 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
M-LIO: Multi-lidar, multi-IMU odometry with sensor dropout tolerance
Oct 09, 2022




We present a robust system for state estimation that fuses measurements from multiple lidars and inertial sensors with GNSS data. To initiate the method, we use the prior GNSS pose information. We then perform incremental motion in real-time, which produces robust motion estimates in a global frame by fusing lidar and IMU signals with GNSS translation components using a factor graph framework. We also propose methods to account for signal loss with a novel synchronization and fusion mechanism. To validate our approach extensive tests were carried out on data collected using Scania test vehicles (5 sequences for a total of ~ 7 Km). From our evaluations, we show an average improvement of 61% in relative translation and 42% rotational error compared to a state-of-the-art estimator fusing a single lidar/inertial sensor pair.
Scale-Invariant Fast Functional Registration
Sep 26, 2022
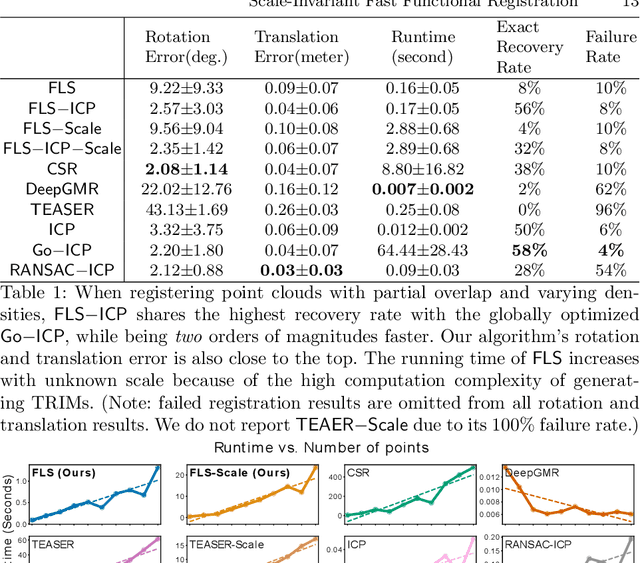
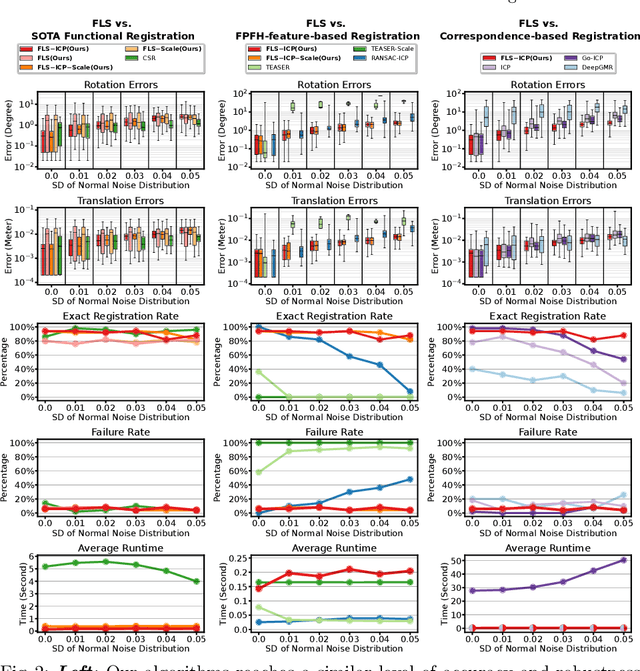
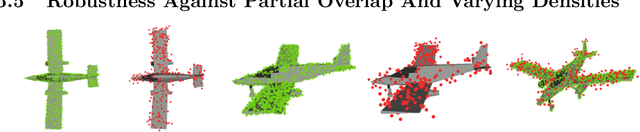
Functional registration algorithms represent point clouds as functions (e.g. spacial occupancy field) avoiding unreliable correspondence estimation in conventional least-squares registration algorithms. However, existing functional registration algorithms are computationally expensive. Furthermore, the capability of registration with unknown scale is necessary in tasks such as CAD model-based object localization, yet no such support exists in functional registration. In this work, we propose a scale-invariant, linear time complexity functional registration algorithm. We achieve linear time complexity through an efficient approximation of L2-distance between functions using orthonormal basis functions. The use of orthonormal basis functions leads to a formulation that is compatible with least-squares registration. Benefited from the least-square formulation, we use the theory of translation-rotation-invariant measurement to decouple scale estimation and therefore achieve scale-invariant registration. We evaluate the proposed algorithm, named FLS (functional least-squares), on standard 3D registration benchmarks, showing FLS is an order of magnitude faster than state-of-the-art functional registration algorithm without compromising accuracy and robustness. FLS also outperforms state-of-the-art correspondence-based least-squares registration algorithm on accuracy and robustness, with known and unknown scale. Finally, we demonstrate applying FLS to register point clouds with varying densities and partial overlaps, point clouds from different objects within the same category, and point clouds from real world objects with noisy RGB-D measurements.
* 17 pages
View-Invariant Localization using Semantic Objects in Changing Environments
Sep 28, 2022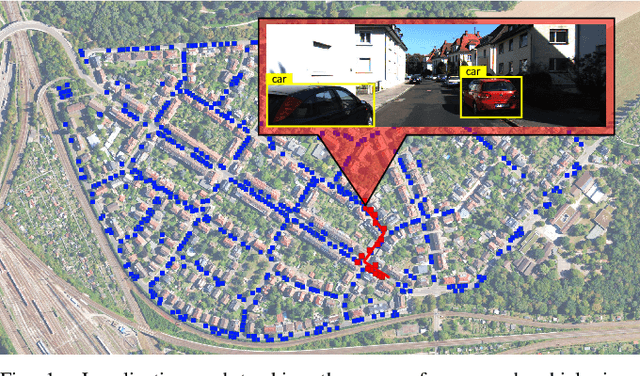
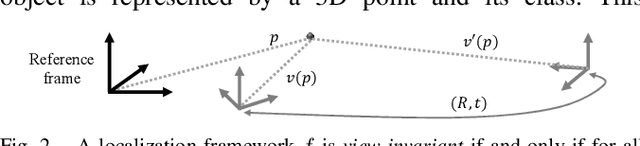
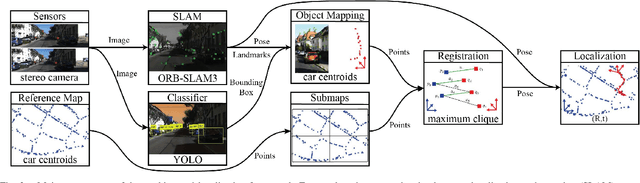
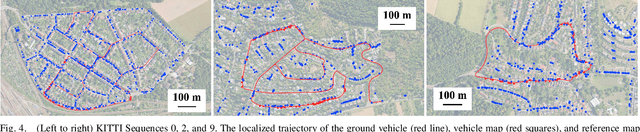
This paper proposes a novel framework for real-time localization and egomotion tracking of a vehicle in a reference map. The core idea is to map the semantic objects observed by the vehicle and register them to their corresponding objects in the reference map. While several recent works have leveraged semantic information for cross-view localization, the main contribution of this work is a view-invariant formulation that makes the approach directly applicable to any viewpoint configuration for which objects are detectable. Another distinctive feature is robustness to changes in the environment/objects due to a data association scheme suited for extreme outlier regimes (e.g., 90% association outliers). To demonstrate our framework, we consider an example of localizing a ground vehicle in a reference object map using only cars as objects. While only a stereo camera is used for the ground vehicle, we consider reference maps constructed a priori from ground viewpoints using stereo cameras and Lidar scans, and georeferenced aerial images captured at a different date to demonstrate the framework's robustness to different modalities, viewpoints, and environment changes. Evaluations on the KITTI dataset show that over a 3.7 km trajectory, localization occurs in 36 sec and is followed by real-time egomotion tracking with an average position error of 8.5 m in a Lidar reference map, and on an aerial object map where 77% of objects are outliers, localization is achieved in 71 sec with an average position error of 7.9 m.
Flying Trot Control Method for Quadruped Robot Based on Trajectory Planning
Oct 24, 2022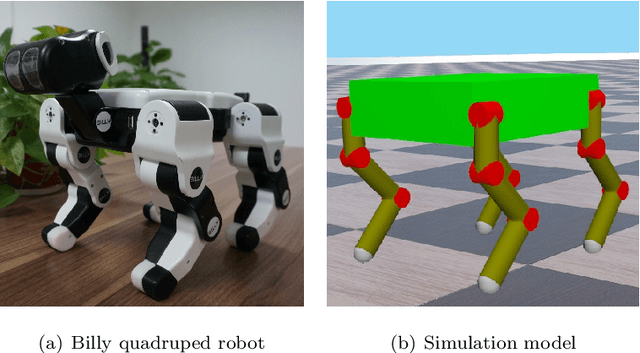
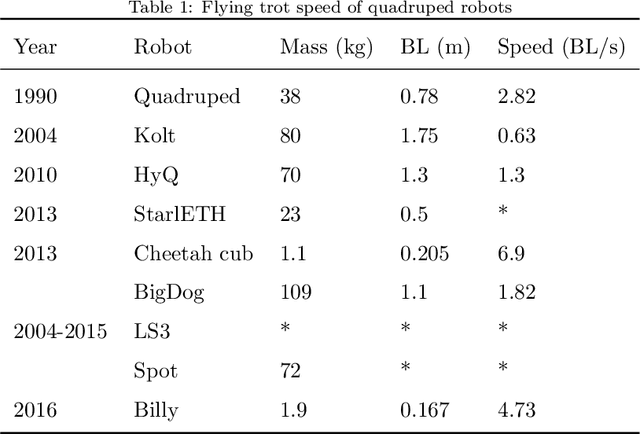
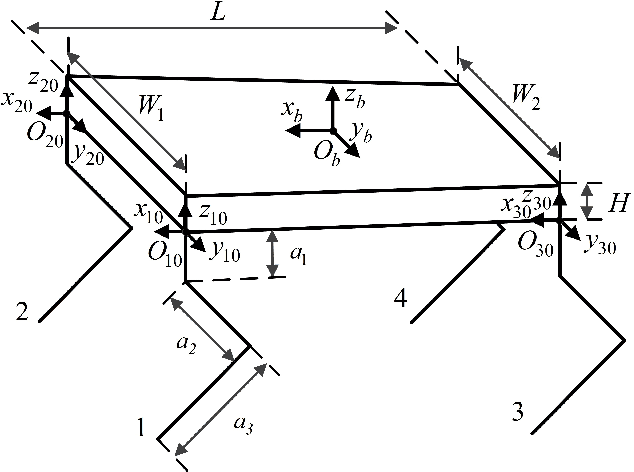
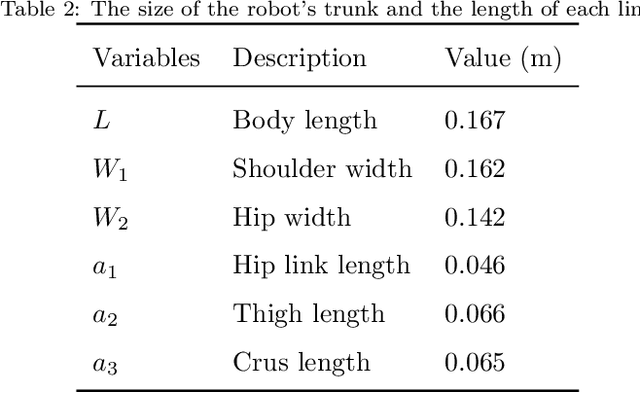
An intuitive control method for the flying trot, which combines offline trajectory planning with real-time balance control, is presented. The motion features of running animals in the vertical direction were analysed using the spring-load-inverted-pendulum (SLIP) model, and the foot trajectory of the robot was planned, so the robot could run similar to an animal capable of vertical flight, according to the given height and speed of the trunk. To improve the robustness of running, a posture control method based on a foot acceleration adjustment is proposed. A novel kinematic based CoM observation method and CoM regulation method is present to enhance the stability of locomotion. To reduce the impact force when the robot interacts with the environment, the virtual model control method is used in the control of the foot trajectory to achieve active compliance. By selecting the proper parameters for the virtual model, the oscillation motion of the virtual model and the planning motion of the support foot are synchronized to avoid the large disturbance caused by the oscillation motion of the virtual model in relation to the robot motion. The simulation and experiment using the quadruped robot Billy are reported. In the experiment, the maximum speed of the robot could reach 4.73 times the body length per second, which verified the feasibility of the control method.
Exploring Self-Attention for Crop-type Classification Explainability
Oct 24, 2022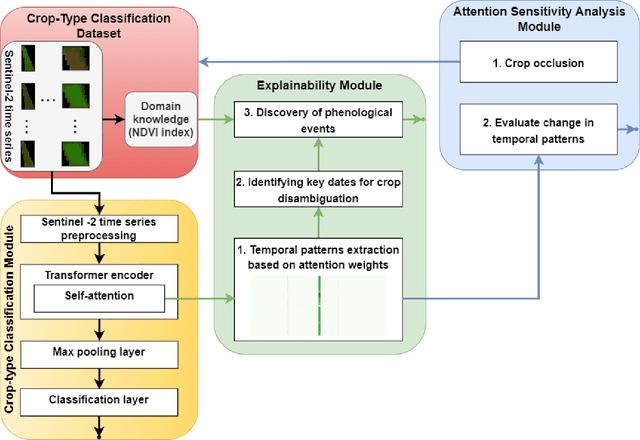
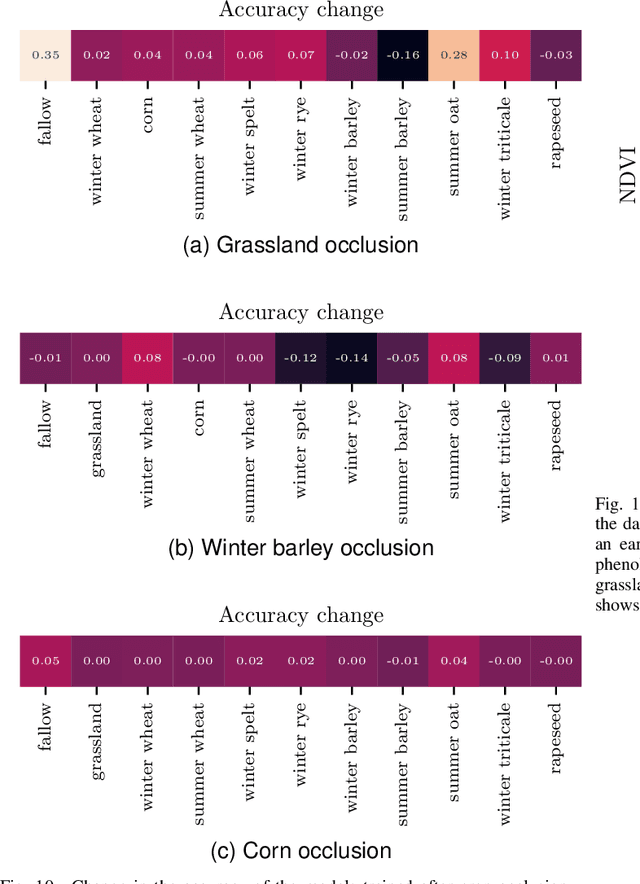
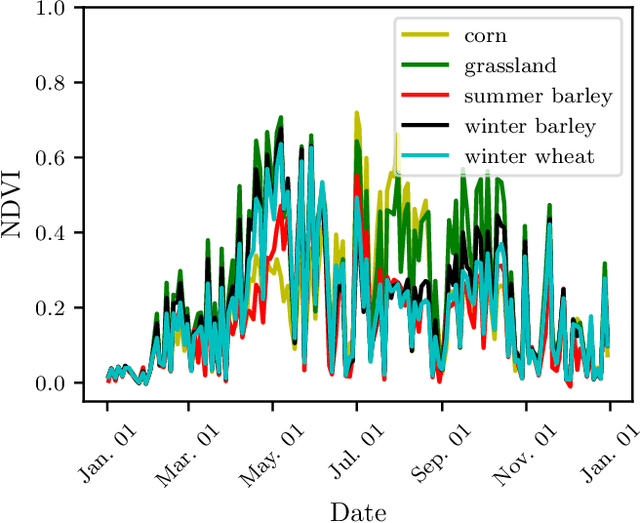

Automated crop-type classification using Sentinel-2 satellite time series is essential to support agriculture monitoring. Recently, deep learning models based on transformer encoders became a promising approach for crop-type classification. Using explainable machine learning to reveal the inner workings of these models is an important step towards improving stakeholders' trust and efficient agriculture monitoring. In this paper, we introduce a novel explainability framework that aims to shed a light on the essential crop disambiguation patterns learned by a state-of-the-art transformer encoder model. More specifically, we process the attention weights of a trained transformer encoder to reveal the critical dates for crop disambiguation and use domain knowledge to uncover the phenological events that support the model performance. We also present a sensitivity analysis approach to understand better the attention capability for revealing crop-specific phenological events. We report compelling results showing that attention patterns strongly relate to key dates, and consequently, to the critical phenological events for crop-type classification. These findings might be relevant for improving stakeholder trust and optimizing agriculture monitoring processes. Additionally, our sensitivity analysis demonstrates the limitation of attention weights for identifying the important events in the crop phenology as we empirically show that the unveiled phenological events depend on the other crops in the data considered during training.
Applying Machine Learning for Duplicate Detection, Throttling and Prioritization of Equipment Commissioning Audits at Fulfillment Network
Sep 28, 2022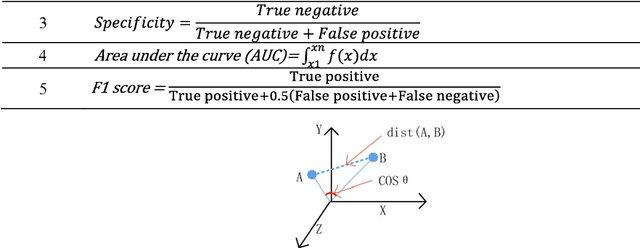
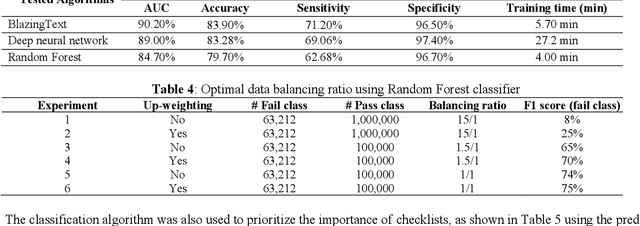
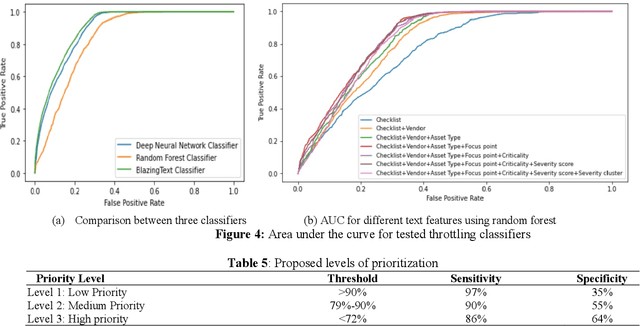
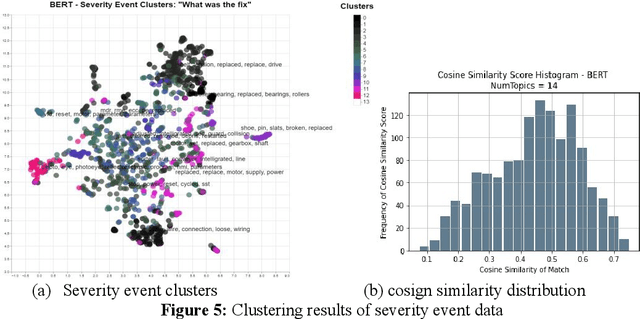
VQ (Vendor Qualification) and IOQ (Installation and Operation Qualification) audits are implemented in warehouses to ensure all equipment being turned over in the fulfillment network meets the quality standards. Audit checks are likely to be skipped if there are many checks to be performed in a short time. In addition, exploratory data analysis reveals several instances of similar checks being performed on the same assets and thus, duplicating the effort. In this work, Natural Language Processing and Machine Learning are applied to trim a large checklist dataset for a network of warehouses by identifying similarities and duplicates, and predict the non-critical ones with a high passing rate. The study proposes ML classifiers to identify checks which have a high passing probability of IOQ and VQ and assign priorities to checks to be prioritized when the time is not available to perform all checks. This research proposes using NLP-based BlazingText classifier to throttle the checklists with a high passing rate, which can reduce 10%-37% of the checks and achieve significant cost reduction. The applied algorithm over performs Random Forest and Neural Network classifiers and achieves an area under the curve of 90%. Because of imbalanced data, down-sampling and upweighting have shown a positive impact on the models' accuracy using F1 score, which improve from 8% to 75%. In addition, the proposed duplicate detection process identifies 17% possible redundant checks to be trimmed.
FUSSL: Fuzzy Uncertain Self Supervised Learning
Oct 28, 2022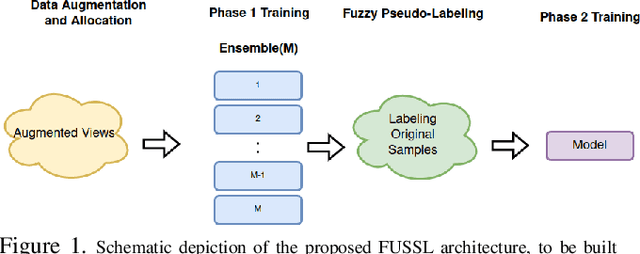
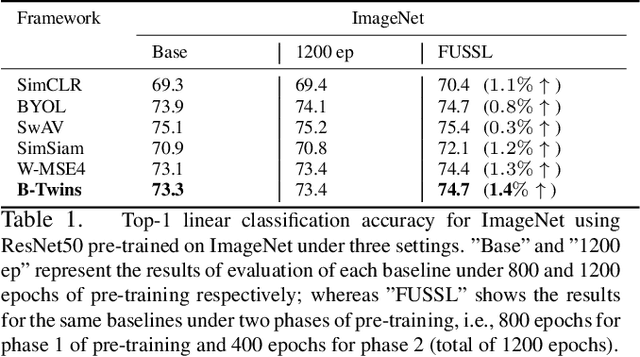
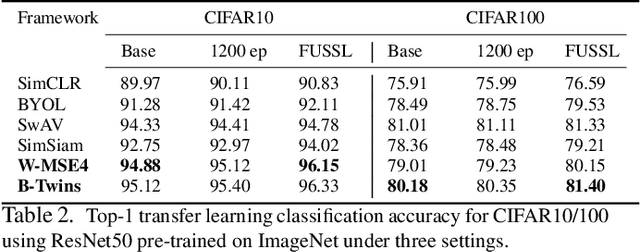
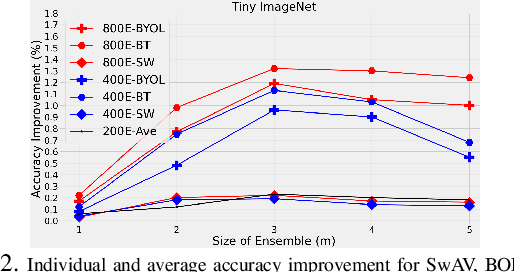
Self supervised learning (SSL) has become a very successful technique to harness the power of unlabeled data, with no annotation effort. A number of developed approaches are evolving with the goal of outperforming supervised alternatives, which have been relatively successful. One main issue in SSL is robustness of the approaches under different settings. In this paper, for the first time, we recognize the fundamental limits of SSL coming from the use of a single-supervisory signal. To address this limitation, we leverage the power of uncertainty representation to devise a robust and general standard hierarchical learning/training protocol for any SSL baseline, regardless of their assumptions and approaches. Essentially, using the information bottleneck principle, we decompose feature learning into a two-stage training procedure, each with a distinct supervision signal. This double supervision approach is captured in two key steps: 1) invariance enforcement to data augmentation, and 2) fuzzy pseudo labeling (both hard and soft annotation). This simple, yet, effective protocol which enables cross-class/cluster feature learning, is instantiated via an initial training of an ensemble of models through invariance enforcement to data augmentation as first training phase, and then assigning fuzzy labels to the original samples for the second training phase. We consider multiple alternative scenarios with double supervision and evaluate the effectiveness of our approach on recent baselines, covering four different SSL paradigms, including geometrical, contrastive, non-contrastive, and hard/soft whitening (redundancy reduction) baselines. Extensive experiments under multiple settings show that the proposed training protocol consistently improves the performance of the former baselines, independent of their respective underlying principles.
Learning Variational Motion Prior for Video-based Motion Capture
Oct 28, 2022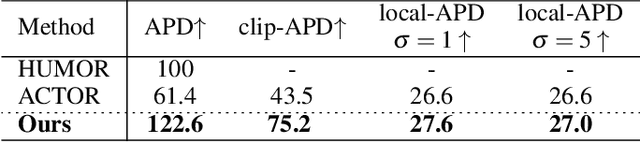
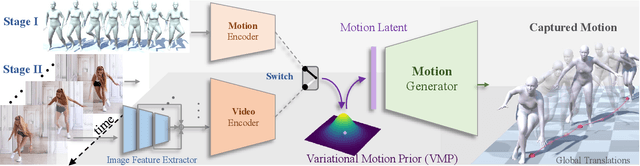
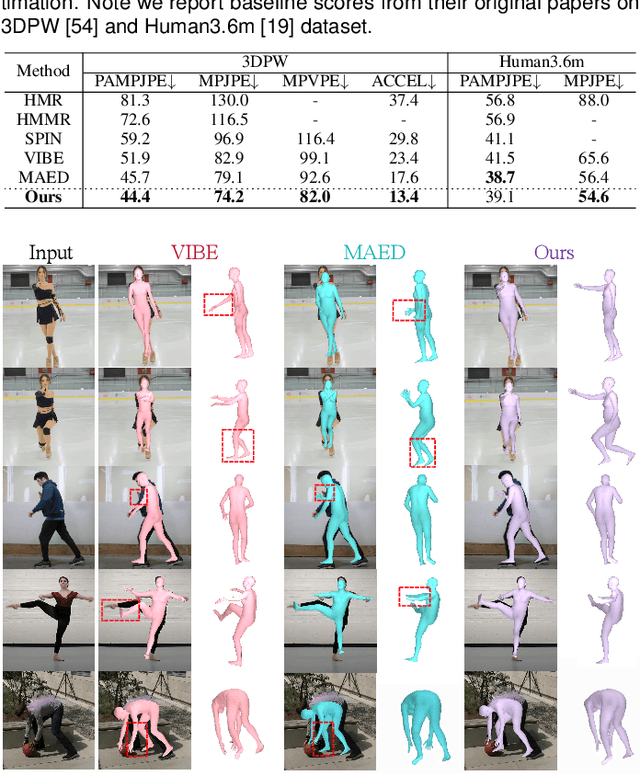

Motion capture from a monocular video is fundamental and crucial for us humans to naturally experience and interact with each other in Virtual Reality (VR) and Augmented Reality (AR). However, existing methods still struggle with challenging cases involving self-occlusion and complex poses due to the lack of effective motion prior modeling. In this paper, we present a novel variational motion prior (VMP) learning approach for video-based motion capture to resolve the above issue. Instead of directly building the correspondence between the video and motion domain, We propose to learn a generic latent space for capturing the prior distribution of all natural motions, which serve as the basis for subsequent video-based motion capture tasks. To improve the generalization capacity of prior space, we propose a transformer-based variational autoencoder pretrained over marker-based 3D mocap data, with a novel style-mapping block to boost the generation quality. Afterward, a separate video encoder is attached to the pretrained motion generator for end-to-end fine-tuning over task-specific video datasets. Compared to existing motion prior models, our VMP model serves as a motion rectifier that can effectively reduce temporal jittering and failure modes in frame-wise pose estimation, leading to temporally stable and visually realistic motion capture results. Furthermore, our VMP-based framework models motion at sequence level and can directly generate motion clips in the forward pass, achieving real-time motion capture during inference. Extensive experiments over both public datasets and in-the-wild videos have demonstrated the efficacy and generalization capability of our framework.
Improved Prediction of Beta-Amyloid and Tau Burden Using Hippocampal Surface Multivariate Morphometry Statistics and Sparse Coding
Oct 28, 2022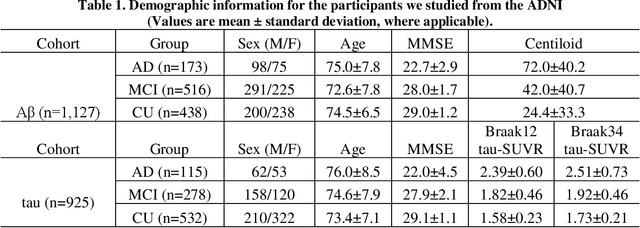
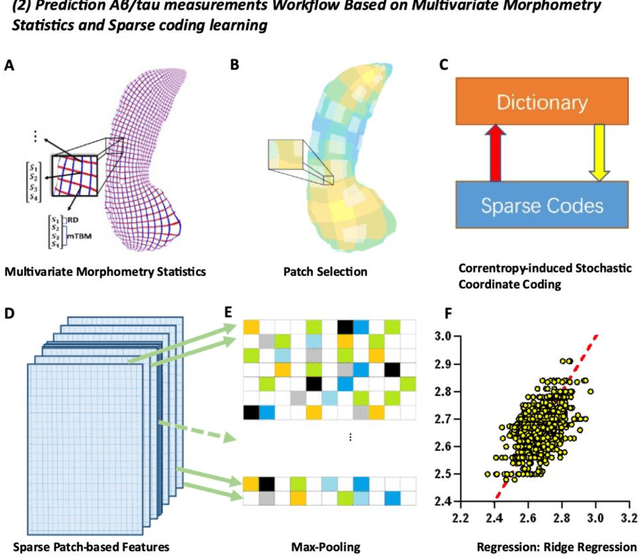
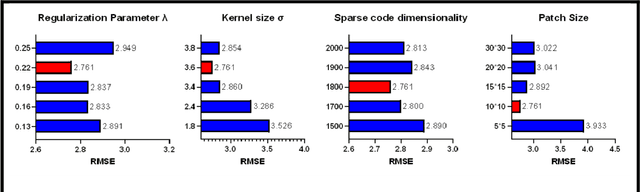
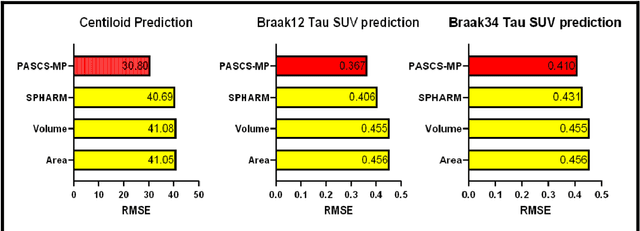
Background: Beta-amyloid (A$\beta$) plaques and tau protein tangles in the brain are the defining 'A' and 'T' hallmarks of Alzheimer's disease (AD), and together with structural atrophy detectable on brain magnetic resonance imaging (MRI) scans as one of the neurodegenerative ('N') biomarkers comprise the ''ATN framework'' of AD. Current methods to detect A$\beta$/tau pathology include cerebrospinal fluid (CSF; invasive), positron emission tomography (PET; costly and not widely available), and blood-based biomarkers (BBBM; promising but mainly still in development). Objective: To develop a non-invasive and widely available structural MRI-based framework to quantitatively predict the amyloid and tau measurements. Methods: With MRI-based hippocampal multivariate morphometry statistics (MMS) features, we apply our Patch Analysis-based Surface Correntropy-induced Sparse coding and max-pooling (PASCS-MP) method combined with the ridge regression model to individual amyloid/tau measure prediction. Results: We evaluate our framework on amyloid PET/MRI and tau PET/MRI datasets from the Alzheimer's Disease Neuroimaging Initiative (ADNI). Each subject has one pair consisting of a PET image and MRI scan, collected at about the same time. Experimental results suggest that amyloid/tau measurements predicted with our PASCP-MP representations are closer to the real values than the measures derived from other approaches, such as hippocampal surface area, volume, and shape morphometry features based on spherical harmonics (SPHARM). Conclusion: The MMS-based PASCP-MP is an efficient tool that can bridge hippocampal atrophy with amyloid and tau pathology and thus help assess disease burden, progression, and treatment effects.
Can Current Explainability Help Provide References in Clinical Notes to Support Humans Annotate Medical Codes?
Oct 28, 2022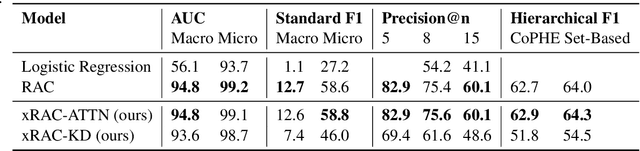


The medical codes prediction problem from clinical notes has received substantial interest in the NLP community, and several recent studies have shown the state-of-the-art (SOTA) code prediction results of full-fledged deep learning-based methods. However, most previous SOTA works based on deep learning are still in early stages in terms of providing textual references and explanations of the predicted codes, despite the fact that this level of explainability of the prediction outcomes is critical to gaining trust from professional medical coders. This raises the important question of how well current explainability methods apply to advanced neural network models such as transformers to predict correct codes and present references in clinical notes that support code prediction. First, we present an explainable Read, Attend, and Code (xRAC) framework and assess two approaches, attention score-based xRAC-ATTN and model-agnostic knowledge-distillation-based xRAC-KD, through simplified but thorough human-grounded evaluations with SOTA transformer-based model, RAC. We find that the supporting evidence text highlighted by xRAC-ATTN is of higher quality than xRAC-KD whereas xRAC-KD has potential advantages in production deployment scenarios. More importantly, we show for the first time that, given the current state of explainability methodologies, using the SOTA medical codes prediction system still requires the expertise and competencies of professional coders, even though its prediction accuracy is superior to that of human coders. This, we believe, is a very meaningful step toward developing explainable and accurate machine learning systems for fully autonomous medical code prediction from clinical notes.