 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
HIE-SQL: History Information Enhanced Network for Context-Dependent Text-to-SQL Semantic Parsing
Apr 02, 2022

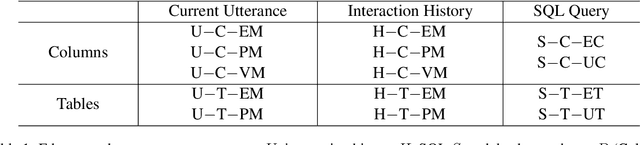
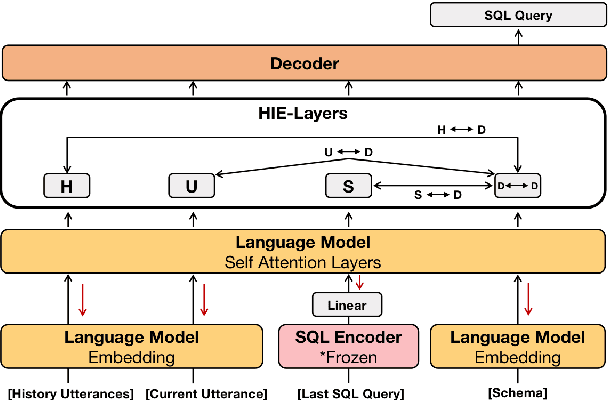

Recently, context-dependent text-to-SQL semantic parsing which translates natural language into SQL in an interaction process has attracted a lot of attention. Previous works leverage context-dependence information either from interaction history utterances or the previous predicted SQL queries but fail in taking advantage of both since of the mismatch between natural language and logic-form SQL. In this work, we propose a History Information Enhanced text-to-SQL model (HIE-SQL) to exploit context-dependence information from both history utterances and the last predicted SQL query. In view of the mismatch, we treat natural language and SQL as two modalities and propose a bimodal pre-trained model to bridge the gap between them. Besides, we design a schema-linking graph to enhance connections from utterances and the SQL query to the database schema. We show our history information enhanced methods improve the performance of HIE-SQL by a significant margin, which achieves new state-of-the-art results on the two context-dependent text-to-SQL benchmarks, the SparC and CoSQL datasets, at the writing time.
Probabilistic Spherical Discriminant Analysis: An Alternative to PLDA for length-normalized embeddings
Mar 28, 2022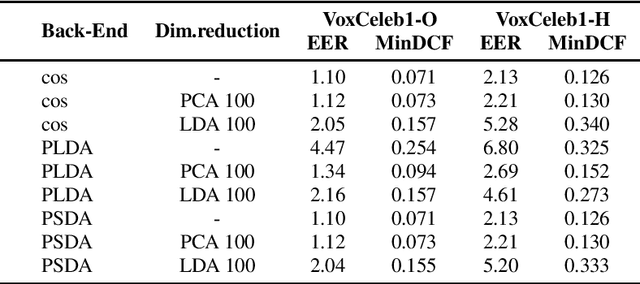
In speaker recognition, where speech segments are mapped to embeddings on the unit hypersphere, two scoring backends are commonly used, namely cosine scoring or PLDA. Both have advantages and disadvantages, depending on the context. Cosine scoring follows naturally from the spherical geometry, but for PLDA the blessing is mixed -- length normalization Gaussianizes the between-speaker distribution, but violates the assumption of a speaker-independent within-speaker distribution. We propose PSDA, an analogue to PLDA that uses Von Mises-Fisher distributions on the hypersphere for both within and between-class distributions. We show how the self-conjugacy of this distribution gives closed-form likelihood-ratio scores, making it a drop-in replacement for PLDA at scoring time. All kinds of trials can be scored, including single-enroll and multi-enroll verification, as well as more complex likelihood-ratios that could be used in clustering and diarization. Learning is done via an EM-algorithm with closed-form updates. We explain the model and present some first experiments.
WawPart: Workload-Aware Partitioning of Knowledge Graphs
Mar 28, 2022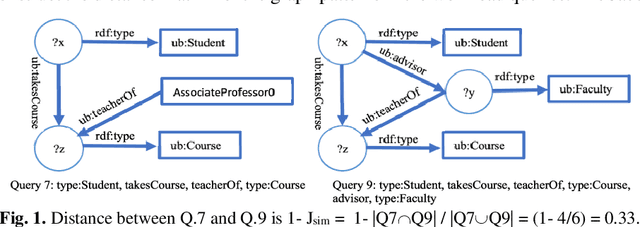
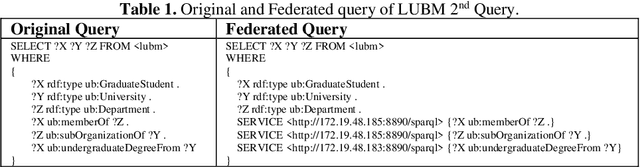
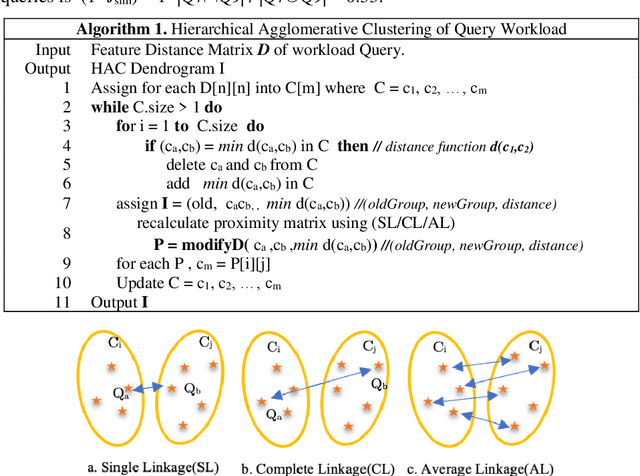
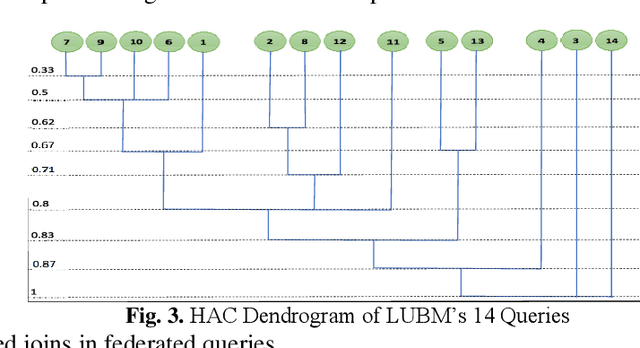
Large-scale datasets in the form of knowledge graphs are often used in numerous domains, today. A knowledge graphs size often exceeds the capacity of a single computer system, especially if the graph must be stored in main memory. To overcome this, knowledge graphs can be partitioned into multiple sub-graphs and distributed as shards among many computing nodes. However, performance of many common tasks performed on graphs, such as querying, suffers, as a result. This is due to distributed joins mandated by graph edges crossing (cutting) the partitions. In this paper, we propose a method of knowledge graph partitioning that takes into account a set of queries (workload). The resulting partitioning aims to reduces the number of distributed joins and improve the workload performance. Critical features identified in the query workload and the knowledge graph are used to cluster the queries and then partition the graph. Queries are rewritten to account for the graph partitioning. Our evaluation results demonstrate the performance improvement in workload processing time.
Multi-Component Optimization and Efficient Deployment of Neural-Networks on Resource-Constrained IoT Hardware
Apr 20, 2022
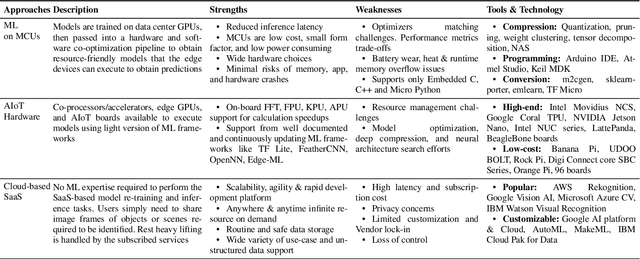
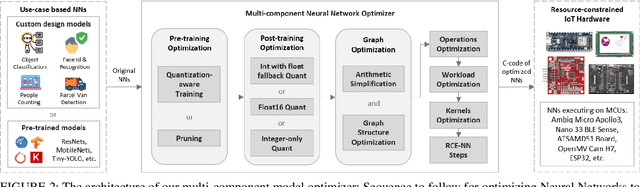
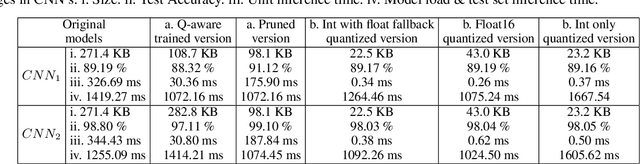
The majority of IoT devices like smartwatches, smart plugs, HVAC controllers, etc., are powered by hardware with a constrained specification (low memory, clock speed and processor) which is insufficient to accommodate and execute large, high-quality models. On such resource-constrained devices, manufacturers still manage to provide attractive functionalities (to boost sales) by following the traditional approach of programming IoT devices/products to collect and transmit data (image, audio, sensor readings, etc.) to their cloud-based ML analytics platforms. For decades, this online approach has been facing issues such as compromised data streams, non-real-time analytics due to latency, bandwidth constraints, costly subscriptions, recent privacy issues raised by users and the GDPR guidelines, etc. In this paper, to enable ultra-fast and accurate AI-based offline analytics on resource-constrained IoT devices, we present an end-to-end multi-component model optimization sequence and open-source its implementation. Researchers and developers can use our optimization sequence to optimize high memory, computation demanding models in multiple aspects in order to produce small size, low latency, low-power consuming models that can comfortably fit and execute on resource-constrained hardware. The experimental results show that our optimization components can produce models that are; (i) 12.06 x times compressed; (ii) 0.13% to 0.27% more accurate; (iii) Orders of magnitude faster unit inference at 0.06 ms. Our optimization sequence is generic and can be applied to any state-of-the-art models trained for anomaly detection, predictive maintenance, robotics, voice recognition, and machine vision.
Fast Matching Pursuit with Multi-Gabor Dictionaries
Feb 16, 2022
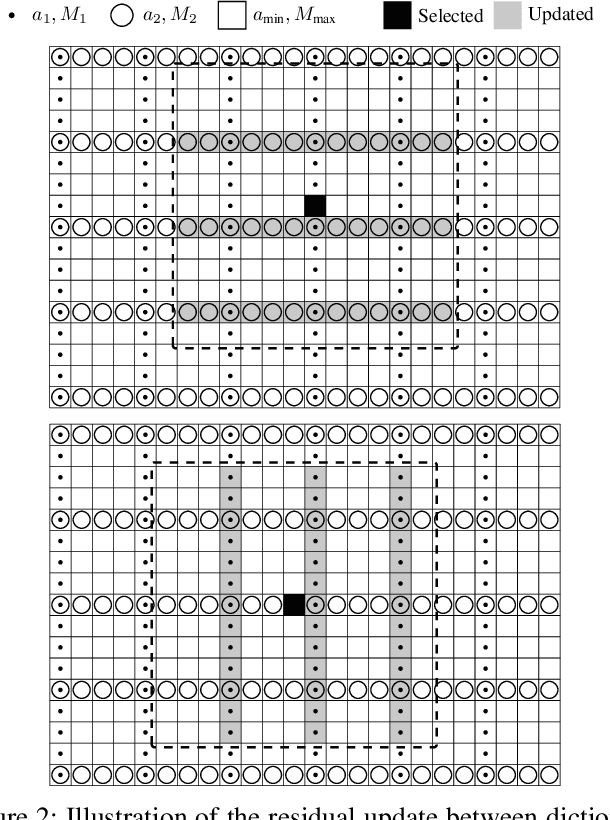


Finding the best K-sparse approximation of a signal in a redundant dictionary is an NP-hard problem. Suboptimal greedy matching pursuit (MP) algorithms are generally used for this task. In this work, we present an acceleration technique and an implementation of the matching pursuit algorithm acting on a multi-Gabor dictionary, i.e., a concatenation of several Gabor-type time-frequency dictionaries, each of which consisting of translations and modulations of a possibly different window and time and frequency shift parameters. The technique is based on pre-computing and thresholding inner products between atoms and on updating the residual directly in the coefficient domain, i.e., without the round-trip to the signal domain. Since the proposed acceleration technique involves an approximate update step, we provide theoretical and experimental results illustrating the convergence of the resulting algorithm. The implementation is written in C (compatible with C99 and C++11) and we also provide Matlab and GNU Octave interfaces. For some settings, the implementation is up to 70 times faster than the standard Matching Pursuit Toolkit (MPTK).
Real-Time Resource Allocation for Tracking Systems
Sep 21, 2020
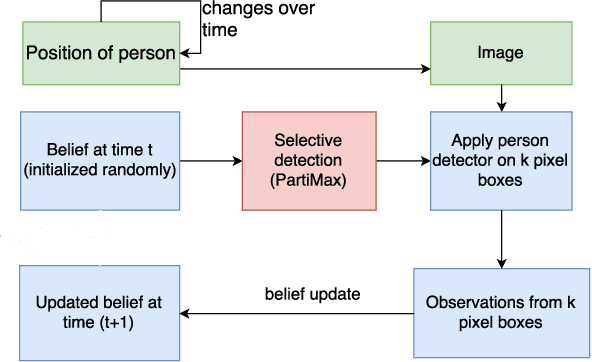

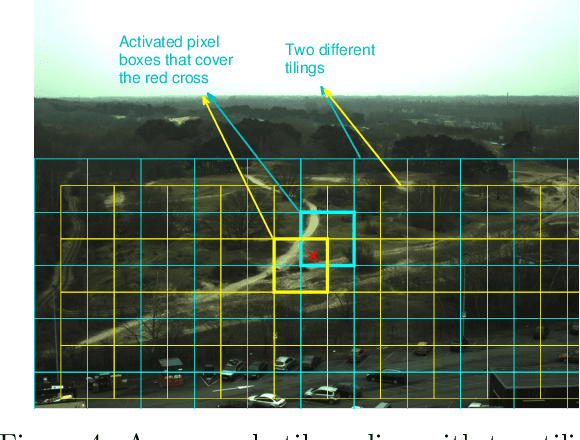
Automated tracking is key to many computer vision applications. However, many tracking systems struggle to perform in real-time due to the high computational cost of detecting people, especially in ultra high resolution images. We propose a new algorithm called \emph{PartiMax} that greatly reduces this cost by applying the person detector only to the relevant parts of the image. PartiMax exploits information in the particle filter to select $k$ of the $n$ candidate \emph{pixel boxes} in the image. We prove that PartiMax is guaranteed to make a near-optimal selection with error bounds that are independent of the problem size. Furthermore, empirical results on a real-life dataset show that our system runs in real-time by processing only 10\% of the pixel boxes in the image while still retaining 80\% of the original tracking performance achieved when processing all pixel boxes.
* http://auai.org/uai2017/proceedings/papers/130.pdf
Chance-Constrained Optimization in Contact-Rich Systems for Robust Manipulation
Mar 05, 2022
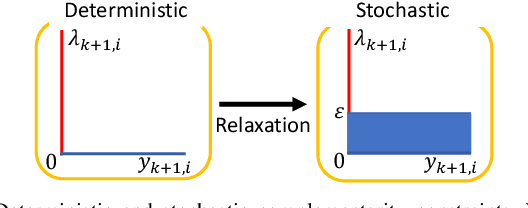
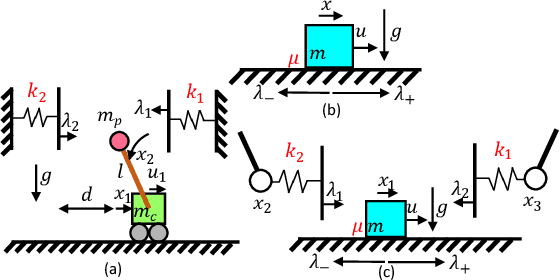
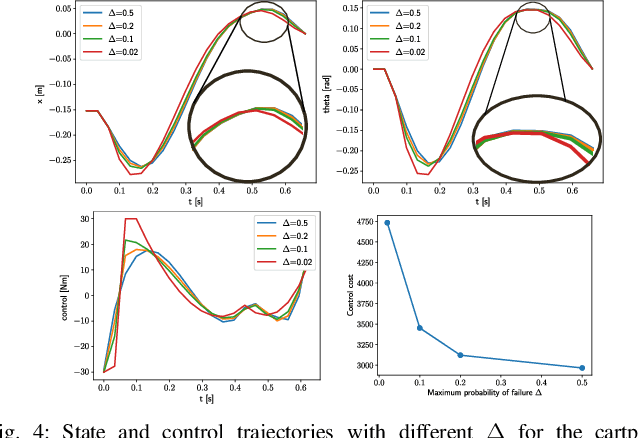
This paper presents a chance-constrained formulation for robust trajectory optimization during manipulation. In particular, we present a chance-constrained optimization for Stochastic Discrete-time Linear Complementarity Systems (SDLCS). To solve the optimization problem, we formulate Mixed-Integer Quadratic Programming with Chance Constraints (MIQPCC). In our formulation, we explicitly consider joint chance constraints for complementarity as well as states to capture the stochastic evolution of dynamics. We evaluate robustness of our optimized trajectories in simulation on several systems. The proposed approach outperforms some recent approaches for robust trajectory optimization for SDLCS.
* 9 pages, 9 figures
Adaptive Risk Tendency: Nano Drone Navigation in Cluttered Environments with Distributional Reinforcement Learning
Mar 28, 2022

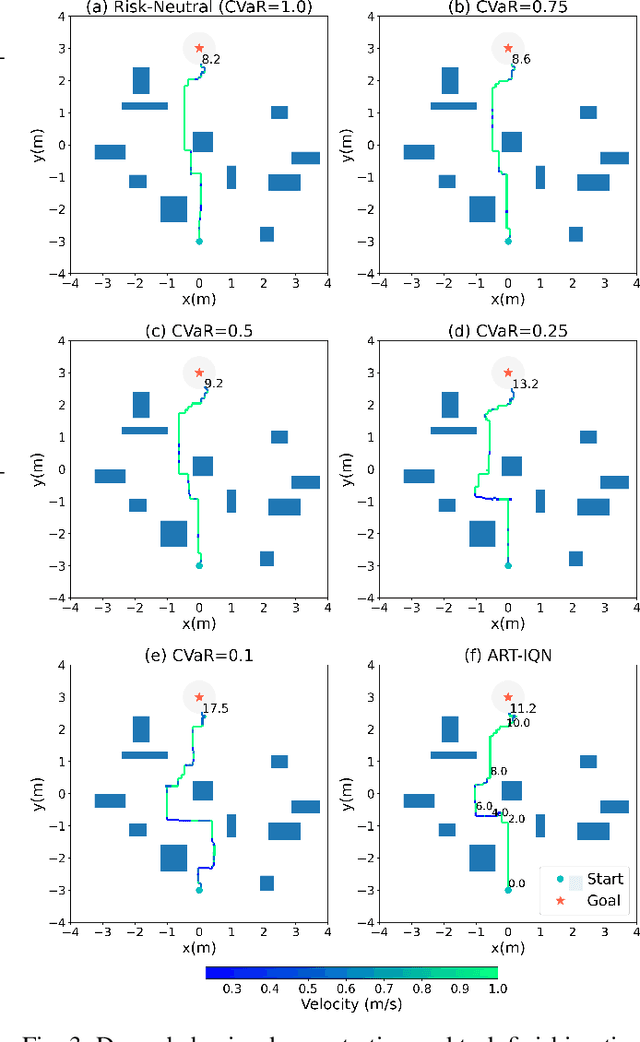
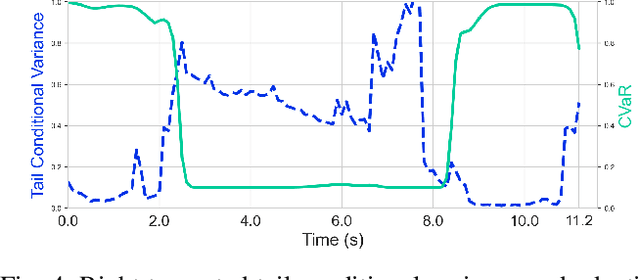
Enabling robots with the capability of assessing risk and making risk-aware decisions is widely considered a key step toward ensuring robustness for robots operating under uncertainty. In this paper, we consider the specific case of a nano drone robot learning to navigate an apriori unknown environment while avoiding obstacles under partial observability. We present a distributional reinforcement learning framework in order to learn adaptive risk tendency policies. Specifically, we propose to use tail conditional variance of the learnt action-value distribution as an uncertainty measurement, and use a exponentially weighted average forecasting algorithm to automatically adapt the risk-tendency at run-time based on the observed uncertainty in the environment. We show our algorithm can adjust its risk-sensitivity on the fly both in simulation and real-world experiments and achieving better performance than risk-neutral policy or risk-averse policies. Code and real-world experiment video can be found in this repository: \url{https://github.com/tudelft/risk-sensitive-rl.git}
LiveMap: Real-Time Dynamic Map in Automotive Edge Computing
Dec 16, 2020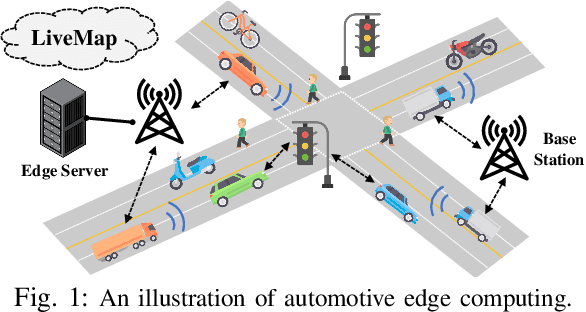
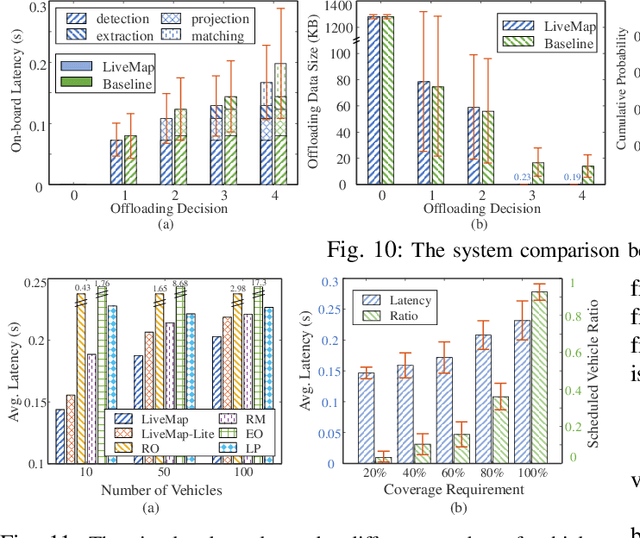
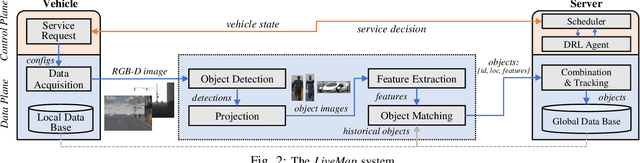
Autonomous driving needs various line-of-sight sensors to perceive surroundings that could be impaired under diverse environment uncertainties such as visual occlusion and extreme weather. To improve driving safety, we explore to wirelessly share perception information among connected vehicles within automotive edge computing networks. Sharing massive perception data in real time, however, is challenging under dynamic networking conditions and varying computation workloads. In this paper, we propose LiveMap, a real-time dynamic map, that detects, matches, and tracks objects on the road with crowdsourcing data from connected vehicles in sub-second. We develop the data plane of LiveMap that efficiently processes individual vehicle data with object detection, projection, feature extraction, object matching, and effectively integrates objects from multiple vehicles with object combination. We design the control plane of LiveMap that allows adaptive offloading of vehicle computations, and develop an intelligent vehicle scheduling and offloading algorithm to reduce the offloading latency of vehicles based on deep reinforcement learning (DRL) techniques. We implement LiveMap on a small-scale testbed and develop a large-scale network simulator. We evaluate the performance of LiveMap with both experiments and simulations, and the results show LiveMap reduces 34.1% average latency than the baseline solution.
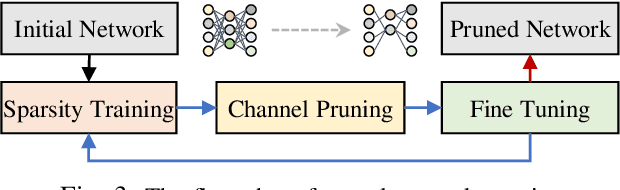
HASA: Hybrid Architecture Search with Aggregation Strategy for Echinococcosis Classification and Ovary Segmentation in Ultrasound Images
Apr 20, 2022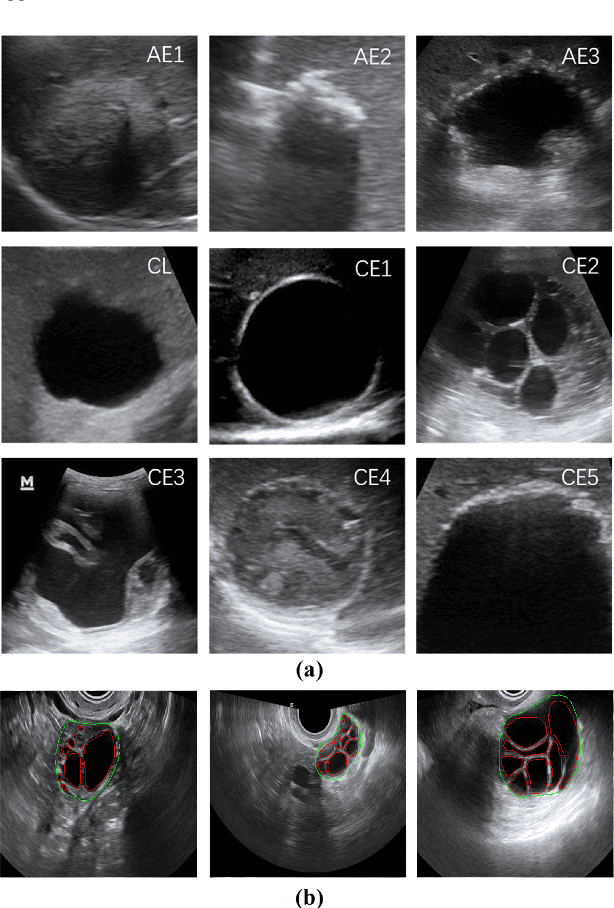
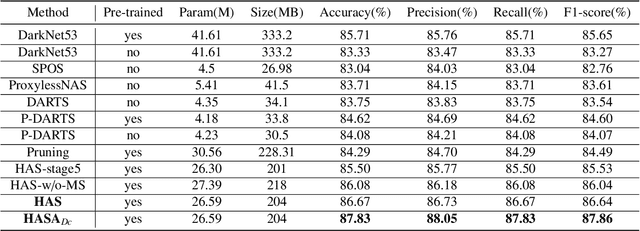
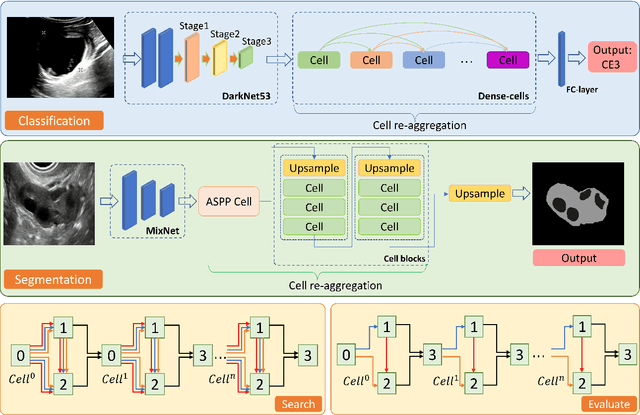
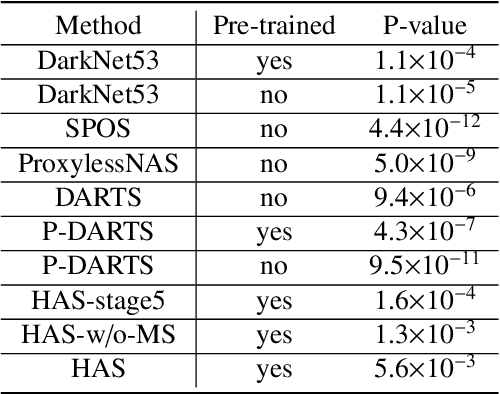
Different from handcrafted features, deep neural networks can automatically learn task-specific features from data. Due to this data-driven nature, they have achieved remarkable success in various areas. However, manual design and selection of suitable network architectures are time-consuming and require substantial effort of human experts. To address this problem, researchers have proposed neural architecture search (NAS) algorithms which can automatically generate network architectures but suffer from heavy computational cost and instability if searching from scratch. In this paper, we propose a hybrid NAS framework for ultrasound (US) image classification and segmentation. The hybrid framework consists of a pre-trained backbone and several searched cells (i.e., network building blocks), which takes advantage of the strengths of both NAS and the expert knowledge from existing convolutional neural networks. Specifically, two effective and lightweight operations, a mixed depth-wise convolution operator and a squeeze-and-excitation block, are introduced into the candidate operations to enhance the variety and capacity of the searched cells. These two operations not only decrease model parameters but also boost network performance. Moreover, we propose a re-aggregation strategy for the searched cells, aiming to further improve the performance for different vision tasks. We tested our method on two large US image datasets, including a 9-class echinococcosis dataset containing 9566 images for classification and an ovary dataset containing 3204 images for segmentation. Ablation experiments and comparison with other handcrafted or automatically searched architectures demonstrate that our method can generate more powerful and lightweight models for the above US image classification and segmentation tasks.