 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeakerCard-1M: An Evidence-Grounded Speaker Card Corpus for In-the-Wild Speaker Verification
Jun 03, 2026Modern speaker verification (SV) systems rely on speaker embeddings that are effective but difficult to interpret or query in natural language. Most existing speech-text corpora target controllable synthesis or utterance-level captioning, and provide limited speaker-level supervision for in-the-wild speaker recognition. This paper introduces SpeakerCard-1M, a bilingual speaker-centric resource for evidence-grounded SV, derived from VoxCeleb1/2 and CN-Celeb1/2, where the "-1M" suffix refers to the 1.78M utterance-level captions contained in the release. We adopt a tool-first, LLM-last approach: ten acoustic probes produce field-level evidence, the evidence is aggregated into speaker profiles under a schema that separates relatively stable traits from utterance-level states, and bilingual Speaker Cards are rendered by a constrained LLM that sees only the structured fields. The release includes 56.7K Speaker Card records over 10.2K speakers, 1.78M utterance-level captions, and speaker-ID-disjoint hard-negative triplets. We further define two SV-oriented cross-modal protocols, bidirectional Speaker-Text Retrieval (T2S-R / S2T-R) and Attribute-Conditioned Verification (AC-Verify), and compare a dual-encoder baseline against recent audio language models under a zero-shot forced-choice setting. Joint audio-text training increases VoxCeleb1-O EER by 0.31% absolute over the audio-only baseline. Under a style-symmetric LLM-generated counterfactual protocol, eight recent audio language models (7B-30B+ parameters, both open- and closed-source) score 49-77% on pitch-level AC-Verify under two-way forced choice, compared with 88.66% reached by our dual encoder.
FLiP: Towards understanding and interpreting multimodal multilingual sentence embeddings
Apr 20, 2026This paper presents factorized linear projection (FLiP) models for understanding pretrained sentence embedding spaces. We train FLiP models to recover the lexical content from multilingual (LaBSE), multimodal (SONAR) and API-based (Gemini) sentence embedding spaces in several high- and mid-resource languages. We show that FLiP can recall more than 75% of lexical content from the embeddings, significantly outperforming existing non-factorized baselines. Using this as a diagnostic tool, we uncover the modality and language biases across the selected sentence encoders and provide practitioners with intrinsic insights about the encoders without relying on conventional downstream evaluation tasks. Our implementation is public https://github.com/BUTSpeechFIT/FLiP.
Factors affecting the in-context learning abilities of LLMs for dialogue state tracking
Jun 10, 2025This study explores the application of in-context learning (ICL) to the dialogue state tracking (DST) problem and investigates the factors that influence its effectiveness. We use a sentence embedding based k-nearest neighbour method to retrieve the suitable demonstrations for ICL. The selected demonstrations, along with the test samples, are structured within a template as input to the LLM. We then conduct a systematic study to analyse the impact of factors related to demonstration selection and prompt context on DST performance. This work is conducted using the MultiWoZ2.4 dataset and focuses primarily on the OLMo-7B-instruct, Mistral-7B-Instruct-v0.3, and Llama3.2-3B-Instruct models. Our findings provide several useful insights on in-context learning abilities of LLMs for dialogue state tracking.
Approaching Dialogue State Tracking via Aligning Speech Encoders and LLMs
Jun 10, 2025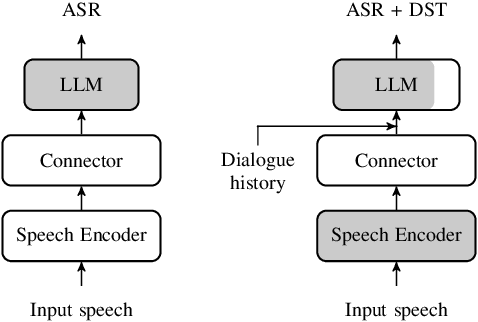
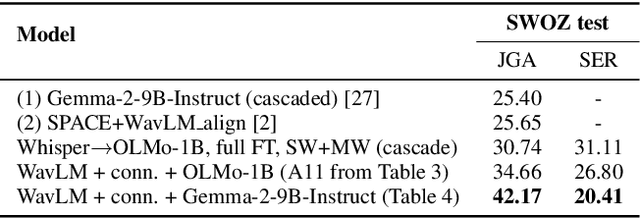
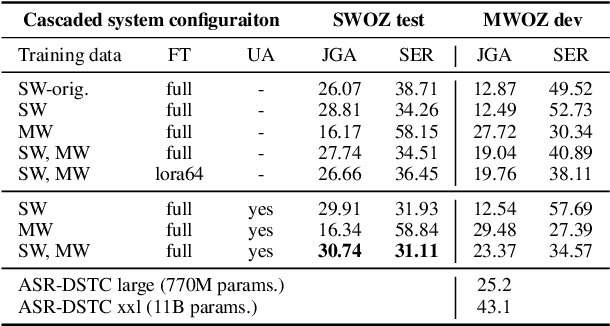
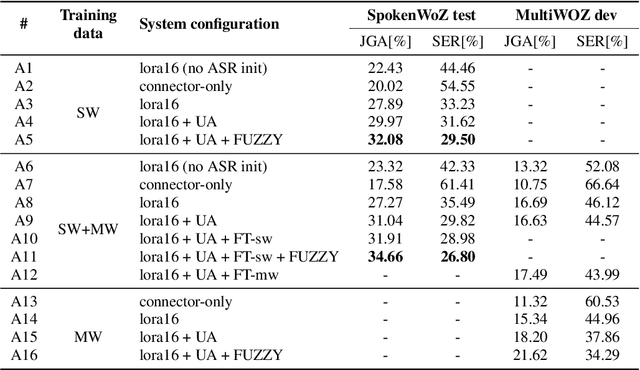
In this work, we approach spoken Dialogue State Tracking (DST) by bridging the representation spaces of speech encoders and LLMs via a small connector module, with a focus on fully open-sourced and open-data components (WavLM-large, OLMo). We focus on ablating different aspects of such systems including full/LoRA adapter fine-tuning, the effect of agent turns in the dialogue history, as well as fuzzy matching-based output post-processing, which greatly improves performance of our systems on named entities in the dialogue slot values. We conduct our experiments on the SpokenWOZ dataset, and additionally utilize the Speech-Aware MultiWOZ dataset to augment our training data. Ultimately, our best-performing WavLM + connector + OLMo-1B aligned models achieve state of the art on the SpokenWOZ test set (34.66% JGA), and our system with Gemma-2-9B-instruct further surpasses this result, reaching 42.17% JGA on SpokenWOZ test.
Analysis of ABC Frontend Audio Systems for the NIST-SRE24
May 21, 2025We present a comprehensive analysis of the embedding extractors (frontends) developed by the ABC team for the audio track of NIST SRE 2024. We follow the two scenarios imposed by NIST: using only a provided set of telephone recordings for training (fixed) or adding publicly available data (open condition). Under these constraints, we develop the best possible speaker embedding extractors for the pre-dominant conversational telephone speech (CTS) domain. We explored architectures based on ResNet with different pooling mechanisms, recently introduced ReDimNet architecture, as well as a system based on the XLS-R model, which represents the family of large pre-trained self-supervised models. In open condition, we train on VoxBlink2 dataset, containing 110 thousand speakers across multiple languages. We observed a good performance and robustness of VoxBlink-trained models, and our experiments show practical recipes for developing state-of-the-art frontends for speaker recognition.
State-of-the-art Embeddings with Video-free Segmentation of the Source VoxCeleb Data
Oct 03, 2024



In this paper, we refine and validate our method for training speaker embedding extractors using weak annotations. More specifically, we use only the audio stream of the source VoxCeleb videos and the names of the celebrities without knowing the time intervals in which they appear in the recording. We experiment with hyperparameters and embedding extractors based on ResNet and WavLM. We show that the method achieves state-of-the-art results in speaker verification, comparable with training the extractors in a standard supervised way on the VoxCeleb dataset. We also extend it by considering segments belonging to unknown speakers appearing alongside the celebrities, which are typically being discarded. Overall, our approach can be used for directly training state-of-the-art embedding extractors or as an alternative to the VoxCeleb-like pipeline for dataset creation without needing image modality.
BUT Systems and Analyses for the ASVspoof 5 Challenge
Aug 20, 2024



This paper describes the BUT submitted systems for the ASVspoof 5 challenge, along with analyses. For the conventional deepfake detection task, we use ResNet18 and self-supervised models for the closed and open conditions, respectively. In addition, we analyze and visualize different combinations of speaker information and spoofing information as label schemes for training. For spoofing-robust automatic speaker verification (SASV), we introduce effective priors and propose using logistic regression to jointly train affine transformations of the countermeasure scores and the automatic speaker verification scores in such a way that the SASV LLR is optimized.
Improving Speaker Verification with Self-Pretrained Transformer Models
May 17, 2023



Recently, fine-tuning large pre-trained Transformer models using downstream datasets has received a rising interest. Despite their success, it is still challenging to disentangle the benefits of large-scale datasets and Transformer structures from the limitations of the pre-training. In this paper, we introduce a hierarchical training approach, named self-pretraining, in which Transformer models are pretrained and finetuned on the same dataset. Three pre-trained models including HuBERT, Conformer and WavLM are evaluated on four different speaker verification datasets with varying sizes. Our experiments show that these self-pretrained models achieve competitive performance on downstream speaker verification tasks with only one-third of the data compared to Librispeech pretraining, such as VoxCeleb1 and CNCeleb1. Furthermore, when pre-training only on the VoxCeleb2-dev, the Conformer model outperforms the one pre-trained on 94k hours of data using the same fine-tuning settings.
Parameter-efficient transfer learning of pre-trained Transformer models for speaker verification using adapters
Oct 28, 2022



Recently, the pre-trained Transformer models have received a rising interest in the field of speech processing thanks to their great success in various downstream tasks. However, most fine-tuning approaches update all the parameters of the pre-trained model, which becomes prohibitive as the model size grows and sometimes results in overfitting on small datasets. In this paper, we conduct a comprehensive analysis of applying parameter-efficient transfer learning (PETL) methods to reduce the required learnable parameters for adapting to speaker verification tasks. Specifically, during the fine-tuning process, the pre-trained models are frozen, and only lightweight modules inserted in each Transformer block are trainable (a method known as adapters). Moreover, to boost the performance in a cross-language low-resource scenario, the Transformer model is further tuned on a large intermediate dataset before directly fine-tuning it on a small dataset. With updating fewer than 4% of parameters, (our proposed) PETL-based methods achieve comparable performances with full fine-tuning methods (Vox1-O: 0.55%, Vox1-E: 0.82%, Vox1-H:1.73%).
Training Speaker Embedding Extractors Using Multi-Speaker Audio with Unknown Speaker Boundaries
Mar 29, 2022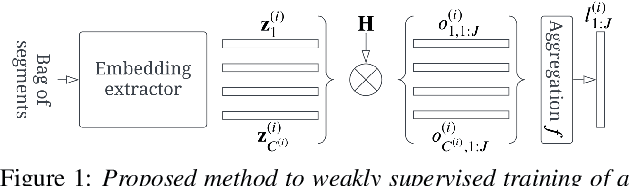
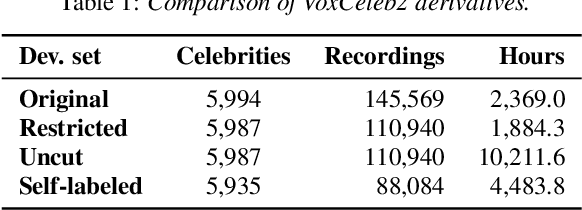
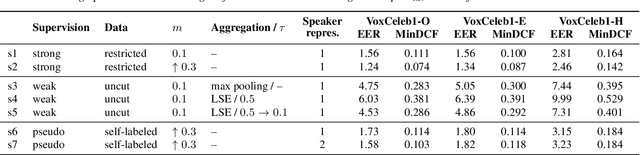
In this paper, we demonstrate a method for training speaker embedding extractors using weak annotation. More specifically, we are using the full VoxCeleb recordings and the name of the celebrities appearing on each video without knowledge of the time intervals the celebrities appear in the video. We show that by combining a baseline speaker diarization algorithm that requires no training or parameter tuning, a modified loss with aggregation over segments, and a two-stage training approach, we are able to train a competitive ResNet-based embedding extractor. Finally, we experiment with two different aggregation functions and analyze their behaviour in terms of their gradients.