 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Standard Benchmarks: A Systematic Audit of Vision-Language Model's Robustness to Natural Semantic Variation Across Diverse Tasks
Apr 06, 2026Recent advances in vision-language models (VLMs) trained on web-scale image-text pairs have enabled impressive zero-shot transfer across a diverse range of visual tasks. However, comprehensive and independent evaluation beyond standard benchmarks is essential to understand their robustness, limitations, and real-world applicability. This paper presents a systematic evaluation framework for VLMs under natural adversarial scenarios for diverse downstream tasks, which has been overlooked in previous evaluation works. We evaluate a wide range of VLMs (CLIP, robust CLIP, BLIP2, and SigLIP2) on curated adversarial datasets (typographic attacks, ImageNet-A, and natural language-induced adversarial examples). We measure the natural adversarial performance of selected VLMs for zero-shot image classification, semantic segmentation, and visual question answering. Our analysis reveals that robust CLIP models can amplify natural adversarial vulnerabilities, and CLIP models significantly reduce performance for natural language-induced adversarial examples. Additionally, we provide interpretable analyses to identify failure modes. We hope our findings inspire future research in robust and fair multimodal pattern recognition.
Predict, Don't React: Value-Based Safety Forecasting for LLM Streaming
Apr 05, 2026In many practical LLM deployments, a single guardrail is used for both prompt and response moderation. Prompt moderation operates on fully observed text, whereas streaming response moderation requires safety decisions to be made over partial generations. Existing text-based streaming guardrails commonly frame this output-side problem as boundary detection, training models to identify the earliest prefix at which a response has already become unsafe. In this work, we introduce StreamGuard, a unified model-agnostic streaming guardrail that instead formulates moderation as a forecasting problem: given a partial prefix, the model predicts the expected harmfulness of likely future continuations. We supervise this prediction using Monte Carlo rollouts, which enables early intervention without requiring exact token-level boundary annotations. Across standard safety benchmarks, StreamGuard performs strongly both for input moderation and for streaming output moderation. At the 8B scale, StreamGuard improves aggregated input-moderation F1 from 86.7 to 88.2 and aggregated streaming output-moderation F1 from 80.4 to 81.9 relative to Qwen3Guard-Stream-8B-strict. On the QWENGUARDTEST response_loc streaming benchmark, StreamGuard reaches 97.5 F1, 95.1 recall, and 92.6% on-time intervention, compared to 95.9 F1, 92.1 recall, and 89.9% for Qwen3Guard-Stream-8B-stric, while reducing the miss rate from 7.9% to 4.9%. We further show that forecasting-based supervision transfers effectively across tokenizers and model families: with transferred targets, Gemma3-StreamGuard-1B reaches 81.3 response-moderation F1, 98.2 streaming F1, and a 3.5% miss rate. These results show that strong end-to-end streaming moderation can be obtained without exact boundary labels, and that forecasting future risk is an effective supervision strategy for low-latency safety intervention.
Exploring Active Data Selection Strategies for Continuous Training in Deepfake Detection
Feb 11, 2025In deepfake detection, it is essential to maintain high performance by adjusting the parameters of the detector as new deepfake methods emerge. In this paper, we propose a method to automatically and actively select the small amount of additional data required for the continuous training of deepfake detection models in situations where deepfake detection models are regularly updated. The proposed method automatically selects new training data from a \textit{redundant} pool set containing a large number of images generated by new deepfake methods and real images, using the confidence score of the deepfake detection model as a metric. Experimental results show that the deepfake detection model, continuously trained with a small amount of additional data automatically selected and added to the original training set, significantly and efficiently improved the detection performance, achieving an EER of 2.5% with only 15% of the amount of data in the pool set.
Physics-Based Adversarial Attack on Near-Infrared Human Detector for Nighttime Surveillance Camera Systems
Dec 18, 2024



Many surveillance cameras switch between daytime and nighttime modes based on illuminance levels. During the day, the camera records ordinary RGB images through an enabled IR-cut filter. At night, the filter is disabled to capture near-infrared (NIR) light emitted from NIR LEDs typically mounted around the lens. While RGB-based AI algorithm vulnerabilities have been widely reported, the vulnerabilities of NIR-based AI have rarely been investigated. In this paper, we identify fundamental vulnerabilities in NIR-based image understanding caused by color and texture loss due to the intrinsic characteristics of clothes' reflectance and cameras' spectral sensitivity in the NIR range. We further show that the nearly co-located configuration of illuminants and cameras in existing surveillance systems facilitates concealing and fully passive attacks in the physical world. Specifically, we demonstrate how retro-reflective and insulation plastic tapes can manipulate the intensity distribution of NIR images. We showcase an attack on the YOLO-based human detector using binary patterns designed in the digital space (via black-box query and searching) and then physically realized using tapes pasted onto clothes. Our attack highlights significant reliability concerns for nighttime surveillance systems, which are intended to enhance security. Codes Available: https://github.com/MyNiuuu/AdvNIR
LookupForensics: A Large-Scale Multi-Task Dataset for Multi-Phase Image-Based Fact Verification
Jul 26, 2024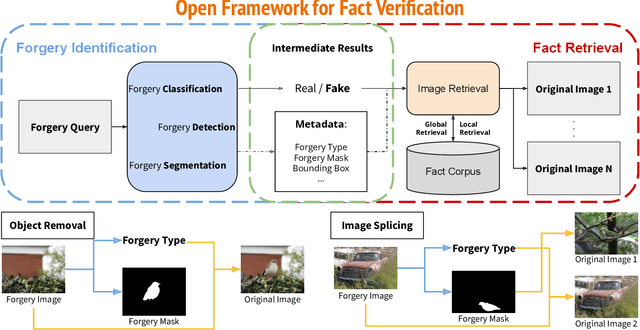
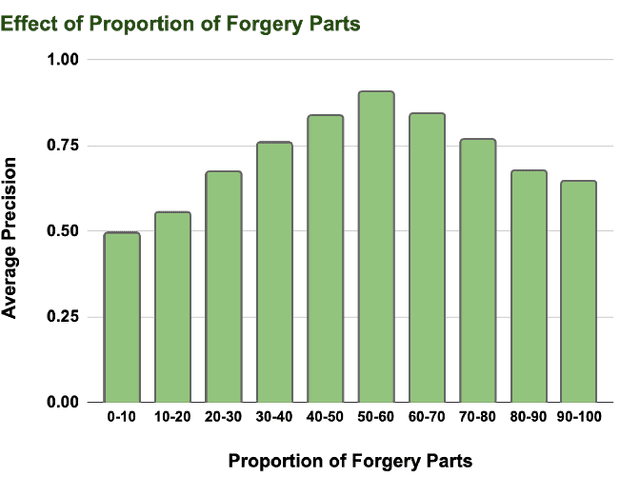

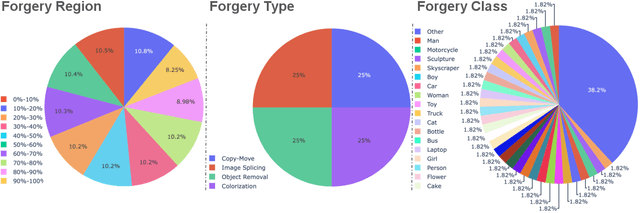
Amid the proliferation of forged images, notably the tsunami of deepfake content, extensive research has been conducted on using artificial intelligence (AI) to identify forged content in the face of continuing advancements in counterfeiting technologies. We have investigated the use of AI to provide the original authentic image after deepfake detection, which we believe is a reliable and persuasive solution. We call this "image-based automated fact verification," a name that originated from a text-based fact-checking system used by journalists. We have developed a two-phase open framework that integrates detection and retrieval components. Additionally, inspired by a dataset proposed by Meta Fundamental AI Research, we further constructed a large-scale dataset that is specifically designed for this task. This dataset simulates real-world conditions and includes both content-preserving and content-aware manipulations that present a range of difficulty levels and have potential for ongoing research. This multi-task dataset is fully annotated, enabling it to be utilized for sub-tasks within the forgery identification and fact retrieval domains. This paper makes two main contributions: (1) We introduce a new task, "image-based automated fact verification," and present a novel two-phase open framework combining "forgery identification" and "fact retrieval." (2) We present a large-scale dataset tailored for this new task that features various hand-crafted image edits and machine learning-driven manipulations, with extensive annotations suitable for various sub-tasks. Extensive experimental results validate its practicality for fact verification research and clarify its difficulty levels for various sub-tasks.
Mitigating Backdoor Attacks using Activation-Guided Model Editing
Jul 10, 2024



Backdoor attacks compromise the integrity and reliability of machine learning models by embedding a hidden trigger during the training process, which can later be activated to cause unintended misbehavior. We propose a novel backdoor mitigation approach via machine unlearning to counter such backdoor attacks. The proposed method utilizes model activation of domain-equivalent unseen data to guide the editing of the model's weights. Unlike the previous unlearning-based mitigation methods, ours is computationally inexpensive and achieves state-of-the-art performance while only requiring a handful of unseen samples for unlearning. In addition, we also point out that unlearning the backdoor may cause the whole targeted class to be unlearned, thus introducing an additional repair step to preserve the model's utility after editing the model. Experiment results show that the proposed method is effective in unlearning the backdoor on different datasets and trigger patterns.
Exploring Self-Supervised Vision Transformers for Deepfake Detection: A Comparative Analysis
May 01, 2024This paper investigates the effectiveness of self-supervised pre-trained transformers compared to supervised pre-trained transformers and conventional neural networks (ConvNets) for detecting various types of deepfakes. We focus on their potential for improved generalization, particularly when training data is limited. Despite the notable success of large vision-language models utilizing transformer architectures in various tasks, including zero-shot and few-shot learning, the deepfake detection community has still shown some reluctance to adopt pre-trained vision transformers (ViTs), especially large ones, as feature extractors. One concern is their perceived excessive capacity, which often demands extensive data, and the resulting suboptimal generalization when training or fine-tuning data is small or less diverse. This contrasts poorly with ConvNets, which have already established themselves as robust feature extractors. Additionally, training and optimizing transformers from scratch requires significant computational resources, making this accessible primarily to large companies and hindering broader investigation within the academic community. Recent advancements in using self-supervised learning (SSL) in transformers, such as DINO and its derivatives, have showcased significant adaptability across diverse vision tasks and possess explicit semantic segmentation capabilities. By leveraging DINO for deepfake detection with modest training data and implementing partial fine-tuning, we observe comparable adaptability to the task and the natural explainability of the detection result via the attention mechanism. Moreover, partial fine-tuning of transformers for deepfake detection offers a more resource-efficient alternative, requiring significantly fewer computational resources.
Fine-Tuning Text-To-Image Diffusion Models for Class-Wise Spurious Feature Generation
Feb 13, 2024We propose a method for generating spurious features by leveraging large-scale text-to-image diffusion models. Although the previous work detects spurious features in a large-scale dataset like ImageNet and introduces Spurious ImageNet, we found that not all spurious images are spurious across different classifiers. Although spurious images help measure the reliance of a classifier, filtering many images from the Internet to find more spurious features is time-consuming. To this end, we utilize an existing approach of personalizing large-scale text-to-image diffusion models with available discovered spurious images and propose a new spurious feature similarity loss based on neural features of an adversarially robust model. Precisely, we fine-tune Stable Diffusion with several reference images from Spurious ImageNet with a modified objective incorporating the proposed spurious-feature similarity loss. Experiment results show that our method can generate spurious images that are consistently spurious across different classifiers. Moreover, the generated spurious images are visually similar to reference images from Spurious ImageNet.
Enhancing Robustness of LLM-Synthetic Text Detectors for Academic Writing: A Comprehensive Analysis
Jan 16, 2024The emergence of large language models (LLMs), such as Generative Pre-trained Transformer 4 (GPT-4) used by ChatGPT, has profoundly impacted the academic and broader community. While these models offer numerous advantages in terms of revolutionizing work and study methods, they have also garnered significant attention due to their potential negative consequences. One example is generating academic reports or papers with little to no human contribution. Consequently, researchers have focused on developing detectors to address the misuse of LLMs. However, most existing methods prioritize achieving higher accuracy on restricted datasets, neglecting the crucial aspect of generalizability. This limitation hinders their practical application in real-life scenarios where reliability is paramount. In this paper, we present a comprehensive analysis of the impact of prompts on the text generated by LLMs and highlight the potential lack of robustness in one of the current state-of-the-art GPT detectors. To mitigate these issues concerning the misuse of LLMs in academic writing, we propose a reference-based Siamese detector named Synthetic-Siamese which takes a pair of texts, one as the inquiry and the other as the reference. Our method effectively addresses the lack of robustness of previous detectors (OpenAI detector and DetectGPT) and significantly improves the baseline performances in realistic academic writing scenarios by approximately 67% to 95%.
Cross-Attention Watermarking of Large Language Models
Jan 12, 2024



A new approach to linguistic watermarking of language models is presented in which information is imperceptibly inserted into the output text while preserving its readability and original meaning. A cross-attention mechanism is used to embed watermarks in the text during inference. Two methods using cross-attention are presented that minimize the effect of watermarking on the performance of a pretrained model. Exploration of different training strategies for optimizing the watermarking and of the challenges and implications of applying this approach in real-world scenarios clarified the tradeoff between watermark robustness and text quality. Watermark selection substantially affects the generated output for high entropy sentences. This proactive watermarking approach has potential application in future model development.