 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGroupGuard: A Framework for Modeling and Defending Collusive Attacks in Multi-Agent Systems
Mar 14, 2026While large language model-based agents demonstrate great potential in collaborative tasks, their interactivity also introduces security vulnerabilities. In this paper, we propose and model group collusive attacks, a highly destructive threat in which multiple agents coordinate via sociological strategies to mislead the system. To address this challenge, we introduce GroupGuard, a training-free defense framework that employs a multi-layered defense strategy, including continuous graph-based monitoring, active honeypot inducement, and structural pruning, to identify and isolate collusive agents. Experimental results across five datasets and four topologies demonstrate that group collusive attacks increase the attack success rate by up to 15\% compared to individual attacks. GroupGuard consistently achieves high detection accuracy (up to 88\%) and effectively restores collaborative performance, providing a robust solution for securing multi-agent systems.
Nexus-Gen: A Unified Model for Image Understanding, Generation, and Editing
Apr 30, 2025Unified multimodal large language models (MLLMs) aim to integrate multimodal understanding and generation abilities through a single framework. Despite their versatility, existing open-source unified models exhibit performance gaps against domain-specific architectures. To bridge this gap, we present Nexus-Gen, a unified model that synergizes the language reasoning capabilities of LLMs with the image synthesis power of diffusion models. To align the embedding space of the LLM and diffusion model, we conduct a dual-phase alignment training process. (1) The autoregressive LLM learns to predict image embeddings conditioned on multimodal inputs, while (2) the vision decoder is trained to reconstruct high-fidelity images from these embeddings. During training the LLM, we identified a critical discrepancy between the autoregressive paradigm's training and inference phases, where error accumulation in continuous embedding space severely degrades generation quality. To avoid this issue, we introduce a prefilled autoregression strategy that prefills input sequence with position-embedded special tokens instead of continuous embeddings. Through dual-phase training, Nexus-Gen has developed the integrated capability to comprehensively address the image understanding, generation and editing tasks. All models, datasets, and codes are published at https://github.com/modelscope/Nexus-Gen.git to facilitate further advancements across the field.
Breaking the Modality Barrier: Universal Embedding Learning with Multimodal LLMs
Apr 24, 2025The Contrastive Language-Image Pre-training (CLIP) framework has become a widely used approach for multimodal representation learning, particularly in image-text retrieval and clustering. However, its efficacy is constrained by three key limitations: (1) text token truncation, (2) isolated image-text encoding, and (3) deficient compositionality due to bag-of-words behavior. While recent Multimodal Large Language Models (MLLMs) have demonstrated significant advances in generalized vision-language understanding, their potential for learning transferable multimodal representations remains underexplored.In this work, we present UniME (Universal Multimodal Embedding), a novel two-stage framework that leverages MLLMs to learn discriminative representations for diverse downstream tasks. In the first stage, we perform textual discriminative knowledge distillation from a powerful LLM-based teacher model to enhance the embedding capability of the MLLM\'s language component. In the second stage, we introduce hard negative enhanced instruction tuning to further advance discriminative representation learning. Specifically, we initially mitigate false negative contamination and then sample multiple hard negatives per instance within each batch, forcing the model to focus on challenging samples. This approach not only improves discriminative power but also enhances instruction-following ability in downstream tasks. We conduct extensive experiments on the MMEB benchmark and multiple retrieval tasks, including short and long caption retrieval and compositional retrieval. Results demonstrate that UniME achieves consistent performance improvement across all tasks, exhibiting superior discriminative and compositional capabilities.
EliGen: Entity-Level Controlled Image Generation with Regional Attention
Jan 02, 2025



Recent advancements in diffusion models have significantly advanced text-to-image generation, yet global text prompts alone remain insufficient for achieving fine-grained control over individual entities within an image. To address this limitation, we present EliGen, a novel framework for Entity-Level controlled Image Generation. We introduce regional attention, a mechanism for diffusion transformers that requires no additional parameters, seamlessly integrating entity prompts and arbitrary-shaped spatial masks. By contributing a high-quality dataset with fine-grained spatial and semantic entity-level annotations, we train EliGen to achieve robust and accurate entity-level manipulation, surpassing existing methods in both positional control precision and image quality. Additionally, we propose an inpainting fusion pipeline, extending EliGen to multi-entity image inpainting tasks. We further demonstrate its flexibility by integrating it with community models such as IP-Adapter and MLLM, unlocking new creative possibilities. The source code, dataset, and model will be released publicly.
Minimum Tuning to Unlock Long Output from LLMs with High Quality Data as the Key
Oct 15, 2024As large language models rapidly evolve to support longer context, there is a notable disparity in their capability to generate output at greater lengths. Recent study suggests that the primary cause for this imbalance may arise from the lack of data with long-output during alignment training. In light of this observation, attempts are made to re-align foundation models with data that fills the gap, which result in models capable of generating lengthy output when instructed. In this paper, we explore the impact of data-quality in tuning a model for long output, and the possibility of doing so from the starting points of human-aligned (instruct or chat) models. With careful data curation, we show that it possible to achieve similar performance improvement in our tuned models, with only a small fraction of training data instances and compute. In addition, we assess the generalizability of such approaches by applying our tuning-recipes to several models. our findings suggest that, while capacities for generating long output vary across different models out-of-the-box, our approach to tune them with high-quality data using lite compute, consistently yields notable improvement across all models we experimented on. We have made public our curated dataset for tuning long-writing capability, the implementations of model tuning and evaluation, as well as the fine-tuned models, all of which can be openly-accessed.
SWIFT:A Scalable lightWeight Infrastructure for Fine-Tuning
Aug 13, 2024



Recent development in Large Language Models (LLMs) and Multi-modal Large Language Models (MLLMs) have leverage Attention-based Transformer architectures and achieved superior performance and generalization capabilities. They have since covered extensive areas of traditional learning tasks. For instance, text-based tasks such as text-classification and sequence-labeling, as well as multi-modal tasks like Visual Question Answering (VQA) and Optical Character Recognition (OCR), which were previously addressed using different models, can now be tackled based on one foundation model. Consequently, the training and lightweight fine-tuning of LLMs and MLLMs, especially those based on Transformer architecture, has become particularly important. In recognition of these overwhelming needs, we develop SWIFT, a customizable one-stop infrastructure for large models. With support of over $300+$ LLMs and $50+$ MLLMs, SWIFT stands as the open-source framework that provide the \textit{most comprehensive support} for fine-tuning large models. In particular, it is the first training framework that provides systematic support for MLLMs. In addition to the core functionalities of fine-tuning, SWIFT also integrates post-training processes such as inference, evaluation, and model quantization, to facilitate fast adoptions of large models in various application scenarios. With a systematic integration of various training techniques, SWIFT offers helpful utilities such as benchmark comparisons among different training techniques for large models. For fine-tuning models specialized in agent framework, we show that notable improvements on the ToolBench leader-board can be achieved by training with customized dataset on SWIFT, with an increase of 5.2%-21.8% in the Act.EM metric over various baseline models, a reduction in hallucination by 1.6%-14.1%, and an average performance improvement of 8%-17%.
FaceChain: A Playground for Identity-Preserving Portrait Generation
Aug 28, 2023



Recent advancement in personalized image generation have unveiled the intriguing capability of pre-trained text-to-image models on learning identity information from a collection of portrait images. However, existing solutions can be vulnerable in producing truthful details, and usually suffer from several defects such as (i) The generated face exhibit its own unique characteristics, \ie facial shape and facial feature positioning may not resemble key characteristics of the input, and (ii) The synthesized face may contain warped, blurred or corrupted regions. In this paper, we present FaceChain, a personalized portrait generation framework that combines a series of customized image-generation model and a rich set of face-related perceptual understanding models (\eg, face detection, deep face embedding extraction, and facial attribute recognition), to tackle aforementioned challenges and to generate truthful personalized portraits, with only a handful of portrait images as input. Concretely, we inject several SOTA face models into the generation procedure, achieving a more efficient label-tagging, data-processing, and model post-processing compared to previous solutions, such as DreamBooth ~\cite{ruiz2023dreambooth} , InstantBooth ~\cite{shi2023instantbooth} , or other LoRA-only approaches ~\cite{hu2021lora} . Through the development of FaceChain, we have identified several potential directions to accelerate development of Face/Human-Centric AIGC research and application. We have designed FaceChain as a framework comprised of pluggable components that can be easily adjusted to accommodate different styles and personalized needs. We hope it can grow to serve the burgeoning needs from the communities. FaceChain is open-sourced under Apache-2.0 license at \url{https://github.com/modelscope/facechain}.
Rethink Long-tailed Recognition with Vision Transforms
Feb 28, 2023In the real world, data tends to follow long-tailed distributions w.r.t. class or attribution, motivating the challenging Long-Tailed Recognition (LTR) problem. In this paper, we revisit recent LTR methods with promising Vision Transformers (ViT). We figure out that 1) ViT is hard to train with long-tailed data. 2) ViT learns generalized features in an unsupervised manner, like mask generative training, either on long-tailed or balanced datasets. Hence, we propose to adopt unsupervised learning to utilize long-tailed data. Furthermore, we propose the Predictive Distribution Calibration (PDC) as a novel metric for LTR, where the model tends to simply classify inputs into common classes. Our PDC can measure the model calibration of predictive preferences quantitatively. On this basis, we find many LTR approaches alleviate it slightly, despite the accuracy improvement. Extensive experiments on benchmark datasets validate that PDC reflects the model's predictive preference precisely, which is consistent with the visualization.
M2-Net: Multi-stages Specular Highlight Detection and Removal in Multi-scenes
Jul 20, 2022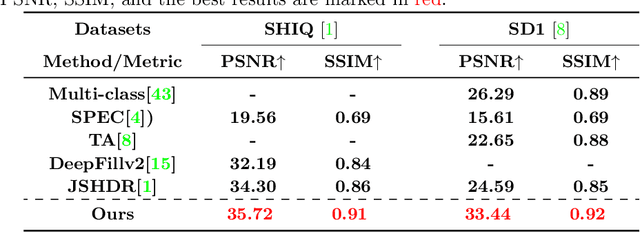
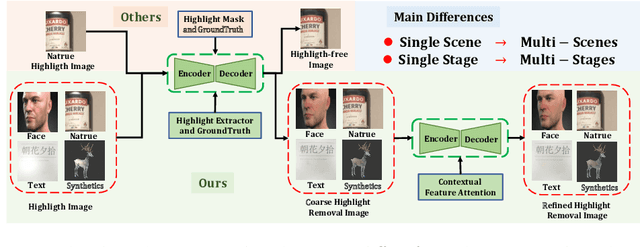
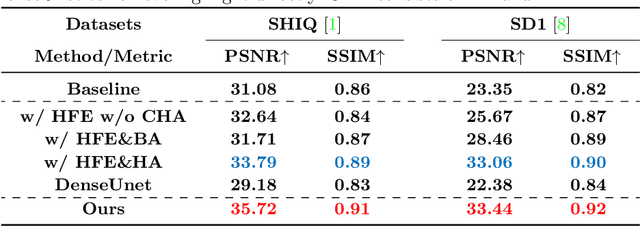
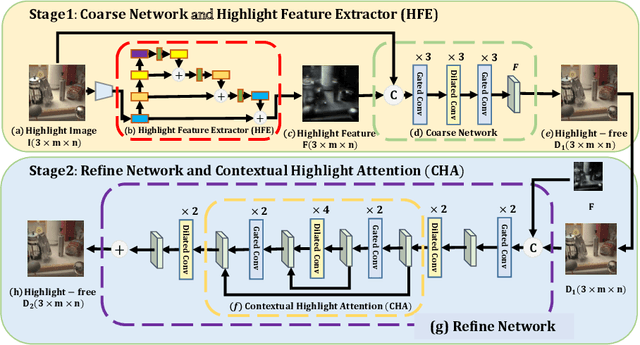
In this paper, we propose a novel uniformity framework for highlight detection and removal in multi-scenes, including synthetic images, face images, natural images, and text images. The framework consists of three main components, highlight feature extractor module, highlight coarse removal module, and highlight refine removal module. Firstly, the highlight feature extractor module can directly separate the highlight feature and non-highlight feature from the original highlight image. Then highlight removal image is obtained using a coarse highlight removal network. To further improve the highlight removal effect, the refined highlight removal image is finally obtained using refine highlight removal module based on contextual highlight attention mechanisms. Extensive experimental results in multiple scenes indicate that the proposed framework can obtain excellent visual effects of highlight removal and achieve state-of-the-art results in several quantitative evaluation metrics. Our algorithm is applied for the first time in video highlight removal with promising results.
HIE-SQL: History Information Enhanced Network for Context-Dependent Text-to-SQL Semantic Parsing
Apr 02, 2022
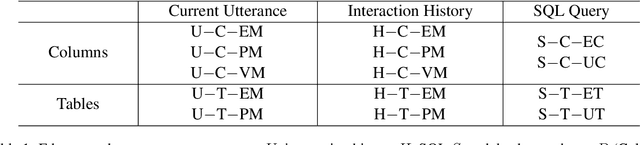
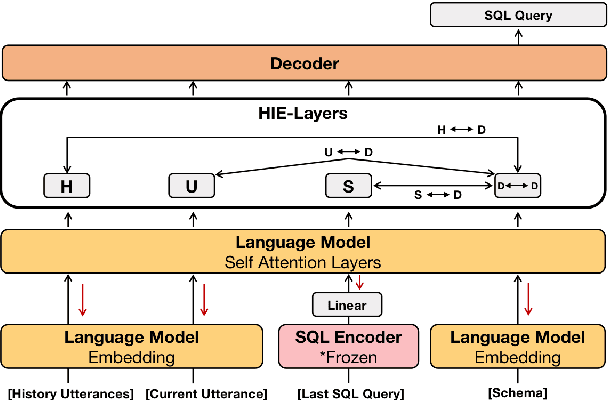

Recently, context-dependent text-to-SQL semantic parsing which translates natural language into SQL in an interaction process has attracted a lot of attention. Previous works leverage context-dependence information either from interaction history utterances or the previous predicted SQL queries but fail in taking advantage of both since of the mismatch between natural language and logic-form SQL. In this work, we propose a History Information Enhanced text-to-SQL model (HIE-SQL) to exploit context-dependence information from both history utterances and the last predicted SQL query. In view of the mismatch, we treat natural language and SQL as two modalities and propose a bimodal pre-trained model to bridge the gap between them. Besides, we design a schema-linking graph to enhance connections from utterances and the SQL query to the database schema. We show our history information enhanced methods improve the performance of HIE-SQL by a significant margin, which achieves new state-of-the-art results on the two context-dependent text-to-SQL benchmarks, the SparC and CoSQL datasets, at the writing time.