 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffectiveness of Detection-based and Regression-based Approaches for Estimating Mask-Wearing Ratio
Paper and Code
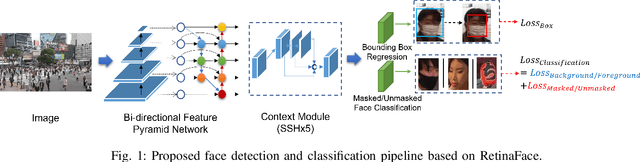
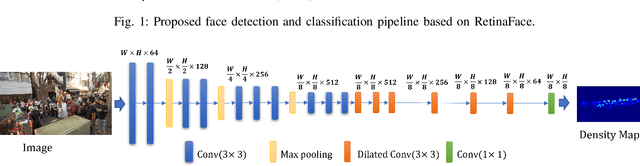

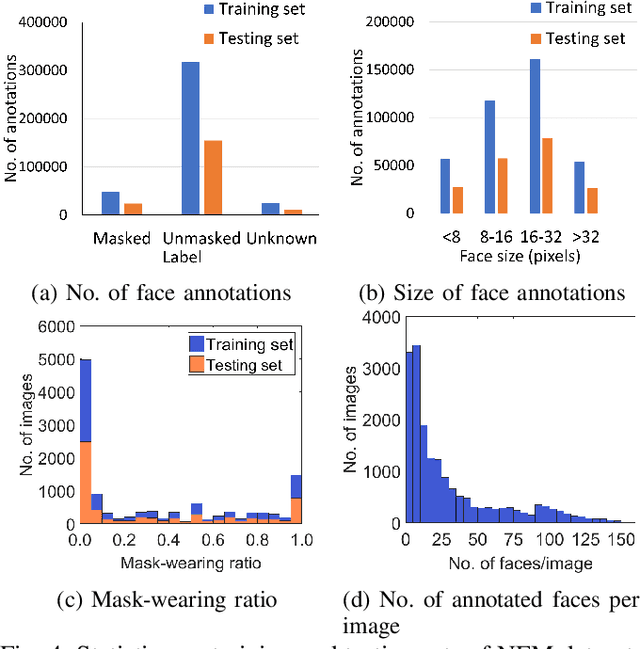
Estimating the mask-wearing ratio in public places is important as it enables health authorities to promptly analyze and implement policies. Methods for estimating the mask-wearing ratio on the basis of image analysis have been reported. However, there is still a lack of comprehensive research on both methodologies and datasets. Most recent reports straightforwardly propose estimating the ratio by applying conventional object detection and classification methods. It is feasible to use regression-based approaches to estimate the number of people wearing masks, especially for congested scenes with tiny and occluded faces, but this has not been well studied. A large-scale and well-annotated dataset is still in demand. In this paper, we present two methods for ratio estimation that leverage either a detection-based or regression-based approach. For the detection-based approach, we improved the state-of-the-art face detector, RetinaFace, used to estimate the ratio. For the regression-based approach, we fine-tuned the baseline network, CSRNet, used to estimate the density maps for masked and unmasked faces. We also present the first large-scale dataset, the ``NFM dataset,'' which contains 581,108 face annotations extracted from 18,088 video frames in 17 street-view videos. Experiments demonstrated that the RetinaFace-based method has higher accuracy under various situations and that the CSRNet-based method has a shorter operation time thanks to its compactness.