 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGloResNet: A lightweight 3D CNN with global topological features for preterm brain injury prediction
Jun 01, 2026This study introduces an automated deep learning framework for predicting brain injury (BI) in preterm infants from T2-weighted MRI (dHCP dataset). We propose GloResNet, a lightweight 3D CNN based on ResNet-10, pretrained on MedicalNet to address data scarcity. A global manifold mapping strategy first resamples each 3D volume to 128x128x128 and then applies subject-wise z-score intensity normalization, thereby preserving global topology while standardizing appearance. Training integrates mixup, class weighting, and test-time augmentation for robustness. In 5-fold cross-validation, GloResNet achieved 75.18% average accuracy (peak 81.82%), with specificity 0.81 and sensitivity 0.76. Results demonstrate that a topology-aware lightweight CNN has the capability to effectively predict neonatal BI, offering a non-invasive screening tool. The source code of this paper can be obtained from the GitHub repository: https://github.com/ICL-SUST/GloResNet-Preterm-Brain
PaCo-VLA: Passivity-Shielded Compliance Prior for Contact-Rich Vision-Language-Action Manipulation
May 30, 2026Contact-rich manipulation demands both high-level semantic reasoning and the safe regulation of high-frequency contact dynamics. While Vision-Language-Action (VLA) models provide unprecedented semantic generalization, their low-rate outputs lack the reliability required for direct plant authority in force-sensitive tasks. To bridge this semantic-to-control gap, we introduce PaCo-VLA, a passivity-shielded compliance prior that recasts the VLA interface. Rather than trusting VLAs with direct motor commands, PaCo-VLA treats network outputs as task-level compliance proposals: semantic bindings, task stages, and admittance schedules. A high-frequency, proposal-independent passivity shield governs these proposals through energy-tank accounting and boundary checks, preventing invalid, stale, or unverified model predictions from bypassing low-level contact physics. This decoupled architecture also enables causal evaluation, isolating semantic contributions from geometric shortcuts. Extensive simulated and real-world connector-insertion experiments demonstrate that PaCo-VLA achieves superior precision over unshielded VLA baselines, sustaining zero passivity violations even under adversarial compliance shifts. This framework establishes a provably sampled-passive runtime contract at the admittance port and provides a runtime interface for deploying foundation models in contact-rich domains.
Versioned Late Materialization for Ultra-Long Sequence Training in Recommendation Systems at Scale
Apr 27, 2026Modern Deep Learning Recommendation Models (DLRMs) follow scaling laws with sequence length, driving the frontier toward ultra-long User Interaction History (UIH). However, the industry-standard "Fat Row" paradigm, which pre-materializes these sequences into every training example, creates a storage and I/O wall where data infrastructure usage exceeds GPU training capacity due to data redundancy that is amplified in multi-tenant environments where models with vastly different sequence length requirements share a union dataset. We present a \emph{versioned late materialization} paradigm that eliminates this redundancy by storing UIH once in a normalized, immutable tier and reconstructing sequences just-in-time during training via lightweight versioned pointers. The system ensures Online-to-Offline (O2O) consistency through a bifurcated protocol that prevents future leakage across both streaming and batch training, while a read-optimized immutable storage layer provides multi-dimensional projection pushdown for heterogeneous model tenants. Disaggregated data preprocessing with pipelined I/O prefetching and data-affinity optimizations masks the latency of training-time sequence reconstruction, keeping training throughput compute-bound by GPUs. Deployed on production DLRMs, the system reduces training data infrastructure resource usage while enabling aggressive sequence length scaling that delivers significant model quality gains, serving as the foundational data infrastructure for modern recommendation model architectures, including HSTU and ULTRA-HSTU.
PAS3R: Pose-Adaptive Streaming 3D Reconstruction for Long Video Sequences
Mar 22, 2026Online monocular 3D reconstruction enables dense scene recovery from streaming video but remains fundamentally limited by the stability-adaptation dilemma: the reconstruction model must rapidly incorporate novel viewpoints while preserving previously accumulated scene structure. Existing streaming approaches rely on uniform or attention-based update mechanisms that often fail to account for abrupt viewpoint transitions, leading to trajectory drift and geometric inconsistencies over long sequences. We introduce PAS3R, a pose-adaptive streaming reconstruction framework that dynamically modulates state updates according to camera motion and scene structure. Our key insight is that frames contributing significant geometric novelty should exert stronger influence on the reconstruction state, while frames with minor viewpoint variation should prioritize preserving historical context. PAS3R operationalizes this principle through a motion-aware update mechanism that jointly leverages inter-frame pose variation and image frequency cues to estimate frame importance. To further stabilize long-horizon reconstruction, we introduce trajectory-consistent training objectives that incorporate relative pose constraints and acceleration regularization. A lightweight online stabilization module further suppresses high-frequency trajectory jitter and geometric artifacts without increasing memory consumption. Extensive experiments across multiple benchmarks demonstrate that PAS3R significantly improves trajectory accuracy, depth estimation, and point cloud reconstruction quality in long video sequences while maintaining competitive performance on shorter sequences.
DECADE: A Temporally-Consistent Unsupervised Diffusion Model for Enhanced Rb-82 Dynamic Cardiac PET Image Denoising
Mar 08, 2026Rb-82 dynamic cardiac PET imaging is widely used for the clinical diagnosis of coronary artery disease (CAD), but its short half-life results in high noise levels that degrade dynamic frame quality and parametric imaging. The lack of paired clean-noisy training data, rapid tracer kinetics, and frame-dependent noise variations further limit the effectiveness of existing deep learning denoising methods. We propose DECADE (A Temporally-Consistent Unsupervised Diffusion model for Enhanced Rb-82 CArdiac PET DEnoising), an unsupervised diffusion framework that generalizes across early- to late-phase dynamic frames. DECADE incorporates temporal consistency during both training and iterative sampling, using noisy frames as guidance to preserve quantitative accuracy. The method was trained and evaluated on datasets acquired from Siemens Vision 450 and Siemens Biograph Vision Quadra scanners. On the Vision 450 dataset, DECADE consistently produced high-quality dynamic and parametric images with reduced noise while preserving myocardial blood flow (MBF) and myocardial flow reserve (MFR). On the Quadra dataset, using 15%-count images as input and full-count images as reference, DECADE outperformed UNet-based and other diffusion models in image quality and K1/MBF quantification. The proposed framework enables effective unsupervised denoising of Rb-82 dynamic cardiac PET without paired training data, supporting clearer visualization while maintaining quantitative integrity.
Deep learning-based neurodevelopmental assessment in preterm infants
Jan 17, 2026Preterm infants (born between 28 and 37 weeks of gestation) face elevated risks of neurodevelopmental delays, making early identification crucial for timely intervention. While deep learning-based volumetric segmentation of brain MRI scans offers a promising avenue for assessing neonatal neurodevelopment, achieving accurate segmentation of white matter (WM) and gray matter (GM) in preterm infants remains challenging due to their comparable signal intensities (isointense appearance) on MRI during early brain development. To address this, we propose a novel segmentation neural network, named Hierarchical Dense Attention Network. Our architecture incorporates a 3D spatial-channel attention mechanism combined with an attention-guided dense upsampling strategy to enhance feature discrimination in low-contrast volumetric data. Quantitative experiments demonstrate that our method achieves superior segmentation performance compared to state-of-the-art baselines, effectively tackling the challenge of isointense tissue differentiation. Furthermore, application of our algorithm confirms that WM and GM volumes in preterm infants are significantly lower than those in term infants, providing additional imaging evidence of the neurodevelopmental delays associated with preterm birth. The code is available at: https://github.com/ICL-SUST/HDAN.
Dual Attention Driven Lumbar Magnetic Resonance Image Feature Enhancement and Automatic Diagnosis of Herniation
Apr 28, 2025



Lumbar disc herniation (LDH) is a common musculoskeletal disease that requires magnetic resonance imaging (MRI) for effective clinical management. However, the interpretation of MRI images heavily relies on the expertise of radiologists, leading to delayed diagnosis and high costs for training physicians. Therefore, this paper proposes an innovative automated LDH classification framework. To address these key issues, the framework utilizes T1-weighted and T2-weighted MRI images from 205 people. The framework extracts clinically actionable LDH features and generates standardized diagnostic outputs by leveraging data augmentation and channel and spatial attention mechanisms. These outputs can help physicians make confident and time-effective care decisions when needed. The proposed framework achieves an area under the receiver operating characteristic curve (AUC-ROC) of 0.969 and an accuracy of 0.9486 for LDH detection. The experimental results demonstrate the performance of the proposed framework. Our framework only requires a small number of datasets for training to demonstrate high diagnostic accuracy. This is expected to be a solution to enhance the LDH detection capabilities of primary hospitals.
Fed-NDIF: A Noise-Embedded Federated Diffusion Model For Low-Count Whole-Body PET Denoising
Mar 20, 2025



Low-count positron emission tomography (LCPET) imaging can reduce patients' exposure to radiation but often suffers from increased image noise and reduced lesion detectability, necessitating effective denoising techniques. Diffusion models have shown promise in LCPET denoising for recovering degraded image quality. However, training such models requires large and diverse datasets, which are challenging to obtain in the medical domain. To address data scarcity and privacy concerns, we combine diffusion models with federated learning -- a decentralized training approach where models are trained individually at different sites, and their parameters are aggregated on a central server over multiple iterations. The variation in scanner types and image noise levels within and across institutions poses additional challenges for federated learning in LCPET denoising. In this study, we propose a novel noise-embedded federated learning diffusion model (Fed-NDIF) to address these challenges, leveraging a multicenter dataset and varying count levels. Our approach incorporates liver normalized standard deviation (NSTD) noise embedding into a 2.5D diffusion model and utilizes the Federated Averaging (FedAvg) algorithm to aggregate locally trained models into a global model, which is subsequently fine-tuned on local datasets to optimize performance and obtain personalized models. Extensive validation on datasets from the University of Bern, Ruijin Hospital in Shanghai, and Yale-New Haven Hospital demonstrates the superior performance of our method in enhancing image quality and improving lesion quantification. The Fed-NDIF model shows significant improvements in PSNR, SSIM, and NMSE of the entire 3D volume, as well as enhanced lesion detectability and quantification, compared to local diffusion models and federated UNet-based models.
Anatomically and Metabolically Informed Diffusion for Unified Denoising and Segmentation in Low-Count PET Imaging
Mar 17, 2025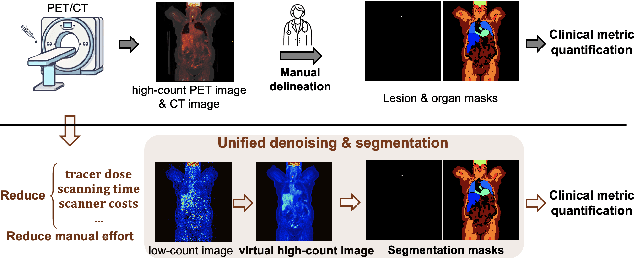
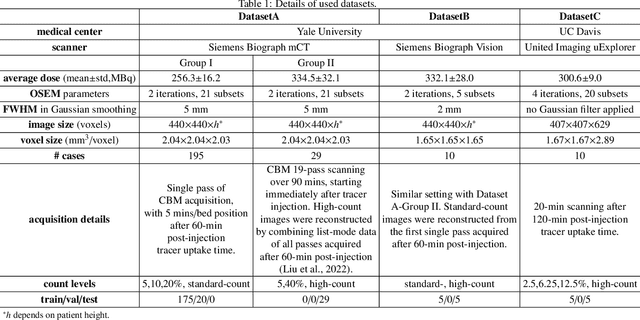
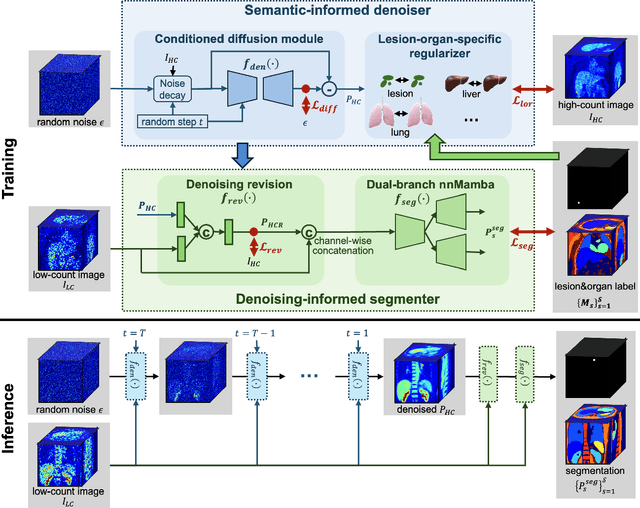
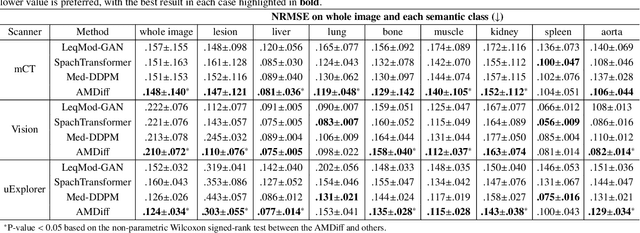
Positron emission tomography (PET) image denoising, along with lesion and organ segmentation, are critical steps in PET-aided diagnosis. However, existing methods typically treat these tasks independently, overlooking inherent synergies between them as correlated steps in the analysis pipeline. In this work, we present the anatomically and metabolically informed diffusion (AMDiff) model, a unified framework for denoising and lesion/organ segmentation in low-count PET imaging. By integrating multi-task functionality and exploiting the mutual benefits of these tasks, AMDiff enables direct quantification of clinical metrics, such as total lesion glycolysis (TLG), from low-count inputs. The AMDiff model incorporates a semantic-informed denoiser based on diffusion strategy and a denoising-informed segmenter utilizing nnMamba architecture. The segmenter constrains denoised outputs via a lesion-organ-specific regularizer, while the denoiser enhances the segmenter by providing enriched image information through a denoising revision module. These components are connected via a warming-up mechanism to optimize multitask interactions. Experiments on multi-vendor, multi-center, and multi-noise-level datasets demonstrate the superior performance of AMDiff. For test cases below 20% of the clinical count levels from participating sites, AMDiff achieves TLG quantification biases of -26.98%, outperforming its ablated versions which yield biases of -35.85% (without the lesion-organ-specific regularizer) and -40.79% (without the denoising revision module).
Derivative-Free Optimization via Finite Difference Approximation: An Experimental Study
Oct 31, 2024



Derivative-free optimization (DFO) is vital in solving complex optimization problems where only noisy function evaluations are available through an oracle. Within this domain, DFO via finite difference (FD) approximation has emerged as a powerful method. Two classical approaches are the Kiefer-Wolfowitz (KW) and simultaneous perturbation stochastic approximation (SPSA) algorithms, which estimate gradients using just two samples in each iteration to conserve samples. However, this approach yields imprecise gradient estimators, necessitating diminishing step sizes to ensure convergence, often resulting in slow optimization progress. In contrast, FD estimators constructed from batch samples approximate gradients more accurately. While gradient descent algorithms using batch-based FD estimators achieve more precise results in each iteration, they require more samples and permit fewer iterations. This raises a fundamental question: which approach is more effective -- KW-style methods or DFO with batch-based FD estimators? This paper conducts a comprehensive experimental comparison among these approaches, examining the fundamental trade-off between gradient estimation accuracy and iteration steps. Through extensive experiments in both low-dimensional and high-dimensional settings, we demonstrate a surprising finding: when an efficient batch-based FD estimator is applied, its corresponding gradient descent algorithm generally shows better performance compared to classical KW and SPSA algorithms in our tested scenarios.