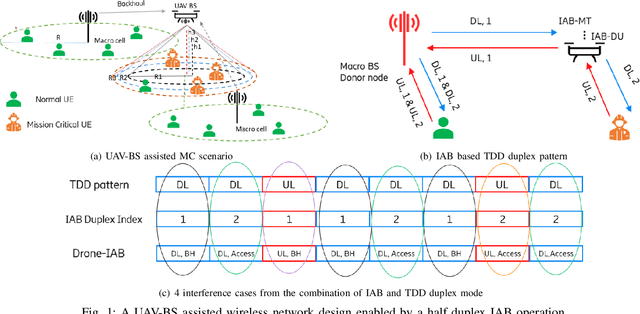
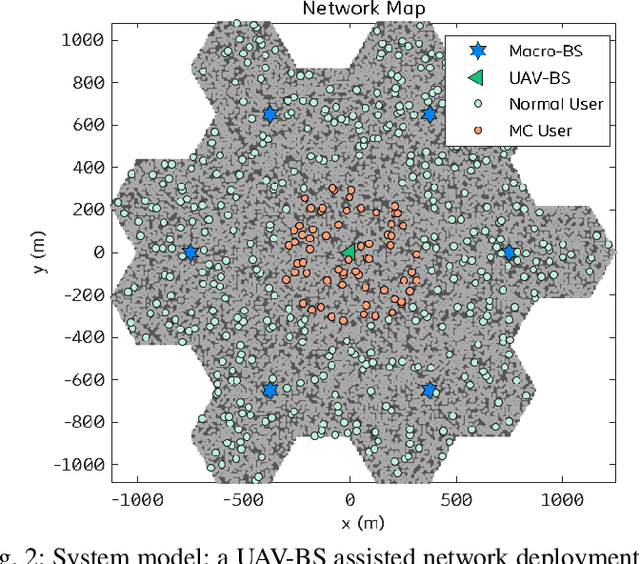
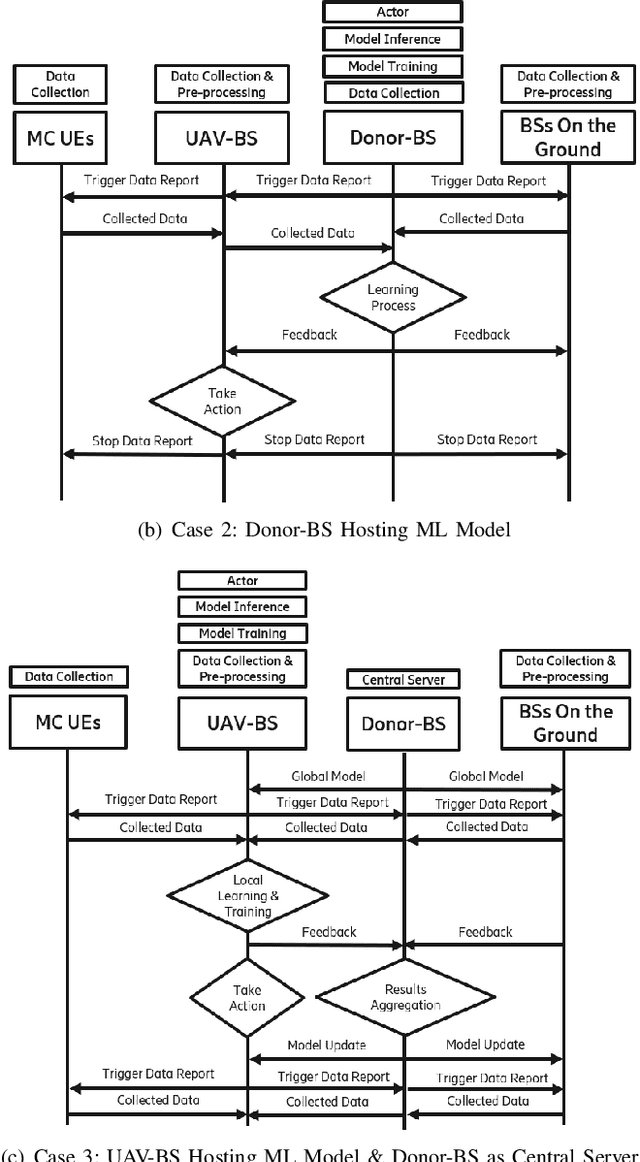
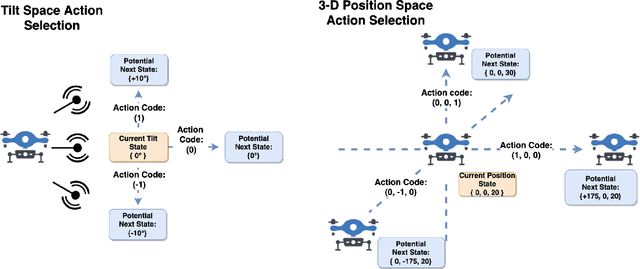
Fast and reliable wireless communication has become a critical demand in human life. When natural disasters strike, providing ubiquitous connectivity becomes challenging by using traditional wireless networks. In this context, unmanned aerial vehicle (UAV) based aerial networks offer a promising alternative for fast, flexible, and reliable wireless communications in mission-critical (MC) scenarios. Due to the unique characteristics such as mobility, flexible deployment, and rapid reconfiguration, drones can readily change location dynamically to provide on-demand communications to users on the ground in emergency scenarios. As a result, the usage of UAV base stations (UAV-BSs) has been considered as an appropriate approach for providing rapid connection in MC scenarios. In this paper, we study how to control a UAV-BS in both static and dynamic environments. We investigate a situation in which a macro BS is destroyed as a result of a natural disaster and a UAV-BS is deployed using integrated access and backhaul (IAB) technology to provide coverage for users in the disaster area. We present a data collection system, signaling procedures and machine learning applications for this use case. A deep reinforcement learning algorithm is developed to jointly optimize the tilt of the access and backhaul antennas of the UAV-BS as well as its three-dimensional placement. Evaluation results show that the proposed algorithm can autonomously navigate and configure the UAV-BS to satisfactorily serve the MC users on the ground.
Autonomous Navigation and Configuration of Integrated Access Backhauling for UAV Base Station Using Reinforcement Learning
Dec 14, 2021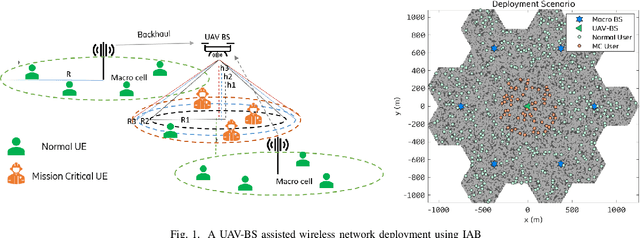
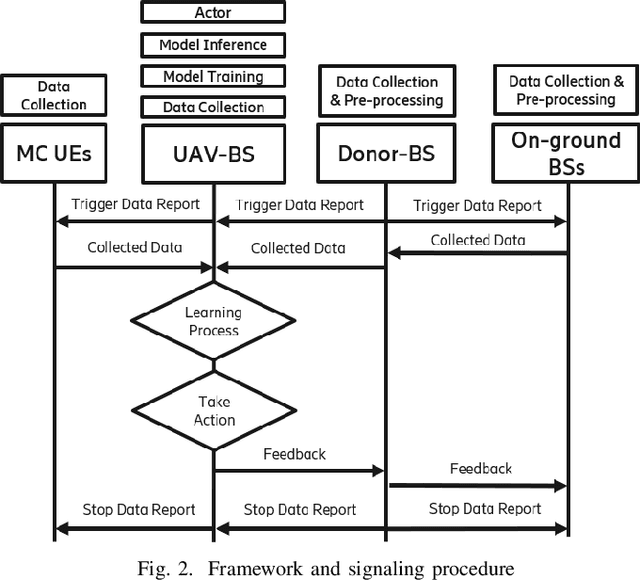
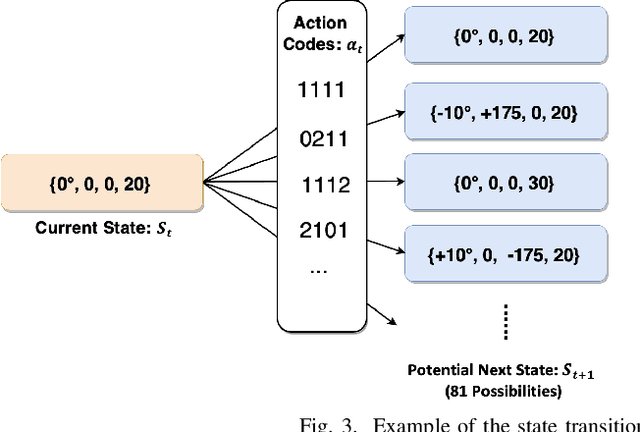
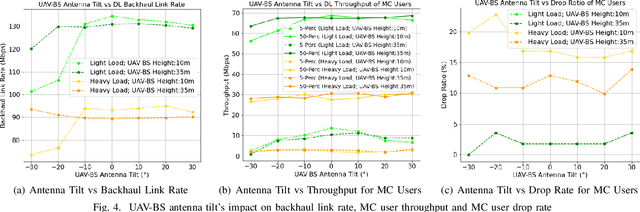
Fast and reliable connectivity is essential to enhancing situational awareness and operational efficiency for public safety mission-critical (MC) users. In emergency or disaster circumstances, where existing cellular network coverage and capacity may not be available to meet MC communication demands, deployable-network-based solutions such as cells-on-wheels/wings can be utilized swiftly to ensure reliable connection for MC users. In this paper, we consider a scenario where a macro base station (BS) is destroyed due to a natural disaster and an unmanned aerial vehicle carrying BS (UAV-BS) is set up to provide temporary coverage for users in the disaster area. The UAV-BS is integrated into the mobile network using the 5G integrated access and backhaul (IAB) technology. We propose a framework and signalling procedure for applying machine learning to this use case. A deep reinforcement learning algorithm is designed to jointly optimize the access and backhaul antenna tilt as well as the three-dimensional location of the UAV-BS in order to best serve the on-ground MC users while maintaining a good backhaul connection. Our result shows that the proposed algorithm can autonomously navigate and configure the UAV-BS to improve the throughput and reduce the drop rate of MC users.
Context-Aware Legal Citation Recommendation using Deep Learning
Jun 20, 2021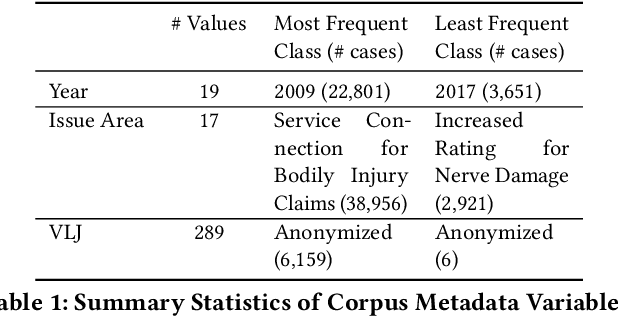
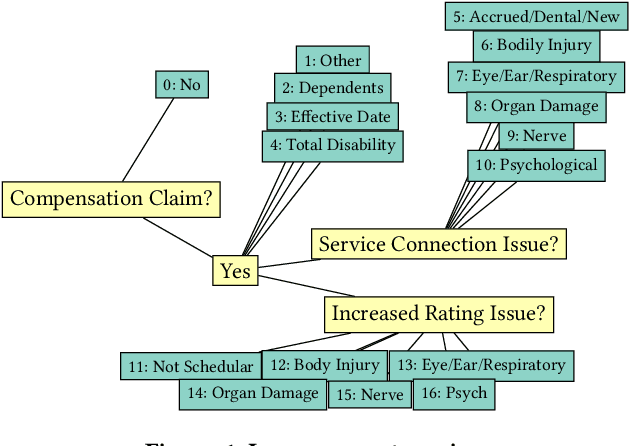
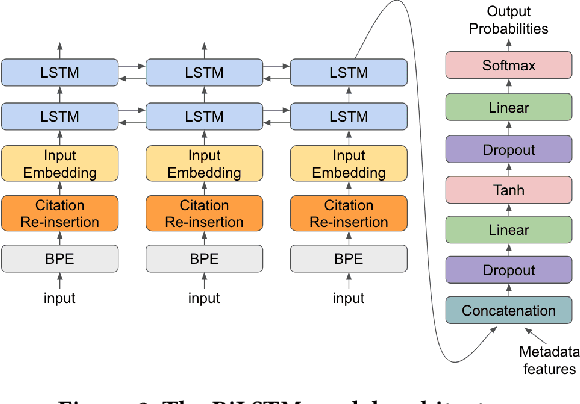
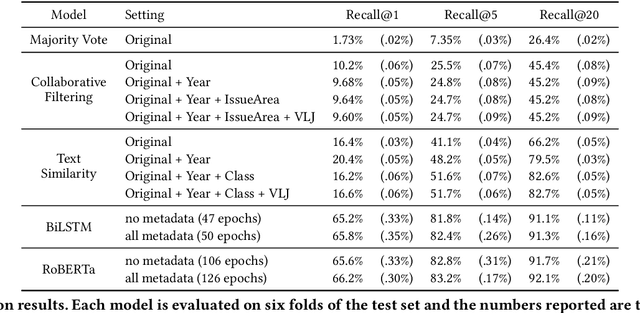
Lawyers and judges spend a large amount of time researching the proper legal authority to cite while drafting decisions. In this paper, we develop a citation recommendation tool that can help improve efficiency in the process of opinion drafting. We train four types of machine learning models, including a citation-list based method (collaborative filtering) and three context-based methods (text similarity, BiLSTM and RoBERTa classifiers). Our experiments show that leveraging local textual context improves recommendation, and that deep neural models achieve decent performance. We show that non-deep text-based methods benefit from access to structured case metadata, but deep models only benefit from such access when predicting from context of insufficient length. We also find that, even after extensive training, RoBERTa does not outperform a recurrent neural model, despite its benefits of pretraining. Our behavior analysis of the RoBERTa model further shows that predictive performance is stable across time and citation classes.
One Backward from Ten Forward, Subsampling for Large-Scale Deep Learning
Apr 27, 2021
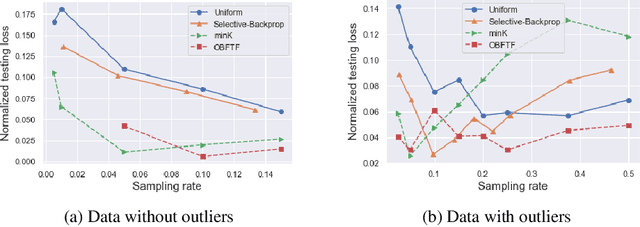

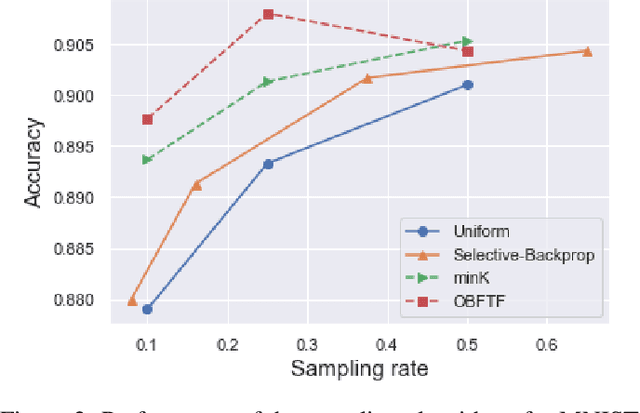
Deep learning models in large-scale machine learning systems are often continuously trained with enormous data from production environments. The sheer volume of streaming training data poses a significant challenge to real-time training subsystems and ad-hoc sampling is the standard practice. Our key insight is that these deployed ML systems continuously perform forward passes on data instances during inference, but ad-hoc sampling does not take advantage of this substantial computational effort. Therefore, we propose to record a constant amount of information per instance from these forward passes. The extra information measurably improves the selection of which data instances should participate in forward and backward passes. A novel optimization framework is proposed to analyze this problem and we provide an efficient approximation algorithm under the framework of Mini-batch gradient descent as a practical solution. We also demonstrate the effectiveness of our framework and algorithm on several large-scale classification and regression tasks, when compared with competitive baselines widely used in industry.
Real-time End-to-End Federated Learning: An Automotive Case Study
Mar 22, 2021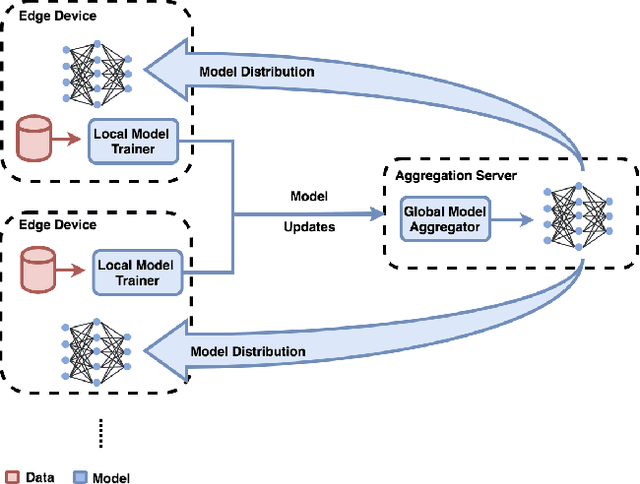

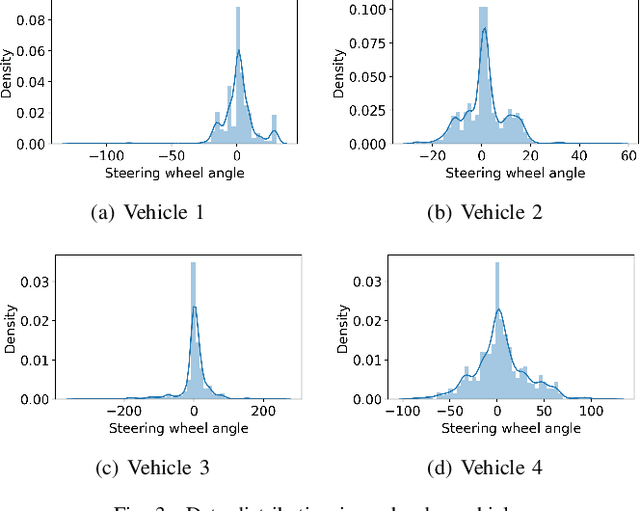
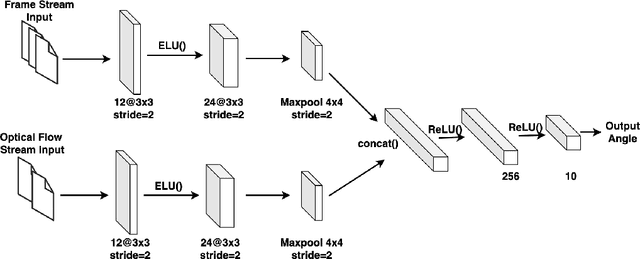
With the development and the increasing interests in ML/DL fields, companies are eager to utilize these methods to improve their service quality and user experience. Federated Learning has been introduced as an efficient model training approach to distribute and speed up time-consuming model training and preserve user data privacy. However, common Federated Learning methods apply a synchronized protocol to perform model aggregation, which turns out to be inflexible and unable to adapt to rapidly evolving environments and heterogeneous hardware settings in real-world systems. In this paper, we introduce an approach to real-time end-to-end Federated Learning combined with a novel asynchronous model aggregation protocol. We validate our approach in an industrial use case in the automotive domain focusing on steering wheel angle prediction for autonomous driving. Our results show that asynchronous Federated Learning can significantly improve the prediction performance of local edge models and reach the same accuracy level as the centralized machine learning method. Moreover, the approach can reduce the communication overhead, accelerate model training speed and consume real-time streaming data by utilizing a sliding training window, which proves high efficiency when deploying ML/DL components to heterogeneous real-world embedded systems.