 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Effectiveness of Detection-based and Regression-based Approaches for Estimating Mask-Wearing Ratio
Nov 25, 2021
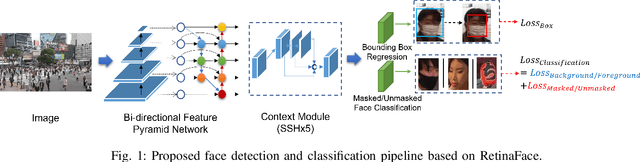
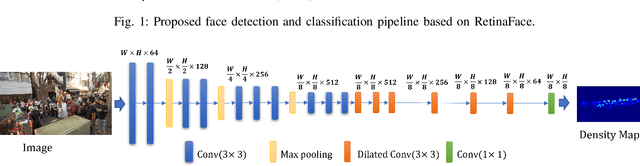

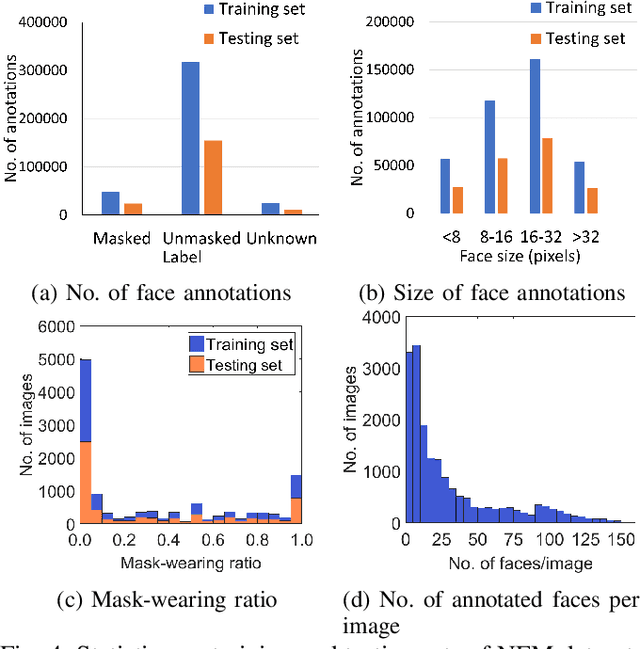
Estimating the mask-wearing ratio in public places is important as it enables health authorities to promptly analyze and implement policies. Methods for estimating the mask-wearing ratio on the basis of image analysis have been reported. However, there is still a lack of comprehensive research on both methodologies and datasets. Most recent reports straightforwardly propose estimating the ratio by applying conventional object detection and classification methods. It is feasible to use regression-based approaches to estimate the number of people wearing masks, especially for congested scenes with tiny and occluded faces, but this has not been well studied. A large-scale and well-annotated dataset is still in demand. In this paper, we present two methods for ratio estimation that leverage either a detection-based or regression-based approach. For the detection-based approach, we improved the state-of-the-art face detector, RetinaFace, used to estimate the ratio. For the regression-based approach, we fine-tuned the baseline network, CSRNet, used to estimate the density maps for masked and unmasked faces. We also present the first large-scale dataset, the ``NFM dataset,'' which contains 581,108 face annotations extracted from 18,088 video frames in 17 street-view videos. Experiments demonstrated that the RetinaFace-based method has higher accuracy under various situations and that the CSRNet-based method has a shorter operation time thanks to its compactness.
Deep Convolution Network Based Emotion Analysis for Automatic Detection of Mild Cognitive Impairment in the Elderly
Nov 09, 2021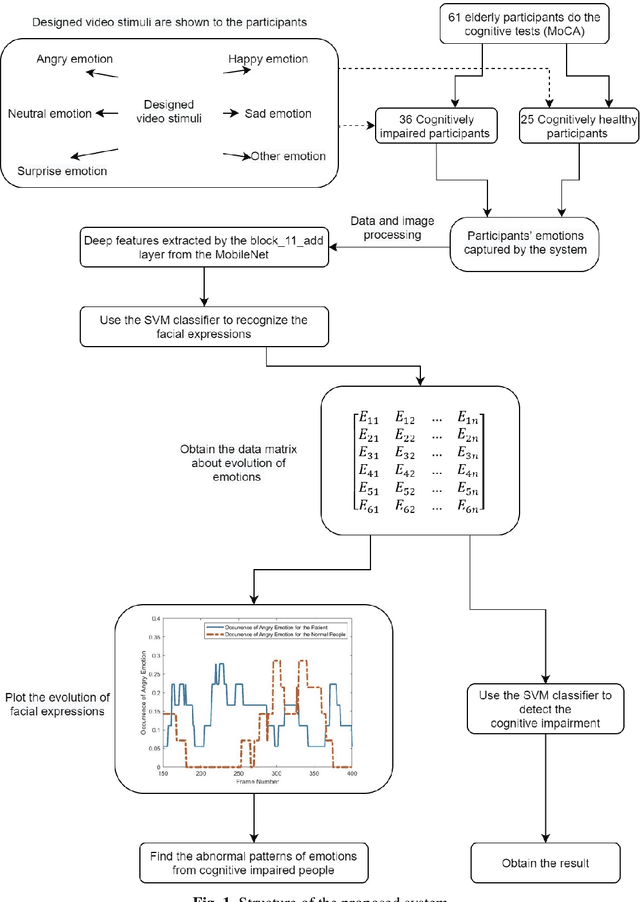
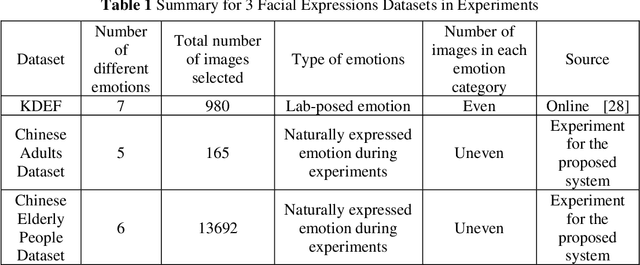
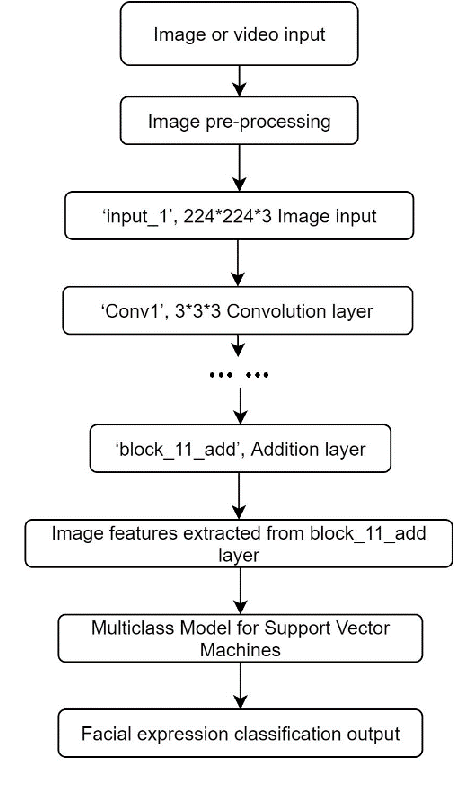
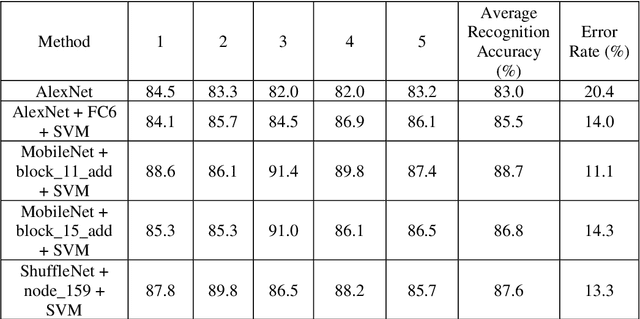
A significant number of people are suffering from cognitive impairment all over the world. Early detection of cognitive impairment is of great importance to both patients and caregivers. However, existing approaches have their shortages, such as time consumption and financial expenses involved in clinics and the neuroimaging stage. It has been found that patients with cognitive impairment show abnormal emotion patterns. In this paper, we present a novel deep convolution network-based system to detect the cognitive impairment through the analysis of the evolution of facial emotions while participants are watching designed video stimuli. In our proposed system, a novel facial expression recognition algorithm is developed using layers from MobileNet and Support Vector Machine (SVM), which showed satisfactory performance in 3 datasets. To verify the proposed system in detecting cognitive impairment, 61 elderly people including patients with cognitive impairment and healthy people as a control group have been invited to participate in the experiments and a dataset was built accordingly. With this dataset, the proposed system has successfully achieved the detection accuracy of 73.3%.
Context-Aware Online Client Selection for Hierarchical Federated Learning
Dec 03, 2021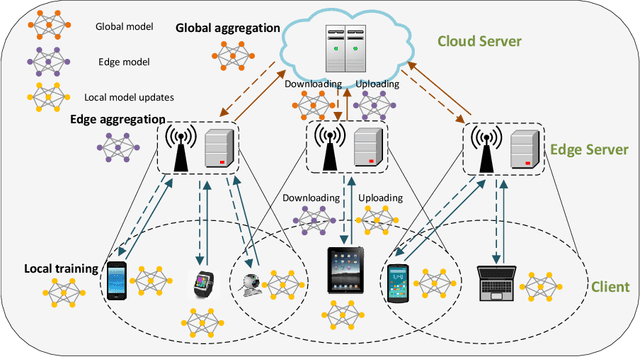
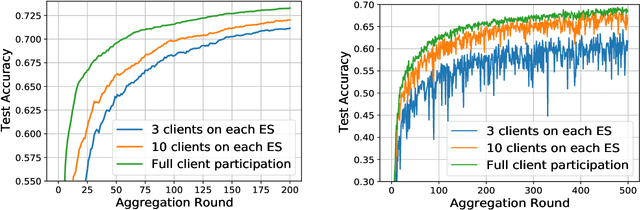
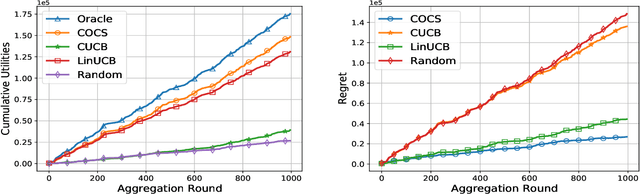
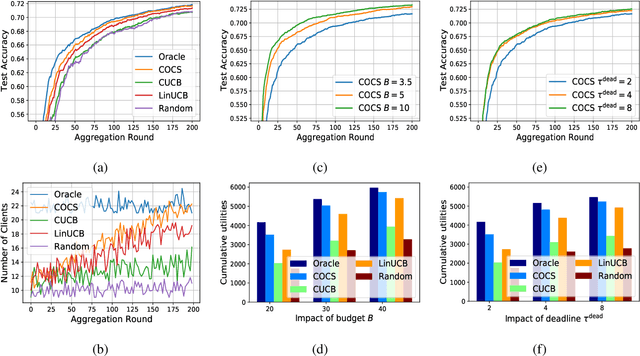
Federated Learning (FL) has been considered as an appealing framework to tackle data privacy issues of mobile devices compared to conventional Machine Learning (ML). Using Edge Servers (ESs) as intermediaries to perform model aggregation in proximity can reduce the transmission overhead, and it enables great potentials in low-latency FL, where the hierarchical architecture of FL (HFL) has been attracted more attention. Designing a proper client selection policy can significantly improve training performance, and it has been extensively used in FL studies. However, to the best of our knowledge, there are no studies focusing on HFL. In addition, client selection for HFL faces more challenges than conventional FL, e.g., the time-varying connection of client-ES pairs and the limited budget of the Network Operator (NO). In this paper, we investigate a client selection problem for HFL, where the NO learns the number of successful participating clients to improve the training performance (i.e., select as many clients in each round) as well as under the limited budget on each ES. An online policy, called Context-aware Online Client Selection (COCS), is developed based on Contextual Combinatorial Multi-Armed Bandit (CC-MAB). COCS observes the side-information (context) of local computing and transmission of client-ES pairs and makes client selection decisions to maximize NO's utility given a limited budget. Theoretically, COCS achieves a sublinear regret compared to an Oracle policy on both strongly convex and non-convex HFL. Simulation results also support the efficiency of the proposed COCS policy on real-world datasets.
Moment evolution equations and moment matching for stochastic image EPDiff
Oct 07, 2021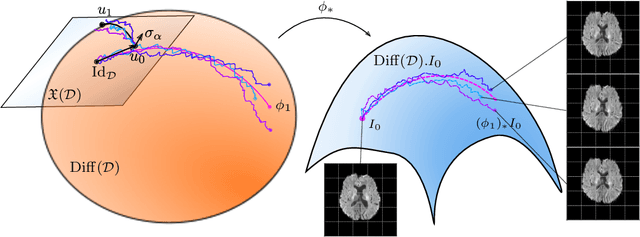
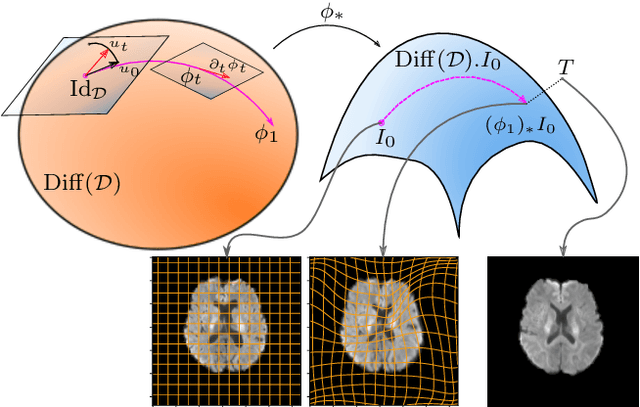

Models of stochastic image deformation allow study of time-continuous stochastic effects transforming images by deforming the image domain. Applications include longitudinal medical image analysis with both population trends and random subject specific variation. Focusing on a stochastic extension of the LDDMM models with evolutions governed by a stochastic EPDiff equation, we use moment approximations of the corresponding Ito diffusion to construct estimators for statistical inference in the full stochastic model. We show that this approach, when efficiently implemented with automatic differentiation tools, can successfully estimate parameters encoding the spatial correlation of the noise fields on the image
Incentive Mechanisms for Federated Learning: From Economic and Game Theoretic Perspective
Nov 20, 2021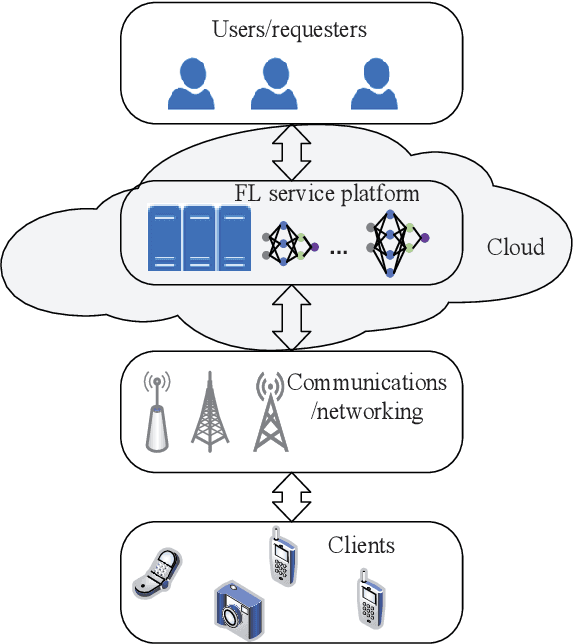
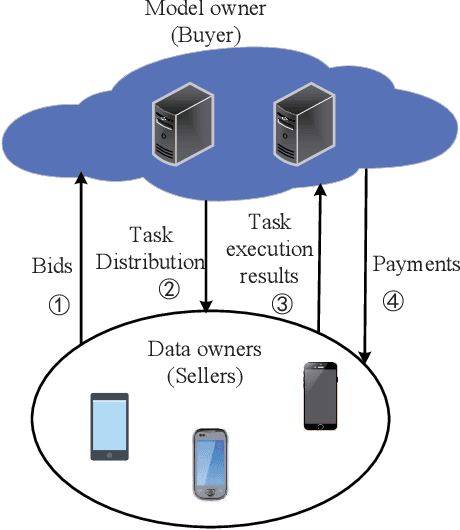
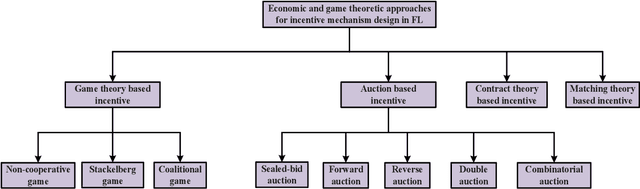
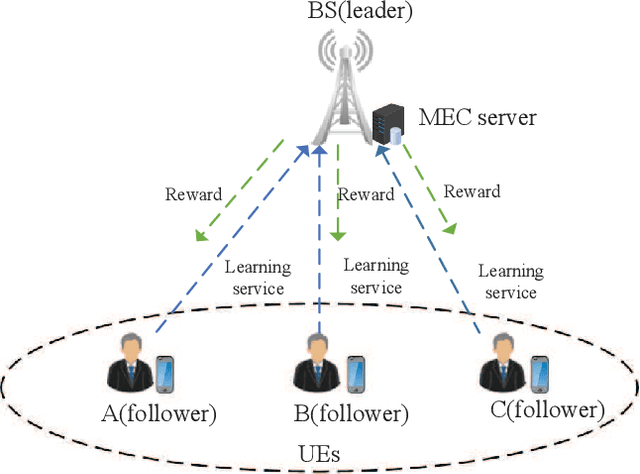
Federated learning (FL) becomes popular and has shown great potentials in training large-scale machine learning (ML) models without exposing the owners' raw data. In FL, the data owners can train ML models based on their local data and only send the model updates rather than raw data to the model owner for aggregation. To improve learning performance in terms of model accuracy and training completion time, it is essential to recruit sufficient participants. Meanwhile, the data owners are rational and may be unwilling to participate in the collaborative learning process due to the resource consumption. To address the issues, there have been various works recently proposed to motivate the data owners to contribute their resources. In this paper, we provide a comprehensive review for the economic and game theoretic approaches proposed in the literature to design various schemes for stimulating data owners to participate in FL training process. In particular, we first present the fundamentals and background of FL, economic theories commonly used in incentive mechanism design. Then, we review applications of game theory and economic approaches applied for incentive mechanisms design of FL. Finally, we highlight some open issues and future research directions concerning incentive mechanism design of FL.
Three-dimensional Cooperative Localization of Commercial-Off-The-Shelf Sensors
Nov 03, 2021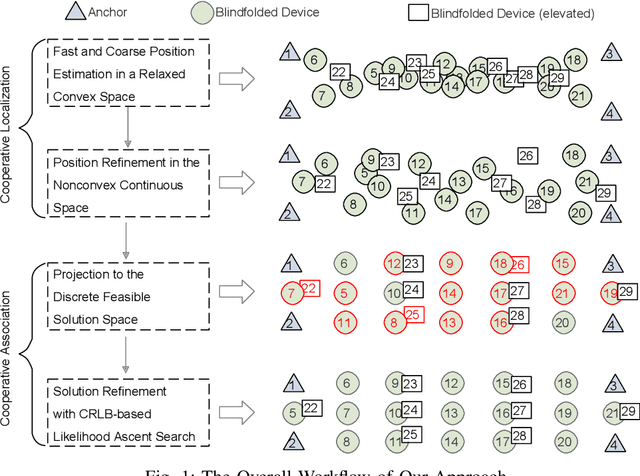
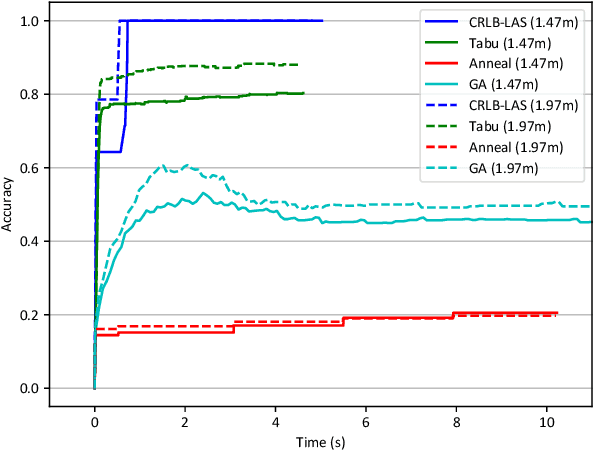
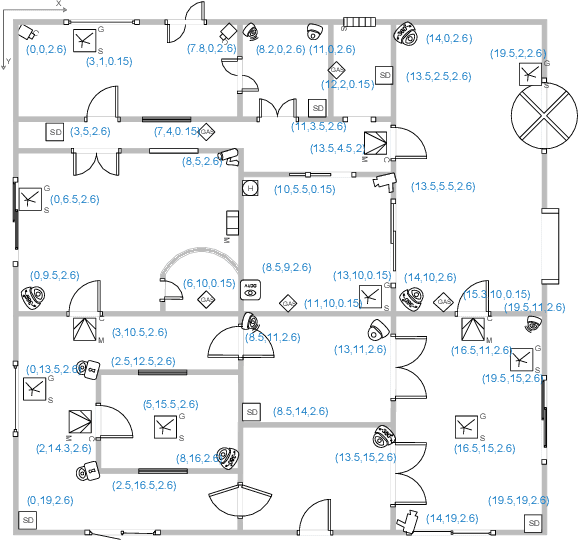
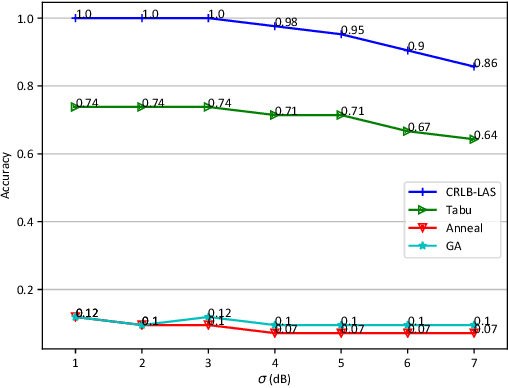
Many location-based services use Received Signal Strength (RSS) measurements due to their universal availability. In this paper, we study the association of a large number of low-cost Internet-of-Things (IoT) sensors and their possible installation locations, which can enable various sensing and automation-related applications. We propose an efficient approach to solve the corresponding permutation combinatorial optimization problem, which integrates continuous space cooperative localization and permutation space likelihood ascent search. A convex relaxation-based optimization is designed to estimate the coarse locations of blindfolded devices in continuous 3D spaces, which are then projected to the feasible permutation space. An efficient Cram\'er-Rao Lower Bound based likelihood ascent search algorithm is proposed to refine the solution. Extensive experiments were conducted to evaluate the performance of the proposed approach, which show that the proposed approach significantly outperforms state-of-the-art combinatorial optimization algorithms and achieves close-to-100% accuracy with affordable execution time.
CodeNeRF: Disentangled Neural Radiance Fields for Object Categories
Sep 03, 2021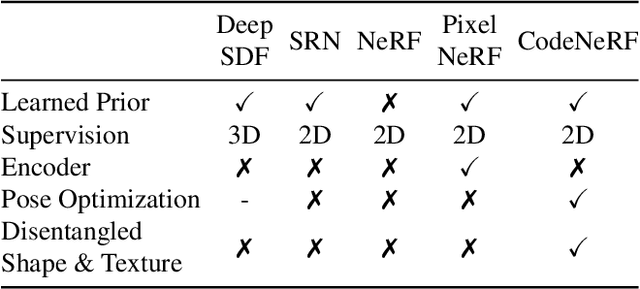
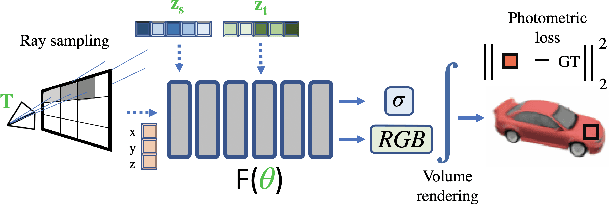
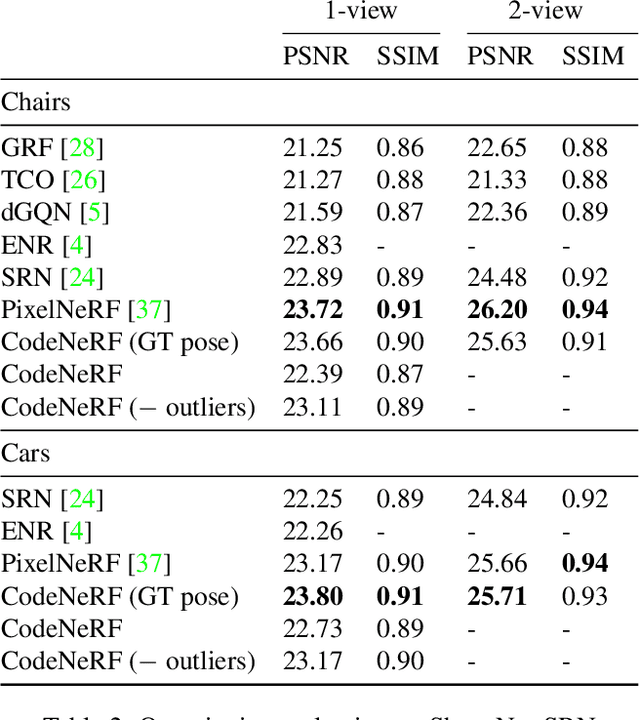
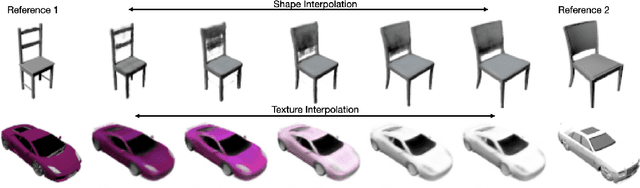
CodeNeRF is an implicit 3D neural representation that learns the variation of object shapes and textures across a category and can be trained, from a set of posed images, to synthesize novel views of unseen objects. Unlike the original NeRF, which is scene specific, CodeNeRF learns to disentangle shape and texture by learning separate embeddings. At test time, given a single unposed image of an unseen object, CodeNeRF jointly estimates camera viewpoint, and shape and appearance codes via optimization. Unseen objects can be reconstructed from a single image, and then rendered from new viewpoints or their shape and texture edited by varying the latent codes. We conduct experiments on the SRN benchmark, which show that CodeNeRF generalises well to unseen objects and achieves on-par performance with methods that require known camera pose at test time. Our results on real-world images demonstrate that CodeNeRF can bridge the sim-to-real gap. Project page: \url{https://github.com/wayne1123/code-nerf}
Sustainable AI: Environmental Implications, Challenges and Opportunities
Oct 30, 2021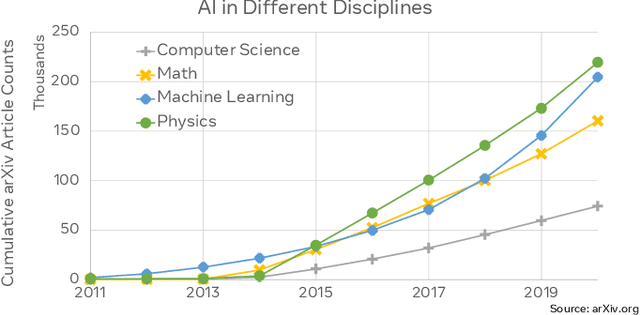
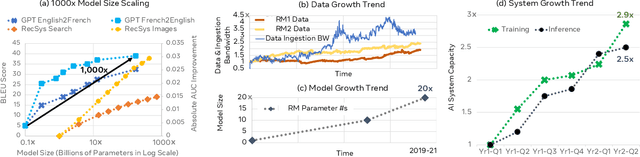
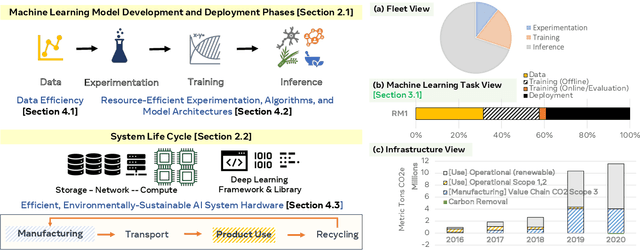
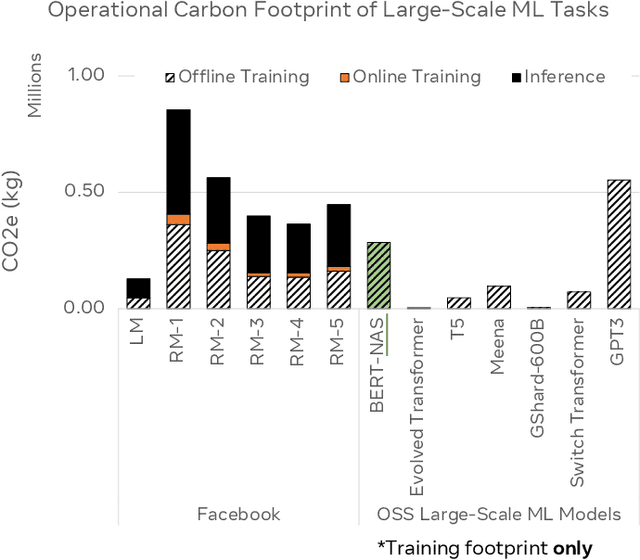
This paper explores the environmental impact of the super-linear growth trends for AI from a holistic perspective, spanning Data, Algorithms, and System Hardware. We characterize the carbon footprint of AI computing by examining the model development cycle across industry-scale machine learning use cases and, at the same time, considering the life cycle of system hardware. Taking a step further, we capture the operational and manufacturing carbon footprint of AI computing and present an end-to-end analysis for what and how hardware-software design and at-scale optimization can help reduce the overall carbon footprint of AI. Based on the industry experience and lessons learned, we share the key challenges and chart out important development directions across the many dimensions of AI. We hope the key messages and insights presented in this paper can inspire the community to advance the field of AI in an environmentally-responsible manner.
Automated Testing of AI Models
Oct 07, 2021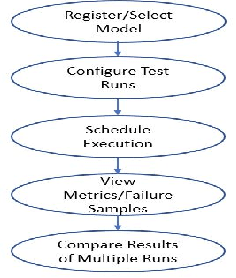
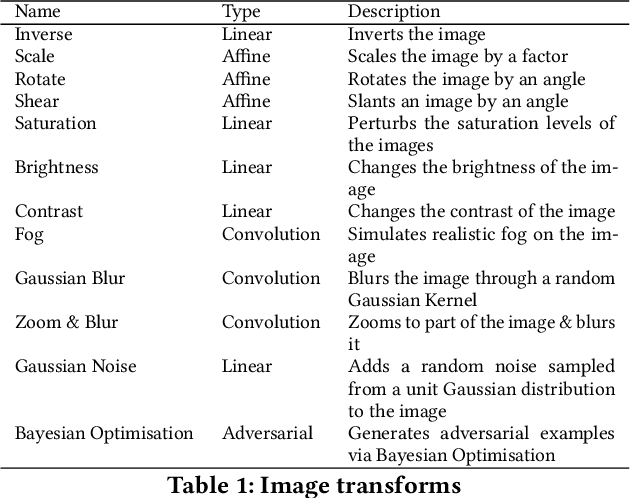
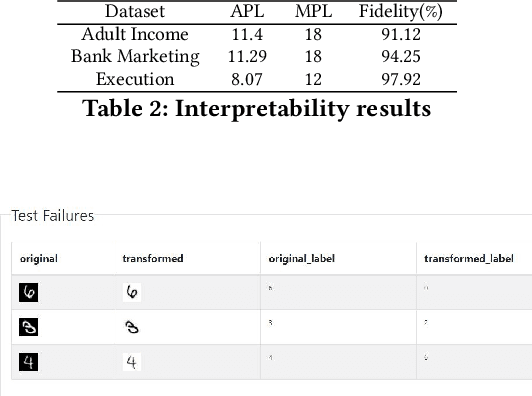
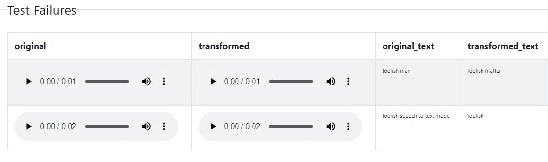
The last decade has seen tremendous progress in AI technology and applications. With such widespread adoption, ensuring the reliability of the AI models is crucial. In past, we took the first step of creating a testing framework called AITEST for metamorphic properties such as fairness, robustness properties for tabular, time-series, and text classification models. In this paper, we extend the capability of the AITEST tool to include the testing techniques for Image and Speech-to-text models along with interpretability testing for tabular models. These novel extensions make AITEST a comprehensive framework for testing AI models.
Deep-Learning Inversion Method for the Interpretation of Noisy Logging-While-Drilling Resistivity Measurements
Nov 15, 2021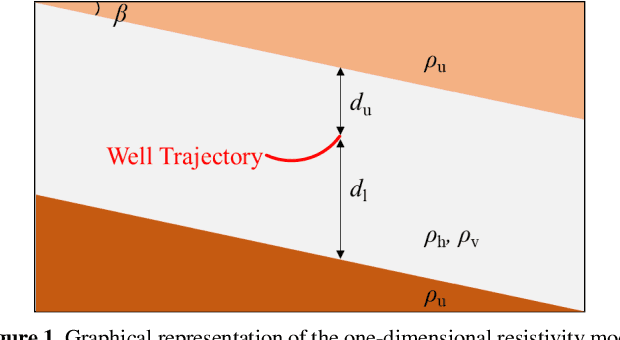

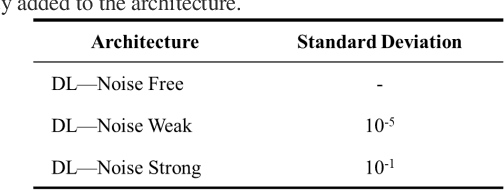
Deep Learning (DL) inversion is a promising method for real time interpretation of logging while drilling (LWD) resistivity measurements for well navigation applications. In this context, measurement noise may significantly affect inversion results. Existing publications examining the effects of measurement noise on DL inversion results are scarce. We develop a method to generate training data sets and construct DL architectures that enhance the robustness of DL inversion methods in the presence of noisy LWD resistivity measurements. We use two synthetic resistivity models to test three approaches that explicitly consider the presence of noise: (1) adding noise to the measurements in the training set, (2) augmenting the training set by replicating it and adding varying noise realizations, and (3) adding a noise layer in the DL architecture. Numerical results confirm that the three approaches produce a denoising effect, yielding better inversion results in both predicted earth model and measurements compared not only to the basic DL inversion but also to traditional gradient based inversion results. A combination of the second and third approaches delivers the best results. The proposed methods can be readily generalized to multi dimensional DL inversion.