 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Rethinking Surgical Captioning: End-to-End Window-Based MLP Transformer Using Patches
Jun 30, 2022
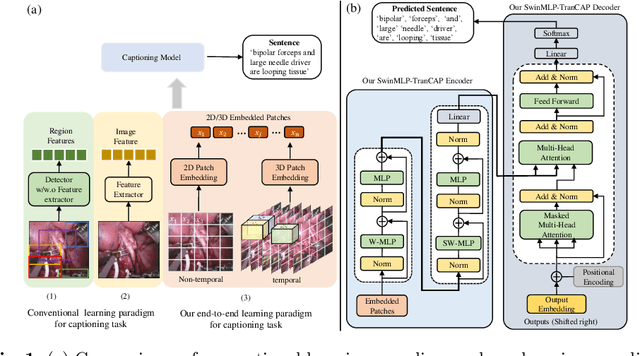
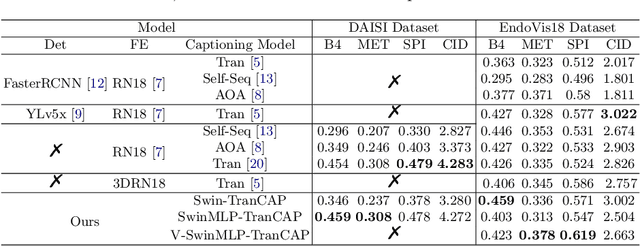
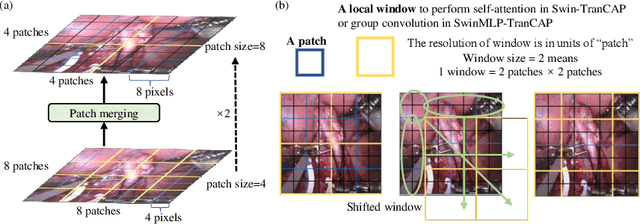
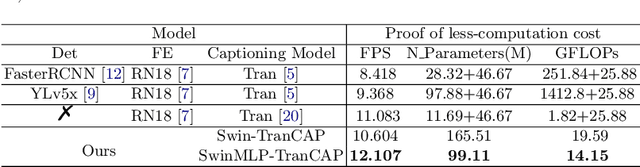
Surgical captioning plays an important role in surgical instruction prediction and report generation. However, the majority of captioning models still rely on the heavy computational object detector or feature extractor to extract regional features. In addition, the detection model requires additional bounding box annotation which is costly and needs skilled annotators. These lead to inference delay and limit the captioning model to deploy in real-time robotic surgery. For this purpose, we design an end-to-end detector and feature extractor-free captioning model by utilizing the patch-based shifted window technique. We propose Shifted Window-Based Multi-Layer Perceptrons Transformer Captioning model (SwinMLP-TranCAP) with faster inference speed and less computation. SwinMLP-TranCAP replaces the multi-head attention module with window-based multi-head MLP. Such deployments primarily focus on image understanding tasks, but very few works investigate the caption generation task. SwinMLP-TranCAP is also extended into a video version for video captioning tasks using 3D patches and windows. Compared with previous detector-based or feature extractor-based models, our models greatly simplify the architecture design while maintaining performance on two surgical datasets. The code is publicly available at https://github.com/XuMengyaAmy/SwinMLP_TranCAP.
Learning Barrier Certificates: Towards Safe Reinforcement Learning with Zero Training-time Violations
Aug 04, 2021
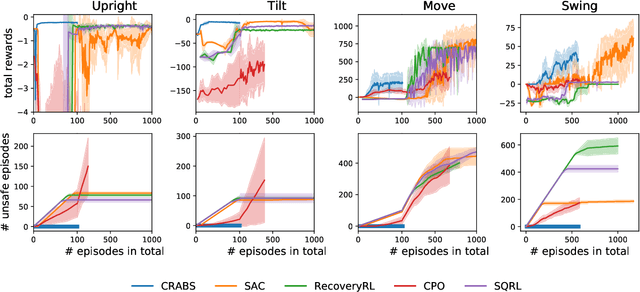
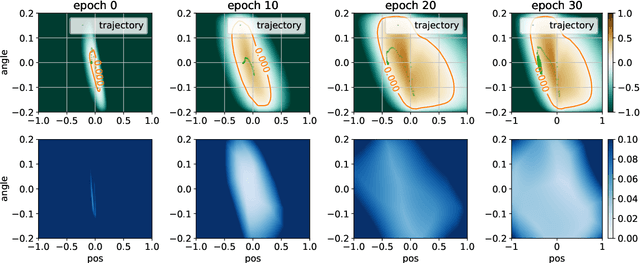
Training-time safety violations have been a major concern when we deploy reinforcement learning algorithms in the real world. This paper explores the possibility of safe RL algorithms with zero training-time safety violations in the challenging setting where we are only given a safe but trivial-reward initial policy without any prior knowledge of the dynamics model and additional offline data. We propose an algorithm, Co-trained Barrier Certificate for Safe RL (CRABS), which iteratively learns barrier certificates, dynamics models, and policies. The barrier certificates, learned via adversarial training, ensure the policy's safety assuming calibrated learned dynamics model. We also add a regularization term to encourage larger certified regions to enable better exploration. Empirical simulations show that zero safety violations are already challenging for a suite of simple environments with only 2-4 dimensional state space, especially if high-reward policies have to visit regions near the safety boundary. Prior methods require hundreds of violations to achieve decent rewards on these tasks, whereas our proposed algorithms incur zero violations.
Multi-version Tensor Completion for Time-delayed Spatio-temporal Data
May 11, 2021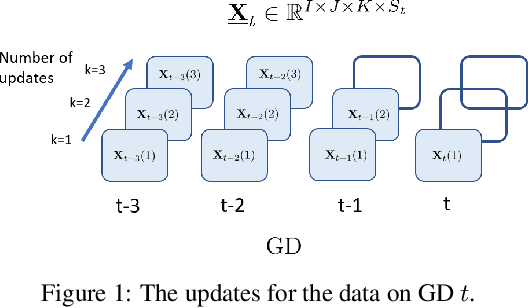
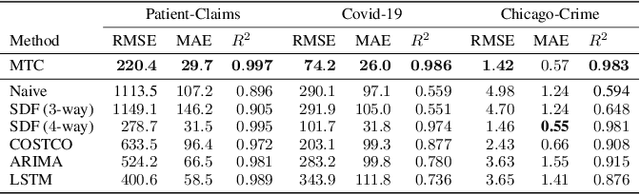
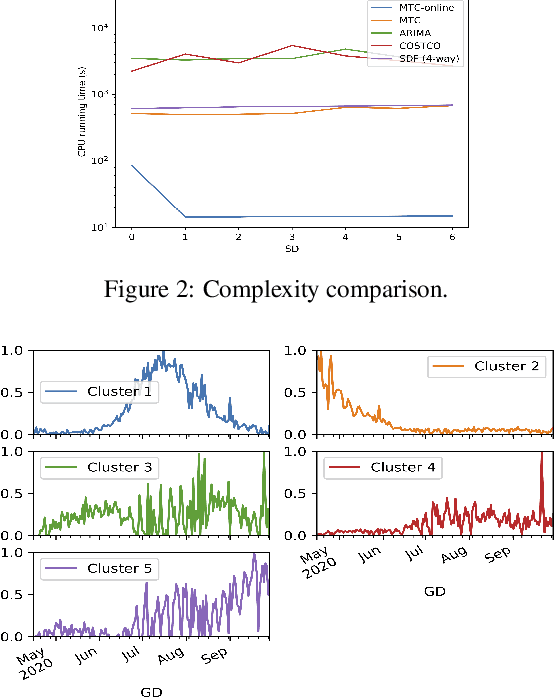
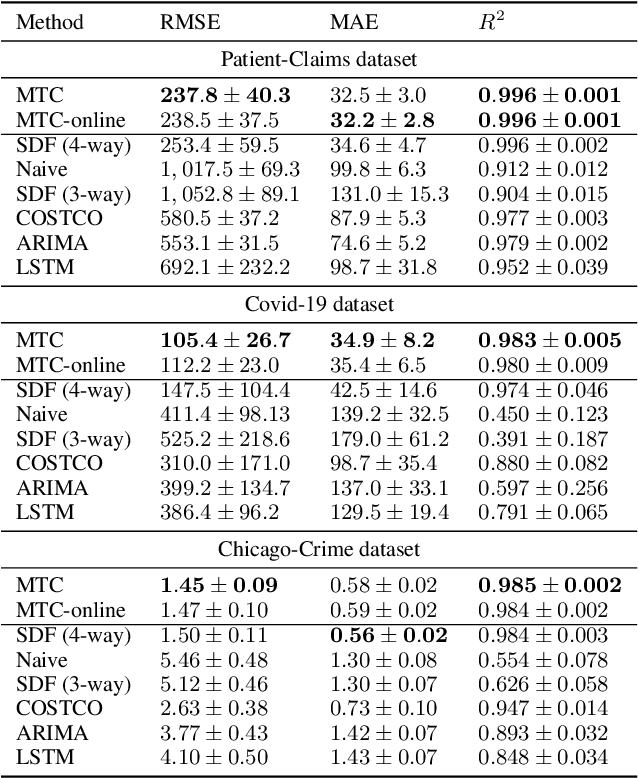
Real-world spatio-temporal data is often incomplete or inaccurate due to various data loading delays. For example, a location-disease-time tensor of case counts can have multiple delayed updates of recent temporal slices for some locations or diseases. Recovering such missing or noisy (under-reported) elements of the input tensor can be viewed as a generalized tensor completion problem. Existing tensor completion methods usually assume that i) missing elements are randomly distributed and ii) noise for each tensor element is i.i.d. zero-mean. Both assumptions can be violated for spatio-temporal tensor data. We often observe multiple versions of the input tensor with different under-reporting noise levels. The amount of noise can be time- or location-dependent as more updates are progressively introduced to the tensor. We model such dynamic data as a multi-version tensor with an extra tensor mode capturing the data updates. We propose a low-rank tensor model to predict the updates over time. We demonstrate that our method can accurately predict the ground-truth values of many real-world tensors. We obtain up to 27.2% lower root mean-squared-error compared to the best baseline method. Finally, we extend our method to track the tensor data over time, leading to significant computational savings.
Optimal Private Payoff Manipulation against Commitment in Extensive-form Games
Jun 27, 2022


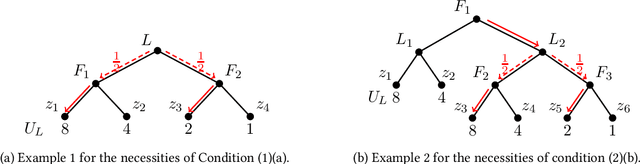
To take advantage of strategy commitment, a useful tactic of playing games, a leader must learn enough information about the follower's payoff function. However, this leaves the follower a chance to provide fake information and influence the final game outcome. Through a carefully contrived payoff function misreported to the learning leader, the follower may induce an outcome that benefits him more, compared to the ones when he truthfully behaves. We study the follower's optimal manipulation via such strategic behaviors in extensive-form games. Followers' different attitudes are taken into account. An optimistic follower maximizes his true utility among all game outcomes that can be induced by some payoff function. A pessimistic follower only considers misreporting payoff functions that induce a unique game outcome. For all the settings considered in this paper, we characterize all the possible game outcomes that can be induced successfully. We show that it is polynomial-time tractable for the follower to find the optimal way of misreporting his private payoff information. Our work completely resolves this follower's optimal manipulation problem on an extensive-form game tree.
Optimal Design of Energy-Harvesting Hybrid VLC-RF Networks
Jun 09, 2022
In this extended abstract, we consider a dual-hop hybrid visible light communication (VLC)/radio frequency (RF) scenario where energy is harvested during the VLC transmission and used to power the relay. We formulate the optimization problem in the sense of maximizing the data rate under the assumption of decode-and-forward (DF) relaying. As the design parameters, the direct current (DC) bias and the assigned time duration for energy harvesting are taken into account. In particular, the joint optimization is split into two subproblems, which are then cyclically solved. Additional details and numerical results are left to be presented in the full paper.
Time-Varying Channel Prediction for RIS-Assisted MU-MISO Networks via Deep Learning
Nov 09, 2021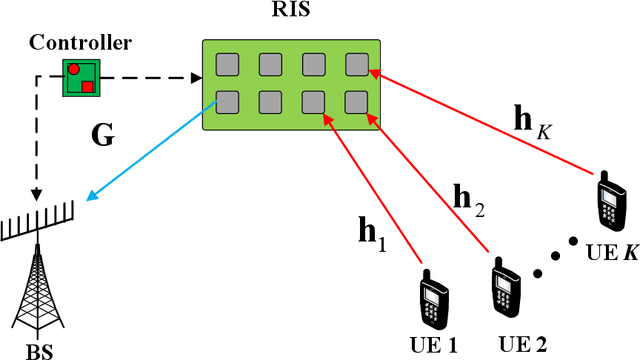
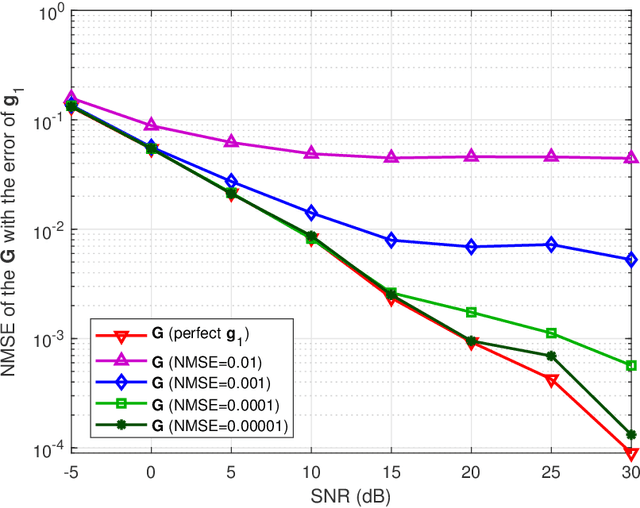
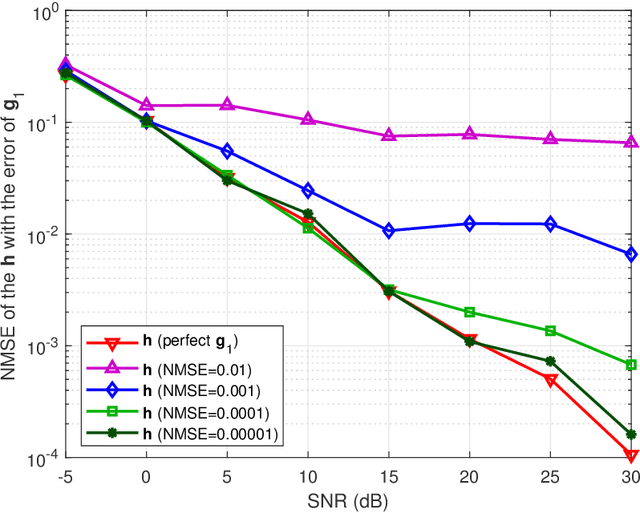
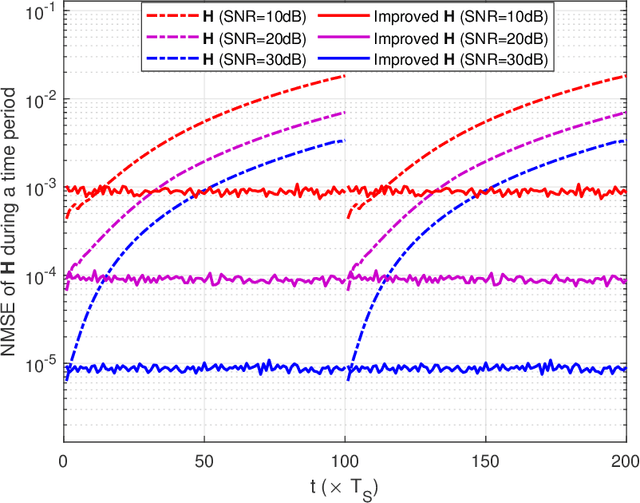
To mitigate the effects of shadow fading and obstacle blocking, reconfigurable intelligent surface (RIS) has become a promising technology to improve the signal transmission quality of wireless communications by controlling the reconfigurable passive elements with less hardware cost and lower power consumption. However, accurate, low-latency and low-pilot-overhead channel state information (CSI) acquisition remains a considerable challenge in RIS-assisted systems due to the large number of RIS passive elements. In this paper, we propose a three-stage joint channel decomposition and prediction framework to require CSI. The proposed framework exploits the two-timescale property that the base station (BS)-RIS channel is quasi-static and the RIS-user equipment (UE) channel is fast time-varying. Specifically, in the first stage, we use the full-duplex technique to estimate the channel between a BS's specific antenna and the RIS, addressing the critical scaling ambiguity problem in the channel decomposition. We then design a novel deep neural network, namely, the sparse-connected long short-term memory (SCLSTM), and propose a SCLSTM-based algorithm in the second and third stages, respectively. The algorithm can simultaneously decompose the BS-RIS channel and RIS-UE channel from the cascaded channel and capture the temporal relationship of the RIS-UE channel for prediction. Simulation results show that our proposed framework has lower pilot overhead than the traditional channel estimation algorithms, and the proposed SCLSTM-based algorithm can also achieve more accurate CSI acquisition robustly and effectively.
Video2StyleGAN: Encoding Video in Latent Space for Manipulation
Jun 27, 2022
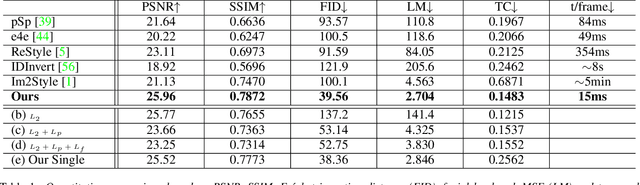
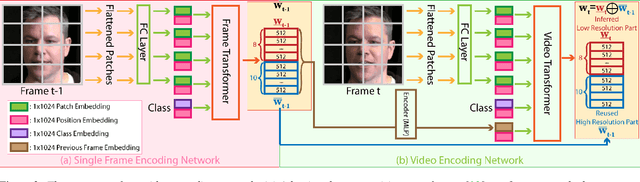
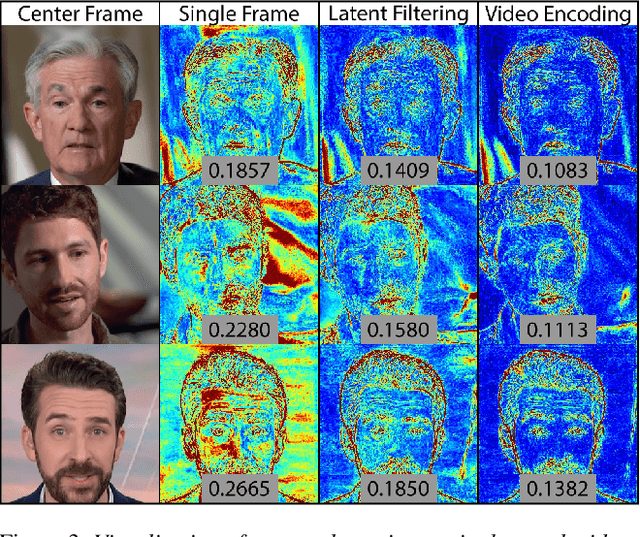
Many recent works have been proposed for face image editing by leveraging the latent space of pretrained GANs. However, few attempts have been made to directly apply them to videos, because 1) they do not guarantee temporal consistency, 2) their application is limited by their processing speed on videos, and 3) they cannot accurately encode details of face motion and expression. To this end, we propose a novel network to encode face videos into the latent space of StyleGAN for semantic face video manipulation. Based on the vision transformer, our network reuses the high-resolution portion of the latent vector to enforce temporal consistency. To capture subtle face motions and expressions, we design novel losses that involve sparse facial landmarks and dense 3D face mesh. We have thoroughly evaluated our approach and successfully demonstrated its application to various face video manipulations. Particularly, we propose a novel network for pose/expression control in a 3D coordinate system. Both qualitative and quantitative results have shown that our approach can significantly outperform existing single image methods, while achieving real-time (66 fps) speed.
Optimal Clustering with Noisy Queries via Multi-Armed Bandit
Jul 12, 2022Motivated by many applications, we study clustering with a faulty oracle. In this problem, there are $n$ items belonging to $k$ unknown clusters, and the algorithm is allowed to ask the oracle whether two items belong to the same cluster or not. However, the answer from the oracle is correct only with probability $\frac{1}{2}+\frac{\delta}{2}$. The goal is to recover the hidden clusters with minimum number of noisy queries. Previous works have shown that the problem can be solved with $O(\frac{nk\log n}{\delta^2} + \text{poly}(k,\frac{1}{\delta}, \log n))$ queries, while $\Omega(\frac{nk}{\delta^2})$ queries is known to be necessary. So, for any values of $k$ and $\delta$, there is still a non-trivial gap between upper and lower bounds. In this work, we obtain the first matching upper and lower bounds for a wide range of parameters. In particular, a new polynomial time algorithm with $O(\frac{n(k+\log n)}{\delta^2} + \text{poly}(k,\frac{1}{\delta}, \log n))$ queries is proposed. Moreover, we prove a new lower bound of $\Omega(\frac{n\log n}{\delta^2})$, which, combined with the existing $\Omega(\frac{nk}{\delta^2})$ bound, matches our upper bound up to an additive $\text{poly}(k,\frac{1}{\delta},\log n)$ term. To obtain the new results, our main ingredient is an interesting connection between our problem and multi-armed bandit, which might provide useful insights for other similar problems.
Learning Iterative Reasoning through Energy Minimization
Jun 30, 2022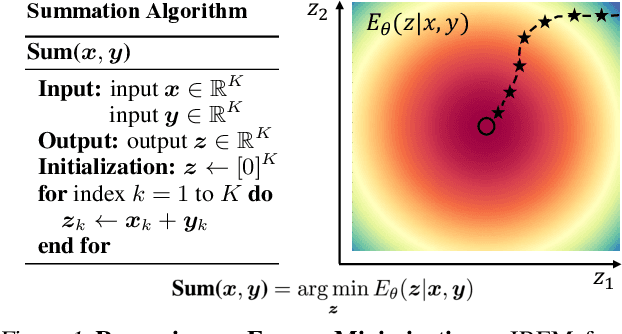
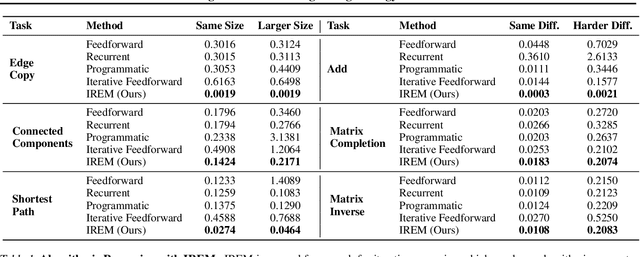
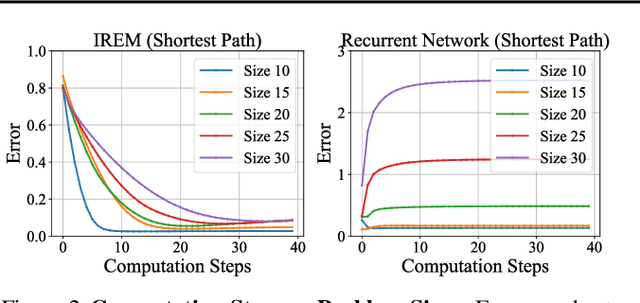
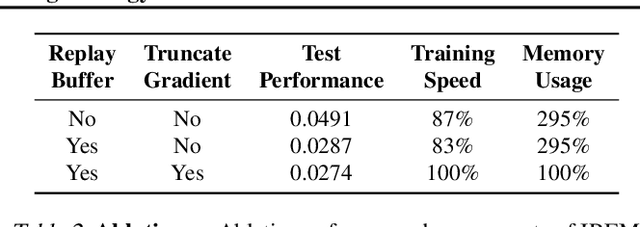
Deep learning has excelled on complex pattern recognition tasks such as image classification and object recognition. However, it struggles with tasks requiring nontrivial reasoning, such as algorithmic computation. Humans are able to solve such tasks through iterative reasoning -- spending more time thinking about harder tasks. Most existing neural networks, however, exhibit a fixed computational budget controlled by the neural network architecture, preventing additional computational processing on harder tasks. In this work, we present a new framework for iterative reasoning with neural networks. We train a neural network to parameterize an energy landscape over all outputs, and implement each step of the iterative reasoning as an energy minimization step to find a minimal energy solution. By formulating reasoning as an energy minimization problem, for harder problems that lead to more complex energy landscapes, we may then adjust our underlying computational budget by running a more complex optimization procedure. We empirically illustrate that our iterative reasoning approach can solve more accurate and generalizable algorithmic reasoning tasks in both graph and continuous domains. Finally, we illustrate that our approach can recursively solve algorithmic problems requiring nested reasoning
Transcormer: Transformer for Sentence Scoring with Sliding Language Modeling
May 28, 2022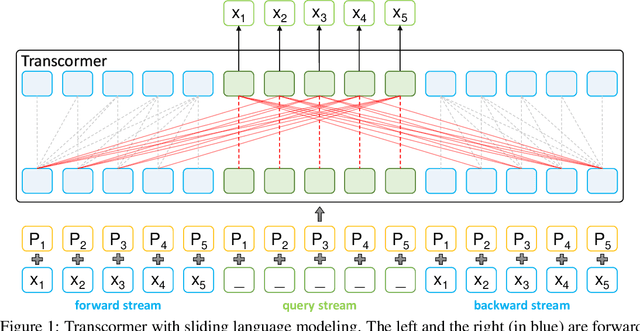

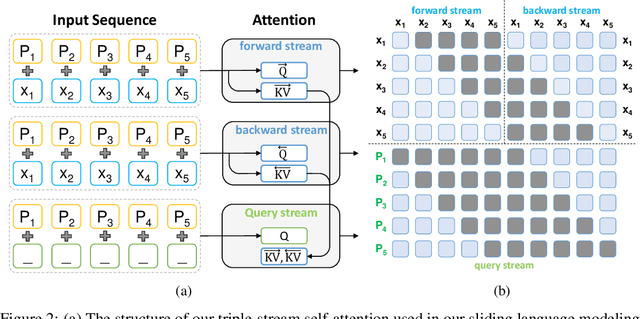
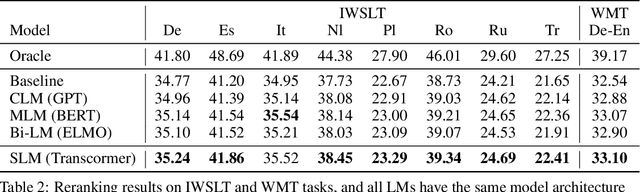
Sentence scoring aims at measuring the likelihood score of a sentence and is widely used in many natural language processing scenarios, like reranking, which is to select the best sentence from multiple candidates. Previous works on sentence scoring mainly adopted either causal language modeling (CLM) like GPT or masked language modeling (MLM) like BERT, which have some limitations: 1) CLM only utilizes unidirectional information for the probability estimation of a sentence without considering bidirectional context, which affects the scoring quality; 2) MLM can only estimate the probability of partial tokens at a time and thus requires multiple forward passes to estimate the probability of the whole sentence, which incurs large computation and time cost. In this paper, we propose \textit{Transcormer} -- a Transformer model with a novel \textit{sliding language modeling} (SLM) for sentence scoring. Specifically, our SLM adopts a triple-stream self-attention mechanism to estimate the probability of all tokens in a sentence with bidirectional context and only requires a single forward pass. SLM can avoid the limitations of CLM (only unidirectional context) and MLM (multiple forward passes) and inherit their advantages, and thus achieve high effectiveness and efficiency in scoring. Experimental results on multiple tasks demonstrate that our method achieves better performance than other language modelings.