 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Frequency-Modulated Point Cloud Rendering with Easy Editing
Mar 18, 2023
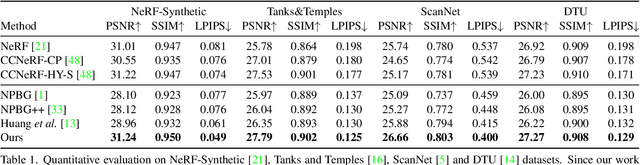
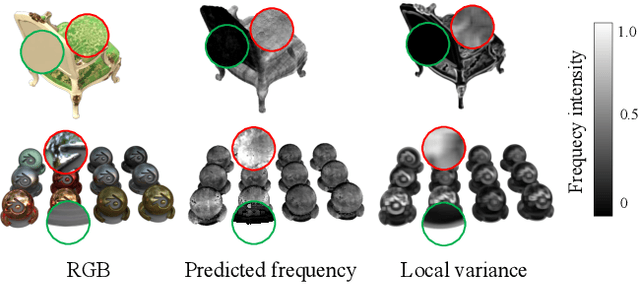
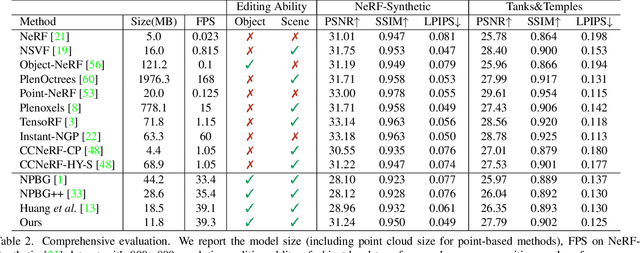
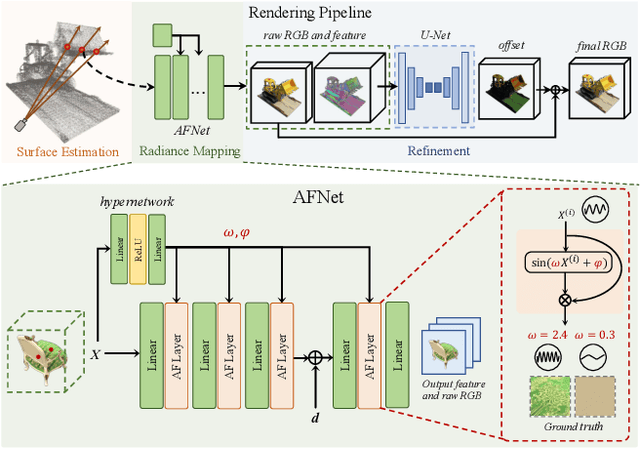
We develop an effective point cloud rendering pipeline for novel view synthesis, which enables high fidelity local detail reconstruction, real-time rendering and user-friendly editing. In the heart of our pipeline is an adaptive frequency modulation module called Adaptive Frequency Net (AFNet), which utilizes a hypernetwork to learn the local texture frequency encoding that is consecutively injected into adaptive frequency activation layers to modulate the implicit radiance signal. This mechanism improves the frequency expressive ability of the network with richer frequency basis support, only at a small computational budget. To further boost performance, a preprocessing module is also proposed for point cloud geometry optimization via point opacity estimation. In contrast to implicit rendering, our pipeline supports high-fidelity interactive editing based on point cloud manipulation. Extensive experimental results on NeRF-Synthetic, ScanNet, DTU and Tanks and Temples datasets demonstrate the superior performances achieved by our method in terms of PSNR, SSIM and LPIPS, in comparison to the state-of-the-art.
Rethinking Range View Representation for LiDAR Segmentation
Mar 18, 2023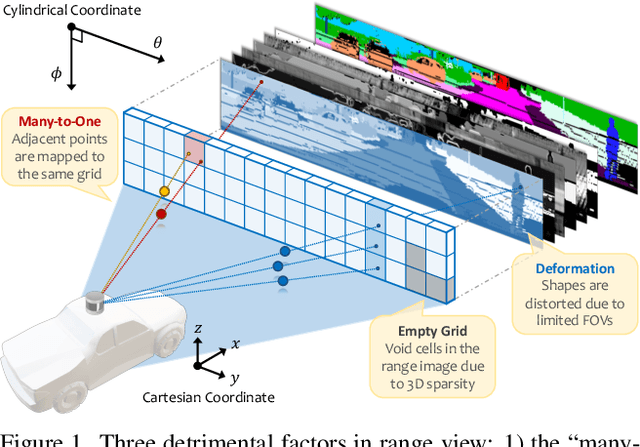
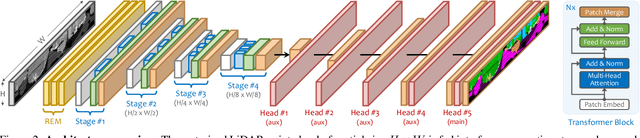
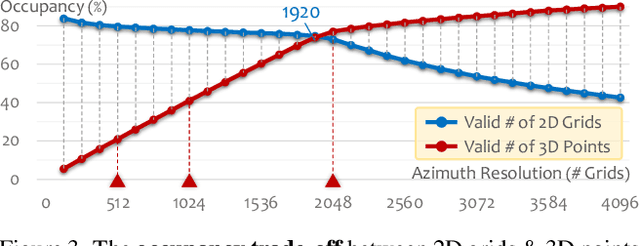
LiDAR segmentation is crucial for autonomous driving perception. Recent trends favor point- or voxel-based methods as they often yield better performance than the traditional range view representation. In this work, we unveil several key factors in building powerful range view models. We observe that the "many-to-one" mapping, semantic incoherence, and shape deformation are possible impediments against effective learning from range view projections. We present RangeFormer -- a full-cycle framework comprising novel designs across network architecture, data augmentation, and post-processing -- that better handles the learning and processing of LiDAR point clouds from the range view. We further introduce a Scalable Training from Range view (STR) strategy that trains on arbitrary low-resolution 2D range images, while still maintaining satisfactory 3D segmentation accuracy. We show that, for the first time, a range view method is able to surpass the point, voxel, and multi-view fusion counterparts in the competing LiDAR semantic and panoptic segmentation benchmarks, i.e., SemanticKITTI, nuScenes, and ScribbleKITTI.
One-class Damage Detector Prototyping Fully-Convolutional Data Description for Prognostics
Mar 18, 2023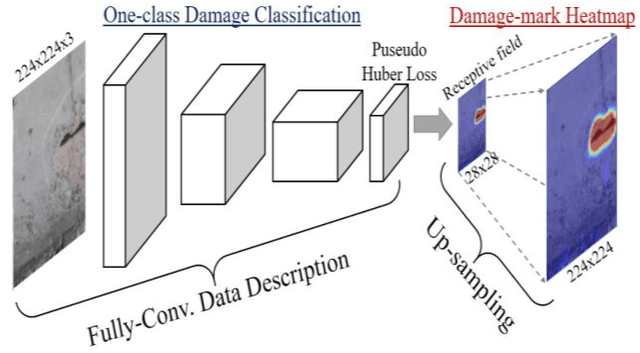
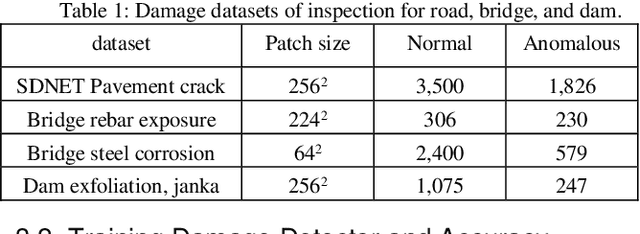
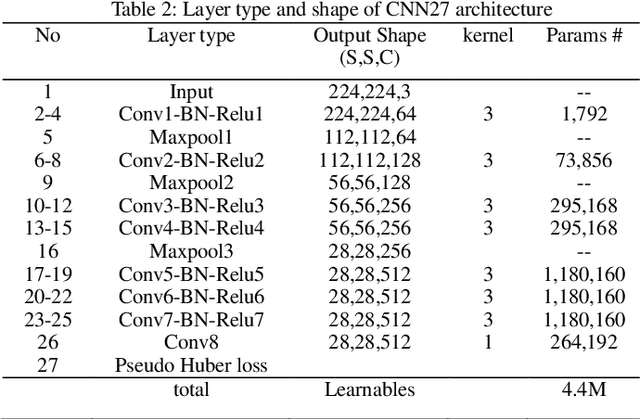

It is important for infrastructure managers to maintain a high standard to ensure user satisfaction during a lifecycle of infrastructures. Surveillance cameras and visual inspections have enabled progress toward automating the detection of anomalous features and assessing the occurrence of the deterioration. Frequently, collecting damage data constraints time consuming and repeated inspections. One-class damage detection approach has a merit that only the normal images enables us to optimize the parameters. Simultaneously, the visual explanation using the heat map enable us to understand the localized anomalous feature. We propose a prototype to automate one-class damage detection using the fully-convolutional data description (FCDD). We also visualize the explanation of the damage feature using the up-sampling-based activation map with the Gaussian up-sampling from the receptive field of the fully convolutional network (FCN). We demonstrate it in experimental studies: concrete damage and steel corrosion and mention its usefulness and future works.
BLiRF-RF: Bandlimited Radiance Fields for Dynamic Scene Modeling
Mar 18, 2023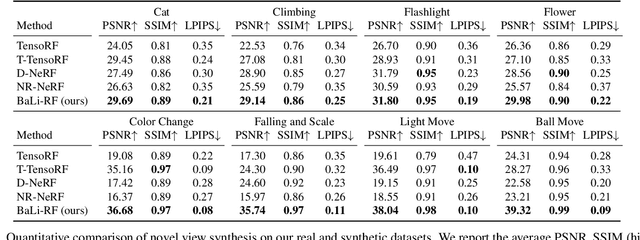
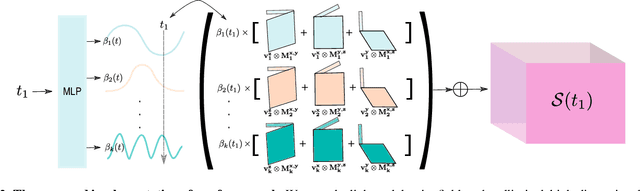

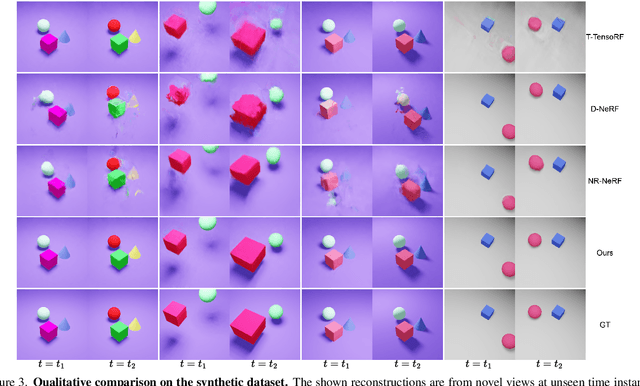
Reasoning the 3D structure of a non-rigid dynamic scene from a single moving camera is an under-constrained problem. Inspired by the remarkable progress of neural radiance fields (NeRFs) in photo-realistic novel view synthesis of static scenes, extensions have been proposed for dynamic settings. These methods heavily rely on neural priors in order to regularize the problem. In this work, we take a step back and reinvestigate how current implementations may entail deleterious effects, including limited expressiveness, entanglement of light and density fields, and sub-optimal motion localization. As a remedy, we advocate for a bridge between classic non-rigid-structure-from-motion (\nrsfm) and NeRF, enabling the well-studied priors of the former to constrain the latter. To this end, we propose a framework that factorizes time and space by formulating a scene as a composition of bandlimited, high-dimensional signals. We demonstrate compelling results across complex dynamic scenes that involve changes in lighting, texture and long-range dynamics.
Neural Frailty Machine: Beyond proportional hazard assumption in neural survival regressions
Mar 18, 2023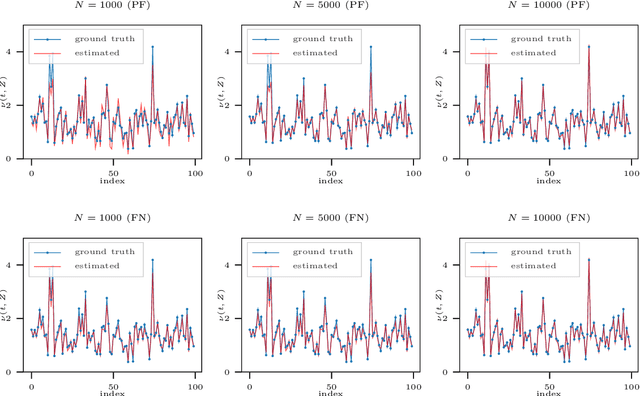
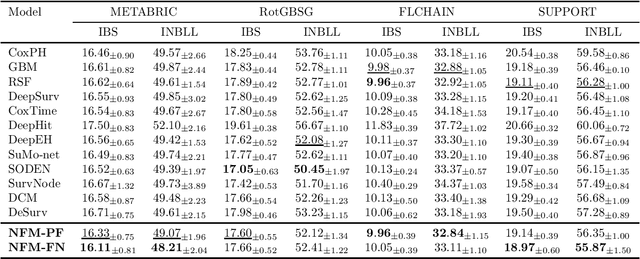
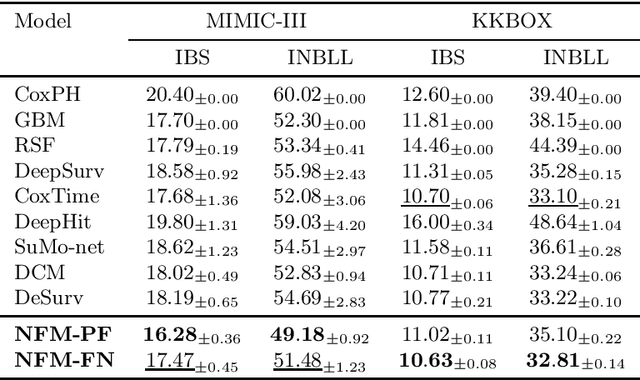
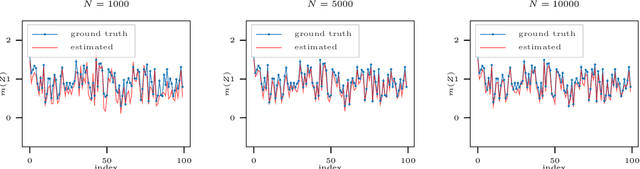
We present neural frailty machine (NFM), a powerful and flexible neural modeling framework for survival regressions. The NFM framework utilizes the classical idea of multiplicative frailty in survival analysis to capture unobserved heterogeneity among individuals, at the same time being able to leverage the strong approximation power of neural architectures for handling nonlinear covariate dependence. Two concrete models are derived under the framework that extends neural proportional hazard models and nonparametric hazard regression models. Both models allow efficient training under the likelihood objective. Theoretically, for both proposed models, we establish statistical guarantees of neural function approximation with respect to nonparametric components via characterizing their rate of convergence. Empirically, we provide synthetic experiments that verify our theoretical statements. We also conduct experimental evaluations over $6$ benchmark datasets of different scales, showing that the proposed NFM models outperform state-of-the-art survival models in terms of predictive performance. Our code is publicly availabel at https://github.com/Rorschach1989/nfm
Towards Open Temporal Graph Neural Networks
Mar 27, 2023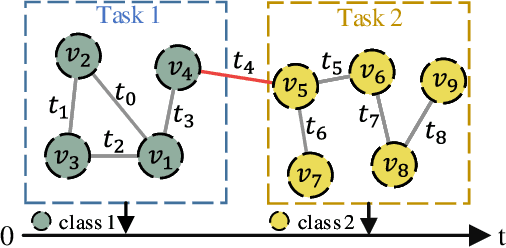
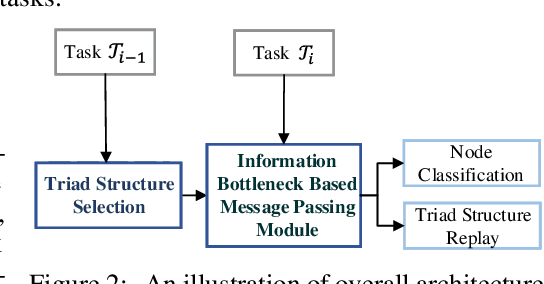
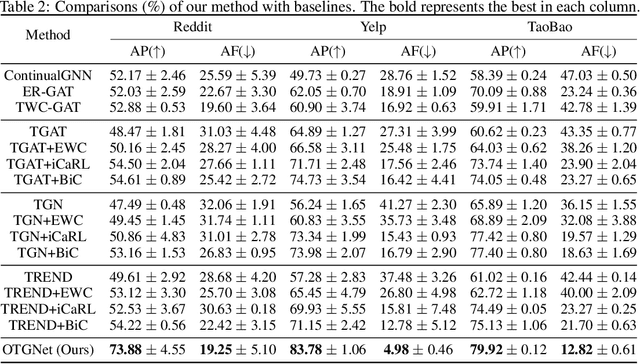
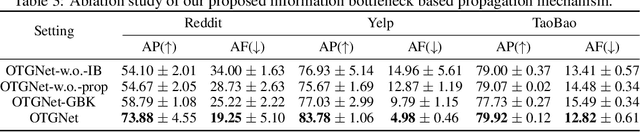
Graph neural networks (GNNs) for temporal graphs have recently attracted increasing attentions, where a common assumption is that the class set for nodes is closed. However, in real-world scenarios, it often faces the open set problem with the dynamically increased class set as the time passes by. This will bring two big challenges to the existing dynamic GNN methods: (i) How to dynamically propagate appropriate information in an open temporal graph, where new class nodes are often linked to old class nodes. This case will lead to a sharp contradiction. This is because typical GNNs are prone to make the embeddings of connected nodes become similar, while we expect the embeddings of these two interactive nodes to be distinguishable since they belong to different classes. (ii) How to avoid catastrophic knowledge forgetting over old classes when learning new classes occurred in temporal graphs. In this paper, we propose a general and principled learning approach for open temporal graphs, called OTGNet, with the goal of addressing the above two challenges. We assume the knowledge of a node can be disentangled into class-relevant and class-agnostic one, and thus explore a new message passing mechanism by extending the information bottleneck principle to only propagate class-agnostic knowledge between nodes of different classes, avoiding aggregating conflictive information. Moreover, we devise a strategy to select both important and diverse triad sub-graph structures for effective class-incremental learning. Extensive experiments on three real-world datasets of different domains demonstrate the superiority of our method, compared to the baselines.
Explain To Me: Salience-Based Explainability for Synthetic Face Detection Models
Mar 27, 2023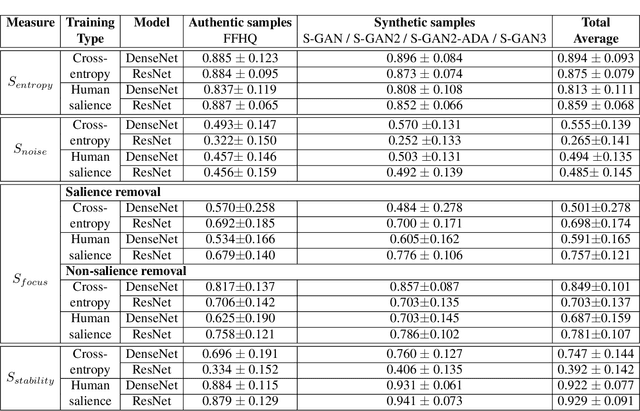

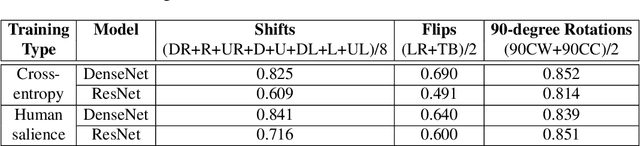

The performance of convolutional neural networks has continued to improve over the last decade. At the same time, as model complexity grows, it becomes increasingly more difficult to explain model decisions. Such explanations may be of critical importance for reliable operation of human-machine pairing setups, or for model selection when the "best" model among many equally-accurate models must be established. Saliency maps represent one popular way of explaining model decisions by highlighting image regions models deem important when making a prediction. However, examining salience maps at scale is not practical. In this paper, we propose five novel methods of leveraging model salience to explain a model behavior at scale. These methods ask: (a) what is the average entropy for a model's salience maps, (b) how does model salience change when fed out-of-set samples, (c) how closely does model salience follow geometrical transformations, (d) what is the stability of model salience across independent training runs, and (e) how does model salience react to salience-guided image degradations. To assess the proposed measures on a concrete and topical problem, we conducted a series of experiments for the task of synthetic face detection with two types of models: those trained traditionally with cross-entropy loss, and those guided by human salience when training to increase model generalizability. These two types of models are characterized by different, interpretable properties of their salience maps, which allows for the evaluation of the correctness of the proposed measures. We offer source codes for each measure along with this paper.
mHealth hyperspectral learning for instantaneous spatiospectral imaging of hemodynamics
Mar 27, 2023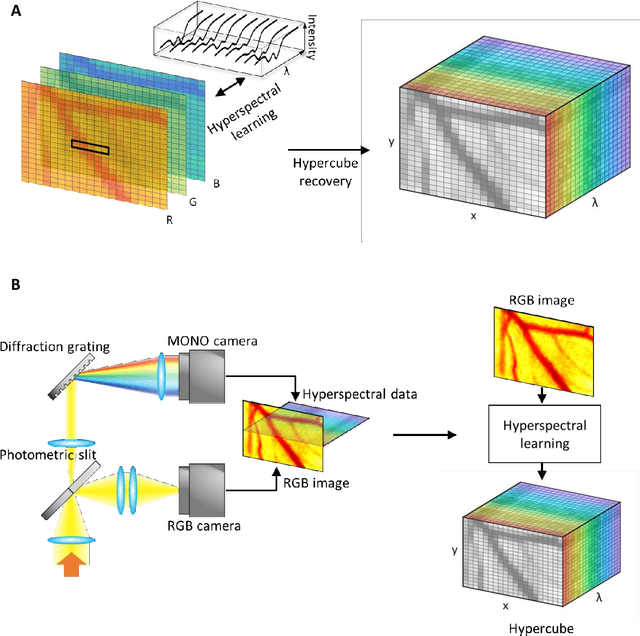
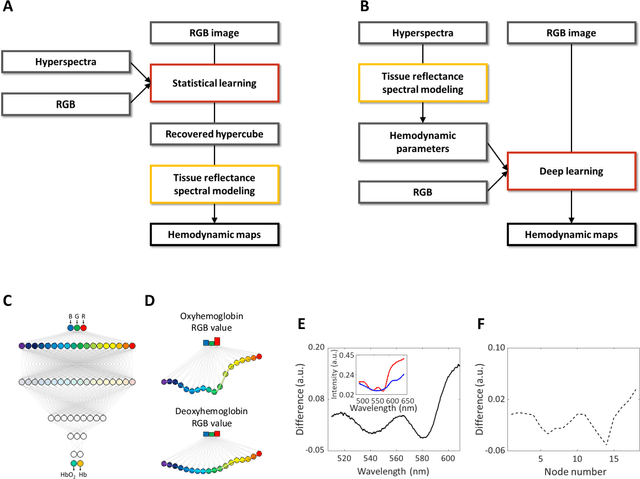
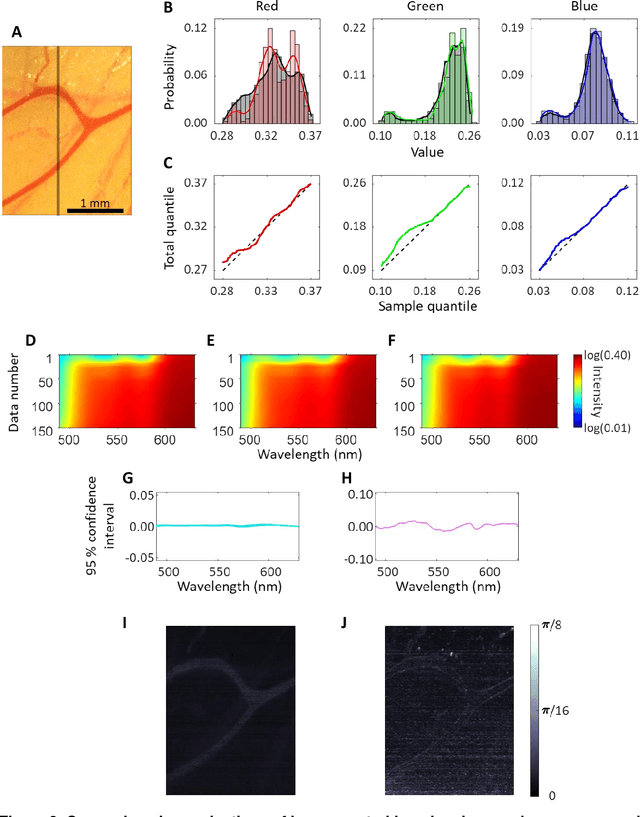
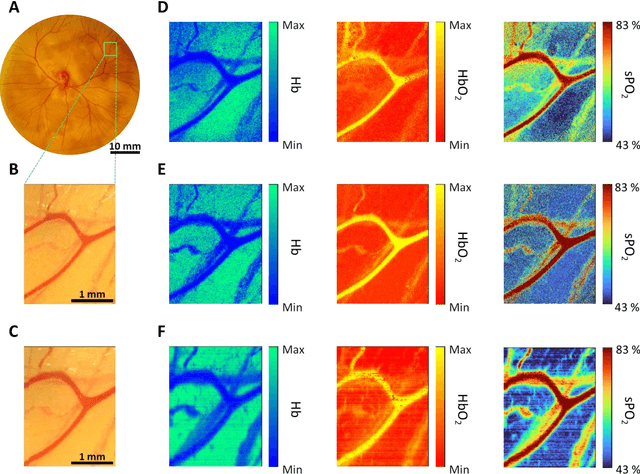
Hyperspectral imaging acquires data in both the spatial and frequency domains to offer abundant physical or biological information. However, conventional hyperspectral imaging has intrinsic limitations of bulky instruments, slow data acquisition rate, and spatiospectral tradeoff. Here we introduce hyperspectral learning for snapshot hyperspectral imaging in which sampled hyperspectral data in a small subarea are incorporated into a learning algorithm to recover the hypercube. Hyperspectral learning exploits the idea that a photograph is more than merely a picture and contains detailed spectral information. A small sampling of hyperspectral data enables spectrally informed learning to recover a hypercube from an RGB image. Hyperspectral learning is capable of recovering full spectroscopic resolution in the hypercube, comparable to high spectral resolutions of scientific spectrometers. Hyperspectral learning also enables ultrafast dynamic imaging, leveraging ultraslow video recording in an off-the-shelf smartphone, given that a video comprises a time series of multiple RGB images. To demonstrate its versatility, an experimental model of vascular development is used to extract hemodynamic parameters via statistical and deep-learning approaches. Subsequently, the hemodynamics of peripheral microcirculation is assessed at an ultrafast temporal resolution up to a millisecond, using a conventional smartphone camera. This spectrally informed learning method is analogous to compressed sensing; however, it further allows for reliable hypercube recovery and key feature extractions with a transparent learning algorithm. This learning-powered snapshot hyperspectral imaging method yields high spectral and temporal resolutions and eliminates the spatiospectral tradeoff, offering simple hardware requirements and potential applications of various machine-learning techniques.
Text2Video-Zero: Text-to-Image Diffusion Models are Zero-Shot Video Generators
Mar 23, 2023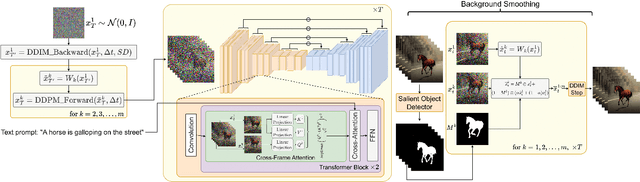

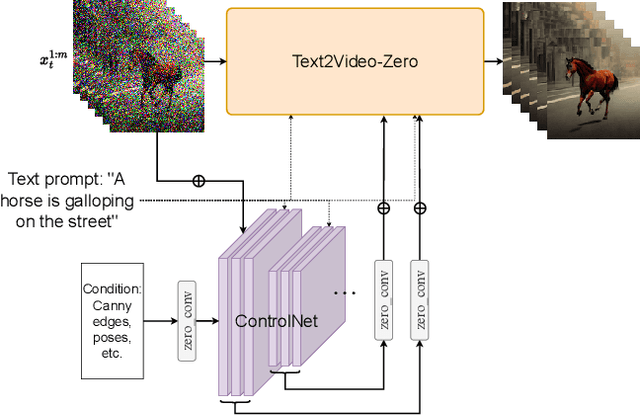

Recent text-to-video generation approaches rely on computationally heavy training and require large-scale video datasets. In this paper, we introduce a new task of zero-shot text-to-video generation and propose a low-cost approach (without any training or optimization) by leveraging the power of existing text-to-image synthesis methods (e.g., Stable Diffusion), making them suitable for the video domain. Our key modifications include (i) enriching the latent codes of the generated frames with motion dynamics to keep the global scene and the background time consistent; and (ii) reprogramming frame-level self-attention using a new cross-frame attention of each frame on the first frame, to preserve the context, appearance, and identity of the foreground object. Experiments show that this leads to low overhead, yet high-quality and remarkably consistent video generation. Moreover, our approach is not limited to text-to-video synthesis but is also applicable to other tasks such as conditional and content-specialized video generation, and Video Instruct-Pix2Pix, i.e., instruction-guided video editing. As experiments show, our method performs comparably or sometimes better than recent approaches, despite not being trained on additional video data. Our code will be open sourced at: https://github.com/Picsart-AI-Research/Text2Video-Zero .
Fault Prognosis of Turbofan Engines: Eventual Failure Prediction and Remaining Useful Life Estimation
Mar 23, 2023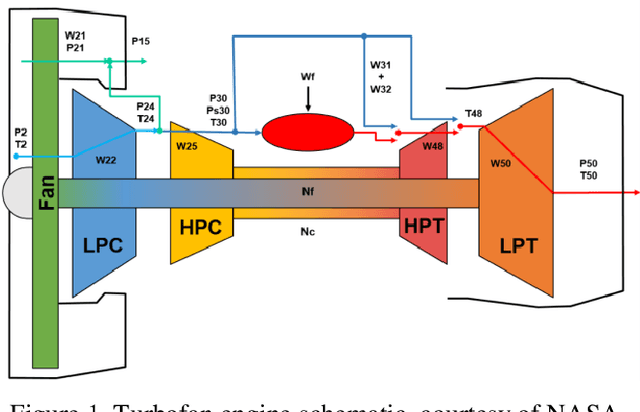
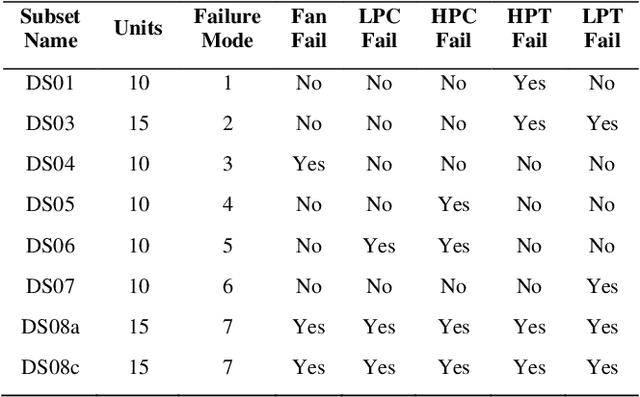
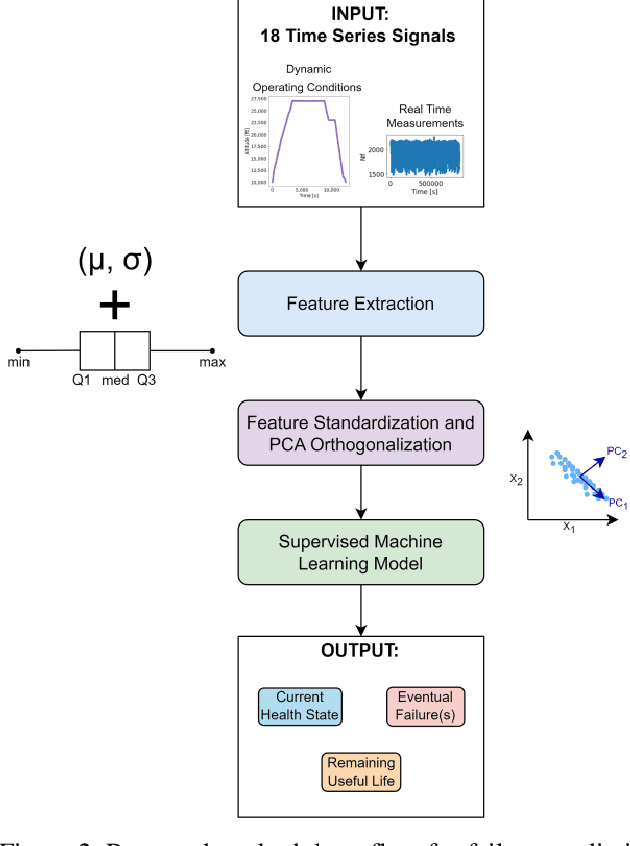
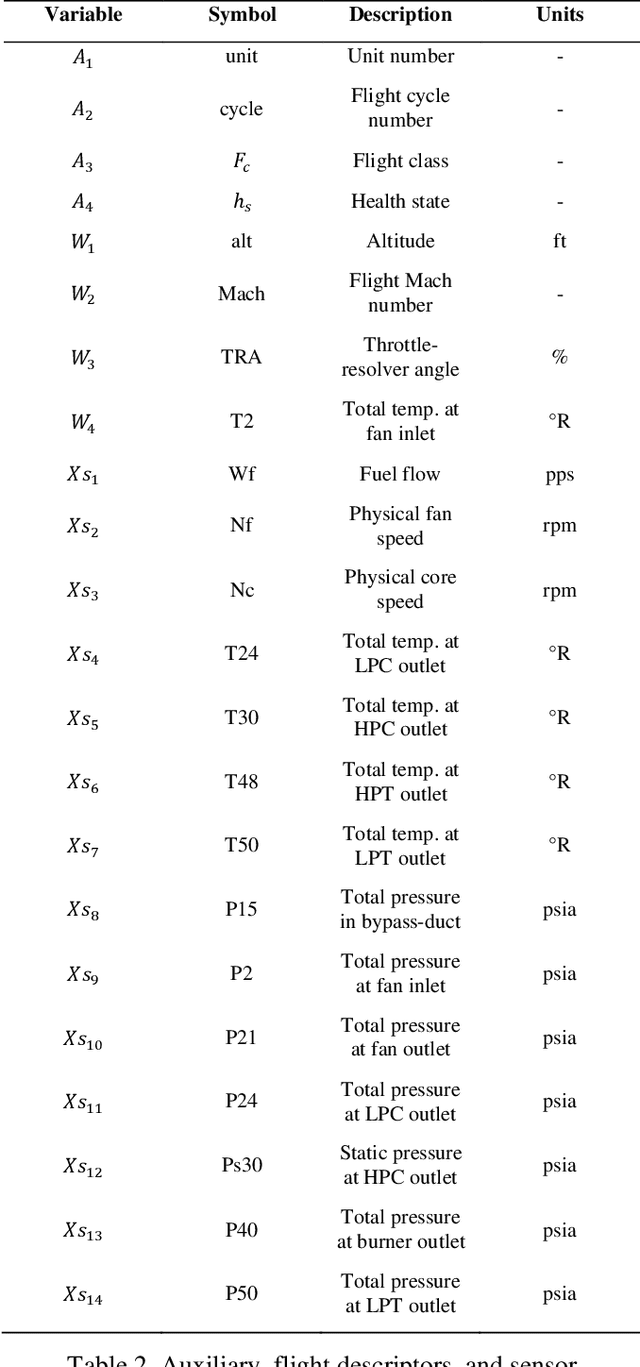
In the era of industrial big data, prognostics and health management is essential to improve the prediction of future failures to minimize inventory, maintenance, and human costs. Used for the 2021 PHM Data Challenge, the new Commercial Modular Aero-Propulsion System Simulation dataset from NASA is an open-source benchmark containing simulated turbofan engine units flown under realistic flight conditions. Deep learning approaches implemented previously for this application attempt to predict the remaining useful life of the engine units, but have not utilized labeled failure mode information, impeding practical usage and explainability. To address these limitations, a new prognostics approach is formulated with a customized loss function to simultaneously predict the current health state, the eventual failing component(s), and the remaining useful life. The proposed method incorporates principal component analysis to orthogonalize statistical time-domain features, which are inputs into supervised regressors such as random forests, extreme random forests, XGBoost, and artificial neural networks. The highest performing algorithm, ANN-Flux, achieves AUROC and AUPR scores exceeding 0.95 for each classification. In addition, ANN-Flux reduces the remaining useful life RMSE by 38% for the same test split of the dataset compared to past work, with significantly less computational cost.