 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
SLIM: Sparsified Late Interaction for Multi-Vector Retrieval with Inverted Indexes
Feb 13, 2023

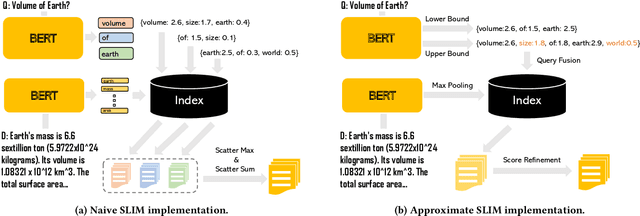
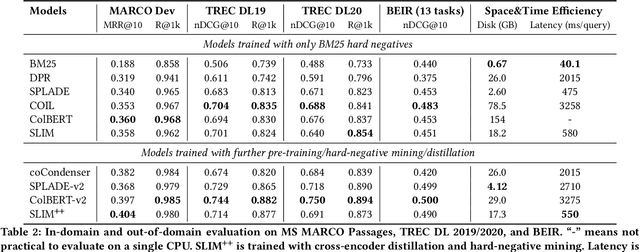
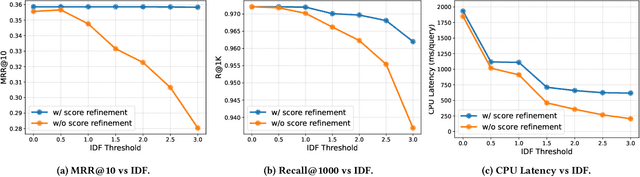
This paper introduces a method called Sparsified Late Interaction for Multi-vector retrieval with inverted indexes (SLIM). Although multi-vector models have demonstrated their effectiveness in various information retrieval tasks, most of their pipelines require custom optimization to be efficient in both time and space. Among them, ColBERT is probably the most established method which is based on the late interaction of contextualized token embeddings of pre-trained language models. Unlike ColBERT where all its token embeddings are low-dimensional and dense, SLIM projects each token embedding into a high-dimensional, sparse lexical space before performing late interaction. In practice, we further propose to approximate SLIM using the lower- and upper-bound of the late interaction to reduce latency and storage. In this way, the sparse outputs can be easily incorporated into an inverted search index and are fully compatible with off-the-shelf search tools such as Pyserini and Elasticsearch. SLIM has competitive accuracy on information retrieval benchmarks such as MS MARCO Passages and BEIR compared to ColBERT while being much smaller and faster on CPUs. Source code and data will be available at https://github.com/castorini/pyserini/blob/master/docs/experiments-slim.md.
A Lifetime Extended Energy Management Strategy for Fuel Cell Hybrid Electric Vehicles via Self-Learning Fuzzy Reinforcement Learning
Feb 13, 2023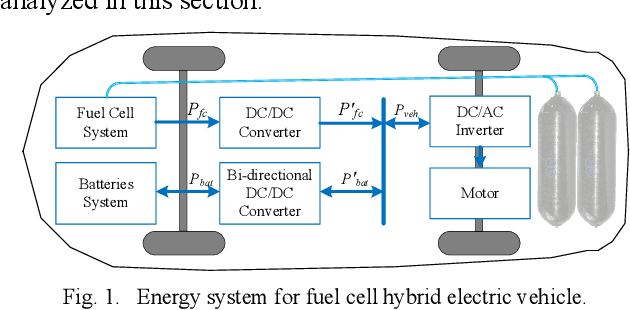
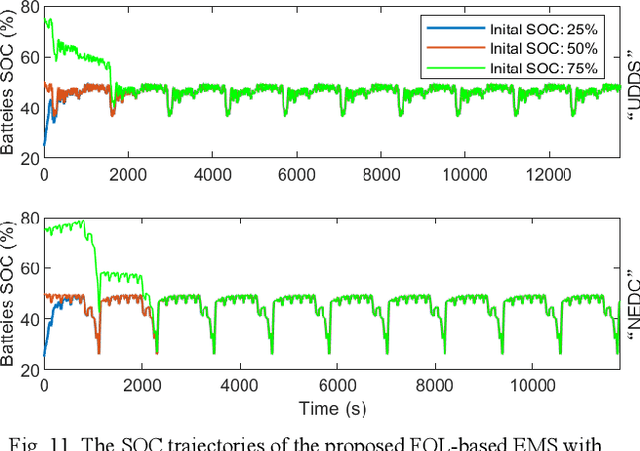

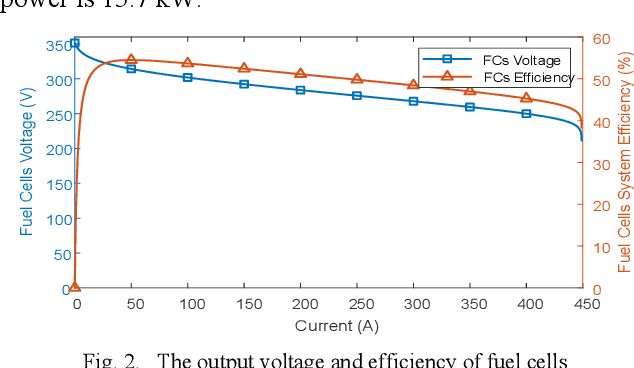
Modeling difficulty, time-varying model, and uncertain external inputs are the main challenges for energy management of fuel cell hybrid electric vehicles. In the paper, a fuzzy reinforcement learning-based energy management strategy for fuel cell hybrid electric vehicles is proposed to reduce fuel consumption, maintain the batteries' long-term operation, and extend the lifetime of the fuel cells system. Fuzzy Q-learning is a model-free reinforcement learning that can learn itself by interacting with the environment, so there is no need for modeling the fuel cells system. In addition, frequent startup of the fuel cells will reduce the remaining useful life of the fuel cells system. The proposed method suppresses frequent fuel cells startup by considering the penalty for the times of fuel cell startups in the reward of reinforcement learning. Moreover, applying fuzzy logic to approximate the value function in Q-Learning can solve continuous state and action space problems. Finally, a python-based training and testing platform verify the effectiveness and self-learning improvement of the proposed method under conditions of initial state change, model change and driving condition change.
TIGER: Temporal Interaction Graph Embedding with Restarts
Feb 13, 2023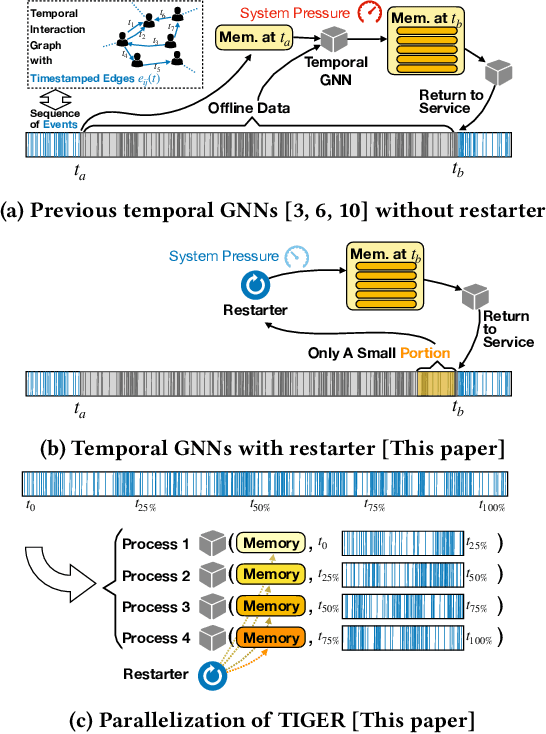
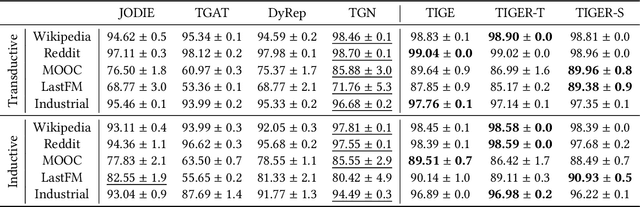
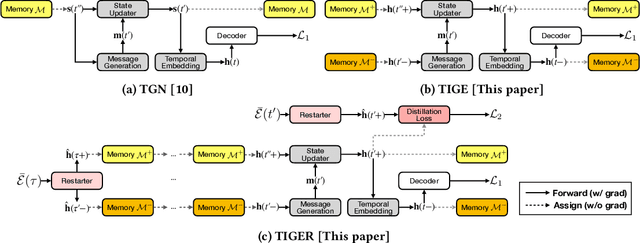

Temporal interaction graphs (TIGs), consisting of sequences of timestamped interaction events, are prevalent in fields like e-commerce and social networks. To better learn dynamic node embeddings that vary over time, researchers have proposed a series of temporal graph neural networks for TIGs. However, due to the entangled temporal and structural dependencies, existing methods have to process the sequence of events chronologically and consecutively to ensure node representations are up-to-date. This prevents existing models from parallelization and reduces their flexibility in industrial applications. To tackle the above challenge, in this paper, we propose TIGER, a TIG embedding model that can restart at any timestamp. We introduce a restarter module that generates surrogate representations acting as the warm initialization of node representations. By restarting from multiple timestamps simultaneously, we divide the sequence into multiple chunks and naturally enable the parallelization of the model. Moreover, in contrast to previous models that utilize a single memory unit, we introduce a dual memory module to better exploit neighborhood information and alleviate the staleness problem. Extensive experiments on four public datasets and one industrial dataset are conducted, and the results verify both the effectiveness and the efficiency of our work.
When Can We Track Significant Preference Shifts in Dueling Bandits?
Feb 13, 2023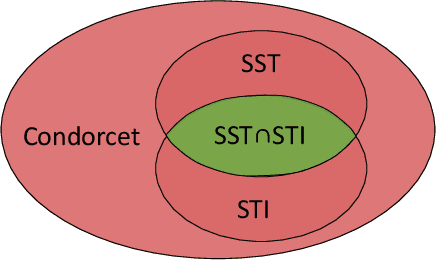
The $K$-armed dueling bandits problem, where the feedback is in the form of noisy pairwise preferences, has been widely studied due its applications in information retrieval, recommendation systems, etc. Motivated by concerns that user preferences/tastes can evolve over time, we consider the problem of dueling bandits with distribution shifts. Specifically, we study the recent notion of significant shifts (Suk and Kpotufe, 2022), and ask whether one can design an adaptive algorithm for the dueling problem with $O(\sqrt{K\tilde{L}T})$ dynamic regret, where $\tilde{L}$ is the (unknown) number of significant shifts in preferences. We show that the answer to this question depends on the properties of underlying preference distributions. Firstly, we give an impossibility result that rules out any algorithm with $O(\sqrt{K\tilde{L}T})$ dynamic regret under the well-studied Condorcet and SST classes of preference distributions. Secondly, we show that $\text{SST} \cap \text{STI}$ is the largest amongst popular classes of preference distributions where it is possible to design such an algorithm. Overall, our results provides an almost complete resolution of the above question for the hierarchy of distribution classes.
Catch Planner: Catching High-Speed Targets in the Flight
Feb 09, 2023
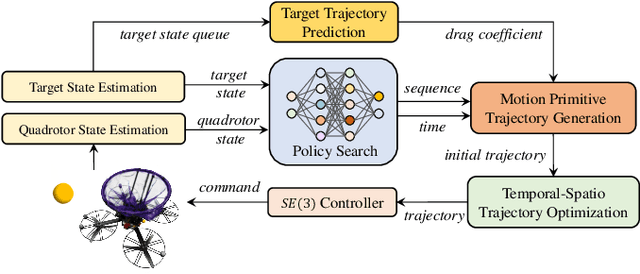
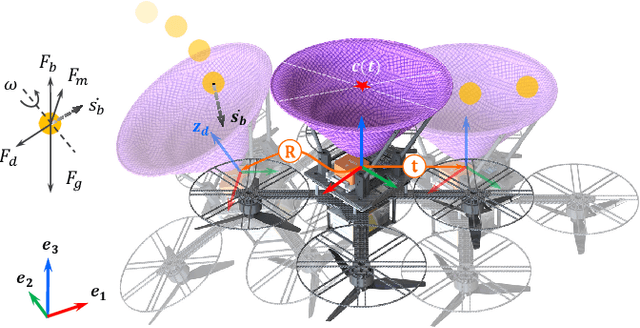
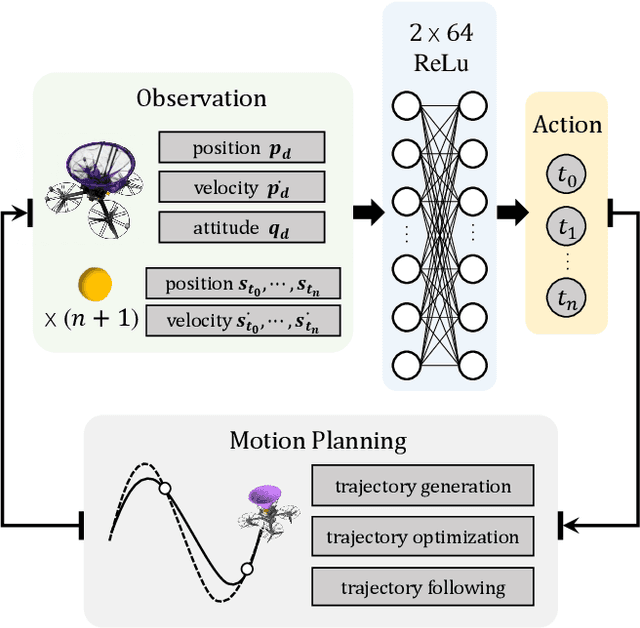
Catching high-speed targets in the flight is a complex and typical highly dynamic task. In this paper, we propose Catch Planner, a planning-with-decision scheme for catching. For sequential decision making, we propose a policy search method based on deep reinforcement learning. In order to make catching adaptive and flexible, we propose a trajectory optimization method to jointly optimize the highly coupled catching time and terminal state while considering the dynamic feasibility and safety. We also propose a flexible constraint transcription method to catch targets at any reasonable attitude and terminal position bias. The proposed Catch Planner provides a new paradigm for the combination of learning and planning and is integrated on the quadrotor designed by ourselves, which runs at 100$hz$ on the onboard computer. Extensive experiments are carried out in real and simulated scenes to verify the robustness of the proposed method and its expansibility when facing a variety of high-speed flying targets.
Exploiting Certified Defences to Attack Randomised Smoothing
Feb 09, 2023
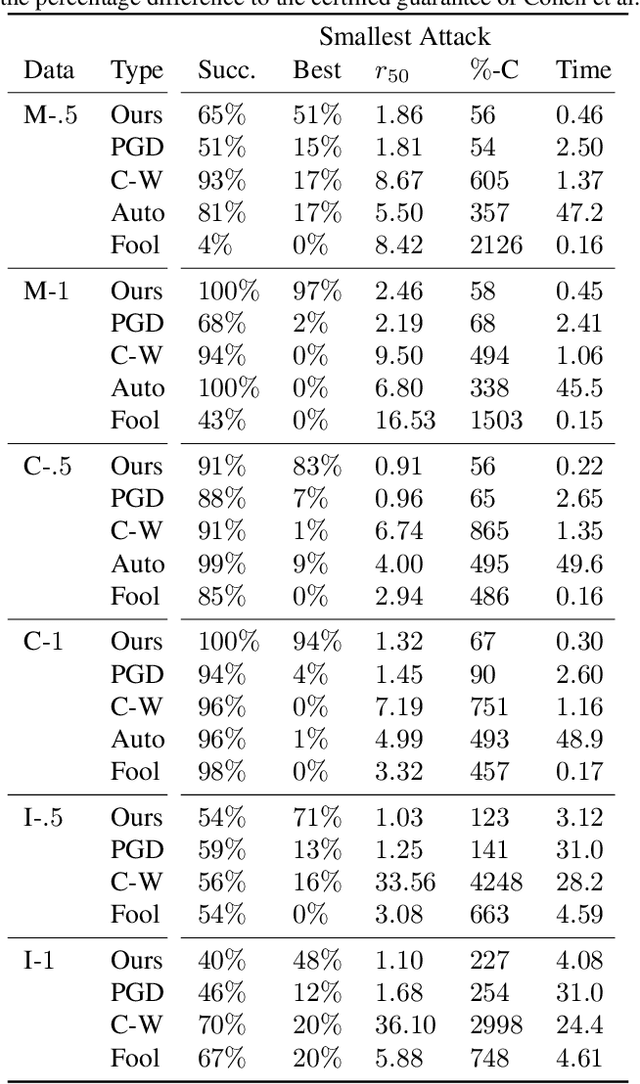
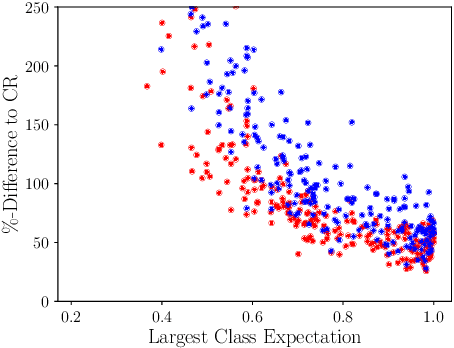
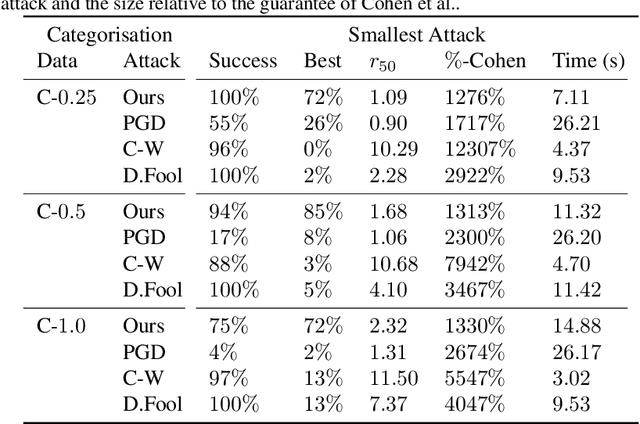
In guaranteeing that no adversarial examples exist within a bounded region, certification mechanisms play an important role in neural network robustness. Concerningly, this work demonstrates that the certification mechanisms themselves introduce a new, heretofore undiscovered attack surface, that can be exploited by attackers to construct smaller adversarial perturbations. While these attacks exist outside the certification region in no way invalidate certifications, minimising a perturbation's norm significantly increases the level of difficulty associated with attack detection. In comparison to baseline attacks, our new framework yields smaller perturbations more than twice as frequently as any other approach, resulting in an up to $34 \%$ reduction in the median perturbation norm. That this approach also requires $90 \%$ less computational time than approaches like PGD. That these reductions are possible suggests that exploiting this new attack vector would allow attackers to more frequently construct hard to detect adversarial attacks, by exploiting the very systems designed to defend deployed models.
Tricking AI chips into Simulating the Human Brain: A Detailed Performance Analysis
Jan 31, 2023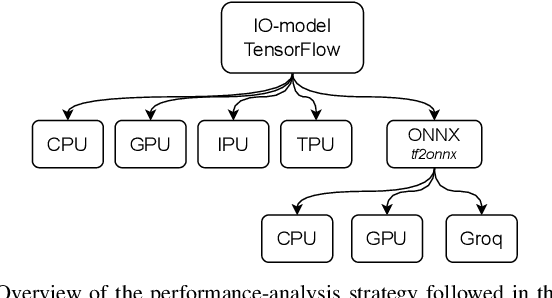
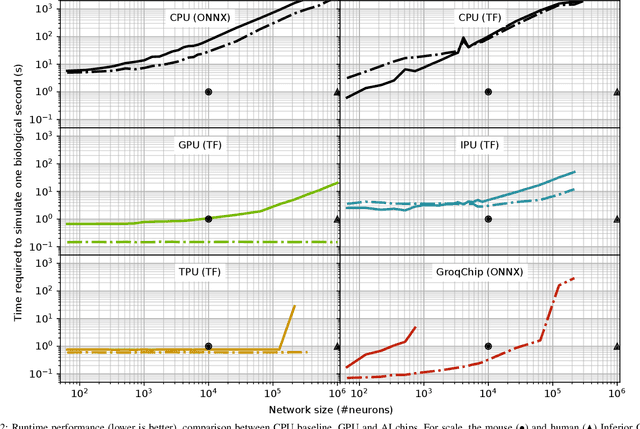
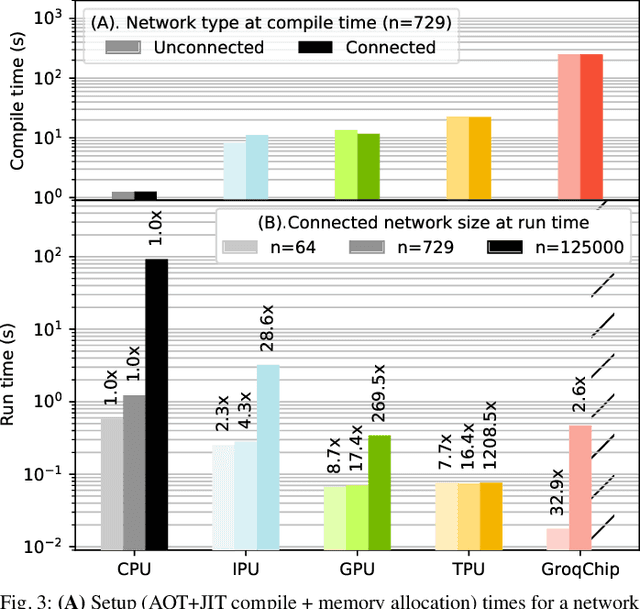
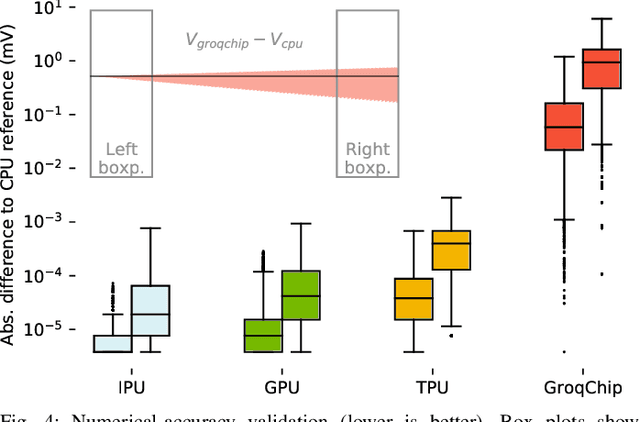
Challenging the Nvidia monopoly, dedicated AI-accelerator chips have begun emerging for tackling the computational challenge that the inference and, especially, the training of modern deep neural networks (DNNs) poses to modern computers. The field has been ridden with studies assessing the performance of these contestants across various DNN model types. However, AI-experts are aware of the limitations of current DNNs and have been working towards the fourth AI wave which will, arguably, rely on more biologically inspired models, predominantly on spiking neural networks (SNNs). At the same time, GPUs have been heavily used for simulating such models in the field of computational neuroscience, yet AI-chips have not been tested on such workloads. The current paper aims at filling this important gap by evaluating multiple, cutting-edge AI-chips (Graphcore IPU, GroqChip, Nvidia GPU with Tensor Cores and Google TPU) on simulating a highly biologically detailed model of a brain region, the inferior olive (IO). This IO application stress-tests the different AI-platforms for highlighting architectural tradeoffs by varying its compute density, memory requirements and floating-point numerical accuracy. Our performance analysis reveals that the simulation problem maps extremely well onto the GPU and TPU architectures, which for networks of 125,000 cells leads to a 28x respectively 1,208x speedup over CPU runtimes. At this speed, the TPU sets a new record for largest real-time IO simulation. The GroqChip outperforms both platforms for small networks but, due to implementing some floating-point operations at reduced accuracy, is found not yet usable for brain simulation.
Learning to Solve Multiple-TSP with Time Window and Rejections via Deep Reinforcement Learning
Sep 13, 2022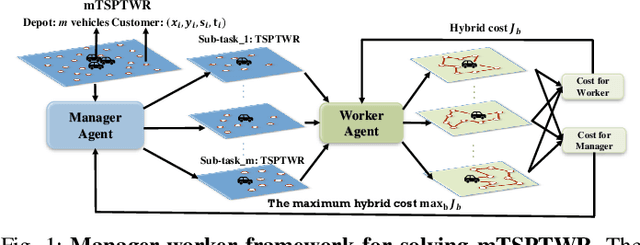
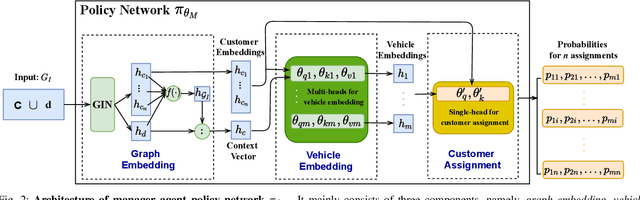
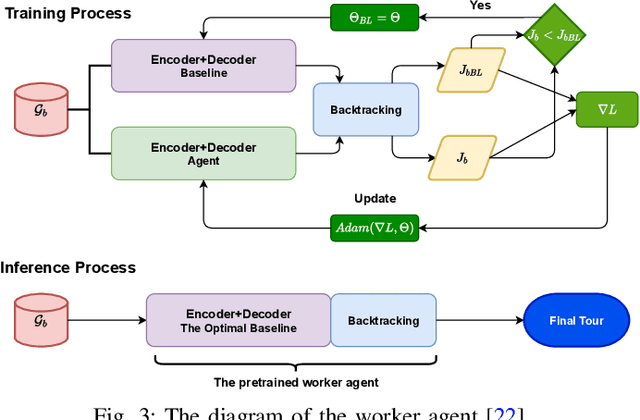
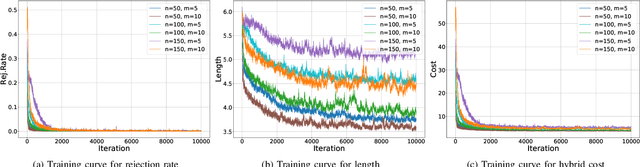
We propose a manager-worker framework based on deep reinforcement learning to tackle a hard yet nontrivial variant of Travelling Salesman Problem (TSP), \ie~multiple-vehicle TSP with time window and rejections (mTSPTWR), where customers who cannot be served before the deadline are subject to rejections. Particularly, in the proposed framework, a manager agent learns to divide mTSPTWR into sub-routing tasks by assigning customers to each vehicle via a Graph Isomorphism Network (GIN) based policy network. A worker agent learns to solve sub-routing tasks by minimizing the cost in terms of both tour length and rejection rate for each vehicle, the maximum of which is then fed back to the manager agent to learn better assignments. Experimental results demonstrate that the proposed framework outperforms strong baselines in terms of higher solution quality and shorter computation time. More importantly, the trained agents also achieve competitive performance for solving unseen larger instances.
Differentiable Outlier Detection Enable Robust Deep Multimodal Analysis
Feb 11, 2023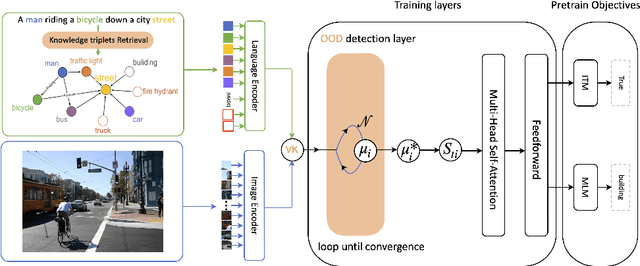
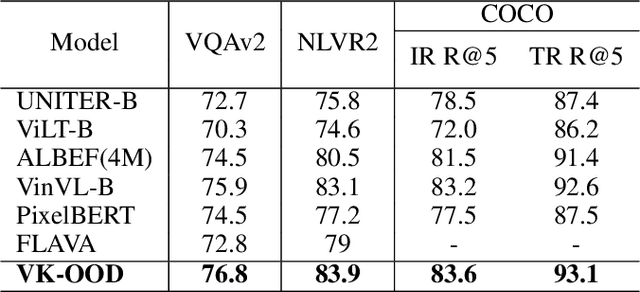

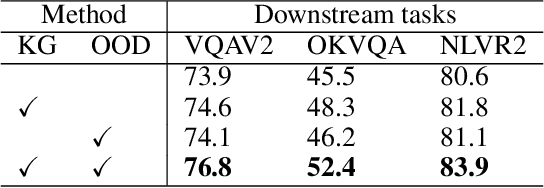
Often, deep network models are purely inductive during training and while performing inference on unseen data. Thus, when such models are used for predictions, it is well known that they often fail to capture the semantic information and implicit dependencies that exist among objects (or concepts) on a population level. Moreover, it is still unclear how domain or prior modal knowledge can be specified in a backpropagation friendly manner, especially in large-scale and noisy settings. In this work, we propose an end-to-end vision and language model incorporating explicit knowledge graphs. We also introduce an interactive out-of-distribution (OOD) layer using implicit network operator. The layer is used to filter noise that is brought by external knowledge base. In practice, we apply our model on several vision and language downstream tasks including visual question answering, visual reasoning, and image-text retrieval on different datasets. Our experiments show that it is possible to design models that perform similarly to state-of-art results but with significantly fewer samples and training time.
Sketch Less Face Image Retrieval: A New Challenge
Feb 11, 2023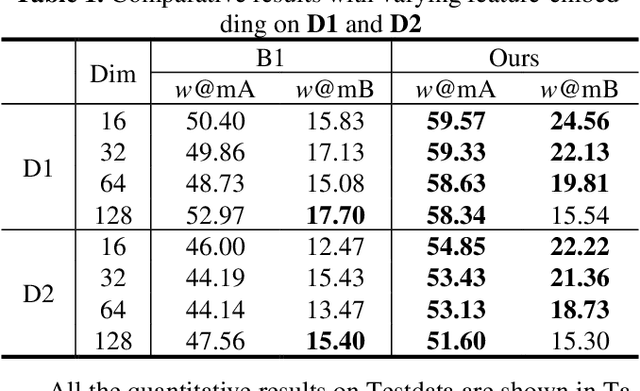
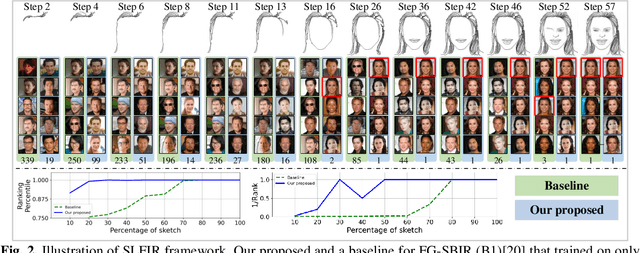
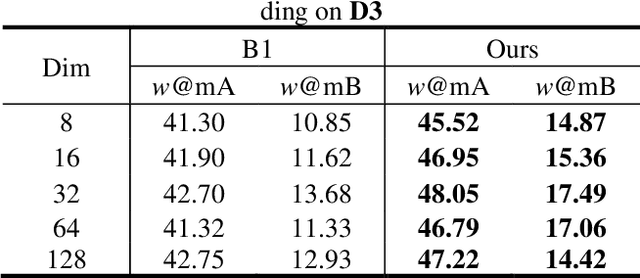
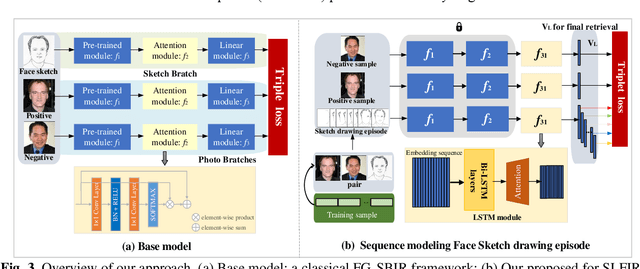
In some specific scenarios, face sketch was used to identify a person. However, drawing a complete face sketch often needs skills and takes time, which hinder its widespread applicability in the practice. In this study, we proposed a new task named sketch less face image retrieval (SLFIR), in which the retrieval was carried out at each stroke and aim to retrieve the target face photo using a partial sketch with as few strokes as possible (see Fig.1). Firstly, we developed a method to generate the data of sketch with drawing process, and opened such dataset; Secondly, we proposed a two-stage method as the baseline for SLFIR that (1) A triplet network, was first adopt to learn the joint embedding space shared between the complete sketch and its target face photo; (2) Regarding the sketch drawing episode as a sequence, we designed a LSTM module to optimize the representation of the incomplete face sketch. Experiments indicate that the new framework can finish the retrieval using a partial or pool drawing sketch.