 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongCat-Flash-Thinking-2601 Technical Report
Jan 23, 2026We introduce LongCat-Flash-Thinking-2601, a 560-billion-parameter open-source Mixture-of-Experts (MoE) reasoning model with superior agentic reasoning capability. LongCat-Flash-Thinking-2601 achieves state-of-the-art performance among open-source models on a wide range of agentic benchmarks, including agentic search, agentic tool use, and tool-integrated reasoning. Beyond benchmark performance, the model demonstrates strong generalization to complex tool interactions and robust behavior under noisy real-world environments. Its advanced capability stems from a unified training framework that combines domain-parallel expert training with subsequent fusion, together with an end-to-end co-design of data construction, environments, algorithms, and infrastructure spanning from pre-training to post-training. In particular, the model's strong generalization capability in complex tool-use are driven by our in-depth exploration of environment scaling and principled task construction. To optimize long-tailed, skewed generation and multi-turn agentic interactions, and to enable stable training across over 10,000 environments spanning more than 20 domains, we systematically extend our asynchronous reinforcement learning framework, DORA, for stable and efficient large-scale multi-environment training. Furthermore, recognizing that real-world tasks are inherently noisy, we conduct a systematic analysis and decomposition of real-world noise patterns, and design targeted training procedures to explicitly incorporate such imperfections into the training process, resulting in improved robustness for real-world applications. To further enhance performance on complex reasoning tasks, we introduce a Heavy Thinking mode that enables effective test-time scaling by jointly expanding reasoning depth and width through intensive parallel thinking.
Data-Juicer Sandbox: A Comprehensive Suite for Multimodal Data-Model Co-development
Jul 16, 2024



The emergence of large-scale multi-modal generative models has drastically advanced artificial intelligence, introducing unprecedented levels of performance and functionality. However, optimizing these models remains challenging due to historically isolated paths of model-centric and data-centric developments, leading to suboptimal outcomes and inefficient resource utilization. In response, we present a novel sandbox suite tailored for integrated data-model co-development. This sandbox provides a comprehensive experimental platform, enabling rapid iteration and insight-driven refinement of both data and models. Our proposed "Probe-Analyze-Refine" workflow, validated through applications on state-of-the-art LLaVA-like and DiT based models, yields significant performance boosts, such as topping the VBench leaderboard. We also uncover fruitful insights gleaned from exhaustive benchmarks, shedding light on the critical interplay between data quality, diversity, and model behavior. With the hope of fostering deeper understanding and future progress in multi-modal data and generative modeling, our codes, datasets, and models are maintained and accessible at https://github.com/modelscope/data-juicer/blob/main/docs/Sandbox.md.
UniDM: A Unified Framework for Data Manipulation with Large Language Models
May 10, 2024



Designing effective data manipulation methods is a long standing problem in data lakes. Traditional methods, which rely on rules or machine learning models, require extensive human efforts on training data collection and tuning models. Recent methods apply Large Language Models (LLMs) to resolve multiple data manipulation tasks. They exhibit bright benefits in terms of performance but still require customized designs to fit each specific task. This is very costly and can not catch up with the requirements of big data lake platforms. In this paper, inspired by the cross-task generality of LLMs on NLP tasks, we pave the first step to design an automatic and general solution to tackle with data manipulation tasks. We propose UniDM, a unified framework which establishes a new paradigm to process data manipulation tasks using LLMs. UniDM formalizes a number of data manipulation tasks in a unified form and abstracts three main general steps to solve each task. We develop an automatic context retrieval to allow the LLMs to retrieve data from data lakes, potentially containing evidence and factual information. For each step, we design effective prompts to guide LLMs to produce high quality results. By our comprehensive evaluation on a variety of benchmarks, our UniDM exhibits great generality and state-of-the-art performance on a wide variety of data manipulation tasks.
Text-to-SQL Empowered by Large Language Models: A Benchmark Evaluation
Sep 08, 2023



Large language models (LLMs) have emerged as a new paradigm for Text-to-SQL task. However, the absence of a systematical benchmark inhibits the development of designing effective, efficient and economic LLM-based Text-to-SQL solutions. To address this challenge, in this paper, we first conduct a systematical and extensive comparison over existing prompt engineering methods, including question representation, example selection and example organization, and with these experimental results, we elaborate their pros and cons. Based on these findings, we propose a new integrated solution, named DAIL-SQL, which refreshes the Spider leaderboard with 86.6% execution accuracy and sets a new bar. To explore the potential of open-source LLM, we investigate them in various scenarios, and further enhance their performance with supervised fine-tuning. Our explorations highlight open-source LLMs' potential in Text-to-SQL, as well as the advantages and disadvantages of the supervised fine-tuning. Additionally, towards an efficient and economic LLM-based Text-to-SQL solution, we emphasize the token efficiency in prompt engineering and compare the prior studies under this metric. We hope that our work provides a deeper understanding of Text-to-SQL with LLMs, and inspires further investigations and broad applications.
HIE-SQL: History Information Enhanced Network for Context-Dependent Text-to-SQL Semantic Parsing
Apr 02, 2022
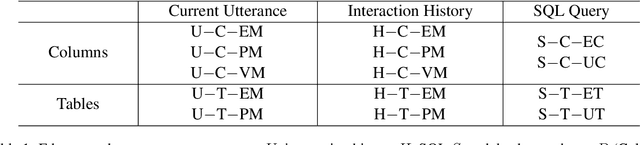
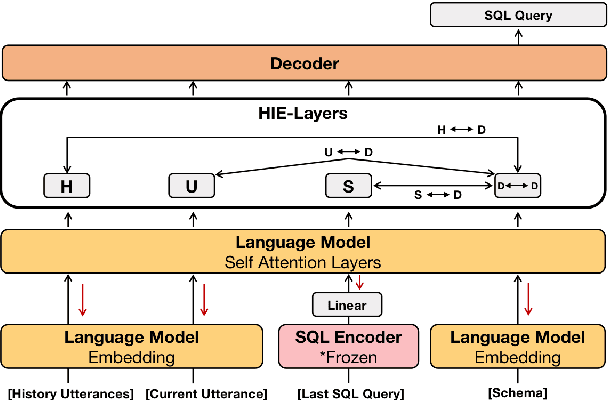

Recently, context-dependent text-to-SQL semantic parsing which translates natural language into SQL in an interaction process has attracted a lot of attention. Previous works leverage context-dependence information either from interaction history utterances or the previous predicted SQL queries but fail in taking advantage of both since of the mismatch between natural language and logic-form SQL. In this work, we propose a History Information Enhanced text-to-SQL model (HIE-SQL) to exploit context-dependence information from both history utterances and the last predicted SQL query. In view of the mismatch, we treat natural language and SQL as two modalities and propose a bimodal pre-trained model to bridge the gap between them. Besides, we design a schema-linking graph to enhance connections from utterances and the SQL query to the database schema. We show our history information enhanced methods improve the performance of HIE-SQL by a significant margin, which achieves new state-of-the-art results on the two context-dependent text-to-SQL benchmarks, the SparC and CoSQL datasets, at the writing time.
Sequential Mechanisms for Multi-type Resource Allocation
Feb 21, 2021
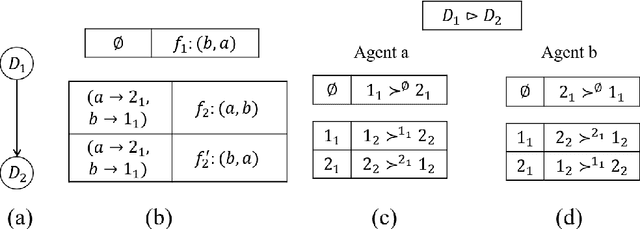
Several resource allocation problems involve multiple types of resources, with a different agency being responsible for "locally" allocating the resources of each type, while a central planner wishes to provide a guarantee on the properties of the final allocation given agents' preferences. We study the relationship between properties of the local mechanisms, each responsible for assigning all of the resources of a designated type, and the properties of a sequential mechanism which is composed of these local mechanisms, one for each type, applied sequentially, under lexicographic preferences, a well studied model of preferences over multiple types of resources in artificial intelligence and economics. We show that when preferences are O-legal, meaning that agents share a common importance order on the types, sequential mechanisms satisfy the desirable properties of anonymity, neutrality, non-bossiness, or Pareto-optimality if and only if every local mechanism also satisfies the same property, and they are applied sequentially according to the order O. Our main results are that under O-legal lexicographic preferences, every mechanism satisfying strategyproofness and a combination of these properties must be a sequential composition of local mechanisms that are also strategyproof, and satisfy the same combinations of properties.
Probabilistic Serial Mechanism for Multi-Type Resource Allocation
Apr 25, 2020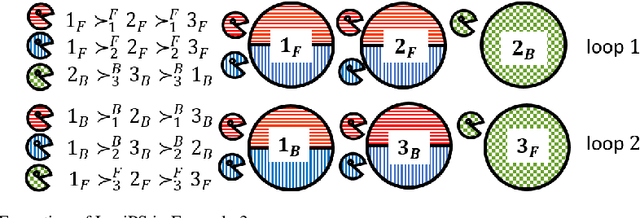
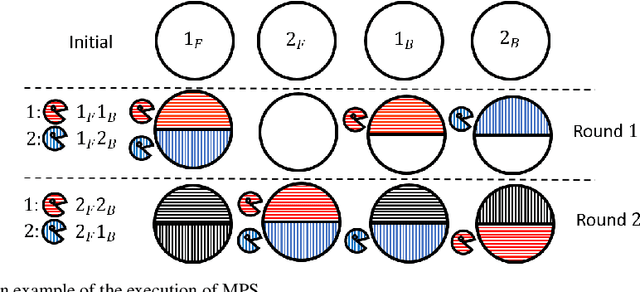
In multi-type resource allocation (MTRA) problems, there are p $\ge$ 2 types of items, and n agents, who each demand one unit of items of each type, and have strict linear preferences over bundles consisting of one item of each type. For MTRAs with indivisible items, our first result is an impossibility theorem that is in direct contrast to the single type (p = 1) setting: No mechanism, the output of which is always decomposable into a probability distribution over discrete assignments (where no item is split between agents), can satisfy both sd-efficiency and sd-envy-freeness. To circumvent this impossibility result, we consider the natural assumption of lexicographic preference, and provide an extension of the probabilistic serial (PS), called lexicographic probabilistic serial (LexiPS).We prove that LexiPS satisfies sd-efficiency and sd-envy-freeness, retaining the desirable properties of PS. Moreover, LexiPS satisfies sd-weak-strategyproofness when agents are not allowed to misreport their importance orders. For MTRAs with divisible items, we show that the existing multi-type probabilistic serial (MPS) mechanism satisfies the stronger efficiency notion of lexi-efficiency, and is sd-envy-free under strict linear preferences, and sd-weak-strategyproof under lexicographic preferences. We also prove that MPS can be characterized both by leximin-ptimality and by item-wise ordinal fairness, and the family of eating algorithms which MPS belongs to can be characterized by no-generalized-cycle condition.
Multi-type Resource Allocation with Partial Preferences
Jun 13, 2019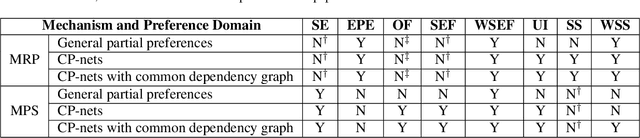
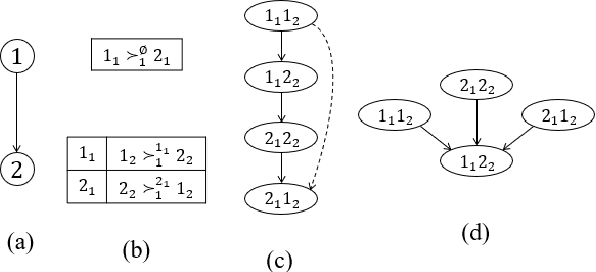
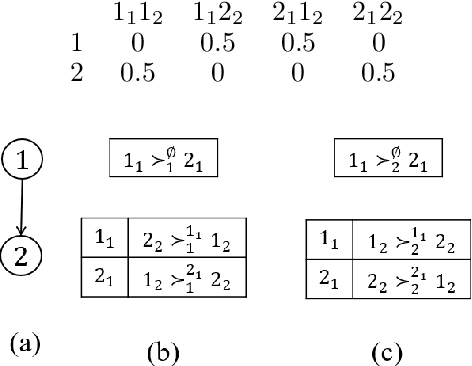
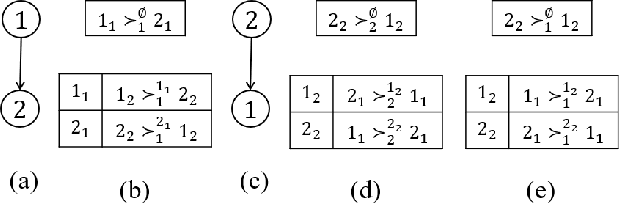
We propose multi-type probabilistic serial (MPS) and multi-type random priority (MRP) as extensions of the well known PS and RP mechanisms to the multi-type resource allocation problem (MTRA) with partial preferences. In our setting, there are multiple types of divisible items, and a group of agents who have partial order preferences over bundles consisting of one item of each type. We show that for the unrestricted domain of partial order preferences, no mechanism satisfies both sd-efficiency and sd-envy-freeness. Notwithstanding this impossibility result, our main message is positive: When agents' preferences are represented by acyclic CP-nets, MPS satisfies sd-efficiency, sd-envy-freeness, ordinal fairness, and upper invariance, while MRP satisfies ex-post-efficiency, sd-strategy-proofness, and upper invariance, recovering the properties of PS and RP.
A Neutrosophic Description Logic
Mar 14, 2008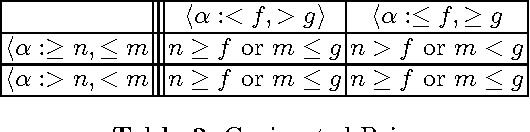

Description Logics (DLs) are appropriate, widely used, logics for managing structured knowledge. They allow reasoning about individuals and concepts, i.e. set of individuals with common properties. Typically, DLs are limited to dealing with crisp, well defined concepts. That is, concepts for which the problem whether an individual is an instance of it is yes/no question. More often than not, the concepts encountered in the real world do not have a precisely defined criteria of membership: we may say that an individual is an instance of a concept only to a certain degree, depending on the individual's properties. The DLs that deal with such fuzzy concepts are called fuzzy DLs. In order to deal with fuzzy, incomplete, indeterminate and inconsistent concepts, we need to extend the fuzzy DLs, combining the neutrosophic logic with a classical DL. In particular, concepts become neutrosophic (here neutrosophic means fuzzy, incomplete, indeterminate, and inconsistent), thus reasoning about neutrosophic concepts is supported. We'll define its syntax, its semantics, and describe its properties.
* 18 pages. Presented at the IEEE International Conference on Granular Computing, Georgia State University, Atlanta, USA, May 2006